 計算機視覺的網絡結構又要迎來革新了?
計算機視覺的網絡結構又要迎來革新了?
【導讀】最近,中科院軟件所等四個機構的研究團隊將CV與圖神經網絡結合起來,提出全新模型ViG,在等量參數情況下,性能超越ViT,可解釋性也有所提升。
從卷積神經網絡到帶注意力機制的視覺Transformer,神經網絡模型都是把輸入圖像視為一個網格或是patch序列,但這種方式無法捕捉到變化的或是復雜的物體。
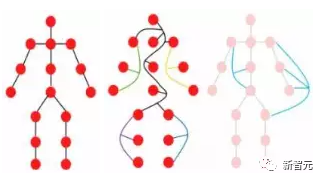
比如人在觀察圖片的時候,就會很自然地就將整個圖片分為多個物體,并在物體間建立空間等位置關系,也就是說整張圖片對于人腦來說實際上是一張graph,物體則是graph上的節點。
最近中科院軟件研究所、華為諾亞方舟實驗室、北京大學、澳門大學的研究人員聯合提出了一個全新的模型架構Vision GNN (ViG),能夠從圖像中抽取graph-level的特征用于視覺任務。

論文鏈接:https://arxiv.org/pdf/2206.00272.pdf
首先需要將圖像分割成若干個patch作為圖中的節點,并通過連接最近的鄰居patch構建一個graph,然后使用ViG模型對整個圖中所有節點的信息進行變換(transform)和交換(exchange)。
ViG 由兩個基本模塊組成,Grapher模塊用graph卷積來聚合和更新圖形信息,FFN模塊用兩個線性層來變換節點特征。
在圖像識別和物體檢測任務上進行的實驗也證明了ViG架構的優越性,GNN在一般視覺任務上的開創性研究將為未來的研究提供有益的啟發和經驗。
論文作者為吳恩華教授,中國科學院軟件研究所博士生導師、澳門大學名譽教授,1970年本科畢業于清華大學工程力學數學系,1980年博士畢業于英國曼徹斯特大學計算機科學系。主要研究領域為計算機圖形學與虛擬現實, 包括:虛擬現實 、真實感圖形生成、基于物理的仿真與實時計算、基于物理的建模與繪制、圖像與視頻的處理與建模、視覺計算與機器學習。
視覺GNN
網絡結構往往是提升性能最關鍵的要素,只要能保證數據量的數量和質量,把模型從CNN換到ViT,就能得到一個性能更佳的模型。
但不同的網絡對待輸入圖像的處理方式也不同,CNN在圖像上滑動窗口,引入平移不變性和局部特征。
而ViT和多層感知機(MLP)則是將圖像轉換為一個patch序列,比如把224×224的圖像分成若干個16×16的patch,最后形成一個長度為196的輸入序列。
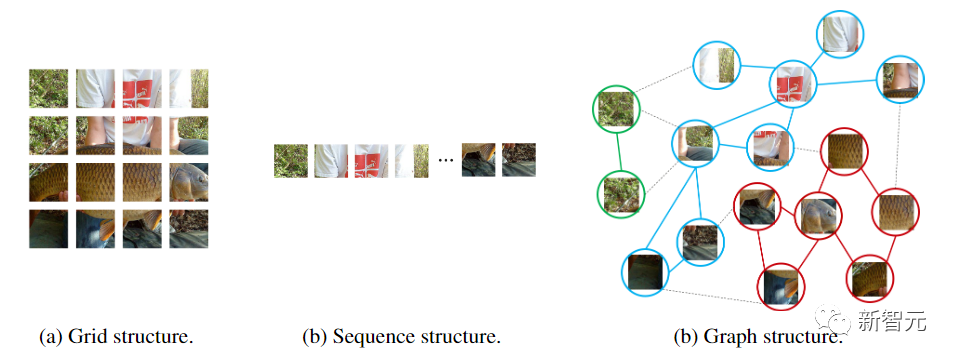
圖神經網絡則更加靈活,比如在計算機視覺中,一個基本任務是識別圖像中的物體。由于物體通常不是四邊形的,可能是不規則的形狀,所以之前的網絡如ResNet和ViT中常用的網格或序列結構是多余的,處理起來不靈活。
一個物體可以被看作是由多個部分組成的,例如,一個人可以大致分為頭部、上半身、胳膊和腿。
這些由關節連接的部分很自然地形成了一個圖形結構,通過分析圖,我們最后才能夠識別出這個物體可能是個人類。
此外,圖是一種通用的數據結構,網格和序列可以被看作是圖的一個特例。將圖像看作是一個圖,對于視覺感知來說更加靈活和有效。
使用圖結構需要將輸入的圖像劃分為若干個patch,并將每個patch視為一個節點,如果將每個像素視為一個節點的話就會導致圖中節點數量過多(>10K)。
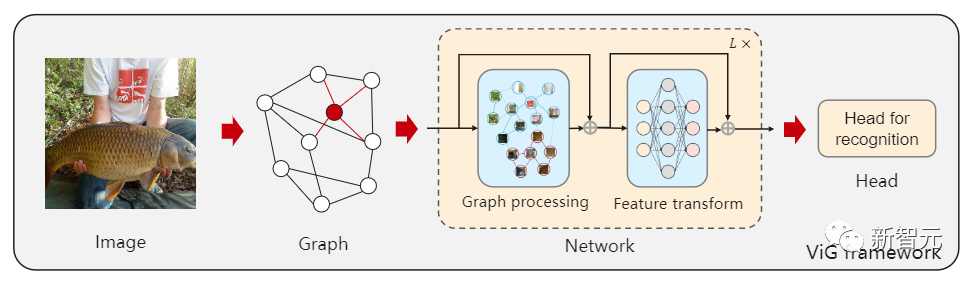
建立graph后,首先通過一個圖卷積神經網絡(GCN)聚合相鄰節點間的特征,并抽取圖像的表征。
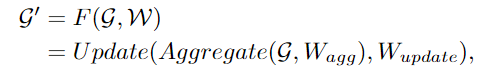
為了讓GCN獲取更多樣性的特征,作者將圖卷積應用multi-head操作,聚合的特征由不同權重的head進行更新,最后級聯為圖像表征。
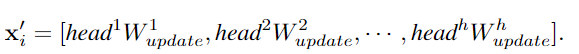
以前的GCN通常重復使用幾個圖卷積層來提取圖數據的聚合特征,而深度GCN中的過度平滑現象則會降低節點特征的獨特性,導致視覺識別的性能下降。
為了緩解這個問題,研究人員在ViG塊中引入了更多的特征轉換和非線性激活函數。
首先在圖卷積的前后應用一個線性層,將節點特征投射到同一域中,增加特征多樣性。在圖形卷積之后插入一個非線性激活函數以避免層崩潰。
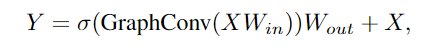
為了進一步提高特征轉換能力,緩解過度平滑現象,還需要在每個節點上利用前饋網絡(FFN)。FFN模塊是一個簡單的多層感知機,有兩個全連接的層。
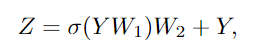
在Grapher和FFN模塊中,每一個全連接層或圖卷積層之后都要進行batch normalization,Grapher模塊和FFN模塊的堆疊構成了一個ViG塊,也是構建大網絡的基本單元。
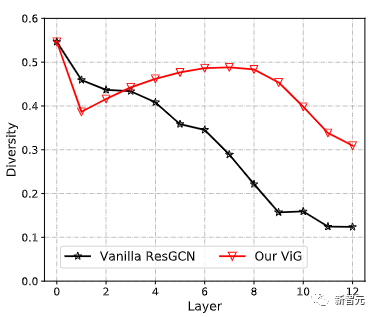
與原始的ResGCN相比,新提出的ViG可以保持特征的多樣性,隨著加入更多的層,網絡也可以學習到更強的表征。
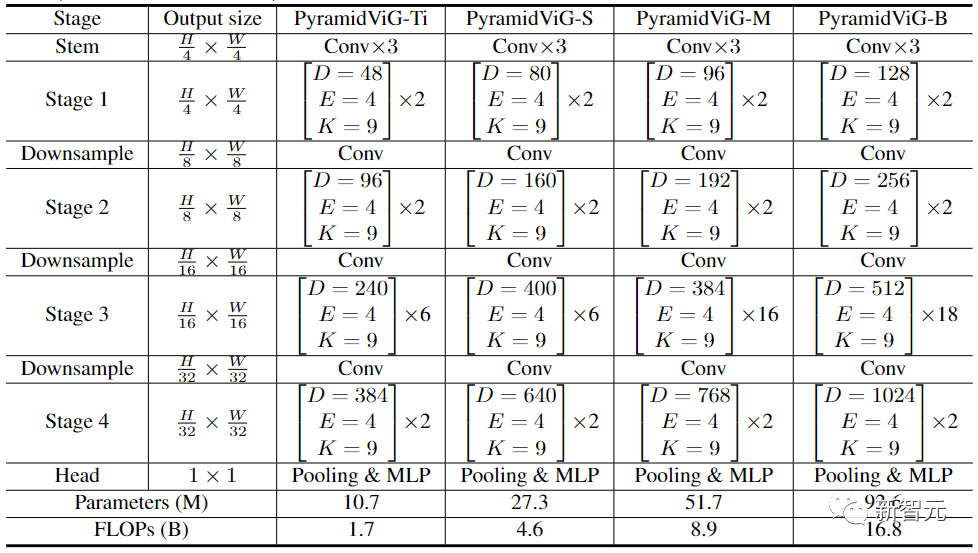
在計算機視覺的網絡架構中,常用的Transformer模型通常有一個等向性(Isotropic)的結構(如ViT),而CNN更傾向于使用金字塔結構(如ResNet)。
為了與其他類型的神經網絡進行比較,研究人員為ViG同時建立了等向性和金字塔的兩種網絡架構。
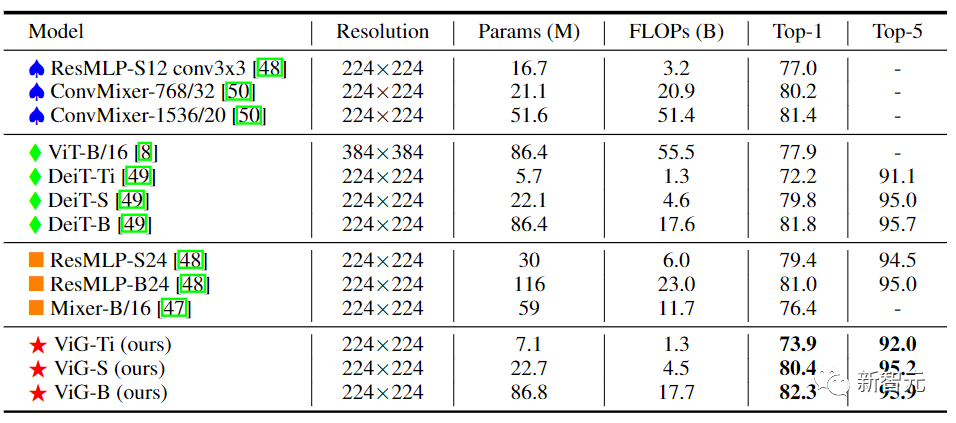
在實驗對比階段,研究人員選擇了圖像分類任務中的ImageNet ILSVRC 2012數據集,包含1000個類別,120M的訓練圖像和50K的驗證圖像。
目標檢測任務中,選擇了有80個目標類別的COCO 2017數據集,包含118k個訓練圖片和5000個驗證集圖片。

在等向性的ViG架構中,其主要計算過程中可以保持特征大小不變,易于擴展,對硬件加速友好。在將其與現有的等向性的CNN、Transformer和MLP進行比較后可以看到,ViG比其他類型的網絡表現得更好。其中ViG-Ti實現了73.9%的top-1準確率,比DeiT-Ti模型高1.7%,而計算成本相似。
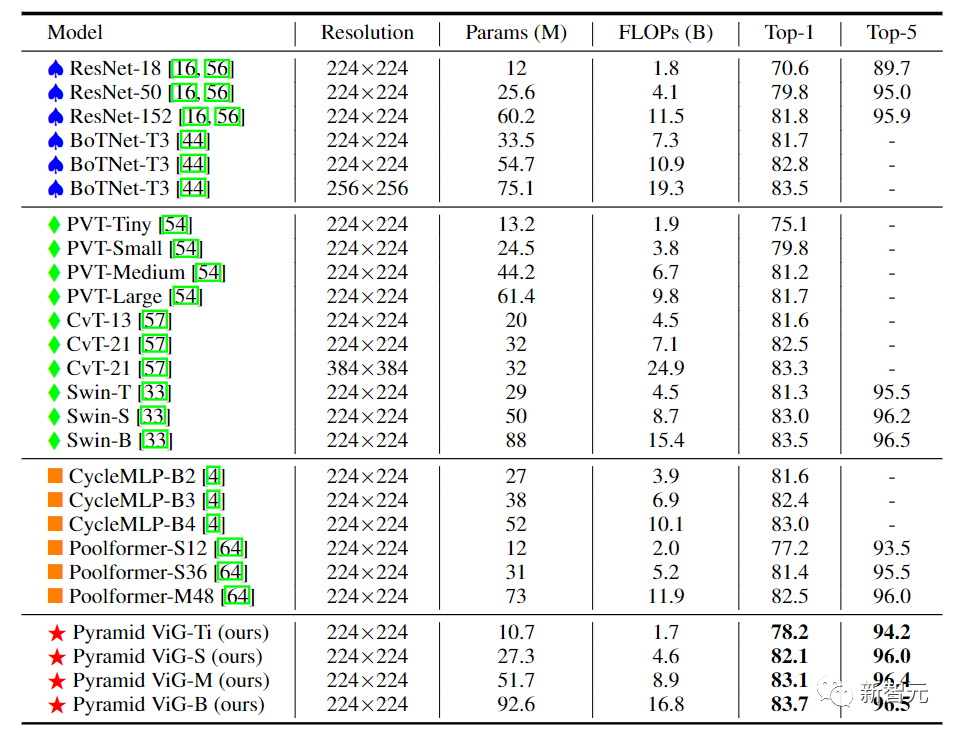
金字塔結構的ViG中,隨著網絡的加深逐漸縮小了特征圖的空間大小,利用圖像的尺度不變量特性,同時產生多尺度的特征。
高性能的網絡大多采用金字塔結構,如ResNet、Swin Transformer和CycleMLP。在將Pyramid ViG與這些有代表性的金字塔網絡進行比較后,可以看到Pyramid ViG系列可以超越或媲美最先進的金字塔網絡包括CNN、MLP和Transfomer。
結果表明,圖神經網絡可以很好地完成視覺任務,并有可能成為計算機視覺系統中的一個基本組成部分。
為了更好地理解ViG模型的工作流程,研究人員將ViG-S中構建的圖結構可視化。在兩個不同深度的樣本(第1和第12塊)的圖。五角星是中心節點,具有相同顏色的節點是其鄰居。只有兩個中心節點是可視化的,因為如果繪制所有的邊會顯得很亂。

可以觀察到,ViG模型可以選擇與內容相關的節點作為第一階鄰居。在淺層,鄰居節點往往是根據低層次和局部特征來選擇的,如顏色和紋理。在深層,中心節點的鄰居更具語義性,屬于同一類別。 ViG網絡可以通過其內容和語義表征逐漸將節點聯系起來,幫助更好地識別物體。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100720 -
模型
+關注
關注
1文章
3229瀏覽量
48812 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45980
原文標題:CV的未來是圖神經網絡?中科院軟件所發布全新CV模型ViG,性能超越ViT
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機視覺有哪些優缺點
計算機視覺技術的AI算法模型
計算機視覺的五大技術
計算機視覺的工作原理和應用
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
深度學習在計算機視覺領域的應用
機器視覺與計算機視覺的區別
計算機視覺的主要研究方向
計算機視覺的十大算法






 工商網監
工商網監
評論