 利用axi_master接口指令端的幾個靜態參數的優化技巧
利用axi_master接口指令端的幾個靜態參數的優化技巧
Vitis HLS 在從Vivaido HLS的升級換代中,以axi_master接口為起點的設計正在變得更易上手,其中很重要的一點就是更多的MAXI端口設計參數可以讓用戶通過指令傳達到。這些參數可以分為兩類:
靜態參數指標:這些參數會影響內存性能,可以在 C 綜合期間的編譯時從編譯的結果中很清楚地知道,突發讀寫地長度、數據端口寬度加寬、對齊等。
動態參數指標:這些參數本質上是動態的,取決于系統。例如,與 DDR/HBM 的通信效率在C綜合編譯時是未知的。 本文給大家提供利用axi_master接口指令端的幾個靜態參數的優化技巧,從擴展總線接口數量,擴展總線位寬,循環展開等角度入手。最核心的優化思想就是以資源面積換取高帶寬的以便并行計算。
熟記這本文幾個關鍵的設計點,讓你的HLS內核接口效率不再成為設計的瓶頸! ?
以上代碼在進行了c綜合后,我們所有的指針變量都會依據指令的設置映射到axi-master上,但是因為根據指令中所有的端口都綁定到了一條總線gmem上。所以在綜合的警告里面會提示:?
?
?
以上代碼在進行了c綜合后,我們所有的指針變量都會依據指令的設置映射到axi-master上,但是因為根據指令中所有的端口都綁定到了一條總線gmem上。所以在綜合的警告里面會提示:?
? ?
當總線數量滿足了我們并行讀入的要求后,讀取數據的位寬就成為了我們優化的方向:?
因為讀取的數據格式是int類型,所以這里的數據位寬就是32bit。
?
?
當總線數量滿足了我們并行讀入的要求后,讀取數據的位寬就成為了我們優化的方向:?
因為讀取的數據格式是int類型,所以這里的數據位寬就是32bit。
? ?
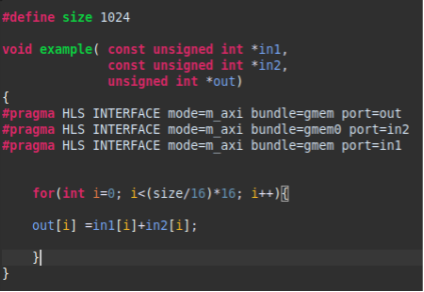
為了能夠轉移數據傳輸瓶頸,在Vitis kernel target flow中,數據位寬在512bit的時候能夠達到最高的數據吞吐效率。在Vitis HLS 中的新增了 max_widen_bitwidth 選項來自動將較短的數據位寬拼接到設定的較長的數據位寬選項。在這里我們可以將位寬設置到512bit的位寬,但是同時要向編譯器說明,原數據位寬和指定的擴展位寬成整數倍關系。這個操作很簡單,在數據讀取的循環邊界上,用(size/16)*16示意編譯器即可。
?
?
為了能夠轉移數據傳輸瓶頸,在Vitis kernel target flow中,數據位寬在512bit的時候能夠達到最高的數據吞吐效率。在Vitis HLS 中的新增了 max_widen_bitwidth 選項來自動將較短的數據位寬拼接到設定的較長的數據位寬選項。在這里我們可以將位寬設置到512bit的位寬,但是同時要向編譯器說明,原數據位寬和指定的擴展位寬成整數倍關系。這個操作很簡單,在數據讀取的循環邊界上,用(size/16)*16示意編譯器即可。
? ?
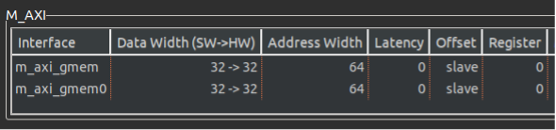
擴展位寬后的結果可以在綜合報告的接口部分看到數據位寬已經從32位擴展到512位。?
?
?
擴展位寬后的結果可以在綜合報告的接口部分看到數據位寬已經從32位擴展到512位。?
? ?
優化到這一步我們的設計可以進行大位寬的同步讀寫,但是發現循環的trip count還是執行了1024次, 也就是說雖然位寬拓展到512后,還是一個循環周期計算一次32bit的累加。實際上512bit的數據位寬可以允許16個累加計算并行執行。?
?
?
優化到這一步我們的設計可以進行大位寬的同步讀寫,但是發現循環的trip count還是執行了1024次, 也就是說雖然位寬拓展到512后,還是一個循環周期計算一次32bit的累加。實際上512bit的數據位寬可以允許16個累加計算并行執行。?
? ?
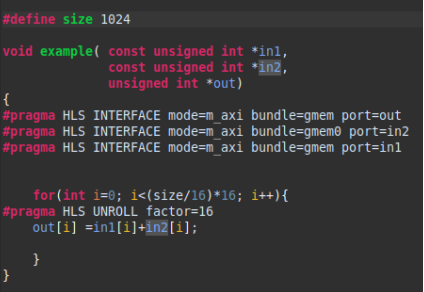
為了完成并行度的優化,我們需要在循環中添加系數為16的unroll 指令,這樣就可以生成16個并行執行累加計算的硬件模塊以及線程。?
?
?
為了完成并行度的優化,我們需要在循環中添加系數為16的unroll 指令,這樣就可以生成16個并行執行累加計算的硬件模塊以及線程。?
? ?
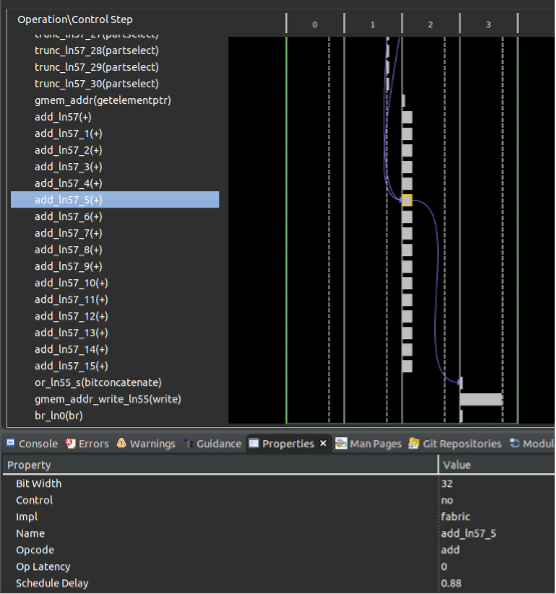
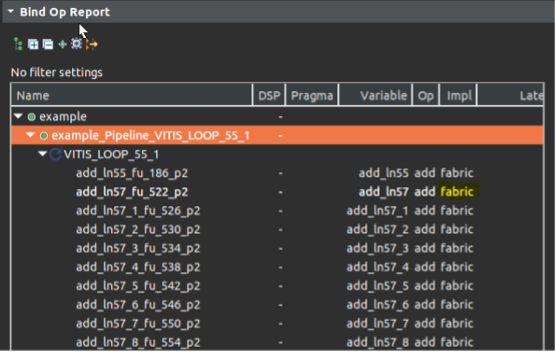
在循環中并行執行的累加操作,我們可以從schedule viewer中觀察到并行度,可以從bind_op窗口中觀察到operation實現所使用的硬件資源,可以從循環的trip_count 降低到了1024/16=64個周期,以及大大縮小的模塊的整個latency中得以證明。?
?
?
在循環中并行執行的累加操作,我們可以從schedule viewer中觀察到并行度,可以從bind_op窗口中觀察到operation實現所使用的硬件資源,可以從循環的trip_count 降低到了1024/16=64個周期,以及大大縮小的模塊的整個latency中得以證明。?
? ?
? ?
最后我們比較了一下并行執行16個累加計算前后的綜合結果,可以發現由于有數據的按位讀寫拆分拼接等操作,整個模塊的延遲雖然沒有縮短為16分之一,但是縮短為5分之一也是性能的極大提升了。?
?
?
最后我們比較了一下并行執行16個累加計算前后的綜合結果,可以發現由于有數據的按位讀寫拆分拼接等操作,整個模塊的延遲雖然沒有縮短為16分之一,但是縮短為5分之一也是性能的極大提升了。?
? ?
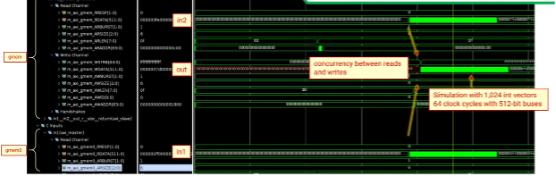
最后的最后,RTL級別的co-sim仿真才讓我們更加確信了數據的從兩個并行讀寫,循環執行的周期減小至了64個時鐘周期。?
?
?
最后的最后,RTL級別的co-sim仿真才讓我們更加確信了數據的從兩個并行讀寫,循環執行的周期減小至了64個時鐘周期。?
? ?
以上內容是設計者在AXI總線接口中使用傳統的數據類型時,提升數據傳輸效率和帶寬的一攬子有效方法:
?第一,擴展總線接口數量,以便并行讀寫。第二,擴展總線位寬,增加讀寫帶寬。第三,循環展開,例化更多計算資源以便并行計算。
本文的優化方式還是基于內核設計本身的,下一篇文章,我們將使用Alveo板卡做一些突發傳輸的實驗,深度定制傳輸需求,以真實仿真波形和測得的傳輸速度,從系統級別強化我們對于突發讀寫效率的認知。
審核編輯 :李倩
?
以上內容是設計者在AXI總線接口中使用傳統的數據類型時,提升數據傳輸效率和帶寬的一攬子有效方法:
?第一,擴展總線接口數量,以便并行讀寫。第二,擴展總線位寬,增加讀寫帶寬。第三,循環展開,例化更多計算資源以便并行計算。
本文的優化方式還是基于內核設計本身的,下一篇文章,我們將使用Alveo板卡做一些突發傳輸的實驗,深度定制傳輸需求,以真實仿真波形和測得的傳輸速度,從系統級別強化我們對于突發讀寫效率的認知。
審核編輯 :李倩
動態參數指標:這些參數本質上是動態的,取決于系統。例如,與 DDR/HBM 的通信效率在C綜合編譯時是未知的。 本文給大家提供利用axi_master接口指令端的幾個靜態參數的優化技巧,從擴展總線接口數量,擴展總線位寬,循環展開等角度入手。最核心的優化思想就是以資源面積換取高帶寬的以便并行計算。
熟記這本文幾個關鍵的設計點,讓你的HLS內核接口效率不再成為設計的瓶頸!
?
以上代碼在進行了c綜合后,我們所有的指針變量都會依據指令的設置映射到axi-master上,但是因為根據指令中所有的端口都綁定到了一條總線gmem上。所以在綜合的警告里面會提示:?
?WARNING: [HLS 200-885] The II Violation in module 'example_Pipeline_VITIS_LOOP_55_1' (loop 'VITIS_LOOP_55_1'):Unable to schedule bus request operation ('gmem_load_1_req', example.cpp:56) on port 'gmem' (example.cpp:56) due to limited memory ports(II = 1). Please consider using a memory core with more ports or partitioning the array.
因為在axi-master總線上最高只能支持一個讀入和一個寫出同時進行,如果綁定到一條總線則無法同時從總線讀入兩個數據,所以最終的循環的II=2。解決這個問題的方法就是用面積換速度,我們實例化兩條axi總線gmem和gmem0,最終達到II=1。
?
當總線數量滿足了我們并行讀入的要求后,讀取數據的位寬就成為了我們優化的方向:?
因為讀取的數據格式是int類型,所以這里的數據位寬就是32bit。
?
?
為了能夠轉移數據傳輸瓶頸,在Vitis kernel target flow中,數據位寬在512bit的時候能夠達到最高的數據吞吐效率。在Vitis HLS 中的新增了 max_widen_bitwidth 選項來自動將較短的數據位寬拼接到設定的較長的數據位寬選項。在這里我們可以將位寬設置到512bit的位寬,但是同時要向編譯器說明,原數據位寬和指定的擴展位寬成整數倍關系。這個操作很簡單,在數據讀取的循環邊界上,用(size/16)*16示意編譯器即可。
?
?
擴展位寬后的結果可以在綜合報告的接口部分看到數據位寬已經從32位擴展到512位。?
?
?
優化到這一步我們的設計可以進行大位寬的同步讀寫,但是發現循環的trip count還是執行了1024次, 也就是說雖然位寬拓展到512后,還是一個循環周期計算一次32bit的累加。實際上512bit的數據位寬可以允許16個累加計算并行執行。?
?
?
為了完成并行度的優化,我們需要在循環中添加系數為16的unroll 指令,這樣就可以生成16個并行執行累加計算的硬件模塊以及線程。?
?
?
在循環中并行執行的累加操作,我們可以從schedule viewer中觀察到并行度,可以從bind_op窗口中觀察到operation實現所使用的硬件資源,可以從循環的trip_count 降低到了1024/16=64個周期,以及大大縮小的模塊的整個latency中得以證明。?
?
?
?
最后我們比較了一下并行執行16個累加計算前后的綜合結果,可以發現由于有數據的按位讀寫拆分拼接等操作,整個模塊的延遲雖然沒有縮短為16分之一,但是縮短為5分之一也是性能的極大提升了。?
?
?
最后的最后,RTL級別的co-sim仿真才讓我們更加確信了數據的從兩個并行讀寫,循環執行的周期減小至了64個時鐘周期。?
?
?
以上內容是設計者在AXI總線接口中使用傳統的數據類型時,提升數據傳輸效率和帶寬的一攬子有效方法:
?第一,擴展總線接口數量,以便并行讀寫。第二,擴展總線位寬,增加讀寫帶寬。第三,循環展開,例化更多計算資源以便并行計算。
本文的優化方式還是基于內核設計本身的,下一篇文章,我們將使用Alveo板卡做一些突發傳輸的實驗,深度定制傳輸需求,以真實仿真波形和測得的傳輸速度,從系統級別強化我們對于突發讀寫效率的認知。
審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
接口
+關注
關注
33文章
8575瀏覽量
151021 -
靜態
+關注
關注
1文章
29瀏覽量
14542 -
代碼
+關注
關注
30文章
4779瀏覽量
68525
原文標題:開發者分享 | HLS, 巧用AXI_master總線接口指令的定制并提升數據帶寬-面積換速度
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
spi master接口的fpga實現
串行外圍接口 大致了解: spi是個同步協議,數據在master和slaver間交換通過時鐘sck,由于它是同步協議,時鐘速率就可以各種變換。 sck:主機提供,從機不能操控,從器件由主機產生的時鐘控制。數據只有在sck來了的上升沿或者下降沿才傳輸。 高級一點的spi芯

AMBA AXI4接口協議概述
AMBA AXI4(高級可擴展接口 4)是 ARM 推出的第四代 AMBA 接口規范。AMD Vivado Design Suite 2014 和 ISE Design Suite 14 憑借半導體產業首個符合
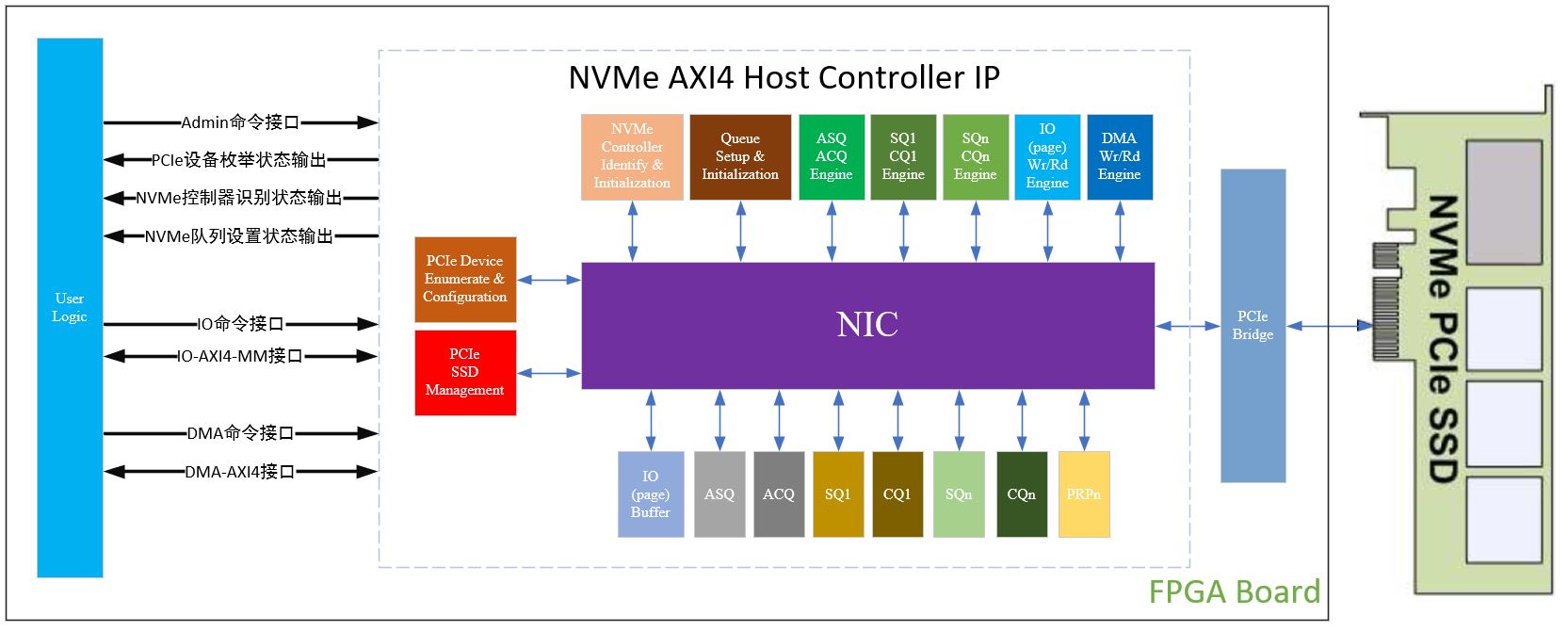
Xilinx NVMe AXI4主機控制器,AXI4接口高性能版本介紹
NVMe AXI4 Host Controller IP可以連接高速存儲PCIe SSD,無需CPU,自動加速處理所有的NVMe協議命令,具備獨立的數據寫入和讀取AXI4接口,不但適用高性能、順序
有關PL端利用AXI總線控制PS端DDR進行讀寫(從機wready信號一直不拉高)
怎么判斷他到底采用了這三種握手里面的哪種握手,這實在令人費解。還是PS端的DDR的機制的問題。
5.31 update:
問題找到部分:
情形一:接口的設置上,如果是設置為AXI4,如圖所示,
那么
發表于 05-31 12:04
SoC設計中總線協議AXI4與AXI3的主要區別詳解
AXI4和AXI3是高級擴展接口(Advanced eXtensible Interface)的兩個不同版本,它們都是用于SoC(System on Chip)設計中的總線協議,用于處理器和其它外設之間的高速數據傳輸。
FPGA設計中,對SPI進行參數化結構設計
今天給大俠帶來FPGA設計中,對SPI進行參數化結構設計,話不多說,上貨。
為了避免每次SPI驅動重寫,直接參數化,盡量一勞永逸。SPI master有啥用呢,你發現各種外圍芯片的配置一般
發表于 05-07 16:09
FPGA設計中,對SPI進行參數化結構設計
今天給大俠帶來FPGA設計中,對SPI進行參數化結構設計,話不多說,上貨。
為了避免每次SPI驅動重寫,直接參數化,盡量一勞永逸。SPI master有啥用呢,你發現各種外圍芯片的配置一般
發表于 04-11 18:29
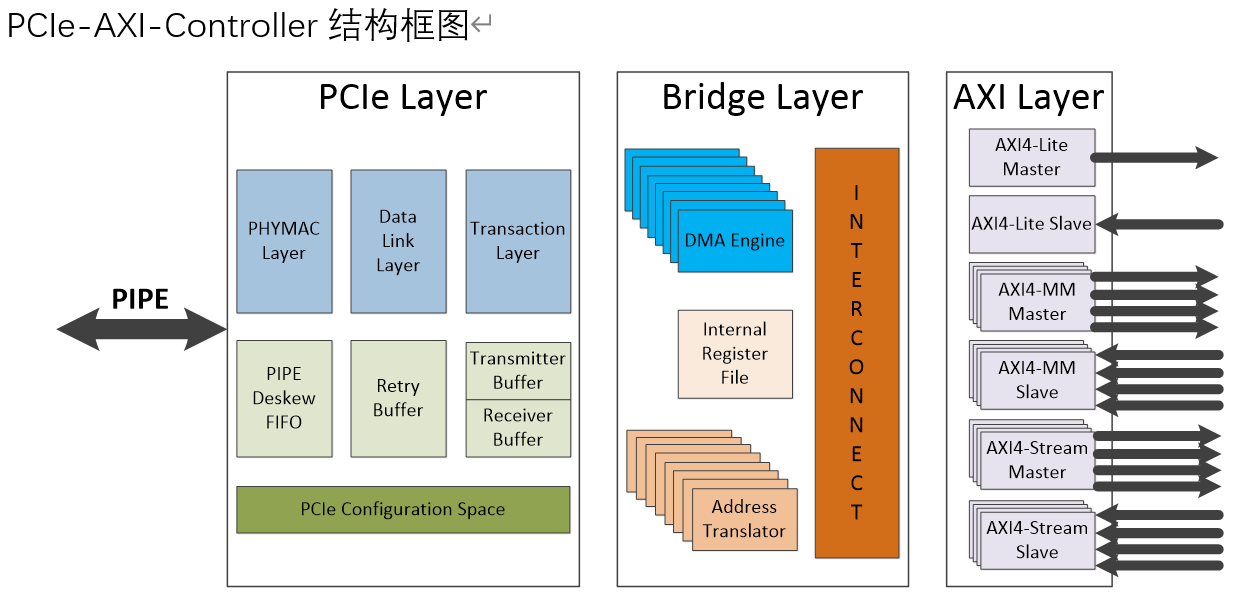
PCIe-AXI-Cont用戶手冊
Transaction layer的所有功能特性,不僅內置DMA控制器,而且具備AXI4用戶接口,提供一個高性能,易于使用,可定制化的PCIe-AXI互連解決方案,同時適用于ASIC和FPGA。
發表于 02-22 09:15
?3次下載
PCIe控制器(FPGA或ASIC),PCIe-AXI-Controller
Transaction Layer的所有功能特性,不僅內置DMA控制器,而且具備AXI4用戶接口,提供一個高性能,易于使用,可定制化的PCIe-AXI互連解決方案,同時適用于ASIC和FPGA。
電容6大特性參數,你知道幾個?
硬件設計好不好,電容參數知多少? 原文整理自書籍《硬件設計指南》 電容是我們電子電路設計中最常用的元件之一,除了基本的電容容值之外,電容還有其他6大參數,你知道幾個呢?本文章介紹MLCC陶瓷電容6
g81循環指令參數
G81循環指令是在數控機床中常用的一種循環加工指令,通過該指令可以實現機床在一個指定區域內的循環加工操作。本文將詳盡、詳實、細致地介紹G81循環指令的相關
什么是靜態IP地址?什么是DHCP?DHCP與靜態IP到底有何區別呢?
管理員手動更改配置。DHCP是一種網絡協議,用于自動分配IP地址、子網掩碼、網關和其他網絡參數給網絡設備。 靜態IP地址與DHCP之間存在幾個主要區別: 1. 配置過程:配置靜態IP地





 工商網監
工商網監
評論