 使用SPARK和Ada進行代碼清理
使用SPARK和Ada進行代碼清理
您能以多快的速度將軟件推出并準備好?
長期以來,這個單一的問題推動了大部分嵌入式工業行業。按時發布此年度版本,滿足該功能里程碑。只要軟件功能相對簡單或次于系統功能,就可以了。
但隨著系統復雜性和互連性的日益增加,曾經是良性的小故障或“故障”現在正在造成威脅,有時甚至危及人的生命。無人機、自動駕駛汽車和醫療設備是這一趨勢的三個非常重要的代表。那么問題就不再是軟件能否按時交付,而是正確、安全、可靠的軟件能否及時交付。這是一個完全不同的野獸。
除了驗證它正在做它應該做的事情之外,沒有太多可以做的事情來交付正確的軟件。不幸的是,傳統的軟件開發方法并不是為了簡化正式規范或優化驗證成本而設計的。而且越晚檢測到問題,修復的成本就越高,以至于在第一天需要幾分鐘才能解決的問題可能會在集成過程中持續數月。是的,使用傳統語言和環境編寫極其強大的軟件是可能的,但成本高得離譜。
特別是對于在微控制器 (MCU) 上運行的嵌入式應用程序,一個更加復雜的因素是編寫測試的難度。當涉及低級嵌入式功能時,編寫甚至運行廣泛的測試活動可能是不切實際的。任何可以在這些程序之前幫助清除問題或確保正確性的東西都可以節省大量成本。
另一方面,從一開始就利用表達性和正式的規范,使實施者更容易尊重需求,提供自動驗證,從而防止問題或在開發周期的早期發現問題。
Ada 和 SPARK 語言在這方面提供了獨特的解決方案,將規范、編碼和驗證集成到一個通用的形式中。這些語言的核心原則是在軟件級別盡可能多地指定,以便在實現時可以驗證盡可能多的組件。
下面逐步檢查實際的 Ada 或 SPARK 實現。
在將 Ada 和 SPARK 語言與替代語言進行比較時,突出的一件事是可以添加到軟件源代碼中以捕獲除實際功能之外的約束和意圖的信息量。數據類型不僅僅是一個整數或浮點數:它是一個語義實體,可以與一組有效值、一組操作、最小精度、內存表示,甚至物理維度相關聯。同樣,函數不僅僅是一種從參數計算值的方法:它有一組可以調用的條件,在它返回時提供一組保證,并對它的環境(參數和全局變量)產生影響)。
Ada 和 SPARK 有很多特性可以用來豐富規范,但是為了本文的目的,我們選擇一個例子:

這個簡單的過程在其屬性和行為方面揭示了很多:
首先,C 是一個in out參數,所以它必須在被調用之前被初始化,并且它的值在子程序中被修改。請注意,沒有指示它是通過復制還是引用傳遞,這是由編譯器根據語言約束和效率自動決定的。
E 是輸入參數,或不打算修改的輸入值。一個前提條件是在調用之前容器未滿。就設計而言,這是一個極其重要的轉變,就像在其他語言中的Push過程可能負責檢測錯誤的調用上下文(如果容器已滿)并實施緩解技術(或防御性代碼)。另一方面,使用先決條件,該過程可以安全地假設容器未滿(否則它會被靜態或動態檢測到,但稍后會詳細介紹)并避免這些額外的代碼。驗證輸入的責任隱含在調用者身上,然后調用者可以將其提升給自己的調用者,直到到達代碼中數據驗證確實有意義的地方。
后置條件提供了有關過程行為的關鍵屬性——這里,E 包含在修改后的容器中并且計數增加的事實。
查看與嵌入式開發相關的一些約束,另一個有用的方面是指定內存映射約束。Ada 允許聲明式表示法來指定數據結構在內存中的布局方式和地址,從而避免容易出錯的按位操作和一致性檢查。例如:

上面聲明了一個數據結構以及一些與邊界相關的字段:
數據的大小固定為 16 位,接下來的兩個方面(具有值High_Order_First)基本上告訴編譯器使用大端表示。
下一個子句提供特定的位表示(例如,Size從索引位1到4的字節0開始。
最后,為R提供了它在內存中的地址。
實施(在 SPARK/Ada 或 C 中)
Ada 和 SPARK 語言提供了現代命令式語言的大部分功能。這些功能如何實現的最顯著特性是它們為編譯器解釋提供的空間很小并且避免了捷徑。例如,沒有隱式轉換,并且輕松地執行指針運算之類的操作需要 5 行代碼。但是,在實際編碼階段花費的額外時間很容易通過易于驗證來重新獲得,無論是用于代碼閱讀、測試還是靜態分析。
在討論的這一點上,值得一提的是房間里的大象:對于新開發的代碼來說,使用一種新語言可能是一個好主意,但通常存在一個不容忽視的預先存在的環境。這通常是來自其他項目或現成庫的代碼。這段代碼可能是用 C 語言或 C++ 創建的。僅此一項就經常驅動開發語言的選擇。
幸運的是,SPARK 和 Ada 已被設計為與 C 環境很好地集成。一些指令可以將 C 直接映射到 Ada,反之亦然,而無需任何包裝代碼的開銷。這種映射甚至可以自動生成。
因此,如果不推薦的話,在 SPARK 或 Ada 中僅開始開發幾個組件,而在其他情況下保留在 C 環境中是完全合理的。
目前可用于 Ada 和 SPARK 的主要編譯器技術是 GCC,但也可以提供其他編譯器技術。這意味著 SPARK 和 C 代碼可以使用相同的技術進行編譯,具有相同的優化和代碼生成通道。結果,C 和 SPARK 代碼之間的性能幾乎沒有差異,并且沒有從一種語言到另一種語言的控制流的損失。
談到我們之前的一個例子,讓我們假設正在使用一個用 C 實現的容器。我們試圖與之交互的 C 代碼如下所示:

除了來自 C 的實現聲明之外,規范在 Ada/SPARK 中完全相同。

Ada 或 SPARK 代碼可以像在 Ada 中實現一樣使用此過程。與導入類似,導出允許 C 調用用 Ada 編寫的子程序。如果需要,這些接口層可以通過綁定生成器自動生成。
盡管將 SPARK 和 C 一起編譯解決了許多用例,但仍然存在最終代碼必須是 C 的情況。確實,一些用戶雖然對使用 SPARK 進行開發感興趣,但仍需要將 C 代碼交付給他們的客戶。
可以使用一個特殊的編譯器來覆蓋這個用例,即“GNAT 通用代碼生成器”。它本質上將 Ada 語言的一個子集編譯為 C。借助這項技術,SPARK 幾乎成為一種建模語言,其輸出集成在 C 環境中。它也可以被視為一種交付形式驗證的 C 代碼的方式,驗證在 SPARK 級別執行。
在數據表示示例(寄存器案例)中,在代碼中使用這段數據非常簡單。分配一個值如下所示:
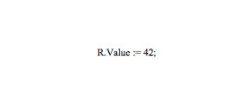
這里不需要按位運算,因為編譯器會在后臺自動生成適當的代碼。
確認
Ada 和 SPARK 在源代碼中提供了大量信息,可供各種檢查器使用。例如,作為第一道防線,編譯器將檢測到許多不一致之處,并可以在測試階段自動在可執行文件中插入動態驗證。有了這個級別的信息,就可以超越經典的靜態分析并應用程序驗證技術來演示整個應用程序的屬性。
對于較低級別的數據結構,也會進行自動一致性驗證。編譯器驗證特定大小是否足以實現所需的數據范圍,沒有數據重疊等。此外,形式證明可用于驗證分配的值是否始終在任何分配的范圍內。
繼續前面的另一個示例,假設在我們想要驗證的一段代碼中調用了Push 。例如,我們可以讓以下語句從輸入文件中讀取數字,直到它達到 0:

這個Push調用將被 SPARK 工具標記為不正確,因為無法知道循環不會達到容器 C 的最大容量。證明者無法證明Push的前提條件,這顯然應該在調用,而不是在被調用的過程中。如果到達文件末尾而沒有擊中0 ,則示例代碼中可能會出現另一個潛在錯誤。如果指定了適當的先決條件,證明者將能夠判斷循環中缺少檢查以驗證是否仍需要讀取輸入。
這種問題通常會在某個時候發生。如果覆蓋極端案例的單元測試足夠廣泛,那么問題將在該級別得到解決。然而,當真正的數據開始輸入系統時,他們可以找到自己的方式進行集成測試,或者當用戶試圖破壞系統時進行 beta 測試。在最壞的情況下,其中一些錯誤會通過部署找到并需要在客戶報告后進行追蹤。問題不是它們是否會被發現,而是當它們被發現時修復它們的成本會有多高。越晚發現,越多的人參與到鏈條中,需要更多的調查來確定源頭、修復問題、證明修復的合理性、測試修復、重新交付產品等。使用技術早期集成驗證 - 在這種情況下,
舊的又是新的
Ada 和 SPARK 方法的獨特之處在于它集成了軟件規范、實現和驗證,提供了一種以現代系統所需的完整性級別生產軟件的經濟高效的方法。醫療、汽車和工業物聯網 (IIoT) 等行業一直在尋找傳統 C 語言開發的替代方案,Ada 和 SPARK 提供了經過驗證的解決方案。
作為 Ada 語言的提供者,AdaCore 在過去幾年中觀察到對該技術的新興趣。今天的限制提供了一個嘗試新事物的好機會——或者正在卷土重來的舊事物。
審核編輯:郭婷
-
物聯網
+關注
關注
2910文章
44752瀏覽量
374569 -
C語言
+關注
關注
180文章
7608瀏覽量
137119 -
編譯器
+關注
關注
1文章
1636瀏覽量
49172
發布評論請先 登錄
相關推薦
ADA4945數據手冊中給出的應用參考案例,ADA4945供電電源并非常規電源大小,7.5V和-2.5V供電是怎么得來的?
對ADA4637仿真時遇到的幾個問題求解
Minitab 數據清理與預處理技巧
spark為什么比mapreduce快?
用ADA4350芯片作跨阻放大時,ADA的關斷電阻是多少?
使用ADA4522-1仿真電路時,仿真時間很長的原因?
spark運行的基本流程
Spark基于DPU的Native引擎算子卸載方案

關于Spark的從0實現30s內實時監控指標計算
關于Docker 的清理命令集錦
使用ADA4571放在轉子外側進行離軸測量,為什么產生的正余弦波形是畸變的呢?
Spark基于DPU Snappy壓縮算法的異構加速方案
RDMA技術在Apache Spark中的應用

基于DPU和HADOS-RACE加速Spark 3.x





 工商網監
工商網監
評論