


在這三部分系列的第一部分中,作者調(diào)查了機(jī)器學(xué)習(xí)技術(shù)在高度自動化駕駛場景中的驅(qū)動因素和潛在應(yīng)用。第二部分定義了機(jī)器學(xué)習(xí)技術(shù)的理論背景,以及汽車開發(fā)人員可用的神經(jīng)網(wǎng)絡(luò)類型。第三部分在功能安全要求的背景下評估這些選項。
在過去的幾年里,機(jī)器學(xué)習(xí)一直是研究和工業(yè)界最熱門的話題之一。與幾十年前機(jī)器學(xué)習(xí)的出現(xiàn)相比,計算性能和算法的最新進(jìn)展引起了新的關(guān)注。
機(jī)器學(xué)習(xí),特別是深度學(xué)習(xí)解決方案促進(jìn)了人工智能最近取得的令人矚目的成果。應(yīng)用包括自然語言處理 (NLP)、個人協(xié)助、AlphaGo 戰(zhàn)勝人類,以及在學(xué)習(xí)玩 Atari 游戲時達(dá)到人類水平的行為。
考慮到機(jī)器學(xué)習(xí)和深度學(xué)習(xí)在解決極其復(fù)雜的問題時能夠取得如此令人印象深刻的結(jié)果,很明顯,研究人員和工程師也考慮將它們應(yīng)用于自動駕駛汽車的高度自動駕駛 (HAD) 場景。NVIDIA 的 Davenet、Comma.Ai、Google Car 和 Tesla 在該領(lǐng)域取得了第一個有希望的成果。機(jī)器學(xué)習(xí)和深度學(xué)習(xí)方法已經(jīng)產(chǎn)生了最初的原型,但是這些功能的工業(yè)化在例如基本的功能安全考慮方面提出了額外的挑戰(zhàn)。
本文旨在為正在進(jìn)行的關(guān)于機(jī)器學(xué)習(xí)在汽車行業(yè)中的作用的討論做出貢獻(xiàn),并強(qiáng)調(diào)該主題在自動駕駛汽車背景下的重要性。特別是,它旨在增加對機(jī)器學(xué)習(xí)技術(shù)的能力和局限性的理解。
首先,我們在 EB robinos 參考架構(gòu)的背景下討論基于機(jī)器學(xué)習(xí)的高度自動駕駛的設(shè)計空間和架構(gòu)替代方案。然后詳細(xì)介紹了 Elektrobit 目前正在研究和開發(fā)的兩個選定用例。
第二部分提供了機(jī)器學(xué)習(xí)和深度神經(jīng)網(wǎng)絡(luò) (DNN) 的理論背景,它們?yōu)橥茖?dǎo)用于根據(jù)給定任務(wù)選擇機(jī)器學(xué)習(xí)技術(shù)的標(biāo)準(zhǔn)提供了基礎(chǔ)。最后,第三部分討論了影響功能安全考慮的驗證和確認(rèn)挑戰(zhàn)。
機(jī)器學(xué)習(xí)和高度自動化駕駛
開發(fā)導(dǎo)致自動駕駛汽車的高度自動駕駛功能是一項復(fù)雜而艱巨的任務(wù)。工程師通常使用分而治之的原則來應(yīng)對這些挑戰(zhàn)。這是有充分理由的:具有明確定義接口的分解系統(tǒng)可以比單個黑盒更徹底地測試和驗證。
我們的高度自動駕駛方法是 EB robinos,如圖 1 所示。EB robinos 是一種功能性軟件架構(gòu),具有開放接口和軟件模塊,允許開發(fā)人員管理自動駕駛的復(fù)雜性。EB robinos 參考架構(gòu)按照“感知、計劃、行動”分解范式集成了組件。此外,它在其軟件模塊中利用機(jī)器學(xué)習(xí)技術(shù),以應(yīng)對高度非結(jié)構(gòu)化的現(xiàn)實世界駕駛環(huán)境。以下小節(jié)包含已選擇的集成在 EB robinos 中的技術(shù)示例。
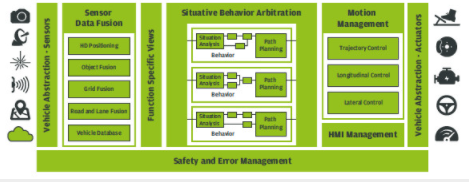
圖 1.開放式 EB robinos 參考架構(gòu)。
相比之下,端到端的深度學(xué)習(xí)方法也存在,它涵蓋了從感覺到行動的方方面面(Bojarski et al. 2016)。然而,關(guān)于極端情況和罕見事件的處理和訓(xùn)練,以及必要的訓(xùn)練數(shù)據(jù)的指數(shù)數(shù)量,分解方法(即語義抽象)被認(rèn)為更合理(Shalev-Shwartz et al. 2016 )。
然而,即使遵循分解方法,也需要決定哪些部分最好單獨處理或與其他部分結(jié)合處理。還必須確定機(jī)器學(xué)習(xí)方法是否有望在特定塊完成的任務(wù)中優(yōu)于傳統(tǒng)工程算法。尤其重要的是,此決定可能會受到功能安全考慮的影響。如本系列后面所述,功能安全是自動駕駛的關(guān)鍵要素。傳統(tǒng)的軟件組件是根據(jù)具體需求編寫的,并進(jìn)行相應(yīng)的測試。
機(jī)器學(xué)習(xí)系統(tǒng)測試和驗證的主要問題是它們的黑盒性質(zhì)和學(xué)習(xí)方法的隨機(jī)行為。基本上不可能預(yù)測系統(tǒng)如何學(xué)習(xí)其結(jié)構(gòu)。
上面給出的標(biāo)準(zhǔn)和理論背景可以為明智的決策提供指導(dǎo)。Elektrobit 目前正在研究和開發(fā)機(jī)器學(xué)習(xí)方法被認(rèn)為很有前景的用例。接下來介紹兩個這樣的用例。第一個涉及為機(jī)器學(xué)習(xí)算法生成人工訓(xùn)練樣本及其在交通標(biāo)志識別中的部署。第二個用例描述了我們的自學(xué)汽車方法。這兩個示例都使用了當(dāng)前最先進(jìn)的深度學(xué)習(xí)技術(shù)。
用例 1:人工樣本生成和交通標(biāo)志識別
該項目在增強(qiáng)入口導(dǎo)航系統(tǒng)中使用的 OpenStreetMap (OSM) 數(shù)據(jù)的背景下,提出了一種限速和限速結(jié)束交通標(biāo)志 (TS) 識別系統(tǒng)。目的是在可以安裝在汽車擋風(fēng)玻璃上的標(biāo)準(zhǔn)智能手機(jī)上運行該算法。系統(tǒng)檢測交通標(biāo)志及其 GPS 位置,并通過手機(jī)的移動數(shù)據(jù)連接將收集的數(shù)據(jù)上傳到后端服務(wù)器。該方法主要分為兩個階段:檢測和識別。檢測是通過增強(qiáng)分類器實現(xiàn)的。識別是通過概率貝葉斯推理框架執(zhí)行的,該框架融合了由一組視覺概率過濾器傳遞的信息。本文的下一部分包含對所用算法背后的理論背景的描述。
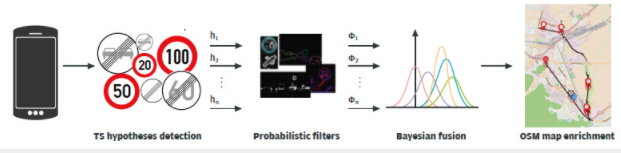
圖 2:基于智能手機(jī)的 TSR 系統(tǒng)框圖
獲得的彩色圖像以 24 位 RGB 格式傳遞給檢測器。通過評估通過檢測窗口計算的級聯(lián)分類器的響應(yīng)來執(zhí)行檢測過程。
該檢測窗口以不同的比例在圖像上移動。可能的交通標(biāo)志感興趣區(qū)域 (RoI) 被收集為一組對象假設(shè)。從特征提取的角度來看,分類級聯(lián)使用擴(kuò)展的局部二進(jìn)制模式 (eLPB) 進(jìn)行訓(xùn)練。假設(shè)向量中的每個元素通過支持向量機(jī)(SVM)學(xué)習(xí)算法分類為交通標(biāo)志。
交通標(biāo)志識別方法依賴于人工標(biāo)記的交通標(biāo)志,用于訓(xùn)練檢測和識別分類器。由于不同國家使用的交通標(biāo)志模板種類繁多,標(biāo)記過程繁瑣且容易出錯。
要使交通標(biāo)志識別方法表現(xiàn)良好,需要每個國家/地區(qū)的特定訓(xùn)練數(shù)據(jù)。由于必須考慮位置、照明和天氣條件,因此創(chuàng)建足夠多的手動標(biāo)記交通標(biāo)志非常耗時。
因此,Elektrobit 創(chuàng)建了一種算法,可以從單個人工模板圖像自動生成訓(xùn)練數(shù)據(jù),以克服手動注釋大量訓(xùn)練樣本的挑戰(zhàn)。圖 4 顯示了算法的結(jié)構(gòu)。
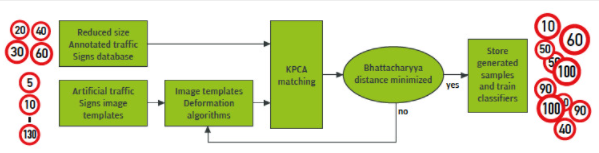
圖 4.基于機(jī)器學(xué)習(xí)的識別系統(tǒng)的人工樣本生成算法框圖。
這種方法提供了一種生成用于機(jī)器學(xué)習(xí)算法訓(xùn)練階段的人工數(shù)據(jù)的方法。該方法使用每個國家的真實和通用交通標(biāo)志圖像模板的縮減數(shù)據(jù)集來輸出圖像集合。
這些圖像的特征是由一系列圖像模板變形算法人為定義的。使用核主成分分析 (KPCA) 對減少的一組真實世界圖像對由此獲得的人工圖像進(jìn)行評估。當(dāng)生成圖像的特征與真實圖像的特征相對應(yīng)時,人工數(shù)據(jù)集適用于機(jī)器學(xué)習(xí)系統(tǒng)的訓(xùn)練,在這種特殊情況下用于交通標(biāo)志識別。
Elektrobit 將 Boosting SVM 分類器替換為基于深度區(qū)域的檢測和識別卷積神經(jīng)網(wǎng)絡(luò),以提高原始交通標(biāo)志識別系統(tǒng)的精度。該網(wǎng)絡(luò)使用 Caffe (Jia et al. 2014) 進(jìn)行部署,Caffe 是由 Berkley 開發(fā)并由 NVIDIA 支持的深度神經(jīng)網(wǎng)絡(luò)庫。Caffe 是一個帶有 Python 和 Matlab 接口的純 C++/CUDA 庫。除了核心的深度學(xué)習(xí)功能外,Caffe 還提供可直接用于機(jī)器學(xué)習(xí)應(yīng)用的參考深度學(xué)習(xí)模型。圖 5 顯示了用于交通標(biāo)志檢測和識別的 Caffe 網(wǎng)絡(luò)結(jié)構(gòu)。不同的彩色塊代表卷積(紅色)、池化(黃色)、激活(綠色)和全連接網(wǎng)絡(luò)層(紫色)。
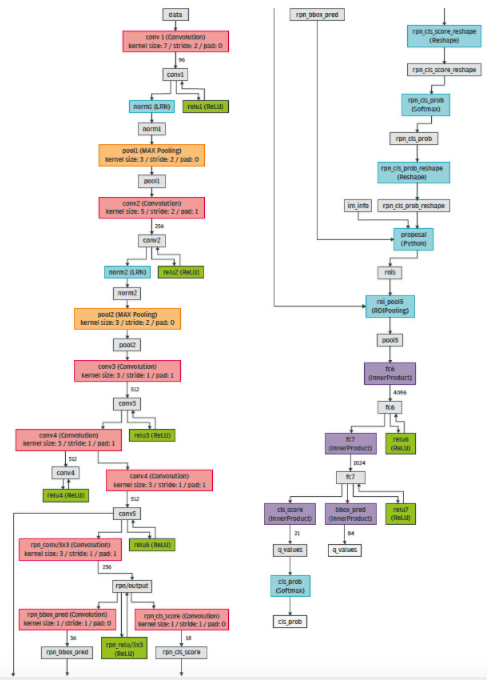
圖 5. Caffe 中基于深度區(qū)域的檢測和識別卷積神經(jīng)網(wǎng)絡(luò)。
用例 2:學(xué)習(xí)如何駕駛
深度學(xué)習(xí)的革命最近增加了對另一種范式的關(guān)注,即強(qiáng)化學(xué)習(xí) (RL)。在 RL 中,代理本身通過獎勵系統(tǒng)學(xué)習(xí)如何執(zhí)行某些任務(wù)。該方法屬于半監(jiān)督學(xué)習(xí)的范疇,因為獎勵系統(tǒng)的設(shè)計需要特定領(lǐng)域的知識。
與監(jiān)督學(xué)習(xí)相比,即使輸入數(shù)據(jù)不需要標(biāo)記也是如此。最近對 RL 的興趣主要歸功于 Deep Mind 團(tuán)隊的開創(chuàng)性工作。該團(tuán)隊設(shè)法將 RL 與能夠?qū)W習(xí)動作價值函數(shù)的深度神經(jīng)網(wǎng)絡(luò)相結(jié)合(Mnih et al. 2016)。他們的系統(tǒng)能夠?qū)W會以人類水平的能力玩多個 Atari 游戲。
我們構(gòu)建了深度強(qiáng)化學(xué)習(xí)系統(tǒng),如圖 6 所示,以便安全地試驗自動駕駛學(xué)習(xí)。該系統(tǒng)使用 TORCS 開源競賽模擬器(Wymann et al. 2014)。TORCS 作為高度便攜的多平臺賽車模擬器在科學(xué)界被廣泛使用。它在 Linux(所有架構(gòu),32 位和 64 位,小端和大端)、FreeBSD、OpenSolaris、MacOSX 和 Windows(32 位和 64 位)上運行。它有許多不同的汽車、賽道和對手來比賽。我們可以收集用于物體檢測的圖像以及來自游戲引擎的關(guān)鍵駕駛指標(biāo)。這些指標(biāo)包括汽車的速度、自我汽車與道路中心線的相對位置以及與前面汽車的距離。
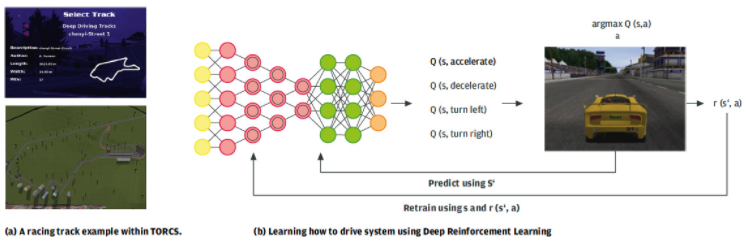
圖 6.用于學(xué)習(xí)如何在模擬器中駕駛的深度強(qiáng)化學(xué)習(xí)架構(gòu)。
該算法的目標(biāo)是通過與虛擬環(huán)境交互來自學(xué)駕駛命令。為此目的使用了深度強(qiáng)化學(xué)習(xí)范式,其中深度卷積神經(jīng)網(wǎng)絡(luò) (DNN) 通過提供正獎勵信號的強(qiáng)化動作 a 進(jìn)行訓(xùn)練r(s^‘,a)。狀態(tài)s由模擬器窗口中顯示的當(dāng)前游戲圖像表示。有四種可能的動作:加速、減速、左轉(zhuǎn)和右轉(zhuǎn)。
DNN 計算一個所謂的Q-函數(shù),該函數(shù)預(yù)測要針對特定狀態(tài)執(zhí)行的最優(yōu)動作 a s。換句話說,DNNQ-為每個狀態(tài)-動作對計算一個值。將執(zhí)行具有最高Q-值的操作,這會將模擬器環(huán)境移動到下一個狀態(tài),s’。在這種狀態(tài)下,通過獎勵信號來評估執(zhí)行的動作r(s’,a)。
例如,如果汽車能夠在沒有碰撞的情況下加速,那么使這成為可能的相關(guān)動作將在 DNN 中得到加強(qiáng);否則,它會氣餒。通過使用狀態(tài)獎勵信號重新訓(xùn)練 DNN,在框架中執(zhí)行強(qiáng)化。圖 7 顯示了深度強(qiáng)化學(xué)習(xí)算法的 Caffe 實現(xiàn)。網(wǎng)絡(luò)層具有與圖 6 相同的顏色編碼。
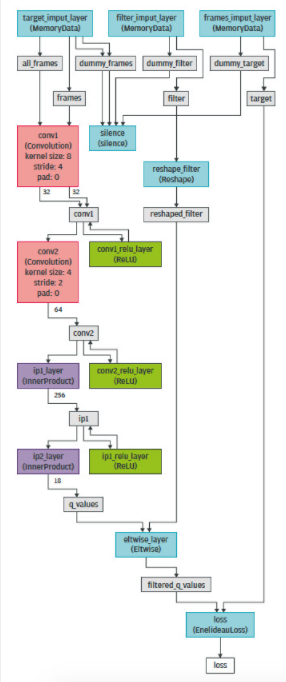
圖 7.用于深度強(qiáng)化學(xué)習(xí)的基于 Caffe 的深度卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。
第二部分定義了機(jī)器學(xué)習(xí)技術(shù)的理論背景,以及汽車開發(fā)人員可用的神經(jīng)網(wǎng)絡(luò)類型。
審核編輯:郭婷
-
汽車電子
+關(guān)注
關(guān)注
3036文章
8296瀏覽量
169886 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4812瀏覽量
103228 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8499瀏覽量
134337
發(fā)布評論請先 登錄
卡車、礦車的自動駕駛和乘用車的自動駕駛在技術(shù)要求上有何不同?
激光雷達(dá)在自動駕駛領(lǐng)域中的優(yōu)勢
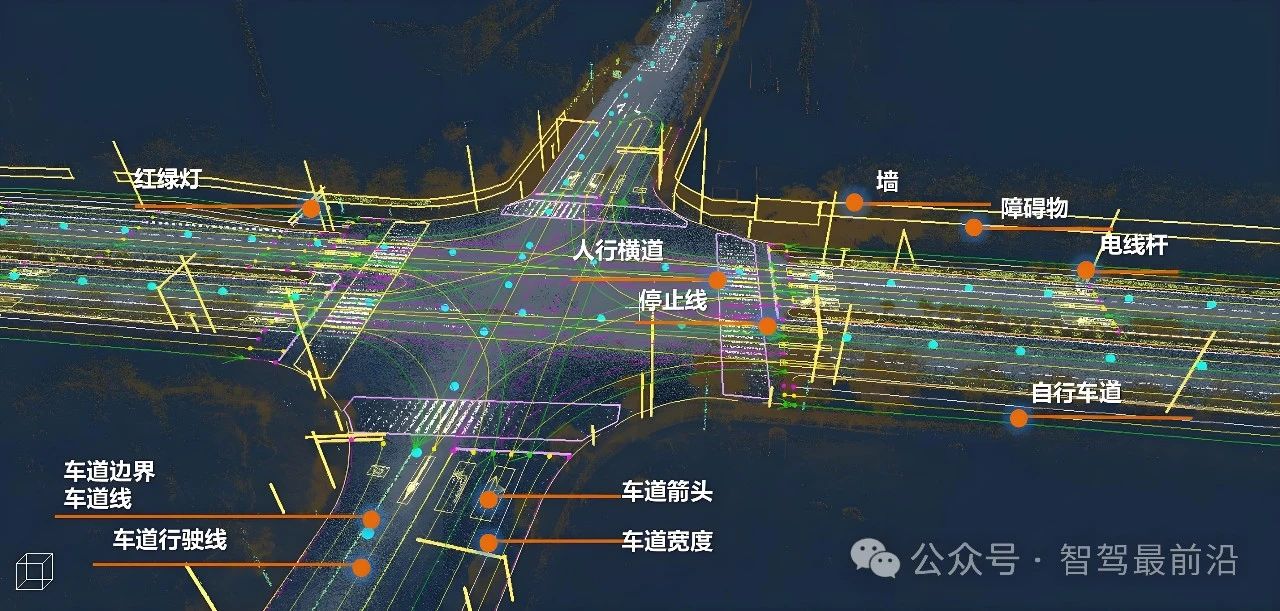
從《自動駕駛地圖數(shù)據(jù)規(guī)范》聊高精地圖在自動駕駛中的重要性
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗】2.具身智能機(jī)器人的基礎(chǔ)模塊
一文聊聊自動駕駛測試技術(shù)的挑戰(zhàn)與創(chuàng)新

新品發(fā)布 | TOSUN正式推出GPS轉(zhuǎn)CAN FD模塊產(chǎn)品,為自動駕駛提供數(shù)據(jù)支持

MEMS技術(shù)在自動駕駛汽車中的應(yīng)用
智能駕駛與自動駕駛的關(guān)系
智能駕駛的挑戰(zhàn)與機(jī)遇
人工智能的應(yīng)用領(lǐng)域有自動駕駛嗎






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論