

1.簡介
隨著預訓練模型的發展,研究者也開始嘗試將預訓練模型的架構和方法應用于多模態任務當中。在圖片-文本多模態任務當中,預訓練模型的應用已經取得了出色的表現。相比于圖片,視頻內容中包含的信息更加豐富而冗余,多幀之間可能包含高度相似的畫面。與圖片不同,視頻內容中自然地包含了時序信息,隨著視頻時間長度的增長,其包含的時序信息也愈加豐富。同時,由于視頻數據的體積相較于圖片而言也更加龐大,數據集、模型的構建都為研究者提出了更大的挑戰。因此,如何更優雅,高質量地建立視頻-文本表示之間的聯系、進行良好的交互,并為下游任務帶來提升,就成為了研究者們探究的問題。
本文簡單梳理了當前視頻-文本預訓練的模型架構及相關數據集,同時,針對視頻信息較為冗余的特點,對引入細粒度信息的工作進行了簡要介紹。
2. 常用預訓練數據集
多模態預訓練的數據通常來源于大規模的模態間對齊樣本對。由于時序維度的存在,視頻當中包含了比圖片更加豐富而冗余的信息。因此,收集大規模的視頻-文本對齊數據對用于視頻預訓練存在較高的難度。目前,大部分研究者所使用的公開預訓練數據集主要包括HowTo100M[1]和WebVid[2]數據集,此外,由于視頻和圖片特征的相似性,也有非常多工作利用圖片-文本預訓練數據集進行訓練,本節主要對視頻-文本預訓練中常用的數據集進行簡單的介紹。
2.1 HowTo100M
學習視頻-文本的跨模態表示通常需要人工標注描述的的視頻片段(clip),而標注一個這樣的大規模數據集非常昂貴。Miech[1]等人發布了HowTo100M數據集,幫助模型從帶有自動轉寫的旁白文本(automatically transcribed narrations)的視頻數據中學習到跨模態的表示。HowTo100M從1.22M個帶有旁白的教學(instructional)網絡視頻中裁切得到了136M個視頻片段(clip)。視頻的教學內容多由人類展示,包含了超過兩萬三千個不同的視覺任務。

圖1 HowTo100M數據集概覽 研究者從WikiHow中檢索、抽取了23,611個與物理世界能夠產生一定交互的視覺任務,并在YouTube中通過構造關鍵詞搜索相關的視頻,保留包含英語字幕的視頻。英文字幕通過時間軸和具體的視頻Clip構成視頻-文本對,例子如圖2所示。

圖2 數據集中視頻-文本對的例子 與之前的視頻-文本配對數據集不同,HowTo100M數據集中的描述并不是人工標注的,由于旁白的特性,其與對應的視頻clip在時序上可能并未對齊,同時也可能并不是完整的句子。但該數據集的規模足夠龐大,為視頻-文本預訓練的工作進一步提供了可能。 2.2 WebVid WebVid-2M[2]數據集包含了從網絡上爬取的2.5M視頻-文本數據對,與HowTo100M不同,WebVid中包含的視頻數據來自于通用領域。WebVid數據集的構造方式和CC3M[3] 比較類似,研究者發現CC3M中超過10%的圖片事實上都是視頻的概覽,通過找到原視頻,研究者得以爬取2.5M的視頻-文本對。 圖3展示了數據集中的一些樣例,WebVid中的視頻描述風格多樣,包含精簡亦或細節性的描述。

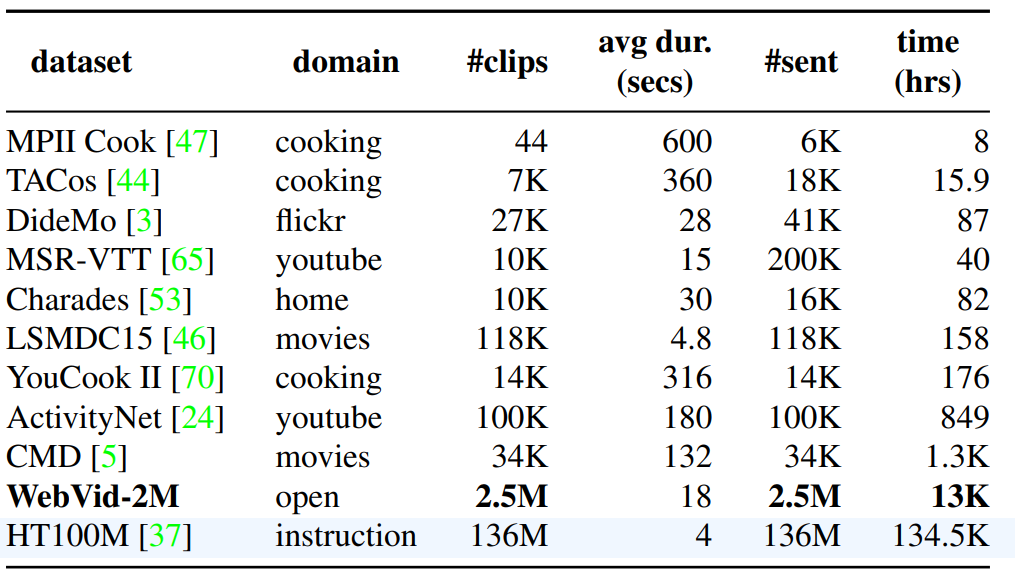
圖3 WebVid數據集的例子 表1列出了現有的部分視頻文本數據集的統計信息,相比于HowTo100M數據集,WebVid的規模僅有不到其1/10。但數據集中的文本通常是人工撰寫的描述,具有較好的句子結構,與視頻具有更好的匹配性,同時也避免了由于ASR撰寫帶來的語法錯誤。 表1 視頻-文本數據集的統計數據[2]
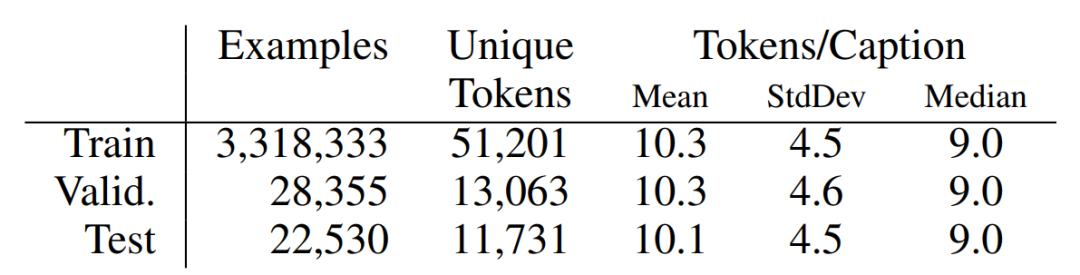
2.3 Conceptual Captions 視頻是由多幀靜態圖片組合而成,由于視頻資源收集的難度較大,研究人員也常使用大規模圖片文本數據集來擴大預訓練數據的規模,增強模型的泛化性。Conceptual Captions[3] 由Google的研究人員于2018年發布,研究人員通過從數十億的網頁中提取、過濾得到了大規模的圖片-描述文本對。為了使圖片描述更加干凈易用,其基于描述文本和圖片自動生成了對應的轉換描述,稱之為Conceptual Captions。數據集的統計數據如表2所示。
表3 Conceptual Captions的統計數據[3]
3. 模型架構 視頻-文本預訓練模型涉及到對視頻、文本的編碼和處理,通常可以粗略地分為單流(Single-Stream)架構和多流(Multi-Stream)架構。對于Single-Stream架構的模型,不同模態的特征/表示被輸入到一個單獨的跨模態編碼器中,捕捉他們的模態內/間交互信息。而對于Multi-Stream架構,視頻、文本將被輸入到各自模態獨立的編碼器中,捕捉模態內部的表示信息,再通過不同的方式建立跨模態的聯系。本節將對不同架構的模型進行簡單介紹,對于引入更細粒度信息的模型,我們將在后面的章節進行介紹。 3.1 Single-Stream 3.1.1VideoBERT VideoBERT[4]是第一個利用Transformer架構探究視頻-文本表示的預訓練模型。從BERT[5]中獲得啟發,研究人員嘗試將視頻內容進行量化,對于視頻Clip進行編碼,聚類,從中抽取得到離散的表示,稱之為視覺詞語(video words),對于每一個視頻,其都可以由多個視覺詞語進行表示,并能夠和文本一同輸入到編碼器中進行聯合的表示學習,其架構如圖4所示。
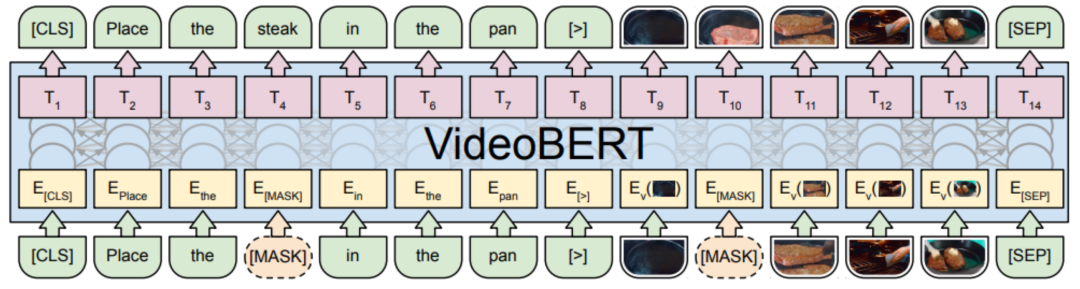
圖4 VideoBERT模型架構[4] 與BERT相似,VideoBERT引入了文本、視頻兩個模態的掩碼完型任務(mask-completion),具體而言,就是利用上下文和跨模態信息恢復被[MASK]標簽遮蓋的視頻/文本token。同時,為了建模跨模態之間的關聯性,VideoBERT也利用[CLS]標簽位置的編碼判斷視頻和文本之間是否時序/語義對齊。 3.1.2 ClipBERT 前人工作通常使用在不同領域預訓練的視頻編碼器抽取得到的密集(dense)視頻特征,ClipBERT[6] 利用了視頻和圖片之間的相似性,通過對視頻進行稀疏(sparse)采樣的方式對其進行編碼,并實現了端到端的預訓練。 具體而言,研究人員隨機采取多個視頻片段(Clip),對于每個視頻片段進行稀疏采樣,以視頻幀為單位進行編碼得到表示;對于不同Clip不同幀的表示,可以進行時空上的信息融合,得到的表示將和文本編碼共同輸入到Transformer架構的編碼器當中,如圖5所示。以視頻幀為單位進行編碼,使得模型能夠僅利用圖片-文本數據集進行預訓練(將圖片看作只有一幀的視頻),再在下游任務上利用視頻進行訓練。在預訓練階段,模型僅僅采用掩碼語言建模,以及利用[CLS]標簽進行視覺-文本匹配,來學習跨模態的表示。
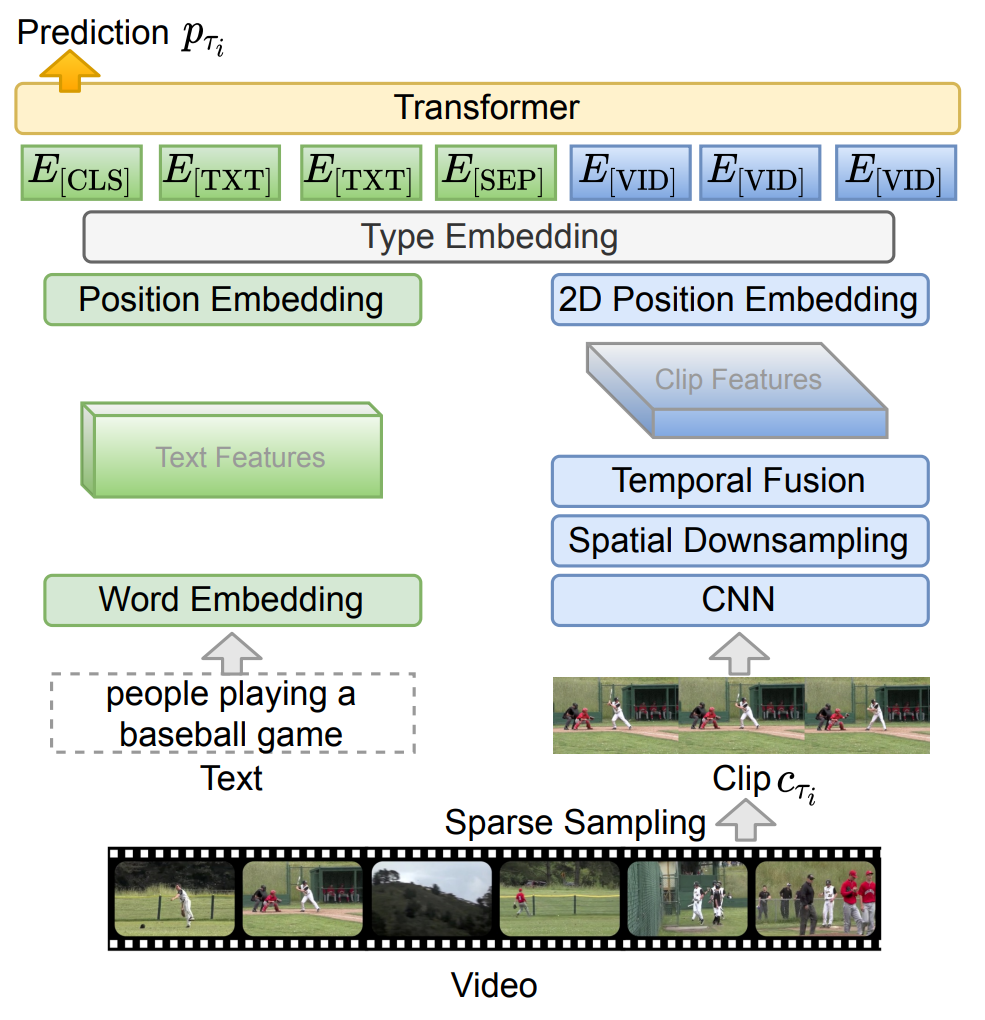
圖5 ClipBERT架構[6] 3.1.3 VLM VLM[7]提出了一個簡單、下游任務無關的預訓練方法,統一了視頻、文本的表示,能夠接受視頻、文本的單模態輸入,亦或視頻-文本的聯合輸入。如圖6所示,模型引入了掩碼表示建模(視頻幀或者文本token)來建立模態內部的表示;同時引入掩碼模態建模任務(MMM),一次性遮蓋整個視頻或整個文本模態,指導模型利用跨模態交互來恢復信息。
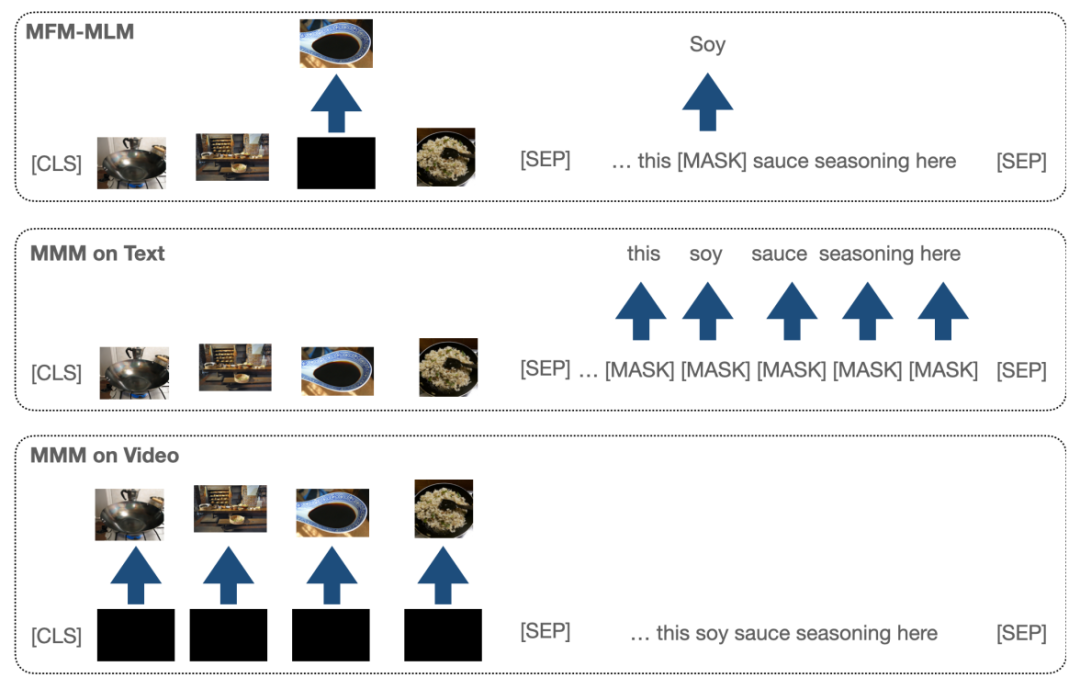
圖6 VLM的預訓練范式[7] 3.2Multi-Stream 3.2.1 CBT CBT[8]提出通過有噪對比估計(noise contrastive estimation, NCE)來學習視頻-文本的表示。CBT拓展了BERT的架構來建立跨模態的表示,在預訓練階段,兩個單模態的Transformer分別被用于學習視頻和文本的表示,并利用一個跨模態Transformer來建立兩個模態的聯合表示。由于視頻特征是連續的,對于視頻的單模態編碼器和跨模態編碼器,模型通過有噪對比估計來學習其表示。具體而言,對于單模態視頻編碼器,其損失函數具有如下的形式:
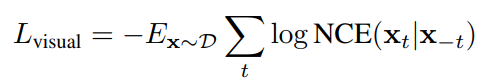
?
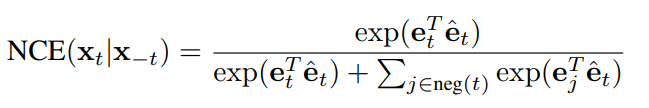
其中 是 3D 編碼器的編碼輸出,而 是視頻 Transformer 的編碼輸出。而對于跨模態 Transformer 的聯合表示,其損失函數具有如下的形式:
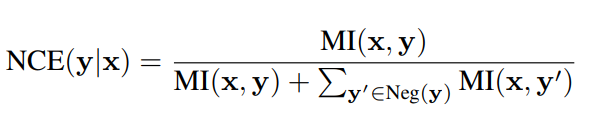
其中MI(x,y)代表將視頻,文本模態進行聯合編碼之后得到的聯合隱層表示輸出。
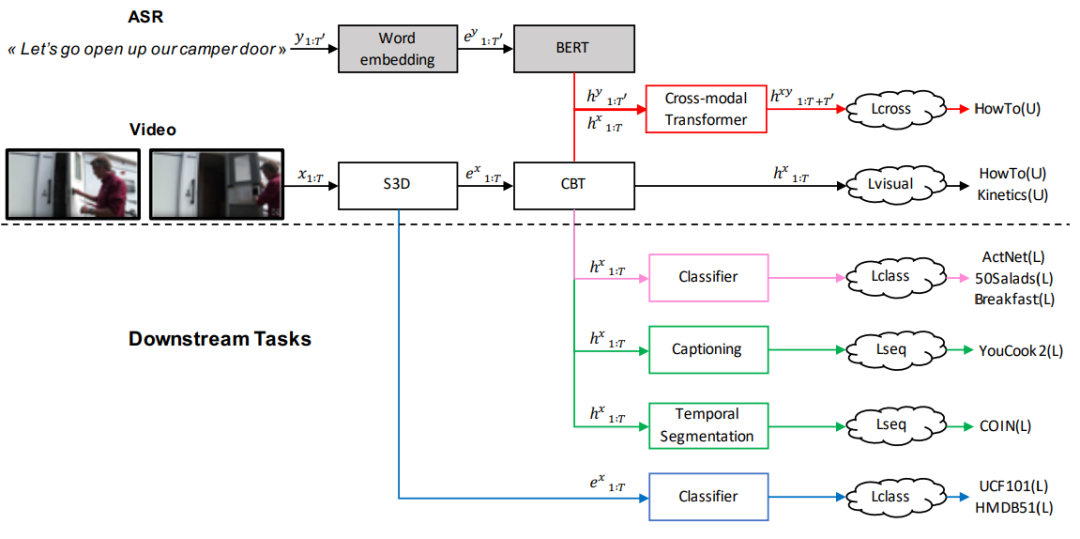
圖7:CBT模型的架構[8] 3.2.2 UniVL 大多數跨模態模型僅僅應用于下游的多模態理解任務,并未過多探索跨模態的生成任務。UniVL[9]建立了一個支持生成任務和理解任務的多模態框架。其架構大致如圖8所示,UniVL將單模態編碼器編碼后的隱向量,輸入到一個跨模態的編碼器-解碼器架構當中。通過NCE建立跨模態之間的相似性,使得同一個視頻-文本對,其不同模態編碼器編碼之后的結果在表示上具有較好的相關性;同時通過跨模態的掩碼語言建模和掩碼幀建模來建立跨模態的交互。同時,利用解碼器進行文本重建,為模型引入跨模態的生成能力。編碼器-解碼器架構的引入使得模型能夠自然地應用到下游的描述生成任務當中。
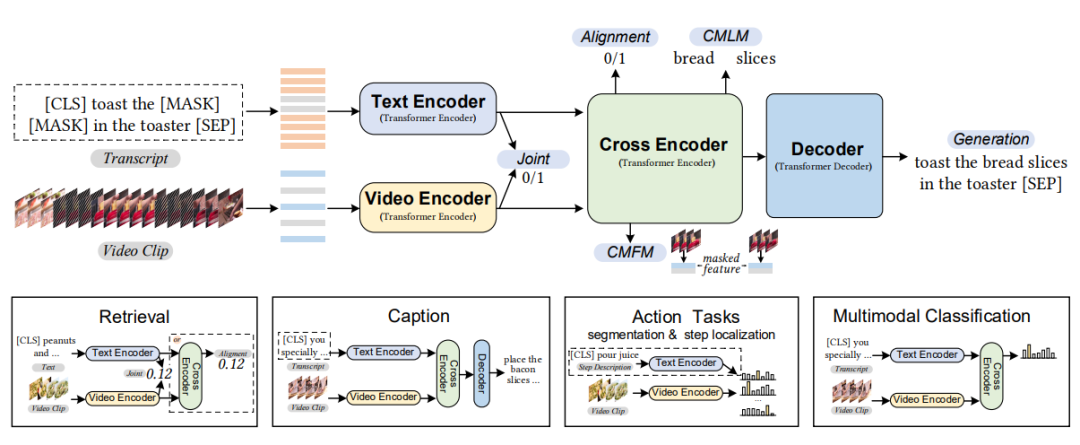
圖8 UniVL的框架、預訓練任務和下游任務的應用[9] 3.2.2 Frozen Fronzen[2]提出了一個專為檢索任務設計的預訓練框架。將圖片看作視頻的“快照”,將圖文數據集作為視頻數據集的一部分進行預訓練,利用圖文數據集增大了預訓練的規模,同時利用視頻-文本數據集學習關注視頻內容中獨有的時序信息。為了高效地進行跨模態檢索,作者利用單模態的編碼器編碼兩個模態的信息,并將兩個模態的信息分別投影至一個共同的表示空間,計算其相似度。其架構大致如圖9所示。視頻以幀為單位進行輸入,而圖片則相當于僅包含一幀的視頻,同時,模型也引入了space-time transformer[10]來建模視頻中的時空信息。在預訓練階段,NCE同樣被用作衡量訓練的損失,模型交替利用視頻數據和文本數據進行預訓練。
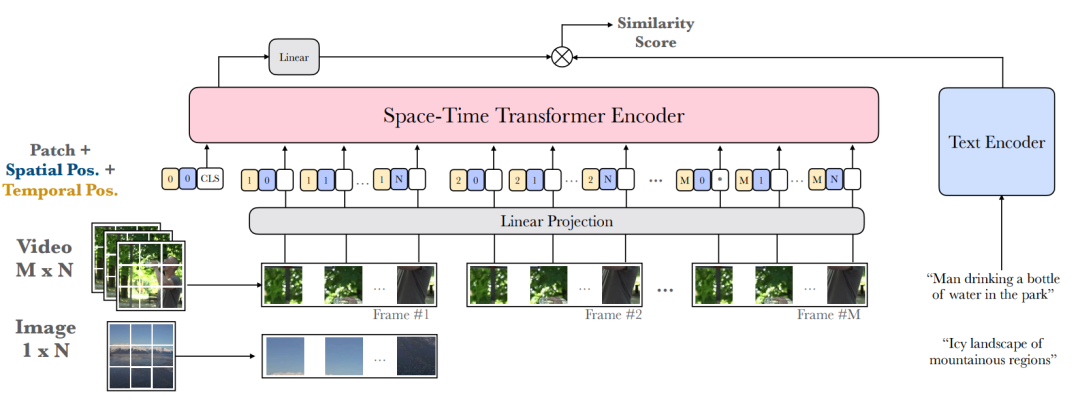
圖9 Frozen的模型架構[2] 4. 預訓練中的細粒度信息 相比于圖片,視頻中包含的信息通常較為豐富而冗余,例如,在連續的幀之間,動作、場景等內容可能高度相似。基于密集采樣的方法將會極大增加計算量,而基于稀疏采樣的方式又會損失過多細粒度信息。如何從視頻內容中提取理解視頻所需要的細粒度信息,并加以利用,增強對視頻內容的理解和跨模態表示的學習,也成為研究者所探究的問題之一。 4.1 基于時空信息 與圖片相比,視頻內容中包含更加豐富的時序信息和空間信息,建模視頻中的時空信息,對理解視頻內容具有十分重要的作用。 4.1.1 HERO 較少工作顯式地探究模型對視頻時序信息的理解。HERO[11]在單流跨模態Transformer的架構之上,引入了一個時序Transformer來建模視頻中的時序信息,同時利用掩碼幀預測(MFM)和幀順序預測(FOM)來增強模型對視頻中時序信息的理解。具體而言,MFM任務要求模型通過文本信息和視頻上下文來恢復當前幀的內容(通過回歸或者有噪對比估計NCE的形式);FOM則將跨模態編碼后的幀信息按比例進行打亂,要求時序Transformer架構嘗試利用視頻上下文和按時序排列的字幕(subtitle)信息恢復被打亂的幀的順序,如圖10所示。
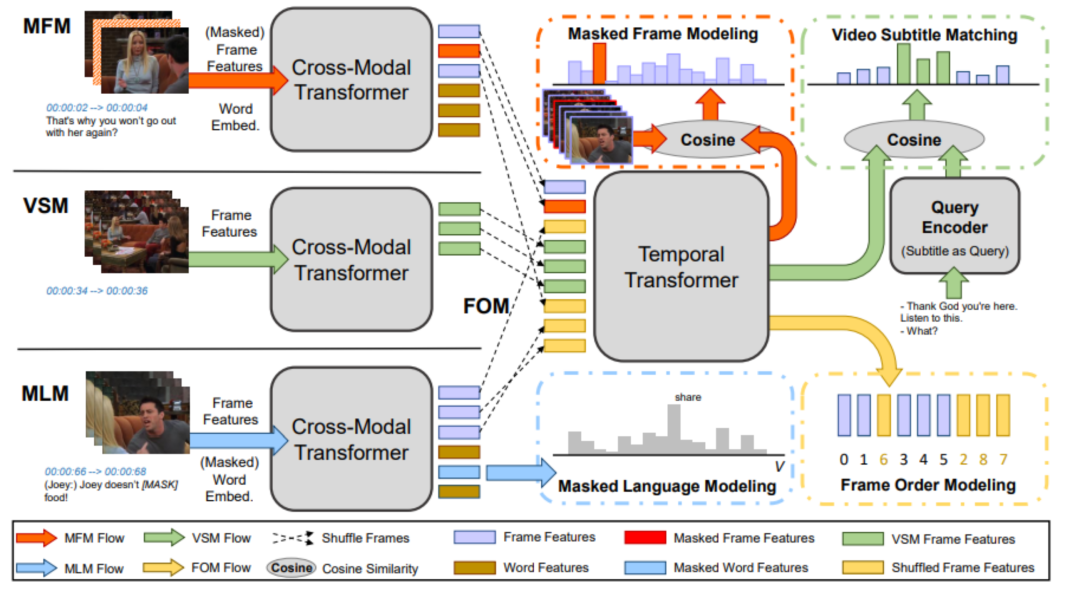
圖10 HERO的模型架構[11] 4.1.2Merlot 包含密集視頻描述(Dense caption)的視頻內容通常包括豐富的跨模態時序對齊信息,Merlot[12]通過視頻幀-描述匹配(Contrastive frame-transcript matching)來建模視頻內部的時序信息。Merlot的輸入是稀疏采樣的視頻幀,和視頻幀對應的描述,模型通過最大化視頻幀和對應描述的相似度,最小化和視頻內其他幀視頻描述相似度來建立視頻和文本之間的時序對齊信息;與HERO不同,Merlot利用時序重排序(Temporal Reordering)任務,按比例打亂視頻幀的順序,并判斷幀之間的相對順序來指導模型關注視頻內部的時序信息。
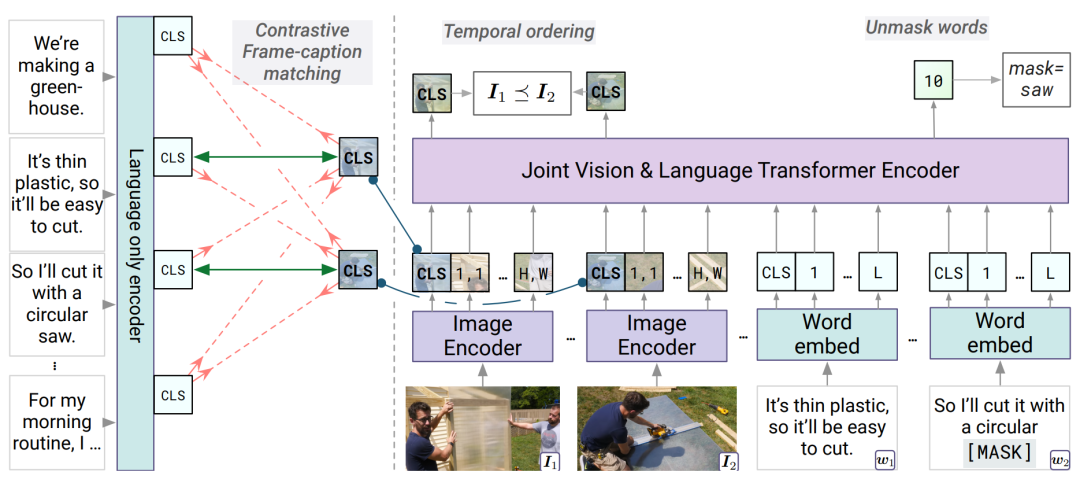
圖11 Merlot模型的架構[12] 4.1.3 DECEMBERT HowTo100M數據集中的對齊文本通常來自于自動語音識別(ASR),包含較多噪聲,而人類可能還會描述已經發生或者還未發聲的場景,導致文本和視頻片段的時序上并未完全對齊,或語義不一致。如圖12所示,DECEMBERT[13]從視頻Clip中抽重新取了較為密集的caption來緩解噪聲和語義不一致的問題;同時引入視頻片段上下文的文本描述,來緩解可能產生的時序不一致問題。
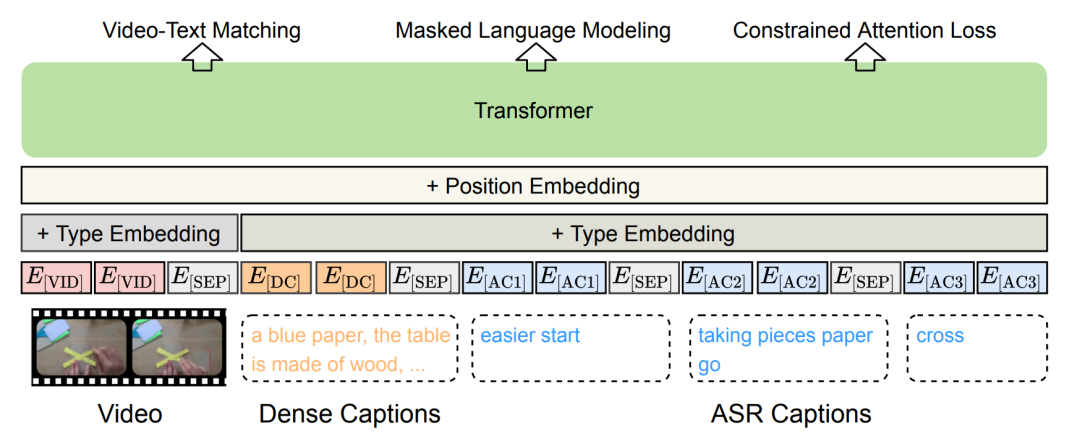
圖12 DECEMBERT的架構[13] 4.1.4 Violet 許多工作將視頻看作是靜態圖片的集合,忽略了時序上信息具有一定的連續性,基于此特點設計的視覺掩碼任務可能會失效。Violet[14]利用Discrete VAE[22]將視頻的patch特征離散化為一系列視覺token,視頻編碼和文本編碼聯合輸入跨模態Transformer后,掩碼視覺token建模任務要求模型從視覺掩碼輸出中恢復對應的離散視覺token,與掩碼語言建模任務得到了統一。同時,模型引入了基于塊(Block wise)的離散視覺掩碼任務,基于時間、空間同時掩碼多個連續位置,防止其簡單地從時空連續的位置恢復被掩碼的信息。此外,一般的掩碼方法以同樣的概率遮蓋重要/不重要的位置,Violet引入了Attended Masking的方法,利用跨模態的注意力權重,嘗試遮蓋模型認為更重要的區域,以提升掩碼任務的難度。
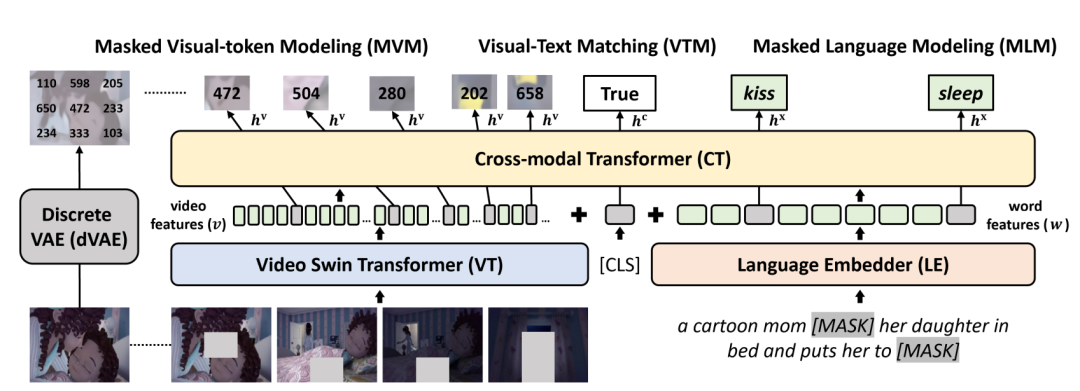
圖13 Violet模型架構[14] 4.2 基于實體和動作 基于patch或者視頻級特征的編碼方式隱式地編碼了視頻中的各類信息,粗粒度的視頻-文本對齊方式可能難以挖掘視頻中包含的細粒度信息。下面的一些工作也嘗試引入了實體和動作等更細粒度的監督信息,增強跨模態的表示學習和建模。 4.2.1 ActBERT
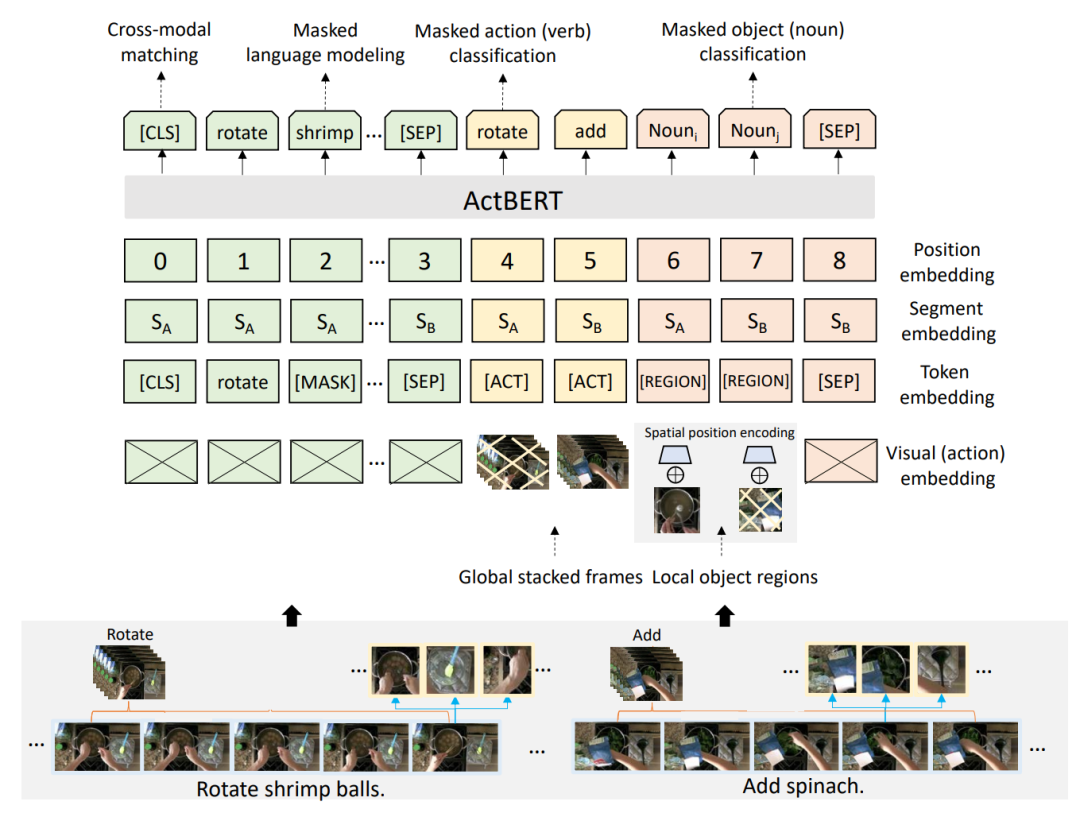
圖14 ActBERT的模型架構[15] 將視頻離散化,與文本共同輸入Transformer進行跨模態聯合建模的方式可能會丟失很多細粒度的信息,ActBERT[15]通過在預訓練數據集上訓練一個視頻動作編碼器,獲得視頻的動作編碼,同時引入目標檢測工具來獲得視頻內容中的物體信息編碼。通過建立文本-動作-視頻區域間的糾纏編碼架構,來建立視頻動作和區域信息與文本信息之間的交互,進而也保留了重要的時序信息。 4.2.2 OA-Trans Multi-Stream跨模態表示學習通常建立視頻-文本之間的整體對齊,并未探究更細粒度的對齊,OA-Trans[16]引入了對關鍵幀目標檢測得到的實體區域信息和對應的標簽。如圖15所示,模型將關鍵幀中不包含實體區域的位置進行掩碼,經過時空編碼得到剩余位置對應的表示,同時將實體區域的類別信息輸入文本編碼器進行編碼。簡單將獲得的細粒度表示進行對齊,將對下游任務沒有太多幫助。在不修改模型架構的前提下,研究者嘗試建立單模態細粒度表示和另一個模態整體表示之間的相似度聯系,指導單模態的整體表示能夠蘊含更多細粒度的信息,在應用于下游任務時,預訓練所用的細粒度表示可以被去除,而單模態的整體表示已經一定程度上具備保留細粒度信息的能力。
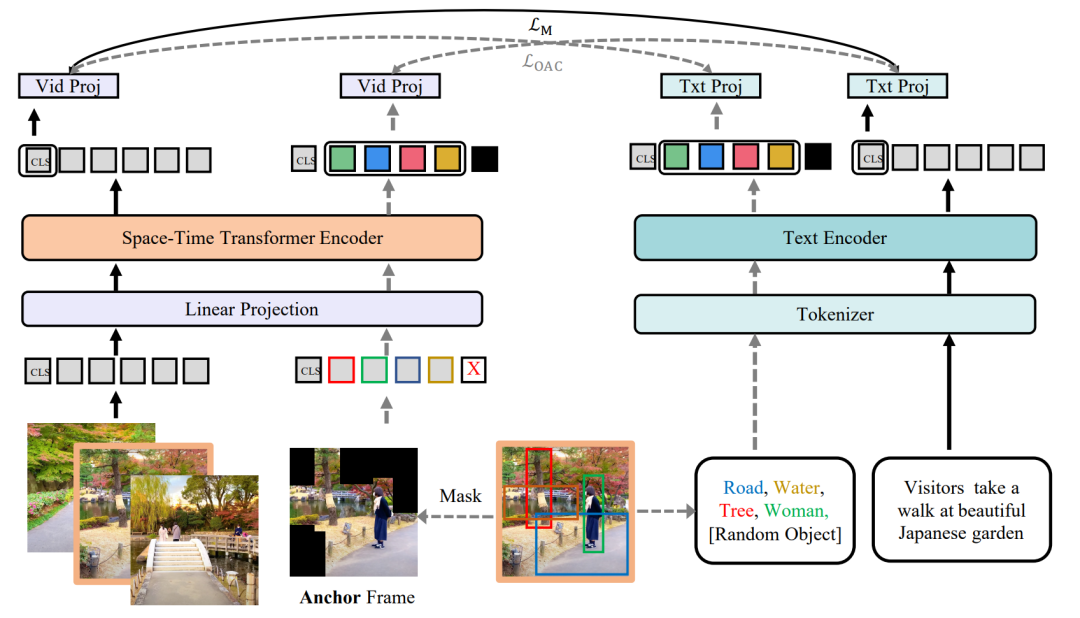
圖15 OA-Trans的模型架構[16] 4.2.3 ALPRO 引入細粒度的信息通常需要借助外部的特征抽取工具,這種做法不僅影響效率,由于特征抽取工具的類別數量等限制,效果也不盡如人意。如圖16所示,ALPRO[17]基于CLIP[18]的思想,首先基于視頻-文本對訓練了一個視頻-文本匹配架構(和ALRP的單模態編碼器具有相同的架構),通過提示描述*[CLS] A video of a [object]*,根據視頻和描述的相似度,能夠識別出視頻中包含的實體。在訓練過程中,模型隨機裁剪一段視頻,利用匹配架構獲得視頻的實體信息作為監督信號,引入提示實體匹配(Prompt Entity Matching)任務,要求跨模態編碼器能夠識別出對應裁剪位置的實體信息,以此建立視頻對細粒度實體信息和場景的理解。
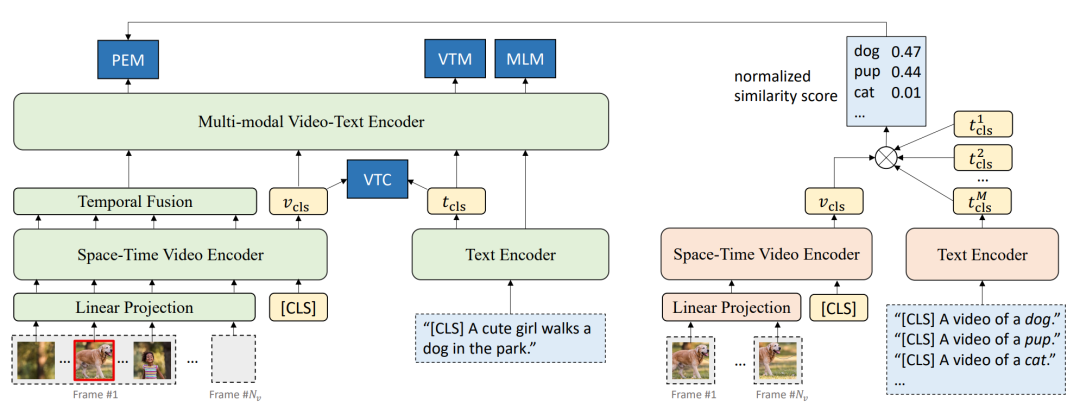
圖16 ALPRO的模型架構[17] 4.2.4 BridgeFormer 相比于利用物體檢測的信息,BridgeFormer[19]利用多項選擇任務(Multiple Choice Questions)來增強模型對視頻中實體新信息和動作信息的理解。具體而言,研究人員從原始文本中遮蓋動詞或名詞短語來構建“問題”,將文本編碼器得到的問題表示作為跨模態Transformer的查詢(Query),將視頻內容編碼表示作為鍵(Key)和鍵值(Value),即將跨模態表示問題形式化為了給定問題,從視頻中進行查詢,獲得答案的過程,在應用于下游任務時,單模態編碼器已經學習如何建立到了細粒度的表示跨模態模塊可以被去除。
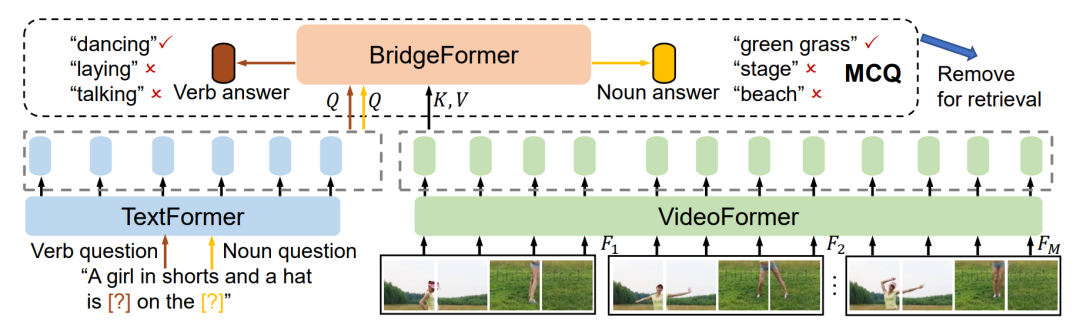
圖17 BridgeFormer的模型架構[19] 4.3 隱式細粒度特征 相比于考慮顯式的細粒度特征,如時序、實體、動作等信息,也有部分工作認為除了視頻、文本的整體表示,還可以考慮幀、patch級別的不同粒度表示,來隱式編碼細粒度特征。 4.3.1 HiT 在Transformer架構中,不同的層將聚焦于不同粒度的表示信息, 例如較低層的注意力記住傾向于編碼更加基礎表面的表示,而更高層的注意力機制,將會捕捉更加復雜的語義信息,基于這樣的想法,HiT[20]提出了分層跨模態的對比匹配機制,來建立不同粒度的跨模態表示對齊,具體而言,模型分別從視頻、文本Query編碼器的第一層和最后一層獲得低層次特征級別和高層次語義級別的表示。并分別與另一模態的高層次編碼結果進行表示匹配,如圖18所示。
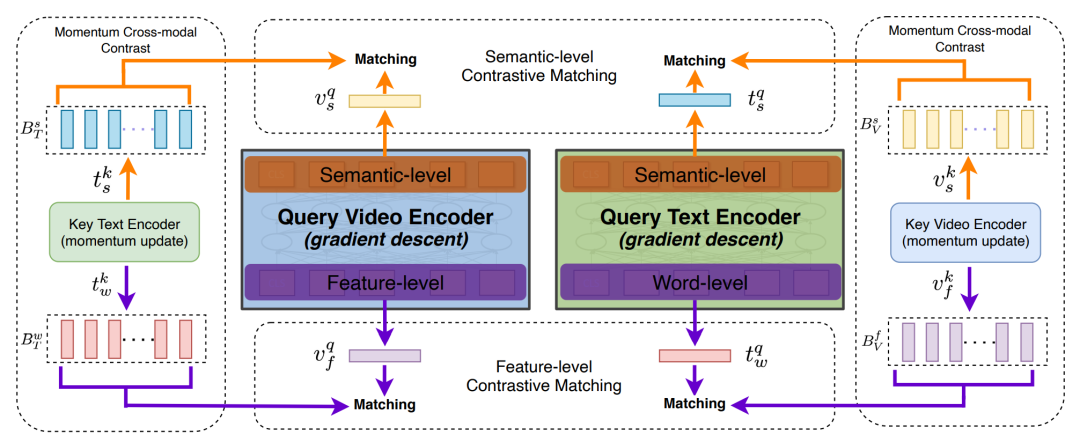
圖18 HiT的模型架構[20] 4.3.2 HunYuan_tvr 大部分的檢索模型都聚焦于建立視頻整體和整個對應文本之間的表示關系,HunYuan_tvr[21]從多個層次探究了細粒度表示的關系,通過建模幀-詞語,視頻片段-短語,視頻-句子三個不同粒度跨模態表示之間的表示匹配,提出了層次化的跨模態交互方法來學習細粒度的跨模態聯系,大致如圖19所示。
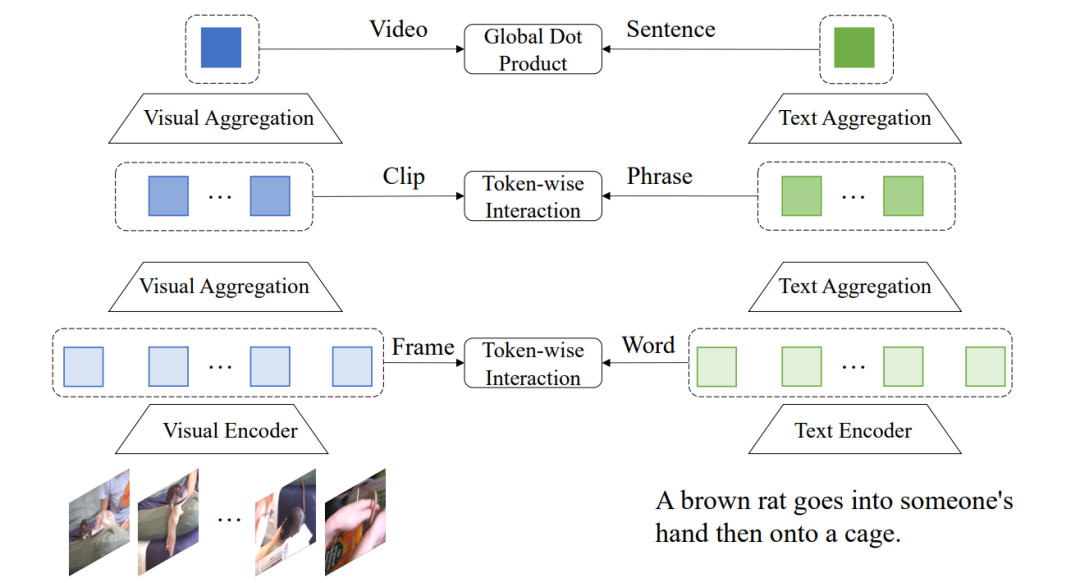
圖19:HunYuan_tvr的大致模型架構[21] 5. 總結 本文簡單梳理了當前視頻-文本預訓練的模型架構及相關數據集,同時,針對視頻信息較為冗余的特點,對引入細粒度信息的工作進行了介紹。 經過梳理和分析我們可以發現,目前視頻-文本預訓練的數據集由于收集和標注的難度較大,可用的數據集數量和規模和圖-文預訓練相比仍然較少,同時也缺乏更加細粒度的標注。 而為了減少對計算資源的依賴,同時更好地利用圖片-文本預訓練數據,視頻-文本預訓練模型從密集采樣逐漸向稀疏采樣過渡,為了彌補稀疏采樣帶來的信息損失和粗粒度預訓練數據的監督信息缺乏,不少工作也開始探索如何抽取、或者通過無監督的方式來獲得有用的細粒度信息,進一步增強細粒度的視頻-文本表示學習。在未來,構建更大規模、更細粒度的視頻-文本預訓練數據;考慮更加合理有用的細粒度信息為訓練過程提供幫助;設計、利用更強大的單模態、跨模態模型架構和自監督學習任務都是值得進一步探索的方向。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3501瀏覽量
50152 -
數據集
+關注
關注
4文章
1223瀏覽量
25325 -
文本
+關注
關注
0文章
119瀏覽量
17400
原文標題:視頻文本預訓練簡述
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

用PaddleNLP在4060單卡上實踐大模型預訓練技術

【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
KerasHub統一、全面的預訓練模型庫
如何訓練自己的LLM模型
AI大模型的訓練數據來源分析
直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習






 工商網監
工商網監

評論