") SOKey如何將數(shù)據(jù)并行轉(zhuǎn)化為模型并行再轉(zhuǎn)回數(shù)據(jù)并行
SOKey如何將數(shù)據(jù)并行轉(zhuǎn)化為模型并行再轉(zhuǎn)回數(shù)據(jù)并行
在上期文章中,我們對 HugeCTR Sparse Operation Kit (以下簡稱SOK) 的基本功能,性能,以及 API 用法做了初步的介紹,相信大家對如何使用 SOK 已經(jīng)有了基本的了解。在這期文章中,我們將從在 TensorFlow 上使用 SOK 時常見的“數(shù)據(jù)并行-模型并行-數(shù)據(jù)并行”流程入手,帶大家詳細了解 SOK 的原理。
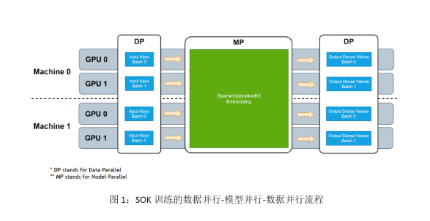
SOK 的 Embedding 計算主要分為三個階段:input-dispatcher -》 lookup -》 output-dispatcher,接下來我們將以 all-to-all 稠密 Embedding 層為例,帶大家梳理各個階段的計算過程。
1. Input Dispatcher
Input Dispatcher 的職責是將數(shù)據(jù)以并行的形式的輸入,分配到各個 GPU 上。總共分為以下幾個步驟:
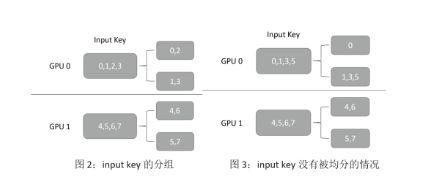
第一步:對每個 GPU 接收到的數(shù)據(jù)并行的 category key,按照 key 求余 GPU 的數(shù)量計算出其對應的 GPU ID,并分成和 GPU 數(shù)量相同的組;同時計算出每組內(nèi)有多少 key。例如圖 2 中,GPU 的總數(shù)為 2,GPU 0 獲取的輸入為 ,根據(jù)前面所講的規(guī)則,它將會被分成兩組。注意,在這一步,我們還會為每個分組產(chǎn)生一個 order 信息,用于 output dispacher 的重排序。
第二步:通過 NCCL 交換各個 GPU 上每組 key 的數(shù)量。由于每個 GPU 獲取的輸入,按照 key 求余 GPU 數(shù)量不一定能夠均分,如圖 3 所示,提前在各個 GPU 上交換 key 的總數(shù),可以在后面交換 key 的時候減少通信量。
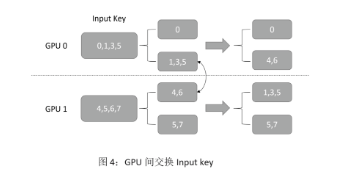
第三步:使用 NCCL,在各個 GPU 間按照 GPU ID 交換前面分好的各組 key,如圖 4 所示。
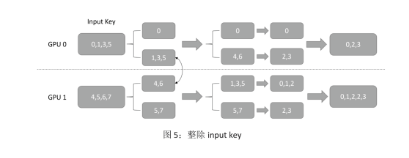
Step4:對交換后的所有 key 除以 GPU 總數(shù),這一步是為了讓每個 GPU 上的 key的數(shù)值范圍都小于 embedding table size 整除 GPU 的數(shù)量,保證后續(xù)在每個 worker 上執(zhí)行 lookup 時不會越界,結(jié)果如圖 5 所示。
總而言之,經(jīng)過上面 4 個步驟,我們將數(shù)據(jù)并行地輸入,按照其求余 GPU 數(shù)量的結(jié)果,分配到了不同對應的 GPU 上,完成了 input key 從數(shù)據(jù)并行到模型并行的轉(zhuǎn)化。雖然用戶往每個 GPU 上輸入的都可以是 embedding table 里的任何一個 key,但是經(jīng)過上述的轉(zhuǎn)化過程后,每個 GPU 上則只需要處理 embedding table 里 1/GPU_NUMBER 的 lookup。
2. Lookup
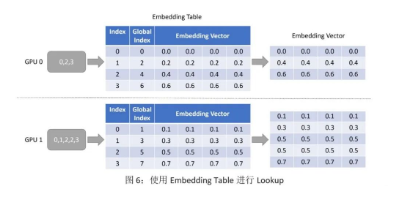
Lookup 的功能比較簡單,和單機的 lookup 的行為相同,就是用 input dispatcher 輸出的 key,在本地的 embedding table 里查詢出對應的 embedding vector,我們同樣用一個簡單的圖來舉例。注意下圖中 Global Index 代表每個 embedding vector 在實際的 embedding table 中對應的 key,而 Index 則是當前 GPU 的“部分”embedding table 中的 key。
3. Output Dispatcher
和 input dispatcher 的功能對應,output dispatcher 是將 embedding vector 按照和 input dispatcher 相同的路徑、相反的方向?qū)?embedding vector 返回給各個 GPU,讓模型并行的 lookup 結(jié)果重新變成數(shù)據(jù)并行。
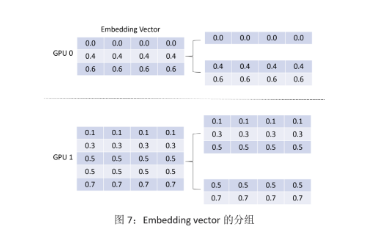
第一步:復用 input dispatcher 中的分組信息,將 embedding vector 進行分組,如圖 7 所示。
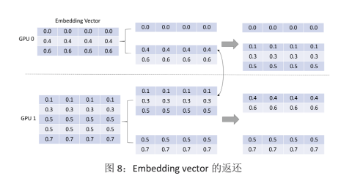
第二步:通過 NCCL 將 embedding vector 按 input dispatcher 的路徑返還,如圖 8 所示。
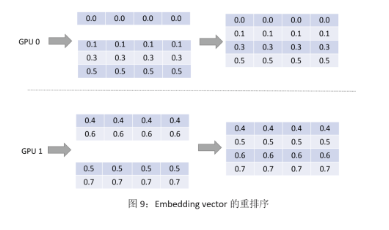
第三步:復用 input dispatcher 第一步驟的結(jié)果,將 embedding vector 進行重排序,讓其和輸入的 key 順序保持一致,如圖 9 所示。
可以看到, GPU 0 上輸入的[0, 1, 3, 5],最終被轉(zhuǎn)化為了[0.0, …], [0.1, …], [0.3, …], [0.5, …] 四個 embedding vector,雖然其中有 3 個 embedding vector 被存儲在 GPU 1 上,但是以一種對用戶透明的方式,在 GPU 0 上拿到了對應的 vector。在用戶看來,就好像整個 embedding table 都存在 GPU 0 上一樣。
4. Backward
在 backward 中,每個 GPU 會得到和 input 的 key 所對應的梯度,也就是數(shù)據(jù)并行的梯度。此時的梯度對應的 embedding vector 可能并不在當前 GPU 上,所以還需要做一步梯度的交換。這個步驟和 output dispatcher 的第三步驟中的工作流程的路徑完全相同,只是方向相反。仍然以前面的例子舉例,GPU 0 獲取了 key [0, 1, 3, 5]的梯度,我們把它們分別叫做 grad0, grad1, grad3, grad5;由于 grad1,grad3,grad5 對應的 embedding vector 在 GPU 1 上,所以我們把它們和 GPU 1 上的 grad4, grad6 進行交換,最終在得到了 GPU 0 上的梯度為[grad0, grad4, grad6],GPU 1 上的梯度為[grad1, grad3, grad5, grad5, gard7]。
結(jié)語
以上就是 SOK 將數(shù)據(jù)并行轉(zhuǎn)化為模型并行再轉(zhuǎn)回數(shù)據(jù)并行的過程,這整個流程都被封裝在了 SOK 的 Embedding Layer 中,用戶可以直接調(diào)用相關的 Python API 即可輕松完成訓練。
-
數(shù)據(jù)
+關注
關注
8文章
7067瀏覽量
89108 -
gpu
+關注
關注
28文章
4743瀏覽量
128992 -
API
+關注
關注
2文章
1502瀏覽量
62101 -
SOK
+關注
關注
0文章
5瀏覽量
6338
發(fā)布評論請先 登錄
相關推薦
基于Transformer做大模型預訓練基本的并行范式
用單片機進行串并行數(shù)據(jù)轉(zhuǎn)化及其在家用電器控制中的應用
verilog串并轉(zhuǎn)換,串行輸入八個12位的數(shù)據(jù),請問如何將這八個12位的數(shù)據(jù)并行輸出?
串行和并行的區(qū)別
串行和并行的區(qū)別
并行編程模型有什么優(yōu)勢
什么是數(shù)據(jù)并行傳輸,并行傳輸原理是什么?
單片機進行串/并行數(shù)據(jù)轉(zhuǎn)化及在家用電器控制中的應用
并行總線是什么?(并行總線協(xié)議介紹)
Spark的并行數(shù)據(jù)挖掘的研究
如何使用FPGA驅(qū)動并行ADC和并行DAC芯片
圖解大模型訓練之:數(shù)據(jù)并行上篇(DP, DDP與ZeRO)
大模型分布式訓練并行技術(一)-概述
基于PyTorch的模型并行分布式訓練Megatron解析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論