

導讀
你應該知道的18個PyTorch小技巧。
你為什么要讀這篇文章?
深度學習模型的訓練/推理過程涉及很多步驟。在有限的時間和資源條件下,每個迭代的速度越快,整個模型的預測性能就越快。我收集了幾個PyTorch技巧,以最大化內存使用效率和最小化運行時間。為了更好地利用這些技巧,我們還需要理解它們如何以及為什么有效。
我首先提供一個完整的列表和一些代碼片段,這樣你就可以開始優化你的腳本了。然后我一個一個地詳細地研究它們。對于每個技巧,我還提供了代碼片段和注釋,告訴你它是特定于設備類型(CPU/GPU)還是模型類型。
列表:
-
數據加載
1、把數據放到SSD中
2、
Dataloader(dataset, num_workers=4*num_GPU)3、
Dataloader(dataset, pin_memory=True) -
數據操作
4、直接在設備中創建
torch.Tensor,不要在一個設備中創建再移動到另一個設備中5、避免CPU和GPU之間不必要的數據傳輸
6、使用
torch.from_numpy(numpy_array)或者torch.as_tensor(others)7、在數據傳輸操作可以重疊時,使用
tensor.to(non_blocking=True)8、使用PyTorch JIT將元素操作融合到單個kernel中。
-
模型結構
9、在使用混合精度的FP16時,對于所有不同架構設計,設置尺寸為8的倍數
-
訓練
10、將batch size設置為8的倍數,最大化GPU內存的使用
11、前向的時候使用混合精度(后向的使用不用)
12、在優化器更新權重之前,設置梯度為
None,model.zero_grad(set_to_none=True)13、梯度積累:每隔x個batch更新一次權重,模擬大batch size的效果
-
推理/驗證
14、關閉梯度計算
-
CNN (卷積神經網絡) 特有的
15、
torch.backends.cudnn.benchmark = True16、對于4D NCHW Tensors,使用channels_last的內存格式
17、在batch normalization之前的卷積層可以去掉bias
-
分布式
18、用
DistributedDataParallel代替DataParallel
第7、11、12、13的代碼片段
#CombiningthetipsNo.7,11,12,13:nonblocking,AMP,setting
#gradientsasNone,andlargereffectivebatchsize
model.train()
#ResetthegradientstoNone
optimizer.zero_grad(set_to_none=True)
scaler=GradScaler()
fori,(features,target)inenumerate(dataloader):
#thesetwocallsarenonblockingandoverlapping
features=features.to('cuda:0',non_blocking=True)
target=target.to('cuda:0',non_blocking=True)
#Forwardpasswithmixedprecision
withtorch.cuda.amp.autocast():#autocastasacontextmanager
output=model(features)
loss=criterion(output,target)
#Backwardpasswithoutmixedprecision
#It'snotrecommendedtousemixedprecisionforbackwardpass
#Becauseweneedmorepreciseloss
scaler.scale(loss).backward()
#Onlyupdateweightseveryother2iterations
#Effectivebatchsizeisdoubled
if(i+1)%2==0or(i+1)==len(dataloader):
#scaler.step()firstunscalesthegradients.
#IfthesegradientscontaininfsorNaNs,
#optimizer.step()isskipped.
scaler.step(optimizer)
#Ifoptimizer.step()wasskipped,
#scalingfactorisreducedbythebackoff_factor
#inGradScaler()
scaler.update()
#ResetthegradientstoNone
optimizer.zero_grad(set_to_none=True)
指導思想
總的來說,你可以通過3個關鍵點來優化時間和內存使用。首先,盡可能減少i/o(輸入/輸出),使模型管道更多的用于計算,而不是用于i/o(帶寬限制或內存限制)。這樣,我們就可以利用GPU及其他專用硬件來加速這些計算。第二,盡量重疊過程,以節省時間。第三,最大限度地提高內存使用效率,節約內存。然后,節省內存可以啟用更大的batch size大小,從而節省更多的時間。擁有更多的時間有助于更快的模型開發周期,并導致更好的模型性能。
1、把數據移動到SSD中
有些機器有不同的硬盤驅動器,如HHD和SSD。建議將項目中使用的數據移動到SSD(或具有更好i/o的硬盤驅動器)以獲得更快的速度。
2. 在加載數據和數據增強的時候異步處理
num_workers=0使數據加載需要在訓練完成后或前一個處理已完成后進行。設置num_workers>0有望加快速度,特別是對于大數據的i/o和增強。具體到GPU,有實驗發現num_workers = 4*num_GPU 具有最好的性能。也就是說,你也可以為你的機器測試最佳的num_workers。需要注意的是,高num_workers將會有很大的內存消耗開銷,這也是意料之中的,因為更多的數據副本正在內存中同時處理。
Dataloader(dataset,num_workers=4*num_GPU)
3. 使用pinned memory來降低數據傳輸
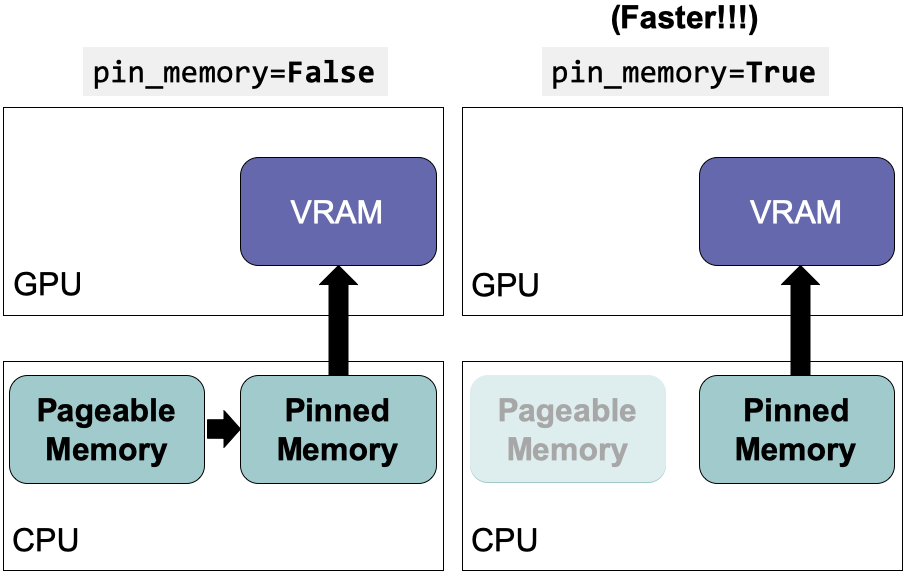
GPU無法直接從CPU的可分頁內存中訪問數據。設置pin_memory=True 可以為CPU主機上的數據直接分配臨時內存,節省將數據從可分頁內存轉移到臨時內存(即固定內存又稱頁面鎖定內存)的時間。該設置可以與num_workers = 4*num_GPU結合使用。
Dataloader(dataset,pin_memory=True)
4. 直接在設備中創建張量
只要你需要torch.Tensor,首先嘗試在要使用它們的設備上創建它們。不要使用原生Python或NumPy創建數據,然后將其轉換為torch.Tensor。在大多數情況下,如果你要在GPU中使用它們,直接在GPU中創建它們。
#Randomnumbersbetween0and1
#Sameasnp.random.rand([10,5])
tensor=torch.rand([10,5],device=torch.device('cuda:0'))
#Randomnumbersfromnormaldistributionwithmean0andvariance1
#Sameasnp.random.randn([10,5])
tensor=torch.randn([10,5],device=torch.device('cuda:0'))
唯一的語法差異是NumPy中的隨機數生成需要額外的random,例如:np.random.rand() vs torch.rand()。許多其他函數在NumPy中也有相應的函數:
torch.empty(),torch.zeros(),torch.full(),torch.ones(),torch.eye(),torch.randint(),torch.rand(),torch.randn()
5. 避免在CPU和GPU中傳輸數據
正如我在指導思想中提到的,我們希望盡可能地減少I/O。注意下面這些命令:
#BAD!AVOIDTHEMIFUNNECESSARY!
print(cuda_tensor)
cuda_tensor.cpu()
cuda_tensor.to_device('cpu')
cpu_tensor.cuda()
cpu_tensor.to_device('cuda')
cuda_tensor.item()
cuda_tensor.numpy()
cuda_tensor.nonzero()
cuda_tensor.tolist()
#PythoncontrolflowwhichdependsonoperationresultsofCUDAtensors
if(cuda_tensor!=0).all():
run_func()
6. 使用 torch.from_numpy(numpy_array)和torch.as_tensor(others)代替 torch.tensor
torch.tensor()會拷貝數據
如果源設備和目標設備都是CPU,torch.from_numpy和torch.as_tensor不會創建數據拷貝。如果源數據是NumPy數組,使用torch.from_numpy(numpy_array) 會更快。如果源數據是一個具有相同數據類型和設備類型的張量,那么torch.as_tensor(others) 可以避免拷貝數據。others 可以是Python的list, tuple,或者torch.tensor。如果源設備和目標設備不同,那么我們可以使用下一個技巧。
torch.from_numpy(numpy_array)
torch.as_tensor(others)
7. 在數據傳輸有重疊時使用tensor.to(non_blocking=True)
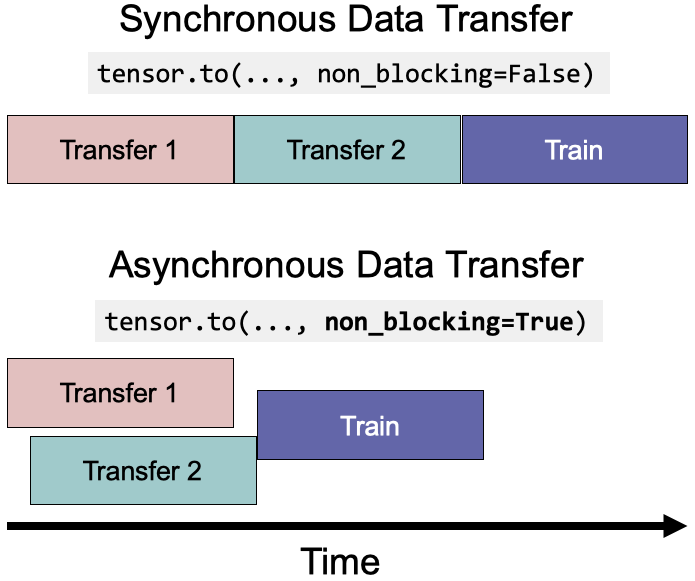
本質上,non_blocking=True允許異步數據傳輸以減少執行時間。
forfeatures,targetinloader:
#thesetwocallsarenonblockingandoverlapping
features=features.to('cuda:0',non_blocking=True)
target=target.to('cuda:0',non_blocking=True)
#Thisisasynchronizationpoint
#Itwillwaitforprevioustwolines
output=model(features)
8. 使用PyTorch JIT將點操作融合到單個kernel中
點操作包括常見的數學操作,通常是內存受限的。PyTorch JIT會自動將相鄰的點操作融合到一個內核中,以保存多次內存讀/寫操作。例如,通過將5個核融合成1個核,gelu函數可以被加速4倍。
@torch.jit.script#JITdecorator
deffused_gelu(x):
returnx*0.5*(1.0+torch.erf(x/1.41421))
9 & 10. 在使用混合精度的FP16時,對于所有不同架構設計,設置圖像尺寸和batch size為8的倍數
為了最大限度地提高GPU的計算效率,最好保證不同的架構設計(包括神經網絡的輸入輸出尺寸/維數/通道數和batch size大小)是8的倍數甚至更大的2的冪(如64、128和最大256)。這是因為當矩陣的維數與2的冪倍數對齊時,Nvidia gpu的張量核心(Tensor Cores)在矩陣乘法方面可以獲得最佳性能。矩陣乘法是最常用的操作,也可能是瓶頸,所以它是我們能確保張量/矩陣/向量的維數能被2的冪整除的最好方法(例如,8、64、128,最多256)。
這些實驗顯示設置輸出維度和batch size大小為8的倍數,比如(33712、4088、4096)相比33708,batch size為4084或者4095這些不能被8整除的數可以加速計算1.3倍到 4倍。加速度大小取決于過程類型(例如,向前傳遞或梯度計算)和cuBLAS版本。特別是,如果你使用NLP,請記住檢查輸出維度,這通常是詞匯表大小。
使用大于256的倍數不會增加更多的好處,但也沒有害處。這些設置取決于cuBLAS和cuDNN版本以及GPU架構。你可以在文檔中找到矩陣維數的特定張量核心要求。由于目前PyTorch AMP多使用FP16,而FP16需要8的倍數,所以通常推薦使用8的倍數。如果你有更高級的GPU,比如A100,那么你可以選擇64的倍數。如果你使用的是AMD GPU,你可能需要檢查AMD的文檔。
除了將batch size大小設置為8的倍數外,我們還將batch size大小最大化,直到它達到GPU的內存限制。這樣,我們可以用更少的時間來完成一個epoch。
11. 在前向中使用混合精度后向中不使用
有些操作不需要float64或float32的精度。因此,將操作設置為較低的精度可以節省內存和執行時間。對于各種應用,英偉達報告稱具有Tensor Cores的GPU的混合精度可以提高3.5到25倍的速度。
值得注意的是,通常矩陣越大,混合精度加速度越高。在較大的神經網絡中(例如BERT),實驗表明混合精度可以加快2.75倍的訓練,并減少37%的內存使用。具有Volta, Turing, Ampere或Hopper架構的較新的GPU設備(例如,T4, V100, RTX 2060, 2070, 2080, 2080 Ti, A100, RTX 3090, RTX 3080,和RTX 3070)可以從混合精度中受益更多,因為他們有Tensor Core架構,它相比CUDA cores有特殊的優化。

值得一提的是,采用Hopper架構的H100預計將于2022年第三季度發布,支持FP8 (float8)。PyTorch AMP可能會支持FP8(目前v1.11.0還不支持FP8)。
在實踐中,你需要在模型精度性能和速度性能之間找到一個最佳點。我之前確實發現混合精度可能會降低模型的精度,這取決于算法,數據和問題。
使用自動混合精度(AMP)很容易在PyTorch中利用混合精度。PyTorch中的默認浮點類型是float32。AMP將通過使用float16來進行一組操作(例如,matmul, linear, conv2d)來節省內存和時間。AMP會自動cast到float32的一些操作(例如,mse_loss, softmax等)。有些操作(例如add)可以操作最寬的輸入類型。例如,如果一個變量是float32,另一個變量是float16,那么加法結果將是float32。
autocast自動應用精度到不同的操作。因為損失和梯度是按照float16精度計算的,當它們太小時,梯度可能會“下溢”并變成零。GradScaler通過將損失乘以一個比例因子來防止下溢,根據比例損失計算梯度,然后在優化器更新權重之前取消梯度的比例。如果縮放因子太大或太小,并導致inf或NaN,則縮放因子將在下一個迭代中更新縮放因子。
scaler=GradScaler()
forfeatures,targetindata:
#Forwardpasswithmixedprecision
withtorch.cuda.amp.autocast():#autocastasacontextmanager
output=model(features)
loss=criterion(output,target)
#Backwardpasswithoutmixedprecision
#It'snotrecommendedtousemixedprecisionforbackwardpass
#Becauseweneedmorepreciseloss
scaler.scale(loss).backward()
#scaler.step()firstunscalesthegradients.
#IfthesegradientscontaininfsorNaNs,
#optimizer.step()isskipped.
scaler.step(optimizer)
#Ifoptimizer.step()wasskipped,
#scalingfactorisreducedbythebackoff_factorinGradScaler()
scaler.update()
你也可以使用autocast 作為前向傳遞函數的裝飾器。
classAutocastModel(nn.Module):
...
@autocast()#autocastasadecorator
defforward(self,input):
x=self.model(input)
returnx
12. 在優化器更新權重之前將梯度設置為None
通過model.zero_grad()或optimizer.zero_grad()將對所有參數執行memset ,并通過讀寫操作更新梯度。但是,將梯度設置為None將不會執行memset,并且將使用“只寫”操作更新梯度。因此,設置梯度為None更快。
#Resetgradientsbeforeeachstepofoptimizer
forparaminmodel.parameters():
param.grad=None
#or(PyTorch>=1.7)
model.zero_grad(set_to_none=True)
#or(PyTorch>=1.7)
optimizer.zero_grad(set_to_none=True)
13. 梯度累積:每隔x個batch再更新梯度,模擬大batch size
這個技巧是關于從更多的數據樣本積累梯度,以便對梯度的估計更準確,權重更新更接近局部/全局最小值。這在batch size較小的情況下更有幫助(由于GPU內存限制較小或每個樣本的數據量較大)。
fori,(features,target)inenumerate(dataloader):
#Forwardpass
output=model(features)
loss=criterion(output,target)
#Backwardpass
loss.backward()
#Onlyupdateweightseveryother2iterations
#Effectivebatchsizeisdoubled
if(i+1)%2==0or(i+1)==len(dataloader):
#Updateweights
optimizer.step()
#ResetthegradientstoNone
optimizer.zero_grad(set_to_none=True)
14. 在推理和驗證的時候禁用梯度計算
實際上,如果只計算模型的輸出,那么梯度計算對于推斷和驗證步驟并不是必需的。PyTorch使用一個中間內存緩沖區來處理requires_grad=True變量中涉及的操作。因此,如果我們知道不需要任何涉及梯度的操作,通過禁用梯度計算來進行推斷/驗證,就可以避免使用額外的資源。
#torch.no_grad()asacontextmanager:
withtorch.no_grad():
output=model(input)
#torch.no_grad()asafunctiondecorator:
@torch.no_grad()
defvalidation(model,input):
output=model(input)
returnoutput
15. torch.backends.cudnn.benchmark = True
在訓練循環之前設置torch.backends.cudnn.benchmark = True可以加速計算。由于計算不同內核大小卷積的cuDNN算法的性能不同,自動調優器可以運行一個基準來找到最佳算法。當你的輸入大小不經常改變時,建議開啟這個設置。如果輸入大小經常改變,那么自動調優器就需要太頻繁地進行基準測試,這可能會損害性能。它可以將向前和向后傳播速度提高1.27x到1.70x。
torch.backends.cudnn.benchmark=True
16. 對于4D NCHW Tensors使用通道在最后的內存格式

使用channels_last內存格式以逐像素的方式保存圖像,作為內存中最密集的格式。原始4D NCHW張量在內存中按每個通道(紅/綠/藍)順序存儲。轉換之后,x = x.to(memory_format=torch.channels_last),數據在內存中被重組為NHWC (channels_last格式)。你可以看到RGB層的每個像素更近了。據報道,這種NHWC格式與FP16的AMP一起使用可以獲得8%到35%的加速。
目前,它仍處于beta測試階段,僅支持4D NCHW張量和一組模型(例如,alexnet,mnasnet家族,mobilenet_v2,resnet家族,shufflenet_v2,squeezenet1,vgg家族)。但我可以肯定,這將成為一個標準的優化。
N,C,H,W=10,3,32,32
x=torch.rand(N,C,H,W)
#Strideisthegapbetweenoneelementtothenextone
#inadimension.
print(x.stride())
#(3072,1024,32,1)#ConvertthetensortoNHWCinmemory
x2=x.to(memory_format=torch.channels_last)
print(x2.shape)#(10,3,32,32)asdimensionsorderpreserved
print(x2.stride())#(3072,1,96,3),whicharesmaller
print((x==x2).all())#Truebecausethevalueswerenotchanged
17. 在batch normalization之前禁用卷積層的bias
這是可行的,因為在數學上,bias可以通過batch normalization的均值減法來抵消。我們可以節省模型參數、運行時的內存。
nn.Conv2d(...,bias=False)
18. 使用 DistributedDataParallel代替DataParallel
對于多GPU來說,即使只有單個節點,也總是優先使用 DistributedDataParallel而不是 DataParallel ,因為 DistributedDataParallel 應用于多進程,并為每個GPU創建一個進程,從而繞過Python全局解釋器鎖(GIL)并提高速度。
總結
在這篇文章中,我列出了一個清單,并提供了18個PyTorch技巧的代碼片段。然后,我逐一解釋了它們在不同方面的工作原理和原因,包括數據加載、數據操作、模型架構、訓練、推斷、cnn特定的優化和分布式計算。一旦你深入理解了它們的工作原理,你可能會找到適用于任何深度學習框架中的深度學習建模的通用原則。
審核編輯 :李倩
-
cpu
+關注
關注
68文章
11030瀏覽量
215876 -
代碼
+關注
關注
30文章
4886瀏覽量
70219 -
pytorch
+關注
關注
2文章
809瀏覽量
13754
原文標題:優化PyTorch的速度和內存效率(2022)
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
利用Arm Kleidi技術實現PyTorch優化

PyTorch 數據加載與處理方法

【電磁兼容標準解析分享】汽車電子零部件EMC標準解析---你應該了解和知道的細節(二)






 工商網監
工商網監

評論