 ADS算力芯片的多模型架構研究
ADS算力芯片的多模型架構研究
在過去十幾年里,深度神經網絡(DNN)得到了廣泛應用,例如移動手機,AR/VR,IoT和自動駕駛等領域。復雜的用例導致多DNN模型應用的出現,例如VR的應用包含很多子任務:通過目標檢測來避免與附近障礙物沖突,通過對手或手勢的追蹤來預測輸入,通過對眼睛的追蹤來完成中心點渲染等,這些子任務可以使用不同的DNN模型來完成。像自動駕駛汽車也是利用一系列DNN的算法來實現感知功能,每個DNN來完成特定任務。然而不同的DNN模型其網絡層和算子也千差萬別,即使是在一個DNN模型中也可能會使用異構的操作算子和類型。
此外,Torch、TensorFlow和Caffe等主流的深度學習框架,依然采用順序的方式來處理inference 任務,每個模型一個進程。因此也導致目前NPU架構還只是專注于單個DNN任務的加速和優化,這已經遠遠不能滿足多DNN模型應用的性能需求,更迫切需要底層新型的NPU計算架構對多模型任務進行加速和優化。而可重配NPU雖然可以適配神經網絡層的多樣性,但是需要額外的硬件資源來支持(比如交換單元,互聯和控制模塊等),還會導致因重配網絡層帶來的額外功耗。
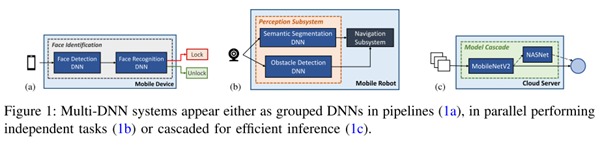
開發NPU來支持多任務模型面臨許多挑戰:DNN負載的多樣性提高了NPU設計的復雜度;多個DNN之間的聯動性,導致DNN之間的調度變得困難;如何在可重配和定制化取得平衡變得更具挑戰。此外這類NPU在設計時還引入了額外的性能標準考量:因多個DNN模型之間的數據共享造成的延時,多個DNN模型之間如何進行有效的資源分配等。
目前的設計研究的方向大體可以分成以下幾點:多個DNN模型之間并行化執行,重新設計NPU架構來有效支持DNN模型的多樣性,調度策略的優化等。
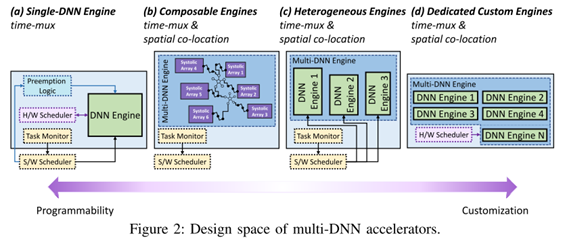
DNN之間的并行性和調度策略:
可以使用時分復用和空間協同定位等并行性策略。調度算法則大概可以分為三個方向:靜態與動態調度,針對時間與空間的調度,以及基于軟件或者硬件的調度。
時分復用是傳統優先級搶占策略的升級版,允許inter-DNN的流水線操作,來提高系統資源的利用率(PE和memory等)。這種策略專注調度算法的優化,好處是對NPU硬件的改動比較少。
空間協同定位則專注于多個DNN模型執行的并行性,也就是不同DNN模型可以同時占用NPU硬件資源的不同部分。這要求在設計NPU階段就要預知各個DNN網絡的特性以及優先級,以預定義那部分NPU硬件單元分配給特定的DNN網絡使用。分配的策略可以選擇DNN運行過程中的動態分配,或者是靜態分配。靜態分配依賴于硬件調度器,軟件干預較少。空間協同定位的好處是可以更好的提高系統的性能,但是對硬件改動比較大。
動態調度與靜態調度則是根據用戶用例的特定目標來選擇使用動態調度或者靜態調度。
動態調度的靈活性更高,會根據實際DNN任務的需求重新分配資源。動態調度主要依賴于時分復用,或者利用動態可組合引擎 (需要在硬件中加入動態調度器),算法則多數選擇preemptive策略或者AI-MT的早期驅逐算法等。
對于定制化的靜態調度策略,可以更好的提高NPU的性能。這種調度策略是指在NPU設計階段就已經定制好特定硬件模塊去處理特定神經網絡層或者特定的操作。這種調度策略性能高,但是硬件改動比較大。
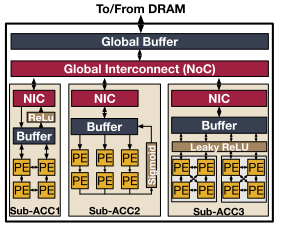
異構NPU架構:
結合動態可重構和定制化的靜態調度策略,在NPU中設計多個子加速器,每個子加速器都是針對于特定的神經網絡層或者特定的網絡操作。這樣調度器可以適配多個DNN模型的網絡層到合適的子加速器上運行,還可以調度來自于不同DNN模型的網絡層在多個子加速器上同步運行。這樣做既可以節省重構架構帶來的額外硬件資源消耗,又可以提高不同網絡層處理的靈活性。
異構NPU架構的研究設計可以主要從這三個方面考慮:
1)如何根據不同網絡層的特性設計多種子加速器;
2)如何在不同的子加速器之間進行資源分布;
3)如何調度滿足內存限制的特定網絡層在合適的子加速器上執行。
審核編輯 :李倩
-
加速器
+關注
關注
2文章
796瀏覽量
37840 -
神經網絡
+關注
關注
42文章
4771瀏覽量
100715 -
算力芯片
+關注
關注
0文章
46瀏覽量
4516
原文標題:ADS算力芯片的多模型架構研究
文章出處:【微信號:iotmag,微信公眾號:iotmag】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ChatGPT背后的算力芯片
名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
【「大模型時代的基礎架構」閱讀體驗】+ 未知領域的感受
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
AI算力研究框架(2023)

科大訊飛、華為強強聯合:攻關算力卡脖子問題
打通AI芯片到大模型訓練的算力橋梁,開放加速設計指南強力助推







 工商網監
工商網監
評論