 世界模型在實體機器人上能發揮多大的作用?
世界模型在實體機器人上能發揮多大的作用?
世界模型在實體機器人上能發揮多大的作用?
教機器人解決現實世界中的復雜任務,一直是機器人研究的基礎問題。深度強化學習提供了一種流行的機器人學習方法,讓機器人能夠通過反復試驗改善其行為。然而,當前的算法需要與環境進行過多的交互才能學習成功,這使得它們不適用于某些現實世界的任務。 為現實世界學習準確的世界模型是一個巨大的開放性挑戰。在最近的一項研究中,UC 伯克利的研究者利用 Dreamer 世界模型的最新進展,在最直接和最基本的問題設置中訓練了各種機器人:無需模擬器或示范學習,就能實現現實世界中的在線強化學習。

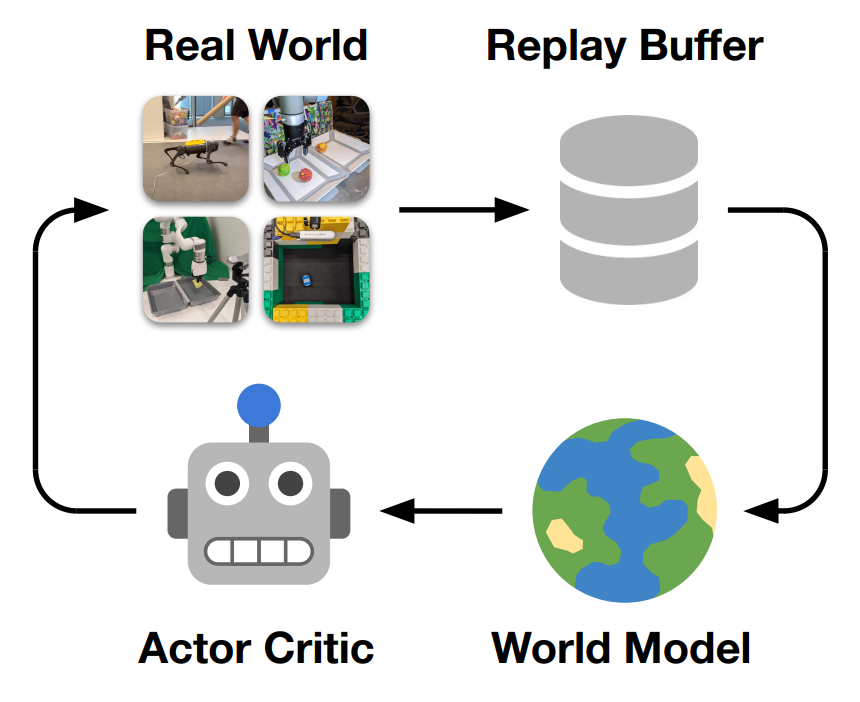
論文鏈接:https://arxiv.org/pdf/2206.14176.pdf Dreamer 世界模型是谷歌、多倫多大學等機構在 2021 年提出的一種。如下圖 2 所示,Dreamer 從過去經驗的回放緩存中學習世界模型,從世界模型的潛在空間中想象的 rollout 中學習行為,并不斷與環境交互以探索和改進其行為。研究者的目標是在現實世界中推動機器人學習的極限,并提供一個強大的平臺來支持未來的工作。
總體來說,這項研究的貢獻在于: 1、Dreamer on Robots。研究者將 Dreamer 應用于 4 個機器人,無需引入新算法直接在現實世界中展示了成功的學習成果。這些任務涵蓋了一系列挑戰,包括不同的行動空間、感官模式和獎勵結構。

2、1 小時內學會步行。研究者在現實世界中從零開始教四足機器人翻身、站起來并在 1 小時內學會步行。
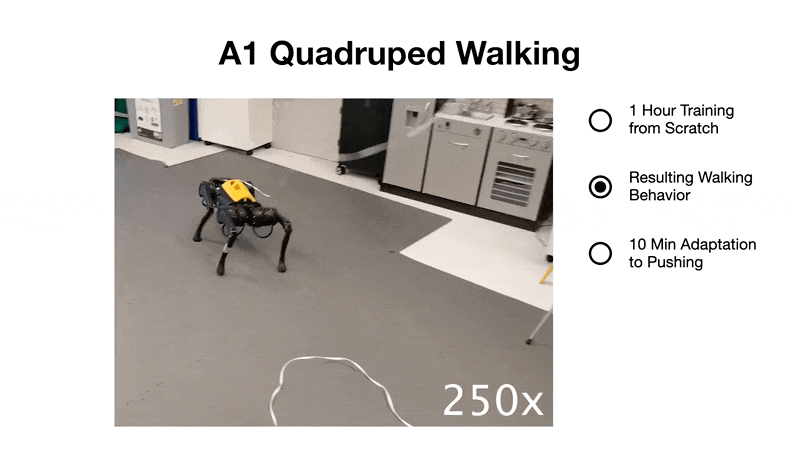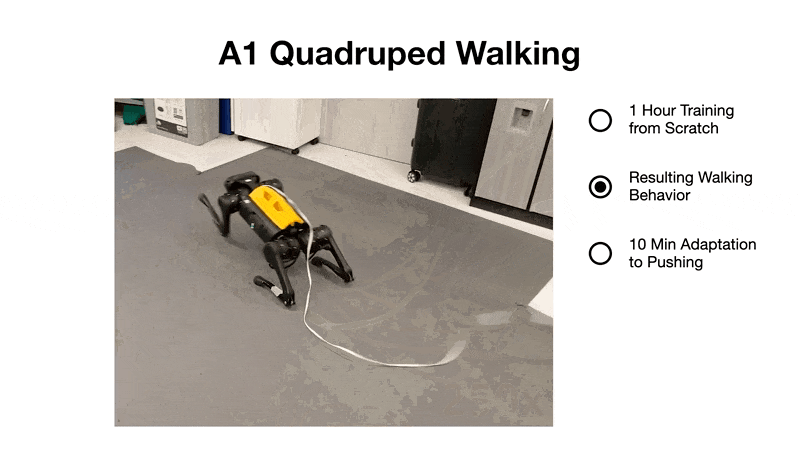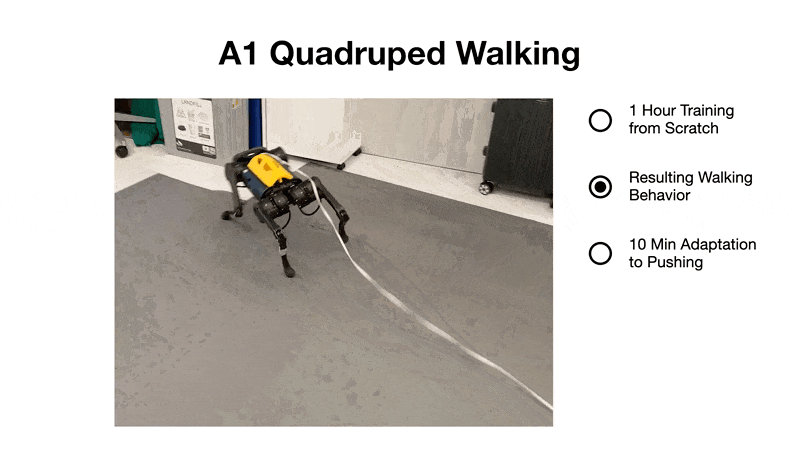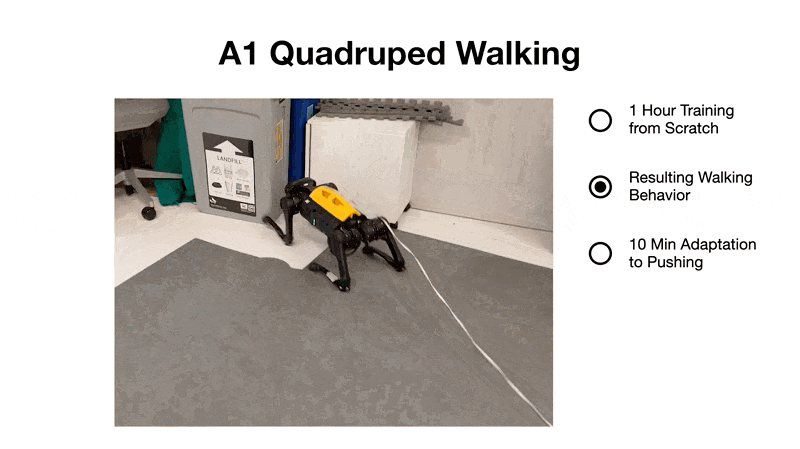
此外,他們發現機器人會在 10 分鐘內能學會承受推力或快速翻身并重新站起來。

3、視覺拾取和放置。研究者訓練機械臂從稀疏獎勵中學會拾取和放置對象,這需要從像素定位對象并將圖像與本體感受輸入融合。此處學習到的行為優于無模型智能體,并接近人類表現。


4、開源。研究者公開發布了所有實驗的軟件基礎架構,它支持不同的動作空間和感官模式,為未來研究現實世界中機器人學習的世界模型提供了一個靈活的平臺。 方法 該研究利用 Dreamer 算法(Hafner et al., 2019; 2020)在物理機器人上進行在線學習(online learning),無需模擬器,總體架構如上圖 2 所示。Dreamer 從過去經驗的回放緩沖區中學習世界模型,使用參與者 - 評價者算法從學習模型預測的軌跡中學習行為,并將其行為部署在環境中來不斷提升回放緩沖區。 該研究將學習更新與數據收集解耦,以滿足延遲要求并實現快速訓練而無需等待環境變化。在該研究的實現中,一個學習線程持續訓練世界模型和參與者 - 評價者行為,同時一個參與者線程并行計算環境交互動作。 世界模型是一個學習預測環境動態的深度神經網絡,如下圖 3(a)所示。
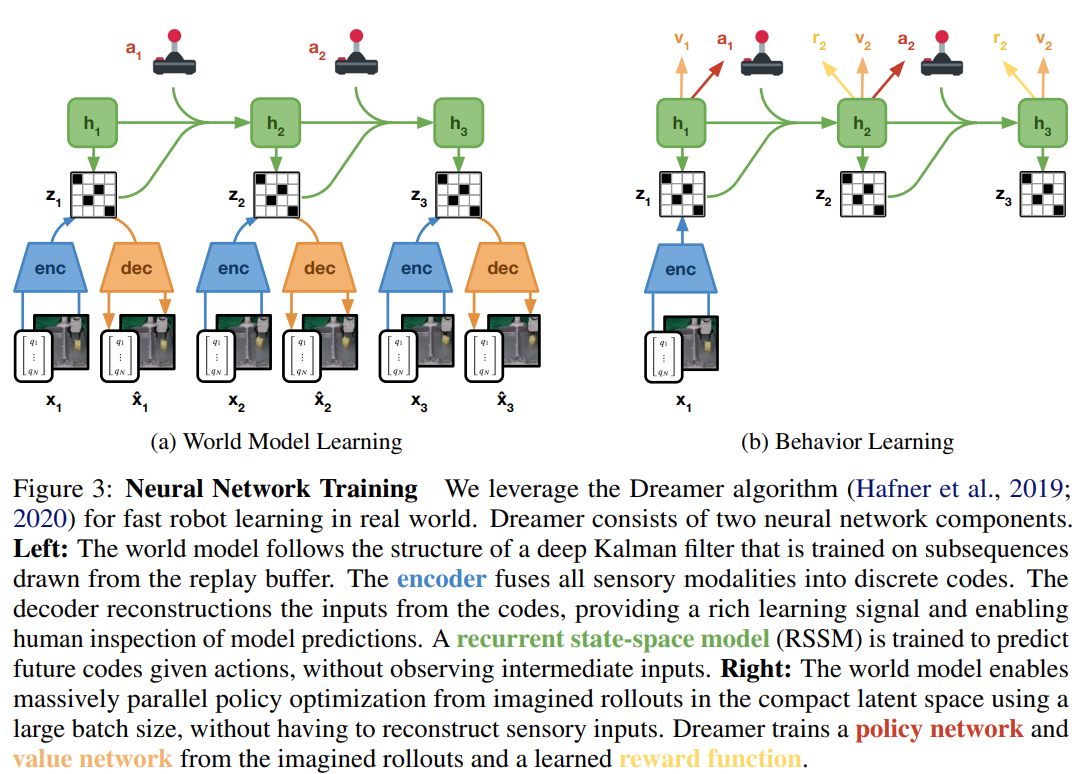
世界模型可以被認為是機器人自主學習環境的快速模擬器,在探索現實世界時不斷改進其模型。世界模型基于循環狀態空間模型 (RSSM; Hafner et al., 2018),它由四個組件組成:
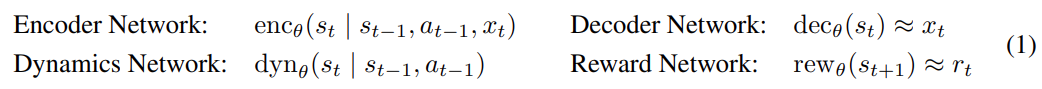
世界模型表征了與任務無關的動態知識,而參與者 - 評價者算法負責學習特定于當前任務的行為。如上圖 3(b) 所示。該研究從在世界模型的潛在空間中預測的 rollout 中學習行為,而無需解碼觀察結果。這可以在單個 GPU 上以 16K 的批大小進行大規模并行行為學習,類似于專門的現代模擬器 (Makoviychuk et al., 2021)。參與者 - 評價者算法由兩個神經網絡組成:
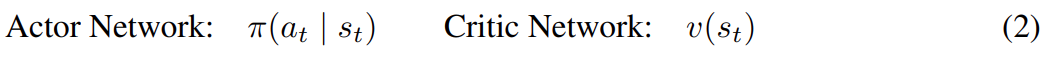
參與者網絡的作用是為每個潛在模型狀態 s_t 學習成功動作的分布,以最大化未來預測任務獎勵(reward)的總和。評價者網絡通過時間差異學習來學習預測未來任務獎勵的總和(Sutton 和 Barto,2018 ),這允許算法學習長期策略。 與 Hafner et al. (2020) 相比,Dreamer 方法沒有訓練頻率超參數,因為學習器優化神經網絡與數據收集并行進行,沒有速率限制。 實驗 研究者在 4 個機器人上評估了 Dreamer,為每個機器人分配了不同的任務,并將其性能與算法和人類基線進行比較,目的是評估近期學習世界模型的成功是否能夠直接在現實世界中實現樣本高效的機器人學習。 這些實驗代表了常見的機器人任務,例如運動、操縱和導航,帶來了各種各樣的挑戰,包括連續和離散的動作、密集和稀疏的獎勵、本體感受和圖像觀察,以及傳感器融合。 A1 機器狗四足步行 如圖 4 所示,經過一小時的訓練,Dreamer 學會了不斷地讓機器人從其背部翻過來、站起來,然后向前走。在訓練的前 5 分鐘,機器人設法從背部翻滾過來并用腳著地。20 分鐘后,它學會了如何站起來。大約 1 小時后,機器人學會了一種叉式步態,以所需的速度向前行走。

在成功完成這項任務后,研究者用一根棍子反復敲打機器人的四足來測試算法的魯棒性,如圖 8 所示。在額外在線學習的 10 分鐘內,機器人會適應并承受推力或快速翻身站穩。相比之下,SAC 也很快學會了翻身,但由于數據預算(data budget)太小,無法站立或行走。

UR5 多物體視覺拾取和放置 拾取和放置任務在倉庫和物流環境中很常見,需要機械臂將物品從一個箱子運輸到另一個箱子。圖 5 展示了成功拾取和放置的循環。由于獎勵稀疏、需要從像素推斷對象位置以及多個移動對象的挑戰性動態,該任務具有一定挑戰性。

XArm 視覺拾取和放置 上面提到的 UR5 機器人是高性能工業機器人,但 XArm 是一種可訪問的低成本 7 DOF 操作,此處任務類似,需要定位和抓取一個柔軟的物體,將其從一個容器移到另一個容器并返回,如圖 6 所示。

Sphero 導航 此外,研究者還在視覺導航任務上評估了 Dreamer,該任務需要將輪式機器人操縱到固定目標位置,僅給定 RGB 圖像作為輸入。這里使用了 Sphero Ollie 機器人,一個帶有兩個可控電機的圓柱形機器人,研究者通過 2 Hz 的連續扭矩命令對其進行控制。鑒于機器人是對稱的,并且機器人只能獲得圖像觀察,它必須從觀察歷史中推斷出航向。

2 小時內,Dreamer 學會了快速且始終如一地導航到目標,并保持在目標附近。如圖 7 所示,Dreamer 與目標的平均距離為 0.15(以區域大小為單位測量并跨時間步求平均值)。
審核編輯 :李倩
-
機器人
+關注
關注
211文章
28390瀏覽量
206957 -
算法
+關注
關注
23文章
4608瀏覽量
92845
原文標題:1小時學會走路,10分鐘學會翻身,世界模型讓機器人迅速掌握多項技能
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
《具身智能機器人系統》第1-6章閱讀心得之具身智能機器人系統背景知識與基礎模塊
復合機器人正逐漸在倉儲物流領域發揮重要作用

FOC電機在機器人技術中的作用
解鎖機器人視覺與人工智能的潛力,從“盲人機器”改造成有視覺能力的機器人(上)

構建語音控制機器人 - 線性模型和機器學習
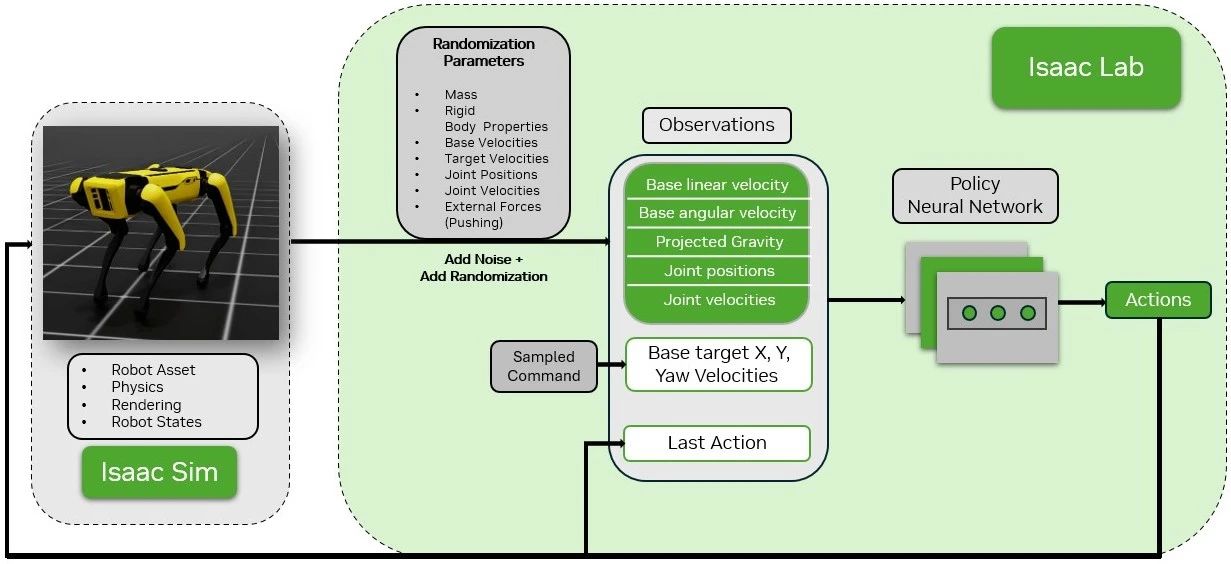
在NVIDIA Isaac Lab中訓練四足機器人運動
在生產制造業中,碼垛機器人發揮的重要作用
Al大模型機器人
編碼器在機器人系統中的應用
英偉達發布人形機器人基礎模型
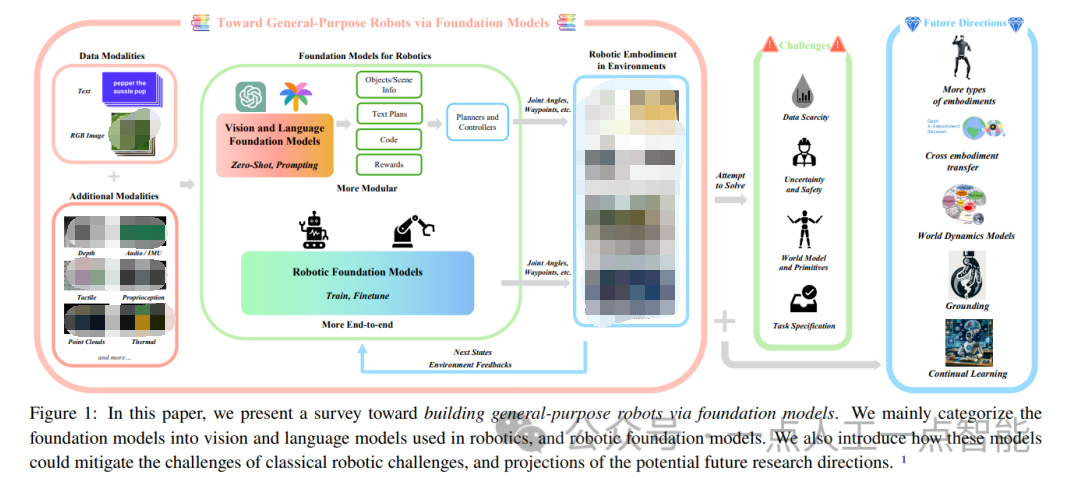
基礎模型能為機器人帶來怎樣的可能性?






 工商網監
工商網監
評論