") FPGA在微軟云azure中的應(yīng)用
FPGA在微軟云azure中的應(yīng)用
隨著5G通信技術(shù)的發(fā)展,云計算和邊緣計算業(yè)務(wù)也將快速增長。由于云計算多樣性和邊緣環(huán)境復(fù)雜性的特點,將決定了在CPU,GPU,FPGA,ASIC中,不會只有一種芯片存在。所以FPGA一定可以尋找到它的應(yīng)用方向。相較于其它幾種芯片,F(xiàn)PGA具有以下幾種優(yōu)勢:
1 靈活可編程。FPGA是以LUT作為基本結(jié)構(gòu)的器件,可以根據(jù)需求的變化對其擦除重寫,運行新的程序。
2 高帶寬。FPGA芯片有很多高速管腳,可以連接多顆DRAM,產(chǎn)生較高的帶寬。
3 復(fù)雜的數(shù)據(jù)處理能力。FPGA能夠有針對性的處理邏輯關(guān)系復(fù)雜的程序,這相比于CPU,GPU等依賴指令處理數(shù)據(jù)的芯片有優(yōu)勢,因為它能夠做到更低的延遲。
FPGA也存在以下劣勢限制了它的發(fā)展:
1 編程復(fù)雜,開發(fā)周期較長。RTL的開發(fā)包括了架構(gòu)設(shè)計,RTL代碼,仿真驗證,上板調(diào)試。一個項目的周期往往是軟件開發(fā)的幾倍,團(tuán)隊規(guī)模也較大。這些既提高了開發(fā)成本,又沒法適應(yīng)不斷迭代的產(chǎn)品需求。
2 粗粒度硬件結(jié)構(gòu)導(dǎo)致資源利用率低。FPGA達(dá)不到100%的資源利用率,這是對資源的一種浪費,體現(xiàn)在經(jīng)濟(jì)上是提高了成本。
以上兩方面都可以歸結(jié)到成本這一點上,但是如果能夠解決1問題,那么2問題也就迎刃而解了。因為如果FPGA的市場應(yīng)用多了,那么其制造成本也會下降。1問題的解決一直在路上,但是一直沒有解決。HLS等類似軟件編程語言的出現(xiàn)可以提高FPGA的開發(fā)效率,但是相比于純軟件開發(fā)語言還是存在一定復(fù)雜性。而相對于RTL語言來說,HLS語言的硬件描述性不夠鮮明。所以硬件開發(fā)人員更多的會選擇硬件描述清晰的verilog,system Verilog等語言。
這些缺點并不意味著我們對FPGA在未來AI應(yīng)用中抱著悲觀的想法,一個是未來場景的復(fù)雜性和多樣性,一個是FPGA也在尋求改進(jìn)和發(fā)展。第一個決定了FPGA一定能夠在AI中活下去,第二個決定了FPGA在AI中活的怎么樣。
接下來我們來了解一下FPGA在微軟云azure中的應(yīng)用。
Azure stack edge
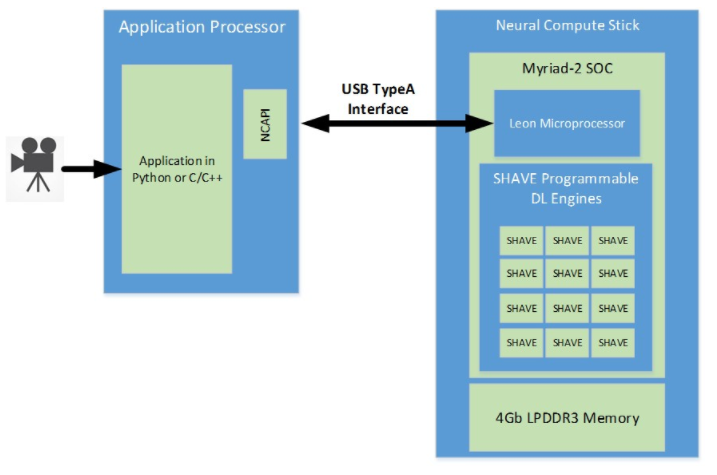
微軟在邊緣做了產(chǎn)品布局,依據(jù)邊緣的規(guī)模,提供了兩類產(chǎn)品。一類是針對計算任務(wù)繁重的企業(yè)用戶,其提供了基于GPU和FPGA的Pro設(shè)備,能夠?qū)崿F(xiàn)邊緣端的數(shù)據(jù)預(yù)處理,包括聚合數(shù)據(jù),修改數(shù)據(jù)等,以及運行ML模型。另外一類是針對隨時移動的用戶,提供了小而便攜的設(shè)備。這些設(shè)備使用了intel針對視覺處理專門研發(fā)的VPU芯片。雖然在2024年基于FPGA的pro設(shè)備將停用,而遷移到基于GPU的設(shè)備上。但是VPU芯片的出現(xiàn),反映了在邊緣計算應(yīng)用中,F(xiàn)PGA所發(fā)生的可能轉(zhuǎn)變。在多變的邊緣目標(biāo)上,小芯片能夠更有針對性的保留有效的計算資源,這樣精簡了結(jié)構(gòu),降低了功耗。Intel VPU是集成了Leon處理器,12個SHAVE計算核以及一個DRAM的SoC結(jié)構(gòu)。SHAVE是一個向量處理器,能夠進(jìn)行大量的向量運算。所以VPU能夠適合運行ML模型,以及進(jìn)行一些圖像處理方面的工作。目前VPU能夠支持21種神經(jīng)網(wǎng)絡(luò)算子,包括conv,relu等。這些神經(jīng)網(wǎng)絡(luò)可以通過其編譯器工具NCAPI轉(zhuǎn)化為可以在VPU中執(zhí)行的指令。目前能夠支持inception,mobilenet,googlenet,ssd,alexnet等很多卷積和LSTM網(wǎng)絡(luò)。
超算中心的FPGA
微軟在數(shù)據(jù)中心系統(tǒng)性的構(gòu)建了一個FPGA集群,這個FPGA集群能夠?qū)崿F(xiàn)內(nèi)部和外部server的互聯(lián)。在頂層軟件的分配調(diào)度下,可以執(zhí)行多種不同的任務(wù),包括web search ranking, deep neural networks, expensive compression等。
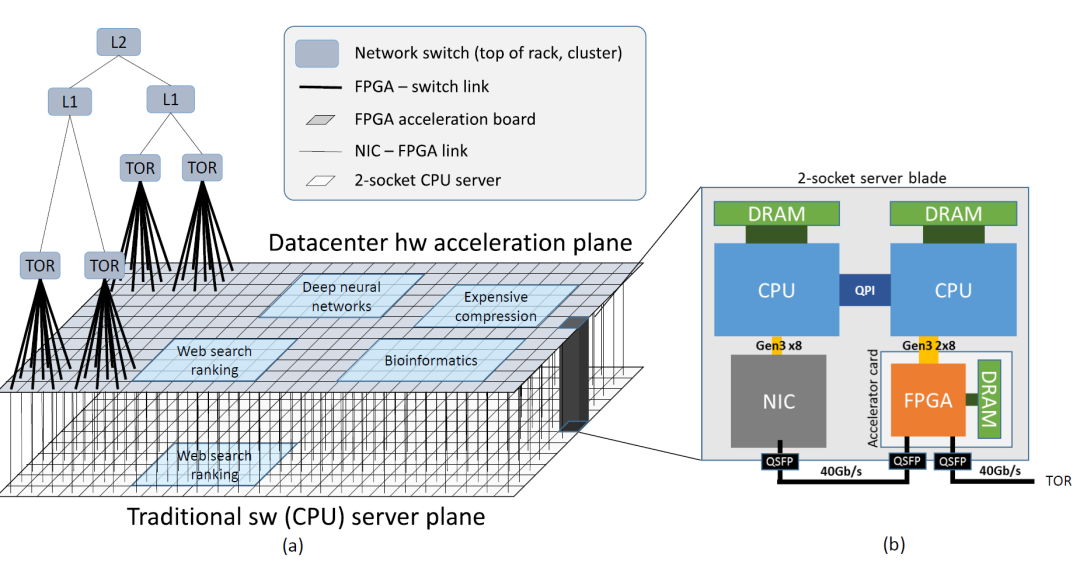
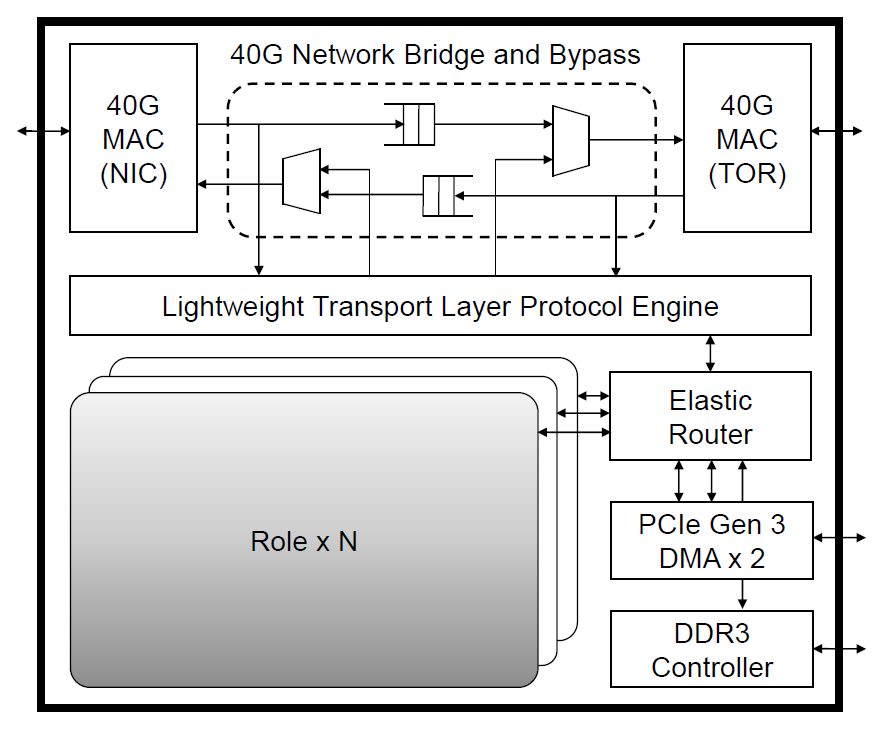
FPGA集群的基本結(jié)構(gòu)如上圖所示:包括了兩塊CPU和一塊altera的FPGA芯片。FPGA通過PCIE和一個NIC來和兩塊CPU進(jìn)行通信。NIC保證了FPGA可以實現(xiàn)原位處理網(wǎng)絡(luò)數(shù)據(jù)包。FPGA之間還通過ToR實現(xiàn)互聯(lián),ToR保證了一個任務(wù)能夠被分割為多個子任務(wù),然后分配給多個FPGA處理。在邏輯層面,F(xiàn)PGA定義了Lightweight Transport Layer(LTL)和Elastic Router(ER)。LTL實現(xiàn)了不同的FPGA芯片之間的互聯(lián),這樣保證了遠(yuǎn)程FPGA之間的通信,使得整個FPGA集群處于一個整體中。ER是用于同一個FPGA芯片中不同任務(wù)的互聯(lián)。LTL和ER的混合使用能夠靈活的為FPGA分配不同任務(wù),滿足數(shù)據(jù)中心任務(wù)多樣性需求。ToR形成了三層結(jié)構(gòu),L0層連接了24個FPGA設(shè)備,L1連接了960個設(shè)備,L2級可能連接了超過幾百萬的設(shè)備。L0級的round-trip延時大概在2.8us,L1級平均在7.7us,而L2級在22us。
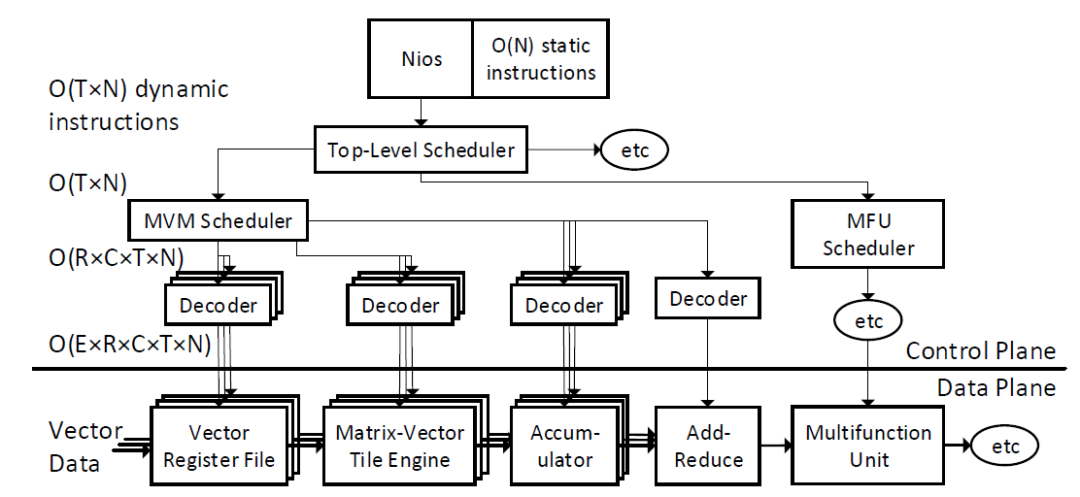
FPGA架構(gòu)
微軟的神經(jīng)網(wǎng)絡(luò)加速器主要是針對單batch低延遲來設(shè)計的,其所期望的是能夠最大限度的將weight緩存在片上,通過將一個大的網(wǎng)絡(luò)進(jìn)行分割,分配到多個FPGA芯片上實現(xiàn)。其分割的子網(wǎng)絡(luò)的權(quán)重大小可以適配一顆FPGA芯片上weight的緩存空間。架構(gòu)將計算重點放在矩陣-向量乘法上,這個也是合理的,因為LSTM,CNN網(wǎng)絡(luò)大部分計算量都由矩陣乘法承擔(dān)。其它函數(shù)運算,包括向量加法,乘法,sigmoid,tanh等函數(shù),則統(tǒng)一到同一個多功能函數(shù)模塊中。這樣做的好處是簡化了FPGA架構(gòu),同時也簡化了數(shù)據(jù)流。因此其整個架構(gòu)中沒有多端口共享的memory,不存在對多數(shù)據(jù)訪問沖突的處理。同時也簡化了指令,消除了對指令依賴關(guān)系的判斷和檢測。FPGA架構(gòu)中有對指令的進(jìn)一步分解和處理,所以軟件端的指令非常簡單,就是通過C語言的宏定義實現(xiàn)的。
其矩陣向量乘法結(jié)構(gòu)是由多個dot-product結(jié)構(gòu)組成的,多個dot-product和累加器形成了一個tile,然后多個tile就構(gòu)成了一個大的矩陣向量乘法。
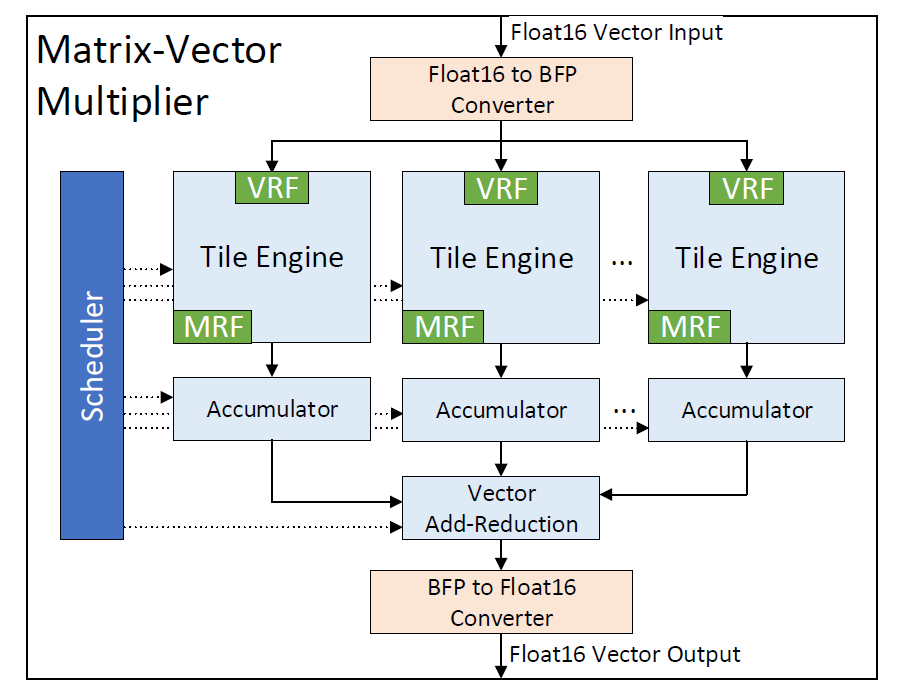
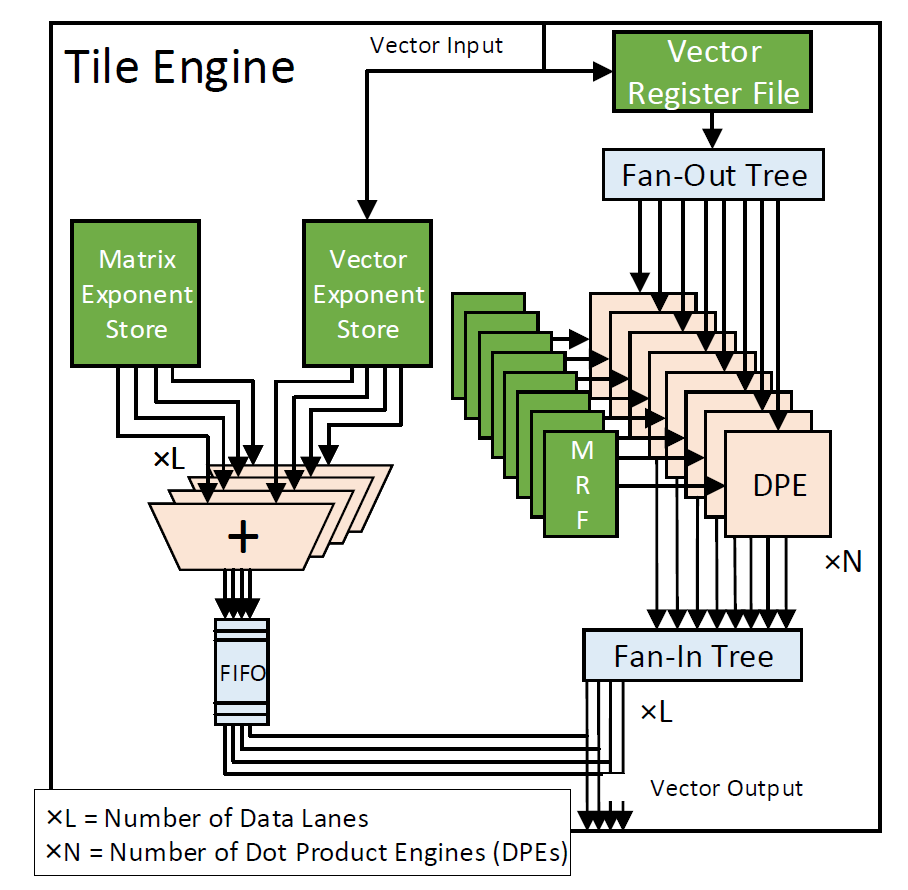
軟件結(jié)構(gòu)
神經(jīng)網(wǎng)絡(luò)加速器的工具鏈包括:CNTK(微軟自定義的一個指令級描述),tensorflow或者caffe的圖文件作為輸入,然后通過前端轉(zhuǎn)化為IR表示,然后依據(jù)網(wǎng)絡(luò)大小以及FPGA中資源情況對圖進(jìn)行分割和優(yōu)化,然后產(chǎn)生硬件可執(zhí)行指令。如果網(wǎng)絡(luò)較大,那么網(wǎng)絡(luò)可以被分割成多個子圖,部署到不同F(xiàn)PGA上。如果一個矩陣乘法過大,那么可以被分割成多塊來實現(xiàn)。對于不可實現(xiàn)的神經(jīng)網(wǎng)絡(luò)算子,工具鏈可以將多個不可實現(xiàn)算子組合成一個子圖,在CPU上完成。
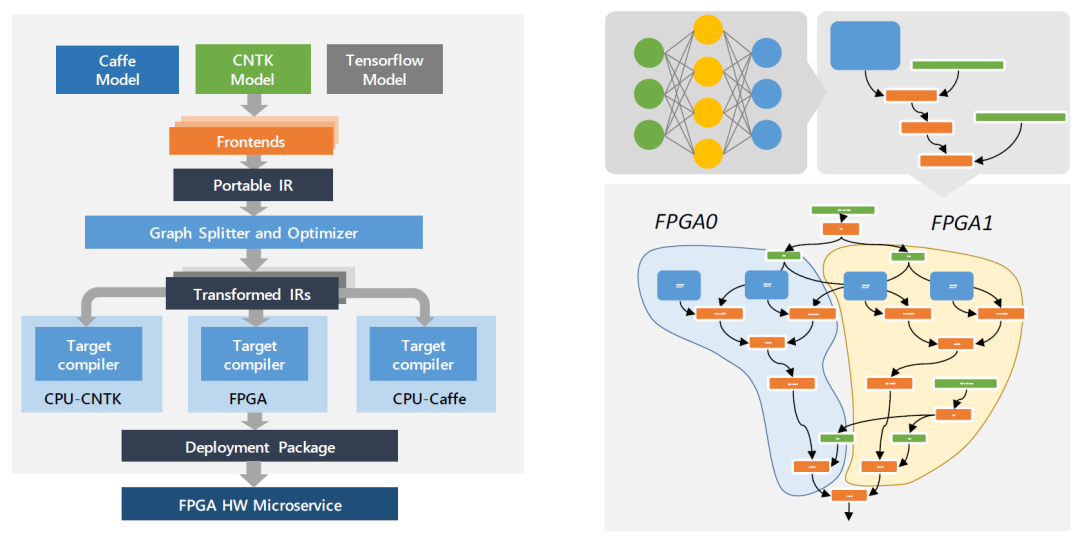
引用
1accelerating artificial intelligence bing whitepaper
2Cloud Scale Acceleration Architecture
3A Configurable Cloud-ScaleDNN Processor for Real-Time AI
審核編輯 :李倩
-
FPGA
+關(guān)注
關(guān)注
1629文章
21729瀏覽量
603018 -
cpu
+關(guān)注
關(guān)注
68文章
10855瀏覽量
211594
原文標(biāo)題:FPGA在microsoft azure的應(yīng)用
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
諾基亞擴(kuò)展與微軟Azure的數(shù)據(jù)中心網(wǎng)絡(luò)供應(yīng)協(xié)議
微軟發(fā)布Azure AI Foundry,推動云服務(wù)增長
通過工業(yè)智能網(wǎng)關(guān)實現(xiàn)與微軟Azure IoT中心快速配置操作
基于Arm Neoverse的微軟全新Azure虛擬機(jī)上線
微軟Azure首獲英偉達(dá)GB200 AI服務(wù)器
微軟為Azure推出全新H200 v5系列虛擬機(jī)
Palantir計劃在微軟Azure平臺上部署其人工智能產(chǎn)品
FPGA在人工智能中的應(yīng)用有哪些?
如影數(shù)字人生成平臺SenseAvatar上線微軟全球云市場
微軟與谷歌云計算部門相繼裁員
微軟Azure云部門裁員數(shù)千人
微軟將采用AMD AI芯片以替代英偉達(dá),為云計算提供更優(yōu)解決方案
全球云服務(wù)市場增長,亞馬遜AWS、微軟Azure及谷歌GCP差距拉大
FPGA在深度學(xué)習(xí)應(yīng)用中或?qū)⑷〈鶪PU
RAMQTT/TLS Azure云連接解決方案-細(xì)胞應(yīng)用項目

- 設(shè)計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計資源
- 設(shè)計技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗
- 設(shè)計大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號手機(jī)智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論