 AUTO插件和自動批處理的最佳實踐
AUTO插件和自動批處理的最佳實踐
1.1 概述
OpenVINO 2022.1是自OpenVINO工具套件2018年首次發布以來最大的更新之一,參見《OpenVINO 迎來迄今為止最重大更新,2022.1新特性搶先看!》。在眾多新特性中,AUTO插件和自動批處理(Automatic-Batching)是最重要的新特性之一,它幫助開發者無需復雜的編程即可提高推理計算的性能和效率。
1.1.1 什么是AUTO插件?
AUTO插件1 ,全稱叫自動設備選擇(Automatic device selection),它是一個構建在CPU/GPU插件之上的虛擬插件,如圖1-1所示。在OpenVINO 文檔中,“設備(device)”是指用于推理計算的 Intel 處理器,它可以是受支持的CPU、GPU、VPU(視覺處理單元)或 GNA(高斯神經加速器協處理器)或這些設備的組合3 。
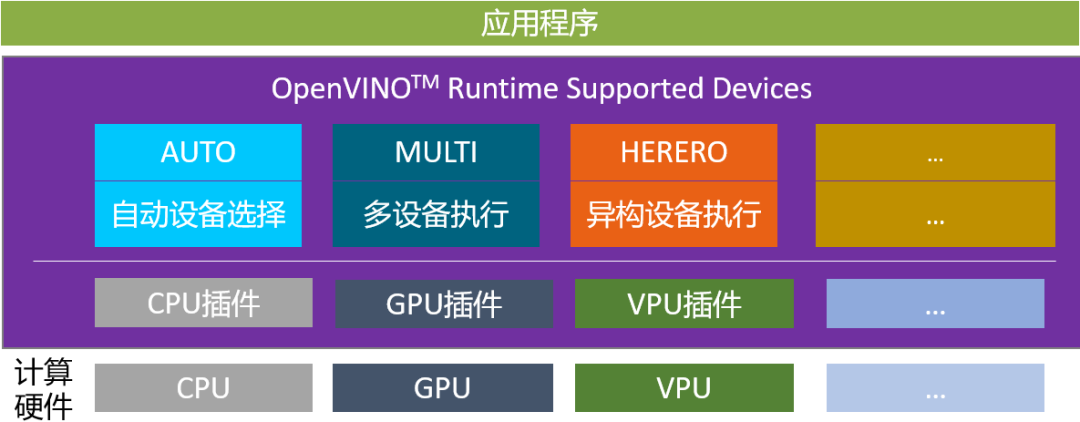
圖1-1 OpenVINO Runtime支持的設備插件3
AUTO插件好處有:
■ 首先檢測運行時平臺上所有可用的計算設備,然后選擇最佳的一個計算設備進行推理計算,并根據深度學習模型和所選設備的特性以最佳配置使用它。
■使 GPU 實現更快的首次推理延遲:GPU 插件需要在開始推理之前在運行時進行在線模型編譯——可能需要 10 秒左右才能完成,具體取決于平臺性能和模型的復雜性。當選擇獨立或集成GPU時,“AUTO”插件開始會首先利用CPU進行推理,以隱藏此GPU模型編譯時間。
■使用簡單,開發者只需將compile_model()方法的device_name參數指定為“AUTO”即可,如圖1-2所示。

圖1-2 指定AUTO插件
1.1.2 什么是自動批處理?
自動批處理(Automatic Batching)2 ,又叫自動批處理執行(Automatic Batching Execution),是OpenVINO Runtime支持的設備之一,如圖1-1所示。
一般來說,批尺寸(batch size) 越大的推理計算,推理效率和吞吐量就越好。自動批處理執行將用戶程序發出的多個異步推理請求組合起來,將它們視為多批次推理請求,并將批推理結果拆解后,返回給各推理請求。
自動批處理無需開發者手動指定。當compile_model()方法的config參數設置為{“PERFORMANCE_HINT”: ”THROUGHPUT”}時,OpenVINO Runtime會自動啟動自動批處理執行,如圖1-3所示,讓開發人員以最少的編碼工作即可享受計算設備利用率和吞吐量的提高。

圖1-3 自動啟動自動批處理執行
1.2 動手學AUTO插件的特性
讀書是學習,實踐也是學習,而且是更有效的學習。本文提供了完整的實驗代碼,供讀者一邊動手實踐,一邊學習總結。
Github地址: https://github.com/yas-sim/openvino-auto-feature-visualization
1.2.1 搭建實驗環境
第一步,克隆代碼倉到本地。
git clone https://github.com/yas-sim/openvino-auto-feature-visualization.git
第二步,在openvino-auto-feature-visualization路徑執行:
python -m pip install --upgrade pip
pip install -r requirements.txt
第三步,下載模型并完成轉換
omz_downloader --list models.txt
omz_converter --list models.txt
到此,實驗環境搭建完畢。實驗程序的所有配置和設置參數都硬編碼在源代碼中,您需要手動修改源代碼以更改測試配置,如圖1-4所示。
圖1-4 手動修改源代碼中的配置
1.2.2 AUTO插件自動切換計算設備
GPU插件需要在 GPU 上開始推理之前將IR模型編譯為 OpenCL 模型。這個模型編譯過程可能需要很長時間,例如 10 秒,會延遲應用程序開始推理,使得應用程序啟動時的用戶體驗不好。
為了隱藏這種 GPU 模型編譯延遲,AUTO插件將在 GPU 模型編譯進行時使用CPU執行推理任務;當GPU模型編譯完成后,AUTO插件會自動將推理計算設備從CPU切換到GPU,如圖1-5所示。
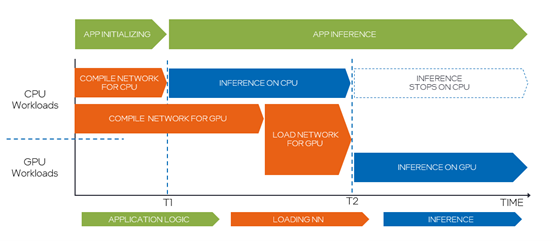
圖1-5 AUTO插件自動切換計算設備
1.2.3 動手觀察自動切換計算設備的行為
AUTO插件會依據設備優先級1 : dGPU > iGPU > VPU > CPU, 來選擇最佳計算設備。當自動插件選擇 GPU 作為最佳設備時,會發生推理設備切換,以隱藏首次推理延遲。
請注意,設備切換前后的推理延遲不同;此外,推理延遲故障可能發生在設備切換的那一刻,如圖1-6所示。
請如圖1-6所示,設置auto-test-latency-graph.py配置參數為:
cfg['PERFORMANCE_HINT'] = ['THROUGHPUT', 'LATENCY'][0]
并運行命令:
python auto-test-latency-graph.py
同時打開Windows任務管理器,觀察CPU和iGPU的利用率。
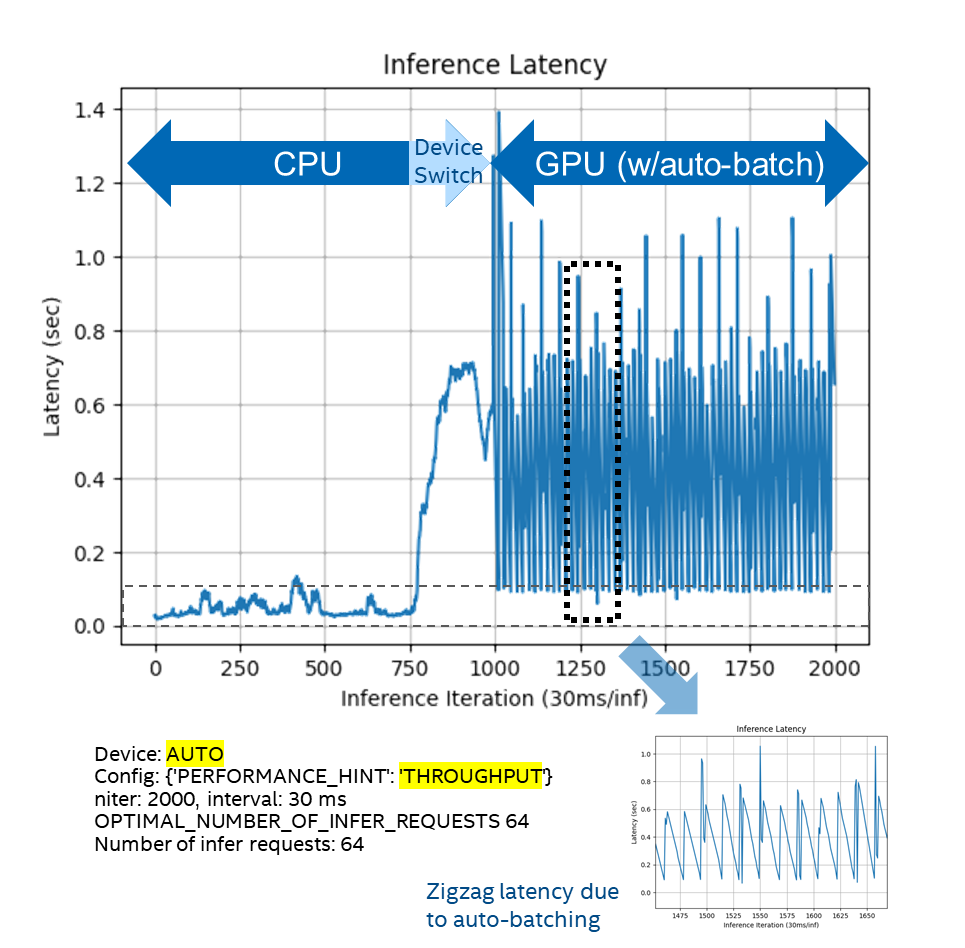
圖1-6 config={“PERFORMANE_HINT”:”THROUGPUT”}的執行行為
1.2.4 PERFORMANCE_HINT設置
如1.1.2節所述,AUTO插件的執行行為取決于compile_model()方法的config參數的PERFORMANCE_HINT設置,如表1-1所示:
表1-1 PERFORMANCE_HINT設置

設置auto-test-latency-graph.py配置參數為:
cfg['PERFORMANCE_HINT'] = ['THROUGHPUT', 'LATENCY'][1]
并運行命令:
python auto-test-latency-graph.py
同時打開Windows任務管理器,觀察CPU和iGPU的利用率,運行結果如圖1-7所示。
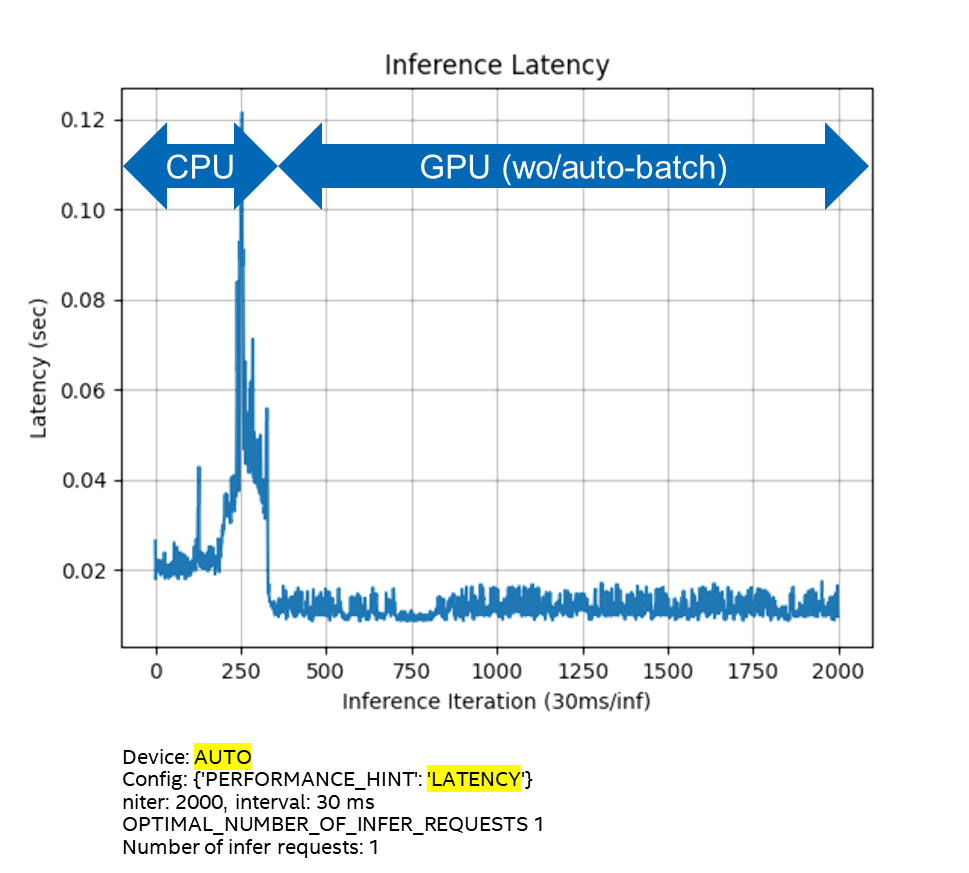
圖1-7 config={“PERFORMANE_HINT”:”LATENCY”}的執行行為
通過實驗,我們可以發現,根據不同的config參數設置,使得AUTO插件可以工作在不同的模式下:
■ 在Latency模式,不會自動啟動Auto Batching,執行設備切換后,GPU上的推理延遲很小,且不會抖動。
■在THROUGHPUT模式,自動啟動Auto Batching,執行設備切換后,GPU上的推理延遲較大,而且會抖動。
接下來,本文將討論Auto Batching對推理計算行為的影響。
1.3 動手學Auto Batching的特性
如1.1.2節所述,自動批處理執行將用戶程序發出的多個異步推理請求組合起來,將它們視為多批次推理請求,并將批推理結果拆解后,返回給各推理請求,如圖1-8所示。

圖1-8 Auto Batching的執行過程
Auto Batching在收集到指定數量的異步推理請求或計時器超時(默認超時=1,000 毫秒)時啟動批推理計算(batch-inference),如圖1-9所示。

圖1-9 啟動批推理計算
1.3.1 Auto Batching被禁止時
Auto Batching被禁止時,所有推理請求都是單獨被處理的。
請配置并運行auto-test.py。
Device: AUTO
Config: {'PERFORMANCE_HINT': 'LATENCY'}
niter: 20 , interval: 30 ms
OPTIMAL_NUMBER_OF_INFER_REQUESTS 1
Number of infer requests: 1
運行結果如圖1-10所示,可見每一個推理請求是被單獨處理的。

圖1-10 Auto Batching被禁止時的運行結果
1.3.2 Auto Batching被使能時
Auto Batching被使能時,異步推理請求將作為多批次推理請求進行綁定和處理。推理完成后,結果將分發給各個異步推理請求并返回。需要注意的是:批推理計算不保證異步推理請求的推理順序。
請配置并運行auto-test.py。
Device: GPU
Config: {'CACHE_DIR': './cache', 'PERFORMANCE_HINT': 'THROUGHPUT', 'ALLOW_AUTO_BATCHING': 'YES'}
niter: 200 , interval: 30 ms
OPTIMAL_NUMBER_OF_INFER_REQUESTS 64
Number of infer requests: 16
運行結果如圖1-11所示,可見每16個推理請求被組合成一個批次進行批推理計算,推理計算順序不被保證。

圖1-11 Auto Batching被使能時的運行結果
1.3.3 Auto Batching會導致推理延遲變長
由于較長的默認超時設置(默認timeout = 1,000ms),在低推理請求頻率情況下可能會引入較長的推理延遲。
由于Auto Batching將等待指定數量的推理請求進入或超時計時器超時,在低推理頻率的情況下,它無法在指定的超時時間內收集足夠的推理請求來啟動批推理計算,因此,提交的推理請求將被推遲,直到計時器超時,這將引入大于timeout設置的推理延遲。
為解決上述問題,用戶可以通過 AUTO_BATCH_TIMEOUT 配置參數指定超時時間,以盡量減少此影響。
請使用AutoBatching的默認timeout,運行auto-test.py。
Device: GPU
Config: {'CACHE_DIR': './cache', 'PERFORMANCE_HINT': 'THROUGHPUT'}
niter: 20, interval: 300 ms
OPTIMAL_NUMBER_OF_INFER_REQUESTS 64
Number of infer requests: 64
運行結果如圖1-12所示,由于每次都無法在timeout時間內收集到指定數量的推理請求,由此導致推理請求的延遲很高。

圖1-12 timeout=1000ms運行結果
請配置AutoBatching的timeout=100ms,然后運行auto-test.py。
Device: GPU
Config: {'CACHE_DIR': './cache', 'PERFORMANCE_HINT': 'THROUGHPUT', 'AUTO_BATCH_TIMEOUT': '100'}
niter: 20 , interval: 300 ms
OPTIMAL_NUMBER_OF_INFER_REQUESTS 64
Number of infer requests: 16

圖1-13 timeout=100ms運行結果
運行結果如圖1-13所示, timeout=100ms時間內,僅能收集到一個推理請求。
1.3.4 Auto Batching最佳實踐
綜上所述,Auto Batching的最佳編程實踐:
■ 要記住,默認情況下Auto Batching不會啟用。
■只有在以下情況時,Auto Batching才啟用:
{'PERFORMANCE_HINT': 'THROUGHPUT', 'ALLOW_AUTO_BATCHING': 'YES'}
■如果您的應用程序能夠以高頻率連續提交推理請求,請使用自動批處理。
■警告:如果您的應用間歇性地提交推理請求,則最后一個推理請求可能會出現意外的長延遲。
■如果推理節奏或頻率較低,即推理頻率遠低于AUTO_BATCH_TIMEOUT(默認為 1,000 毫秒),請勿開啟自動批處理。
■您可以使用AUTO_BATCH_TIMEOUT 參數更改自動批處理的超時設置,以最大限度地減少不需要的長延遲,參數值的單位是“ms”。
■如果您知道工作負載的最佳批處理大小,請使用PERFORMANCE_HINT_NUM_REQUESTS 指定適當的批處理數量,即 {'PERFORMANCE_HINT_NUM_REQUESTS':'4'}。同時,以GPU為例,AUTO插件會在后臺根據可以使用的內存,模型精度等計算出最佳批處理大小。
1.4 總結
本節給出AUTO 插件和Auto Batching的快速小結,如表1-2所示。
表1-2 AUTO插件和自動批處理執行快速小結表

本文GitHub源代碼鏈接:https://github.com/yas-sim/openvino-auto-feature-visualization
審核編輯 :李倩
-
Auto
+關注
關注
0文章
42瀏覽量
15354 -
深度學習
+關注
關注
73文章
5527瀏覽量
121879
原文標題:OpenVINO? 2022.1中AUTO插件和自動批處理的最佳實踐 | 開發者實戰
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
松下MPS媒體制作平臺 第十一篇:深入探索自動跟蹤插件(第二部分)

松下MPS媒體制作平臺之自動跟蹤插件(第一部分)
立訊精密入選2024可持續發展最佳實踐案例

MES系統的最佳實踐案例
邊緣計算架構設計最佳實踐
云計算平臺的最佳實踐

RTOS開發最佳實踐
工業自動化:PROFINET網絡技術解析與Auto Pro工業交換機應用實踐






 工商網監
工商網監
評論