

作者:許勝寶,鄭飂默,袁德成
布匹缺陷檢測任務的難點可能有以下幾個方面:小目標問題,缺陷具有極端的寬高比,樣本不均衡。在MS COCO數據集[1]中,面積小于32×32像素的物體被認為是小目標。小目標具有分辨率低,圖像模糊,攜帶的信息少的特點,導致其特征表達能力弱,也就是在提取特征過程中,能提取到的特征非常少,不利于其檢測;布匹疵點由于生產工藝的原因常常具有極端的寬高比,例如斷經、斷緯等,給其邊界框的預測增添了難度;樣本不均衡是指部分疵點擁有大量的訓練樣本,而另一部分疵點則只有少數的樣本,讓分類器學習起來很困難。 針對小目標問題,Hu等[2]認為小目標在ROI池化之后會破壞小尺度目標的結構,導致物體結構失真,于是提出了新的場景感知ROI池化層,維持場景信息和小目標的原始結構,可以在不增加額外時間復雜度的前提下提升檢測精度;Li等[3]提出了Perceptual GAN網絡來生成小目標的超分表達,Perceptual GAN利用大小目標的結構相關性來增強小目標的表達,使其與其對應大目標的表達相似,從而提升小目標檢測的精度。 針對布匹缺陷極端的長寬比,陳康等[4]提出了通過增加錨定框的尺寸和比例來增加錨定框的數量,最終提升了對多尺度目標的檢測。孟志青等[5]提出基于快速搜索密度頂點的聚類算法的邊框生成器,結合真實框的分布特征分區間對聚類中心進行加權融合,使區域建議網絡生成的邊界框更符合布匹疵點特征。 針對樣本不均衡,Chawla等[6]提出了人工少數類過采樣法,非簡單地對少數類別進行重采樣,而是通過設計算法來人工合成一些新的少數樣本,減少隨機過采樣引起的過度擬合問題,因為生成的是合成示例,而不是實例的復制,也不會丟失有用的信息;Yang等[7]通過半監督和自監督這兩個不同的視角去嘗試理解和利用不平衡的數據,并且驗證了這兩種框架均能提升類別不均衡的長尾學習問題。 針對布匹疵點小目標多,極端長寬比的問題,本文提出一種改進的Cascade R-CNN[8]布匹疵點檢測方法,為適應布匹疵點的極端長寬比,在特征提取網絡的后三個階段采用了可變形卷積(DCN)v2[9],在RCNN部分采用了在線難例挖掘(OHEM)[10]來提高小目標的檢測效果,并采用完全交并比損失函數(CIoU Loss)[11]進一步提升目標邊界框的回歸精度。
改進Cascade R-CNN的面料疵點檢測方法
Faster R-CNN[12]的單一閾值訓練出的檢測器效果有限,本文采用了Cascade R-CNN網絡結構,如圖1所示。其在Faster R-CNN的基礎上通過級聯的方式逐階段提高IoU的閾值,從而使得前一階段重新采樣過的建議框能夠適應下一個有更高閾值的階段。工業場景下目標面積小,特征微弱,通過多級調整,可以使網絡集中于低占比的缺陷目標,最終獲得更為精確的檢測框。
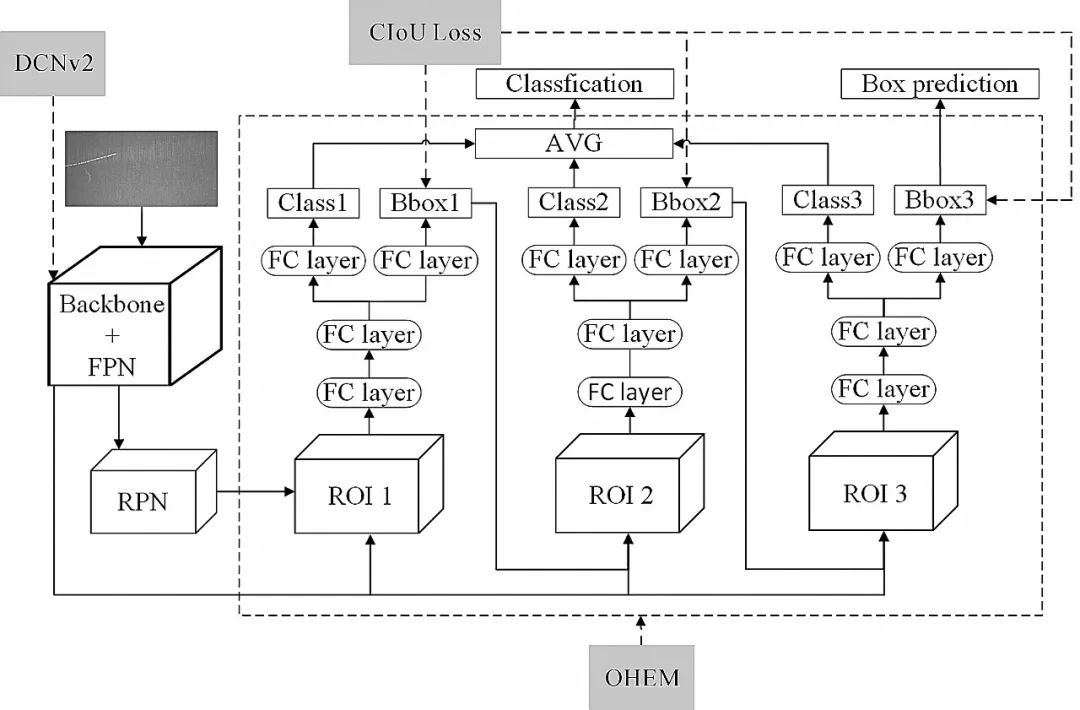
圖1 Cascade R-CNN網絡結構
Fig.1 Architecture of the Cascade R-CNN network
考慮到實驗環境的顯存和算力,骨干網絡主要采用了ResNet50[作為特征提取網絡來進行對比實驗,并接入特征金字塔網絡進行多尺度的特征融合,提升對小目標的檢測效果。
1.1 在線難例挖掘采樣
在兩階段的目標檢測模型中,區域建議網絡會產生大量的建議框,但一張圖片的目標數量有限,絕大部分建議框是沒有目標的,為了減少計算量,避免網絡的預測值少數服從多數而向負樣本靠攏,需要調整正負樣本之間的比例。 目前常規的解決方式是對兩種樣本進行隨機采樣,以使正負樣本的比例保持在1∶3,這一方式緩解了正負樣本之間的比例不均衡,也被大多數兩階段目標檢測方法所使用,但隨機選出來的建議框不一定是易出錯的框,這就導致對易學樣本產生過擬合。 在線難例挖掘就是多找一些困難負樣本加入負樣本集進行訓練,如圖2所示,b部分是a部分的復制,a部分只用于尋找困難負例,b部分用來反向傳播,然后把更新的參數共享到a部分,a部分正常的前向傳播后,獲得每個建議框的損失值,在非極大值抑制后對剩下的建議框按損失值進行排序,然后選用損失較大的前一部分當作輸入再進入b部分進行訓練。
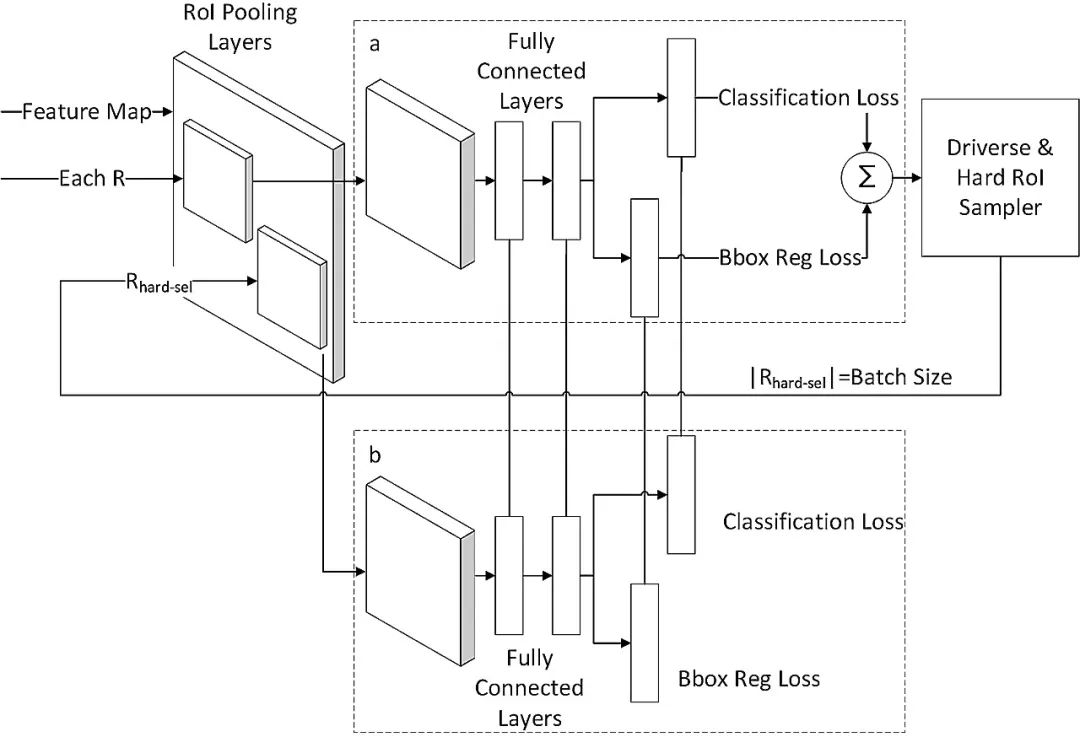
圖2 在線難例挖掘結構
Fig.2 Architecture of online hard example mining
布匹疵點中的小目標疵點往往難以檢測,小目標常常被劃分為難例,在Cascade R-CNN的每個級聯層引入在線難例挖掘采樣之后,提高了整個網絡的短版,防止了網絡針對大量易學樣本過擬合,有利于提升面料疵點的檢測精度。訓練集越大越困難,在線難例挖掘在訓練中所選擇的難例就越多,訓練就更有針對性,效果就越好。而布匹疵點恰好小目標多,寬高比方差大,難例較多,更適合在線難例挖掘的應用,通過讓網絡花更多的精力學習難樣本,進一步提高了檢測的精度。
1.2 可變形卷積v2
可變形卷積v2由可變形卷積[15]演變而來。可變形卷積顧名思義就是卷積的位置是可變形的,并非在傳統的N×N的網格上做卷積,傳統卷積僅僅只能提取到矩形框的特征,可變形卷積則能更準確地提取到復雜區域內的特征。以N×N卷積為例,每個輸出y(p0),都要從中心位置x(p0)上采樣9個位置,(-1,-1)代表x(p0)的左上角,(1,1)代表x(p0)的右下角。傳統的卷積輸出如式(2),R為規格網格,而可變形卷積如式(3),在傳統卷積操作上加入了一個偏移量Δpn,使采樣點擴散成非網格的形狀。
R={(-1,-1),(-1,0)...,(0,1),(1,1)}(1)
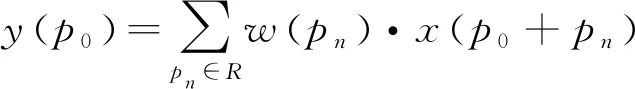 (2)
(2)
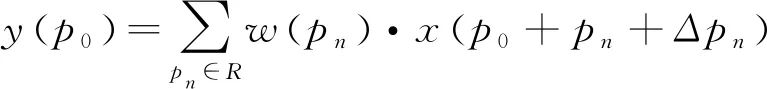 (3)
(3)
而可變形卷積v2如式(4),在可變形卷積的基礎上加上了每個采樣點的權重Δmn,這樣增加了更大的變形自由度,對于某些不想要的采樣點可以將權重設置為0,提高了網絡適應幾何變化的能力。
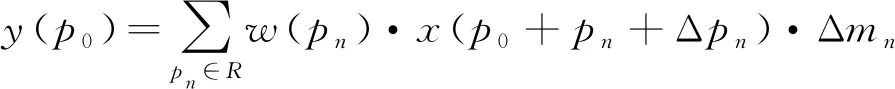 (4)
(4)
ResNet網絡共有5個階段,如圖3所示,第一階段為對圖像的預處理,結構較為簡單,后4個階段結構類似,包含不可串聯的Conv Block和可串聯的Identity Block。本文在ResNet50骨干網絡的最后3個階段采用可變形卷積v2,能夠計算每個點的偏移和權重,從最合適的地方取特征進行卷積,以此來適應不同形狀的瑕疵,緩解了傳統卷積規格格點采樣無法適應目標的幾何形變問題,如圖4所示,改進后的骨干網絡更能適應布匹疵點的極端長寬比,有利于疵點的精確檢測。
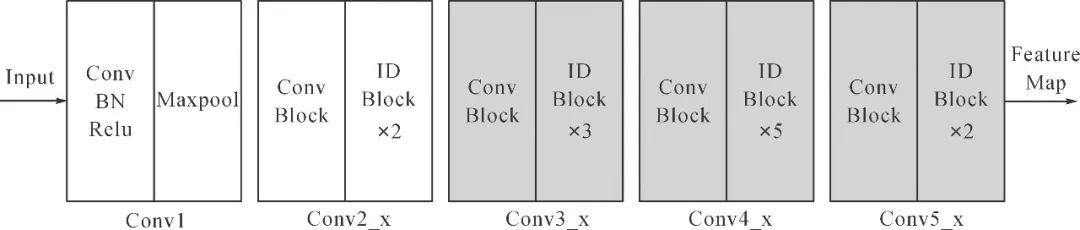
圖3 Resnet骨干網絡結構
Fig.3 Architecture of Resnet backbone network
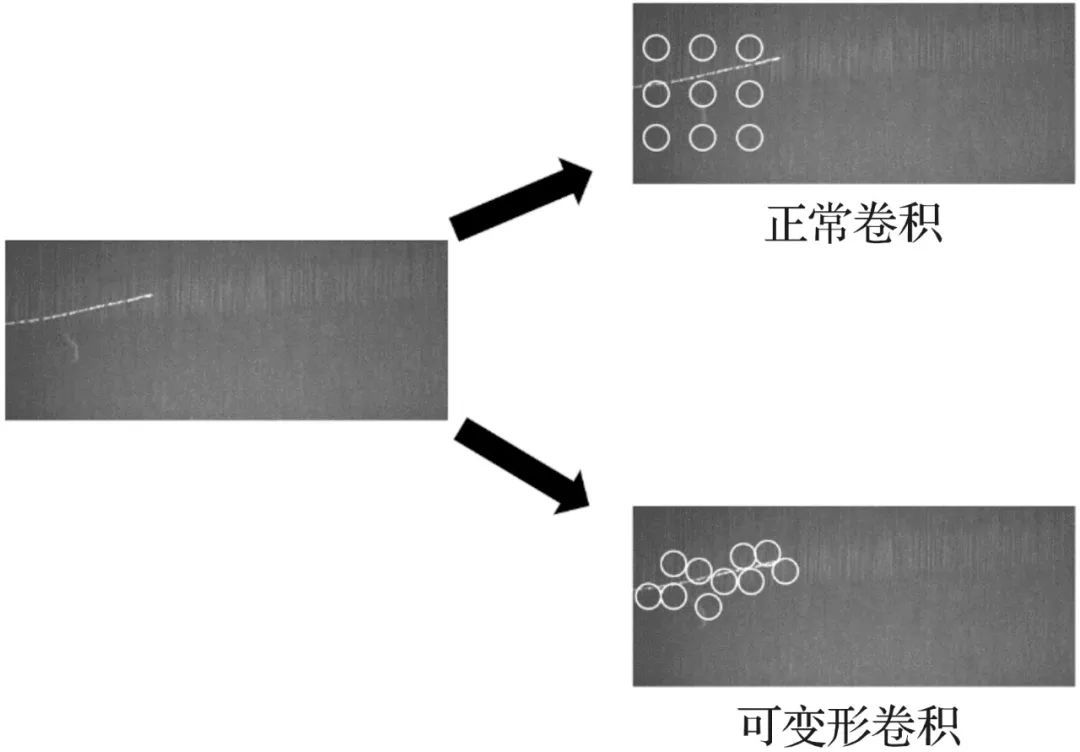
圖4 可變形卷積示意
Fig.4 Diagram of deformable convolution
1.3 完全交并比損失函數
目標檢測中常用的邊界框回歸損失函數有L1 Loss,L2 Loss,Smooth L1 Loss,上述3種損失在計算時,先獨立地求出邊界框4個頂點的損失,然后相加得到最終的邊界框回歸損失,這種計算方法的前提是假設4個點是相互獨立的,但實際它們是相關的。而評價邊界框的指標是IoU,如式(5)所示,即預測邊界框和真實邊界框的交并比。
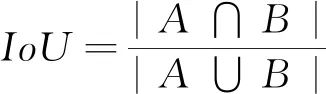 (5)
(5)
但上述3種損失和IoU并不等價,多個邊界框可能損失大小相同,但IoU差異較大,因此就有了IoU Loss[16],如式(6)所示。
IoU Loss=-ln(IoU)(6)
IoU Loss直接把IoU作為損失函數,但它無法解決預測框和真實框不重合時IoU為0的問題,由此產生了GIoU Loss[17],GIoU如式(7),對于兩個邊界框A和B,要找到一個最小的封閉形狀C,讓C將A和B包圍在里面,然后計算C中沒有覆蓋A和B的面積占C總面積的比例,最后用A和B的IoU值減去這個比值。
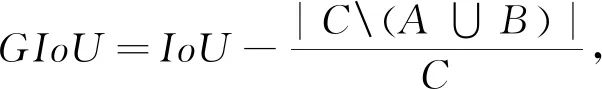 (7)
(7)
但是當目標框完全包含預測框時,GIoU退化為IoU,IoU和GIoU的值相等,無法區分其相對位置關系,由此產生了DIoU和CIoU。DIoU將真實框與預測框之間的距離,重疊率以及尺度都考慮進去,如式(8):
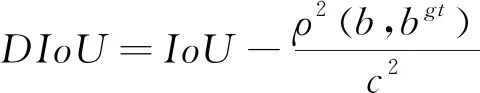 (8)
(8)
式中:b,b??分別代表預測框和真實框的中心點,ρ表示計算兩個中心點之間的歐式距離,c表示包含預測框和真實框的最小外界矩形的對角線長度。 CIoU考慮到邊界框回歸中的長寬比還沒被考慮到計算中,在DIoU懲罰項的基礎上添加了影響因子αv,如式(9):
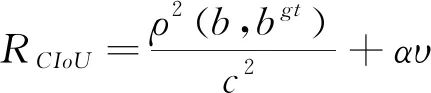 (9)
(9)
式中:α是權重函數, v表示長寬比的相似性,如式(10):
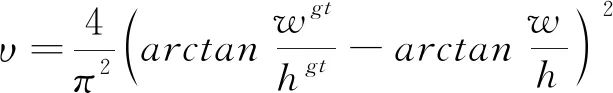 (10)
(10)
式中:w、w??分別代表預測框和真實框的寬度,h、hgt分別代表預測框和真實框的高度。 最終CIoU的損失定義如式(11):
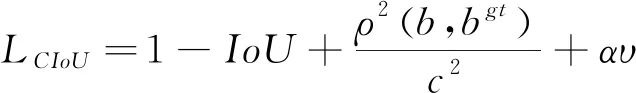 (11)
(11)
本文將原始模型中的邊界框回歸損失選為CIoU Loss,CIoU能夠將重疊面積,中心點距離,長寬比這3個幾何因素都考慮進去,相比其他邊界框損失函數,其收斂的精度更高,從而可以提升布匹疵點檢測時的定位準確度。
實驗結果與對比分析
2.1 實驗數據集
本文使用天池布匹疵點數據集,包含約9 600張大小為2 446×1 000的純色布匹圖像,其中正常圖片約3 600張,瑕疵圖片約6 000張,每張圖片包含一種或多種瑕疵的一個或幾個,共9 523個疵點,包含了紡織業中常見的34類布匹瑕疵,將某些類別合并后,最終分為20個類別。各類疵點的分類及數量見表1,其中6百腳、9松經、10斷經、11吊經、14漿斑等屬于寬高比比較極端的疵點,3三絲、4結頭、7毛粒、12粗緯、13緯縮等屬于小目標的疵點。
表1 布匹瑕疵的分類與數量
Tab.1 Classification and quantity of fabric defects
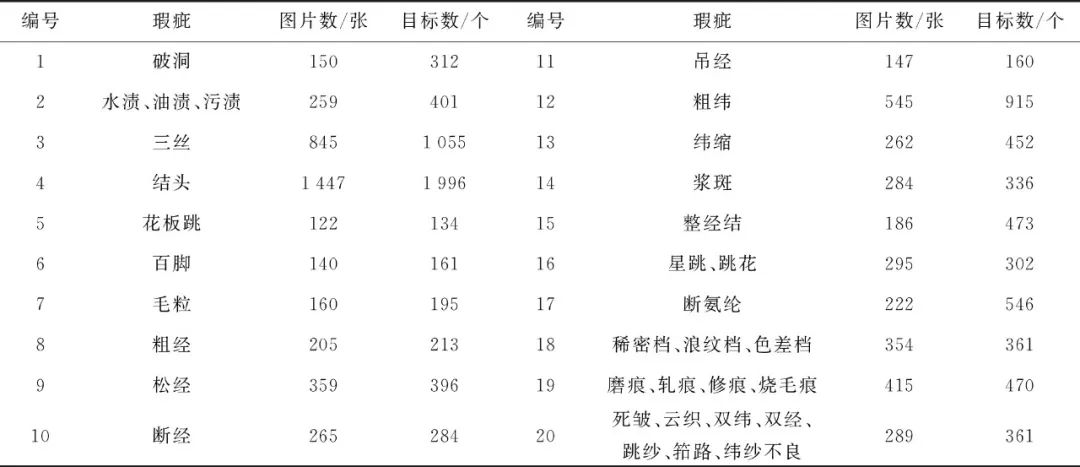
圖5為數據集中不同類型疵點的目標數統計,不同疵點間數目差異巨大,種類分布嚴重不均,例如結頭近2 000個樣本,而花板跳只有134個樣本,這容易產生過擬合,使訓練出的模型泛化能力較差;圖6 展示了不同類型疵點的寬高比,從零點零幾到五十,疵點尺寸差異較大;圖7展示了典型的寬高比懸殊的疵點;圖8為不同面積目標的數量占比,其中小目標占比較高,約四分之一,這些都給布匹疵點的檢測帶來了困難。
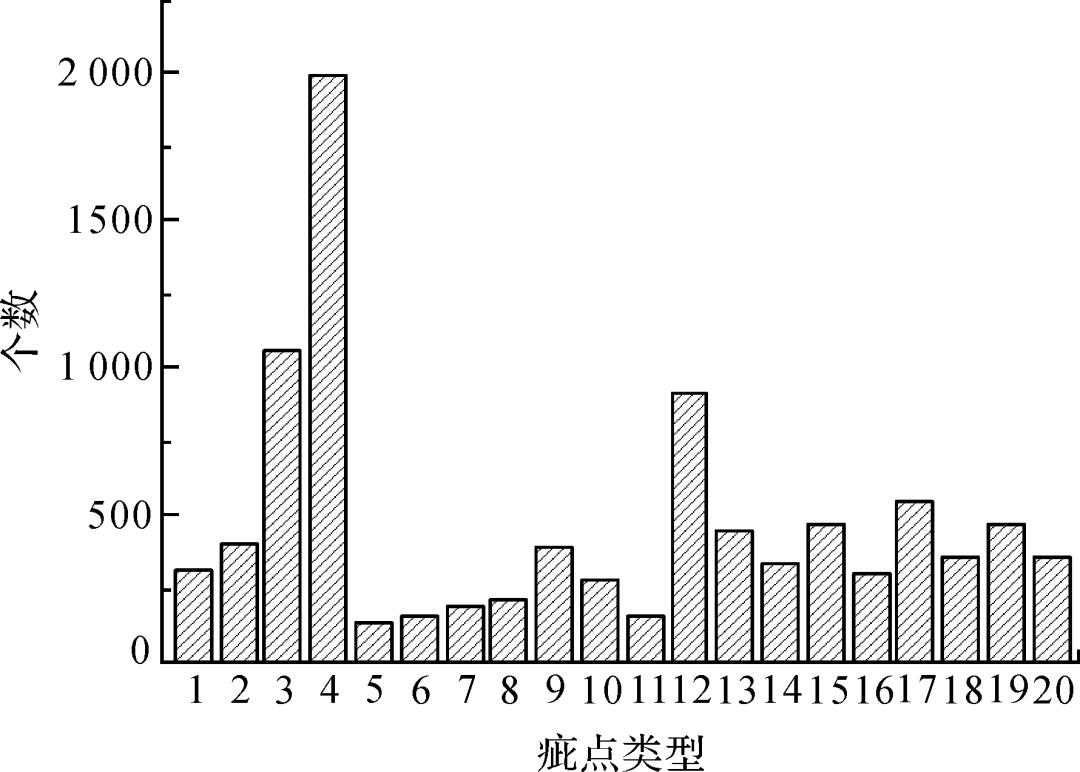
圖5 不同類別目標數統計
Fig.5 Statistics of target number of different categories
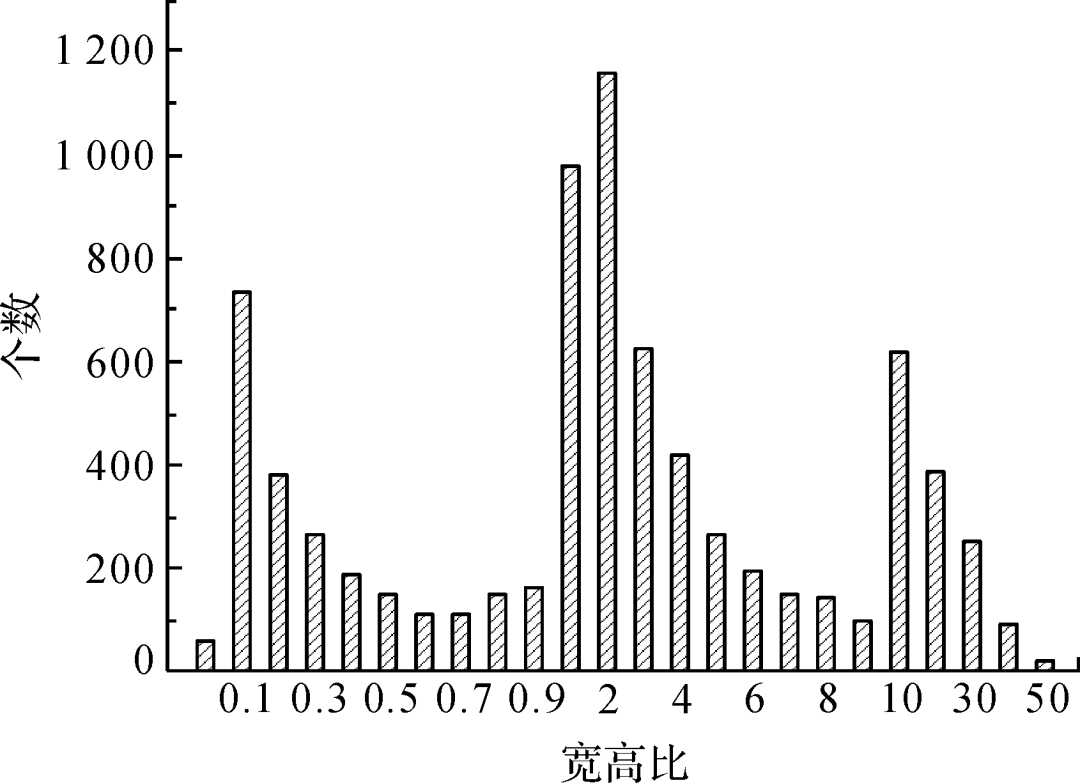
圖6 目標寬高比統計
Fig.6 Statistics of target aspect ratio

圖7 典型疵點
Fig.7 Typical defects
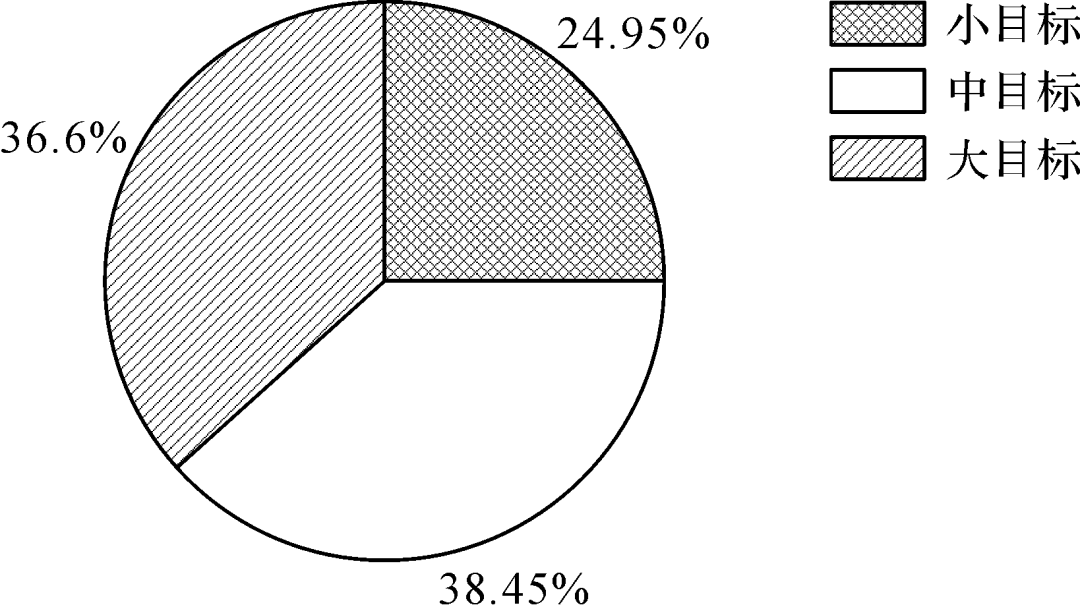
圖8 目標面積統計
Fig.8 Statistics of target area
由于數據尺度固定,也不涉及自然場景,非常適合通過上下反轉等操作來進行數據增強。為減少過擬合,降低疵點種類分布不均的影響,本文對樣本數小于200的四類疵點進行了水平翻轉和垂直翻轉的線下增強,對樣本數在200~300之間的三類疵點進行了水平翻轉的線下增強,最終將數據集擴充到約 10 000 張瑕疵圖片。
2.2 實驗環境及配置
實驗運行的環境為英特爾i9 10900X,GeForce RTX3080,32G內存,Ubuntu18.04操作系統。 為盡可能地利用實驗數據,訓練集中只使用瑕疵圖片,隨機選1000張正常圖片進行兩等分,分別放于驗證集和測試集,并向驗證集和測試集中加入瑕疵圖片,最終訓練集、驗證集和測試集比例約為60%、20%和20%。對于所提出的Cascade R-CNN卷積神經網絡,選擇交叉熵作為分類損失函數。為了加快收斂速度,使用了COCO的預訓練權重,并設置了梯度裁剪來穩定訓練過程,避免產生梯度爆炸或梯度消失。 考慮到樣本的寬高比差異較大,而Cascade R-CNN 網絡原始的邊界框比例是根據COCO數據集設計的,原始的[0.5,1.0,2.0]的比例并不能滿足布匹疵點的需要,因此將邊界框比例設計為[0.02,0.05,0.1,0.5,1.0,2.0,10.0,20.0,50.0]來提高檢測精度。 用Soft-NMS[18]代替了原模型中NMS[19],Soft-NMS沒有將其重合度較高的邊界框直接刪除,而是通過重合度對邊界框的置信度進行衰減,最終得到的結果并非一定是全局最優解,但比NMS更泛化,能有效避免面料疵點丟失,且不會增加算法的復雜度[20]。
2.3 實驗結果對比
在進行數據擴增前,數量多的樣本能夠最先被識別出來,而且最終的平均精確度較高,而數量少的樣本,識別出來的較晚,且最終的平均精確度較低,模型明顯過擬合,偏向于數量較多的樣本,通過對類別少的數據進行數據擴增,有效的緩解了這一問題,且最終的檢測精度也有提升。 模型改進前后的檢測效果對比如圖9所示,改進前后的效果按照上下分布,改進后的模型對目標的邊界識別更加精準,對小目標的檢出能力更強,疵點檢測效果更好。

圖9 模型改進前后的檢測效果對比
Fig.9 The Comparison of detection effect before and after model improvement
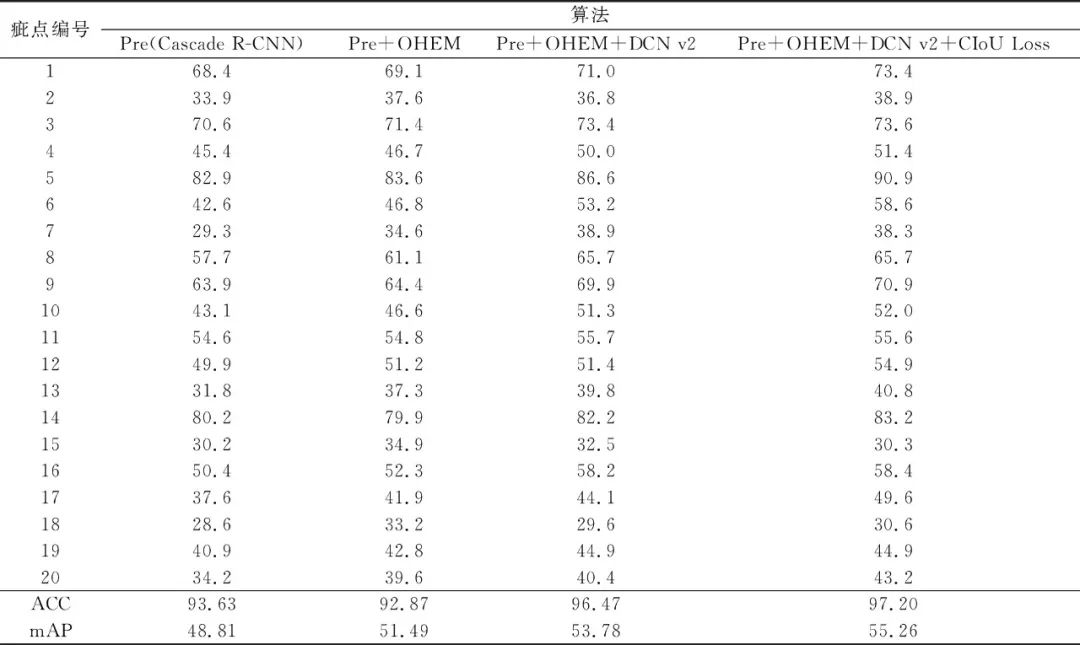
為了對比模型的性能,本文以準確率ACC和平均精確度均值mAP[21]作為評價指標,ACC是有瑕疵或無瑕疵的二分類指標,評估瑕疵檢出能力。mAP是所有類別的平均精確度的均值,參照PASCALVOC的評估標準[22]進行計算。模型改進前后的評價參數如表2所示,在線難例挖掘采樣對2、7、13、15、17、18、20等類別的提升較大,這些類型本身的AP較低,可以歸為難例,證明了在線難例挖掘采樣的有效性。引入OHEM后,雖然模型準確率略微下降,但平均精確度均值還是有較為明顯的提升。綜合來看,改進后的模型在準確率和平均精確度均值上分別提升了3.57%和6.45%,證明了上述3種方法的有效性。
表2 模型改進前后的評價參數
Tab.2 Evaluation parameter before and after model improvement %
影響小目標檢測效果的因素有輸入圖像的尺度、小目標的數量、特征融合、邊界框的設計和光照強度等,為了獲得更好的檢測效果,在訓練出模型后,再在不同的光強下對測試集進行測試,本文使用了mmdetection框架的線上調整亮度的方式,將亮度劃分為0~10之間的小數范圍,對比實驗結果如表3所示,不同光強下的平均精確度均值差異較大,驗證了光強對布匹疵點的識別影響較大,但本文未能找到統一的最佳的光照強度,后通過比較數據集發現,本文數據源于實際工業場景,不同數據已有明顯不同的光強,且布匹顏色并不一致,不同顏色的布匹最合適的光強可能并不一致,因此本文的后續實驗不再調整統一的光照強度,采用原始數據集的亮度。
表3 不同光照強度下測試集的對比
Tab.3 The comparison of the proposed algorithm under different light intensities on test sets
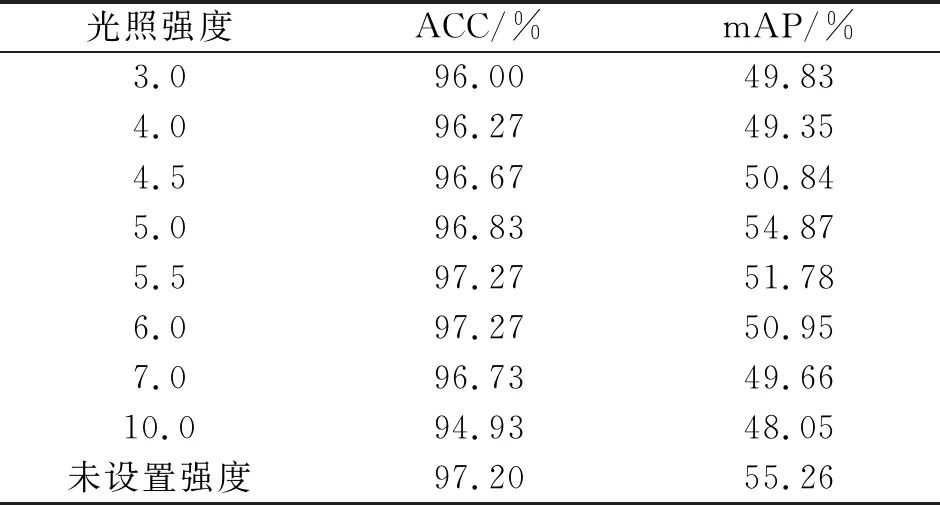
表4為引入在線難例挖掘采樣前后的模型性能對比,在引入在線難例挖掘之后,測試集上的性能明顯提升,而訓練集上的性能反而下降,證明了在線難例挖掘采樣能夠減輕模型的過擬合,同時對于模型的性能提升也是有效的。
表4 引入OHEM前后的對比
Tab.4 The comparison before and after the introduction of OHEM

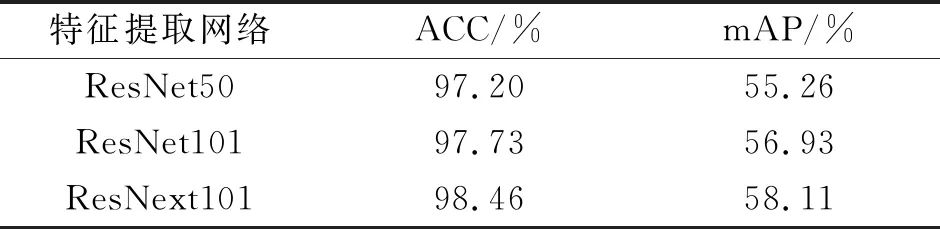
除ResNet50外,本文還選用了不同的特征提取網絡進行對比實驗,如表5所示,改進后的算法分別采用了ResNet50,ResNet101,ResNext101骨干網絡進行對比,結果表明本文算法對這幾種骨干網絡都適用,在相同算法下,ResNext101的性能優于ResNet101和ResNet50,準確率和平均精確度均值分別達到了98.46%和58.11%,相比原來的ResNet50分別提升了1.26%和2.74%,平均精確度均值相比準確率有著更為明顯的提升。
表5 算法在不同特征提取網絡上的對比
Tab.5 The comparison of algorithms on different feature extraction networks
結論
針對布匹疵點具有極端的寬高比,而且小目標較多的問題,提出了基于Cascade R-CNN的布匹檢測算法,根據布匹疵點的形狀特點,用可變形卷積v2替代傳統的卷積方式進行特征提取,并使用在線難例挖掘采樣的方法提升對小目標疵點的檢測效果,用CIoU Loss提升邊界框的精度。結果表明,本文提出的方法比原始模型擁有更高的準確率和平均精確度均值,疵點檢出能力更強,精度更高。此外,由于實驗環境算力的限制,本文未采用更多的擴增數據,也并沒有進行模型融合去提升最終的模型評價指標。實驗過程中發現,邊界框寬高比,NMS閾值,IoU閾值等一些超參數的設置,對模型的性能有極大的影響。例如小目標尺度小,邊界框的交并比更低,在相同閾值下難以得到足夠的正樣本[23],因此,如何更深的理解布匹疵點數據特性,選擇最適合布匹疵點特性的超參數列表,以此來提高目標檢測的性能,將是未來的一個研究方向。
審核編輯:郭婷
-
檢測器
+關注
關注
1文章
892瀏覽量
48631 -
數據集
+關注
關注
4文章
1223瀏覽量
25400
原文標題:基于改進級聯R-CNN的面料疵點檢測方法
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于深度學習的目標檢測算法解析
PowerPC小目標檢測算法怎么實現?
基于YOLOX目標檢測算法的改進

介紹目標檢測工具Faster R-CNN,包括它的構造及實現原理

什么是Mask R-CNN?Mask R-CNN的工作原理
手把手教你操作Faster R-CNN和Mask R-CNN
一種新的帶有不確定性的邊界框回歸損失,可用于學習更準確的目標定位

基于改進Faster R-CNN的目標檢測方法
常見經典目標檢測算法:R-CNN、SPP-Ne
PyTorch教程-14.8。基于區域的 CNN (R-CNN)

無Anchor的目標檢測算法邊框回歸策略






 工商網監
工商網監

評論