 C語言和C++到底是什么關系
C語言和C++到底是什么關系
首先C++和C語言本來就是兩種不同的編程語言,但C++確實是對C語言的擴充和延伸,并且對C語言提供后向兼容的能力。對于有些人說的C++完全就包含了C語言的說法也并沒有錯。
C++一開始被本賈尼·斯特勞斯特盧普(Bjarne Stroustrup)發明時,起初被稱為“C with Classes”,即「帶類的C」。
很明顯它是在C語言的基礎上擴充了類class等面向對象的特性和機制。但是后來經過一步步修訂和很多次演變,最終才形成了現如今這個支持一系列重大特性的龐大編程語言。
1、C語言是面向過程語言,而C++是面向對象語言
我們都知道C語言是面向過程語言,而C++是面向對象語言,說C和C++的區別,也就是在比較面向過程和面向對象的區別。
(1)面向過程和面向對象的區別
面向過程:面向過程編程就是分析出解決問題的步驟,然后把這些步驟一步一步的實現,使用的時候一個一個的依次調用就可以了。
面向對象:面向對象編程就是把問題分解成各個對象,建立對象的目的不是為了完成一個步驟,而是為了描述某個事物在整個解決問題的步驟中的行為。
(2)面向過程和面向對象的優缺點
面向過程語言
優點:性能比面向對象高,因為類調用時需要實例化,開銷比較大,比較消耗資源;比如單片機、嵌入式開發、 Linux/Unix等一般采用面向過程開發,性能是最重要的因素。
缺點:沒有面向對象易維護、易復用、易擴展
面向對象語言
優點:易維護、易復用、易擴展,由于面向對象有封裝、繼承、多態性的特性,可以設計出低耦合的系統,使系統更加靈活、更加易于維護
缺點:性能比面向過程低。
二、具體語言上的區別
1、關鍵字的不同
C語言有32個關鍵字;
C++有63個關鍵字;
2、后綴名不同
C源文件后綴.c,C++源文件后綴.cpp,在VS中,如果在創建源文件時什么都不給,默認是.cpp。
3、返回值
C語言中,如果一個函數沒有指定返回值類型,默認返回int類型;C++中,如果一個函數沒有返回值則必須指定為void。
4、參數列表
在C語言中,函數沒有指定參數列表時,默認可以接收任意多個參數;但在C++中,因為嚴格的參數類型檢測,沒有參數列表的函數,默認為 void,不接收任何參數。
5、缺省參數
缺省參數是聲明或定義函數時為函數的參數指定一個默認值。在調用該函數時,如果沒有指定實參則采用該默認值,否則使用指定的參。(C語言不支持缺省參數)
·半缺省參數

·全缺省參數

注意:
·在半缺省的情況下,帶缺省值的參數必須放在參數列表的最后面。
·缺省參數不能同時在函數的聲明和函數定義中出現,二者只能選其一。
·缺省值必須是常量或者全局變量。
·缺省參數必須通過值參或常參傳遞。
6、函數重載
函數重載:函數重載是函數的一種特殊情況,指在同一作用域中,聲明幾個功能類似的同名函數,這些同名函數的形參列表(參數個數、類型、順序)必須不同,返回值類型可以相同也可以不同,常用來處理實現功能類似數據類型不同的問題。(C語言沒有函數重載,C++支持函數重載)。
C語言中產生函數符號的規則是根據名稱產生,這也就注定了c語言不存在函數重載的概念。而C++生成函數符號則考慮了函數名、參數個數、參數類型。需要注意的是函數的返回值并不能作為函數重載的依據,也就是說int sum和double sum這兩個函數是不能構成重載的!
我們的函數重載也屬于多態的一種,這就是所謂的靜多態。
靜多態:函數重載,函數模板
動多態(運行時的多態):繼承中的多態(虛函數)。
使用重載的時候需要注意作用域問題:請看如下代碼。
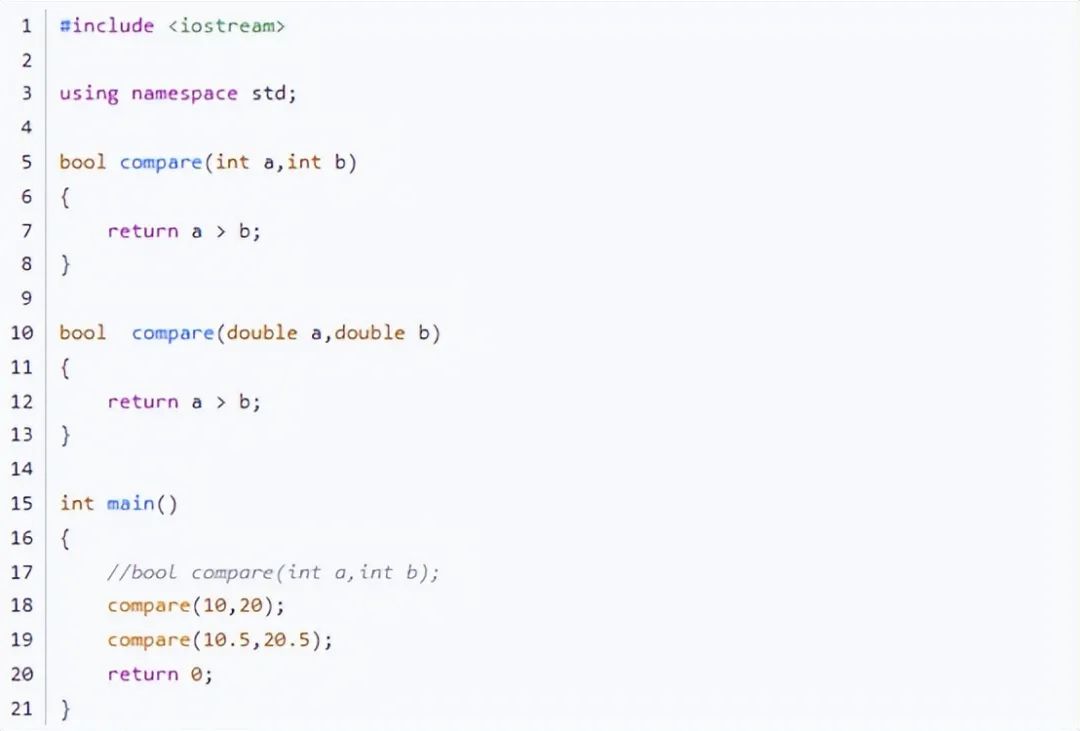
我在全局作用域定義了兩個函數,它們由于參數類型不同可以構成重載,此時main函數中調用則可以正確的調用到各自的函數。
但是請看main函數中被注釋掉的一句代碼。如果將它放出來,則會提出警告:將double類型轉換成int類型可能會丟失數據。
這就意味著我們編譯器針對下面兩句調用都調用了參數類型int的compare。由此可見,編譯器調用函數時優先在局部作用域搜索,若搜索成功則全部按照該函數的標準調用。若未搜索到才在全局作用域進行搜索。
總結:C語言不存在函數重載,C++根據函數名參數個數參數類型判斷重載,屬于靜多態,必須同一作用域下才叫重載。
7、const
C語言中被const修飾的變量不是常量,叫做常變量或者只讀變量,這個常變量是無法當作數組下標的。然而在C++中const修飾的變量可以當作數組下標使用,成為了真正的常量,這就是C++對const的擴展。
C語言中的const:被修飾后不能做左值,可以不初始化,但是之后沒有機會再初始化。不可以當數組的下標,可以通過指針修改。
簡單來說,它和普通變量的區別只是不能做左值而已,其他地方都是一樣的。
C++中的const:真正的常量。定義的時候必須初始化,可以用作數組的下標。const在C++中的編譯規則是替換(和宏很像),所以它被看作是真正的常量。也可以通過指針修改。需要注意的是,C++的指針有可能退化成C語言的指針。比如以下情況:

這時候的a就只是一個普通的C語言的const常變量了,已經無法當數組的下標了。(引用了一個編譯階段不確定的值)
const在生成符號時,是local符號。即在本文件中才可見。如果非要在別的文件中使用它的話,在文件頭部聲明:externcosnt int data = 10;這樣生成的符號就是global符號。
總結:C中的const叫只讀變量,只是無法做左值的變量;C++中的const是真正的常量,但也有可能退化成c語言的常量,默認生成local符號。
8、引用
說到引用,我們第一反應就是想到了他的兄弟:指針。
引用從底層來說和指針就是同一個東西,但是在編譯器中它的特性和指針完全不同。
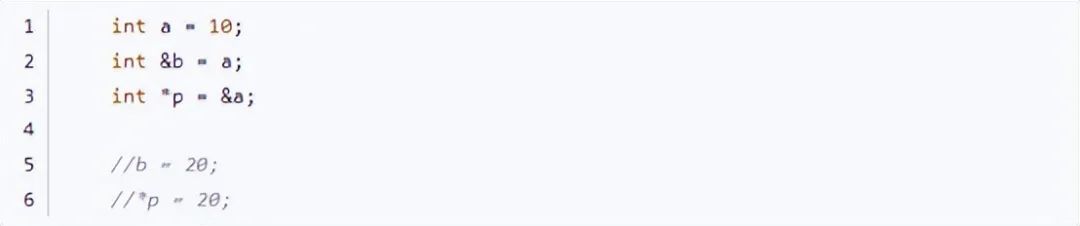
首先定義一個變量a = 10,然后我們分別定義一個引用b以及一個指針p指向a。我們來轉到反匯編看看底層的實現:
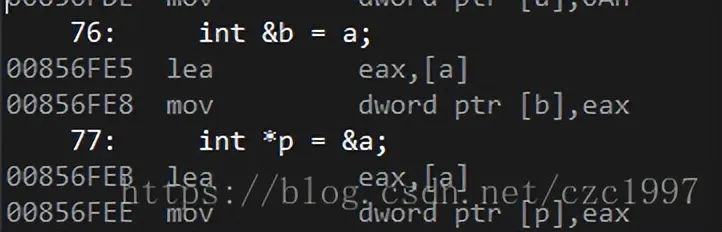
可以看到底層實現完全一致,取a的地址放入eax寄存器,再將eax中的值存入引用b/指針p的內存中。至此我們可以說(在底層)引用本質就是一個指針。
了解了底層實現,我們回到編譯器。我們看到對a的值的修改,指針p的做法是*p = 20;即進行解引用后替換值。
再來看看引用修改:
我們看到修改a的值的方法也是一樣的,也是解引用。只是我們在調用的時候有所不同:調用p時需要*p解引用,b則直接使用就可以。由此我們 推斷出:引用在直接使用時是指針解引用。p直接使用則是它自己的地址。
這樣我們也了解了,我們給引用開辟的這塊內存是根本訪問不到的。如果直接用就直接解引用了。即使打印&b,輸出的也是a的地址。
在此附上將指針轉為引用的小技巧:int *p = &a,我們將 引用符號移到左邊 將 *替換即可:int &p = a。
接下來看看如何創建數組的引用:
intarray[10] = {0};//定義一個數組
我們知道,array拿出來使用的話就是數組array的首元素地址。即是int *類型。
那么&array是什么意思呢?int **類型,用來指向array[0]地址的一個地址嗎?不要想當然了,&array是整個數組類型。
那么要定義一個數組引用,按照上面的小訣竅,先來寫寫數組指針吧:
int(*q) [10] = &array;
將右側的&對左邊的*進行覆蓋:
int(&q)[10] = array;
測試sizeof(q) = 10。我們成功創建了數組引用。
經過上面的詳解,我們知道了引用其實就是取地址。那么我們都知道一個立即數是沒有地址的,即
int&b = 10;
這樣的代碼是無法通過編譯的。那如果你就是非要引用一個立即數,其實也不是沒有辦法:
constint &b = 10;
即將這個立即數用const修飾一下,就可以了。為什么呢?
這時因為被const修飾的都會產生一個臨時量來保存這個數據,自然就有地址可取了。
9、malloc,free && new,delete
這個問題很有意思,也是重點需要關注的問題。malloc()和free()是C語言中動態申請內存和釋放內存的標準庫中的函數。而new和delete是C++運算符、關鍵字。new和delete底層其實還是調用了malloc和free。它們之間的區別有以下幾個方面:
1)、malloc和free是函數,new和delete是運算符。
2)、malloc在分配內存前需要大小,new不需要。
例如:
int *p1 = (int *)malloc(sizeof(int));int *p2 = new int; //int *p3 = new int(10);
malloc時需要指定大小,還需要類型轉換。new時不需要指定大小因為它可以從給出的類型判斷,并且還可以同時賦初始值。
3)、malloc不安全,需要手動類型轉換,new不需要類型轉換。
4)、free只釋放空間,delete先調用析構函數再釋放空間(如果需要)。
與第⑤條對應,如果使用了復雜類型,先析構再call operator delete回收內存。
5)、new是先調用構造函數再申請空間(如果需要)。
與第④條對應,我們在調用new的時候(例如int *p2 = new int;這句代碼 ),底層代碼的實現是:首先push 4字節(int類型的大小),隨后call operator new函數分配了內存。由于我們這句代碼并未涉及到復雜類型(如類類型),所以也就沒有構造函數的調用。如下是operator new的源代碼,也是new實現的重要函數:

我們可以看到,首先malloc(size)申請參數字節大小的內存,如果失敗(malloc失敗返回0)則進入判斷:如果_callnewh(size)也失敗的話,拋出bad_alloc異常。_callnewh()這個函數是在查看new handler是否可用,如果可用會釋放一部分內存再返回到malloc處繼續申請,如果new handler不可用就會拋出異常。
6)、內存不足(開辟失敗)時處理方式不同。
malloc失敗返回0,new失敗拋出bad_alloc異常。
7)、new和malloc開辟內存的位置不同。
malloc開辟在堆區,new開辟在自由存儲區域。
8)、new可以調用malloc(),但malloc不能調用new。
new就是用malloc()實現的,new是C++獨有malloc當然無法調用。
10、作用域
C語言中作用域只有兩個:局部,全局。C++中則是有:局部作用域,類作用域,名字空間作用域三種。
所謂名字空間就是namespace,我們定義一個名字空間就是定義一個新作用域。訪問時需要以如下方式訪問(以std為例)
std::cin<<"123" <<std::endl;
例如我們有一個名字空間叫Myname,其中有一個變量叫做data。如果我們希望在其他地方使用data的話,需要在文件頭聲明:using Myname::data;這樣一來data就使用的是Myname中的值了。可是這樣每個符號我們都得聲明豈不是累死?
我們只要using namespace Myname;就可以將其中所有符號導入了。
這也就是我們經常看到的using namespace std;的意思啦。
不學C語言能直接學C++嗎?
還是像前面所說,C++編程語言的第一大重要組成部分就是「面向過程編程」,而這正是C語言老大哥的領域。即使沒有學過C語言,一上來就直接學習C++的小伙伴,應該也難逃『面向過程』這一部分的內容。
從理論上來說,學C++前并不一定非得學C語言,但是有C語言底子再去學C++往往更具優勢,最起碼「面向過程編程」這一部分內容能夠輕車熟路。
原文標題:不學C語言能直接學C++嗎?
文章出處:【微信公眾號:一口Linux】歡迎添加關注!文章轉載請注明出處。
-
C語言
+關注
關注
180文章
7604瀏覽量
136685 -
編程語言
+關注
關注
10文章
1942瀏覽量
34707 -
C++
+關注
關注
22文章
2108瀏覽量
73618
原文標題:不學C語言能直接學C++嗎?
文章出處:【微信號:yikoulinux,微信公眾號:一口Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
同樣是函數,在C和C++中有什么區別
MCU編程語言和開發環境介紹
TLV320AIC3254內部中的ADC處理模塊和minidsp到底是什么關系?
C語言與Java語言的對比
TMS320LF240x DSP的C語言和匯編代碼快速入門

PLC編程語言和C語言的區別
為什么很少用C++開發單片機
plc編程語言與c語言的聯系 c語言和PLC有什么區別
光耦怎么用?光耦的輸入和輸出到底是什么關系?
C++簡史:C++是如何開始的






 工商網監
工商網監
評論