 高頻系列:單詞拆分問題
高頻系列:單詞拆分問題
140.單詞拆分II(困難)

之前手把手帶你刷二叉樹(綱領篇)把遞歸窮舉劃分為「遍歷」和「分解問題」兩種思路,其中「遍歷」的思路擴展延伸一下就是回溯算法,「分解問題」的思路可以擴展成動態規劃算法。
我在手把手帶你刷二叉樹(思路篇)對一些二叉樹問題進行舉例,同時給出「遍歷」和「分解問題」兩種思路的解法,幫大家借助二叉樹理解更高級的算法設計思想。
當然,這種思維轉換不止局限于二叉樹相關的算法,本文就跳出二叉樹類型問題,來看看實際算法題中如何把問題抽象成樹形結構,從而進行「遍歷」和「分解問題」的思維轉換,從回溯算法順滑地切換到動態規劃算法。
先說句題外話,前文動態規劃核心框架詳解說,標準的動態規劃問題一定是求最值的,因為動態規劃類型問題有一個性質叫做「最優子結構」,即從子問題的最優解推導出原問題的最優解。
但在我們平常的語境中,就算不是求最值的題目,只要看見使用備忘錄消除重疊子問題,我們一般都稱它為動態規劃算法。嚴格來講這是不符合動態規劃問題的定義的,說這種解法叫做「帶備忘錄的 DFS 算法」可能更準確些。不過咱也不用太糾結這種名詞層面的細節,既然大家叫的順口,就叫它動態規劃也無妨。
本文講解的兩道題目也不是求最值的,但依然會把他們的解法稱為動態規劃解法,這里提前跟大家說下這里面的細節,免得細心的讀者疑惑。其他不多說了,直接看題目吧。
單詞拆分 I
首先看下力扣第 139 題「單詞拆分」:

函數簽名如下:
booleanwordBreak(Strings,ListwordDict) ;
這是一道非常高頻的面試題,我們來思考下如何通過「遍歷」和「分解問題」的思路來解決它。
先說說「遍歷」的思路,也就是用回溯算法解決本題。回溯算法最經典的應用就是排列組合相關的問題了,不難發現這道題換個說法也可以變成一個排列問題:
現在給你一個不包含重復單詞的單詞列表wordDict和一個字符串s,請你判斷是否可以從wordDict中選出若干單詞的排列(可以重復挑選)構成字符串s。
這就是前文回溯算法秒殺排列組合問題的九種變體中講到的最后一種變體:元素無重可復選的排列問題,前文我寫了一個permuteRepeat函數,代碼如下:
List>res=newLinkedList<>();
LinkedListtrack=newLinkedList<>();
//元素無重可復選的全排列
publicList>permuteRepeat(int[]nums){
backtrack(nums);
returnres;
}
//回溯算法核心函數
voidbacktrack(int[]nums){
//basecase,到達葉子節點
if(track.size()==nums.length){
//收集根到葉子節點路徑上的值
res.add(newLinkedList(track));
return;
}
//回溯算法標準框架
for(inti=0;i//做選擇
track.add(nums[i]);
//進入下一層回溯樹
backtrack(nums);
//取消選擇
track.removeLast();
}
}
給這個函數輸入nums = [1,2,3],輸出是 3^3 = 27 種可能的組合:
[
[1,1,1],[1,1,2],[1,1,3],[1,2,1],[1,2,2],[1,2,3],[1,3,1],[1,3,2],[1,3,3],
[2,1,1],[2,1,2],[2,1,3],[2,2,1],[2,2,2],[2,2,3],[2,3,1],[2,3,2],[2,3,3],
[3,1,1],[3,1,2],[3,1,3],[3,2,1],[3,2,2],[3,2,3],[3,3,1],[3,3,2],[3,3,3]
]
這段代碼實際上就是遍歷一棵高度為N + 1的滿N叉樹(N為nums的長度),其中根到葉子的每條路徑上的元素就是一個排列結果:
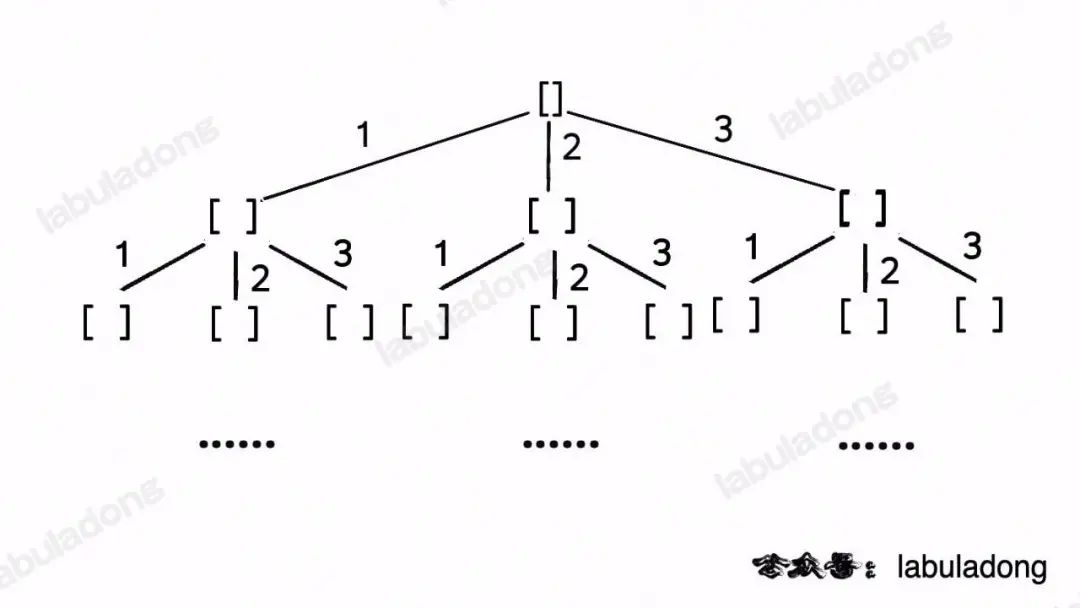
類比一下,本文講的這道題也有異曲同工之妙,假設wordDict = ["a", "aa", "ab"], s = "aaab",想用wordDict中的單詞拼出s,其實也面對著類似的一棵M叉樹,M為wordDict中單詞的個數,你需要做的就是站在回溯樹的每個節點上,看看哪個單詞能夠匹配s[i..]的前綴,從而判斷應該往哪條樹枝上走:
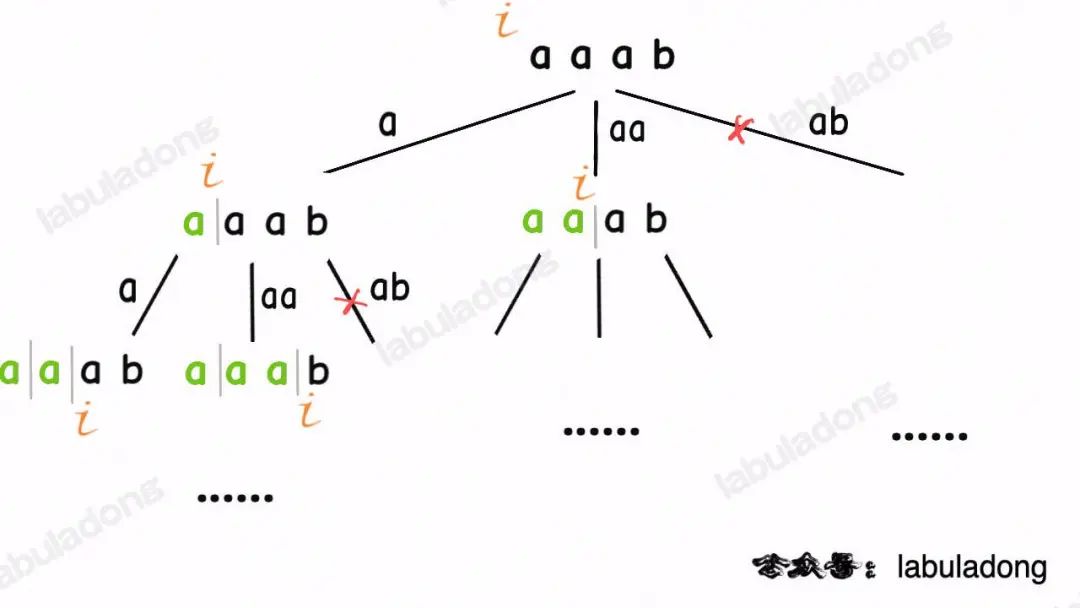
然后,按照前文回溯算法框架詳解所說,你把backtrack函數理解成在回溯樹上游走的一個指針,維護每個節點上的變量i,即可遍歷整棵回溯樹,尋找出匹配s的組合。
回溯算法解法代碼如下:
ListwordDict;
//記錄是否找到一個合法的答案
booleanfound=false;
//記錄回溯算法的路徑
LinkedListtrack=newLinkedList<>();
//主函數
publicbooleanwordBreak(Strings,ListwordDict) {
this.wordDict=wordDict;
//執行回溯算法窮舉所有可能的組合
backtrack(s,0);
returnfound;
}
//回溯算法框架
voidbacktrack(Strings,inti){
//basecase
if(found){
//如果已經找到答案,就不要再遞歸搜索了
return;
}
if(i==s.length()){
//整個s都被匹配完成,找到一個合法答案
found=true;
return;
}
//回溯算法框架
for(Stringword:wordDict){
//看看哪個單詞能夠匹配s[i..]的前綴
intlen=word.length();
if(i+len<=?s.length()
????????????&&?s.substring(i,?i?+?len).equals(word))?{
????????????//找到一個單詞匹配s[i..i+len)
//做選擇
track.addLast(word);
//進入回溯樹的下一層,繼續匹配s[i+len..]
backtrack(s,i+len);
//撤銷選擇
track.removeLast();
}
}
}
這段代碼就是嚴格按照回溯算法框架寫出來的,應該不難理解,但這段代碼無法通過所有測試用例,我們按照之前算法時空復雜度使用指南中講到的方法來分析一下它的時間復雜度。
遞歸函數的時間復雜度的粗略估算方法就是用遞歸函數調用次數(遞歸樹的節點數) x 遞歸函數本身的復雜度。對于這道題來說,遞歸樹的每個節點其實就是對s進行的一次切割,那么最壞情況下s能有多少種切割呢?
長度為N的字符串s中共有N - 1個「縫隙」可供切割,每個縫隙可以選擇「切」或者「不切」,所以s最多有O(2^N)種切割方式,即遞歸樹上最多有O(2^N)個節點。
當然,實際情況可定會好一些,畢竟存在剪枝邏輯,但從最壞復雜度的角度來看,遞歸樹的節點個數確實是指數級別的。
那么backtrack函數本身的時間復雜度是多少呢?主要的時間消耗是遍歷wordDict尋找匹配s[i..]的前綴的單詞:
//遍歷wordDict的所有單詞
for(Stringword:wordDict){
//看看哪個單詞能夠匹配s[i..]的前綴
intlen=word.length();
if(i+len<=?s.length()
????????&&?s.substring(i,?i?+?len).equals(word))?{
????????//找到一個單詞匹配s[i..i+len)
//...
}
}
設wordDict的長度為M,字符串s的長度為N,那么這段代碼的最壞時間復雜度是O(MN)(for 循環O(M),Java 的substring方法O(N)),所以總的時間復雜度是O(2^N * MN)。
這里順便說一個細節優化,其實你也可以反過來,通過窮舉s[i..]的前綴去判斷wordDict中是否有對應的單詞:
//注意,要轉化成哈希集合,提高contains方法的效率
HashSetwordDict=newHashSet<>(wordDict);
//遍歷s[i..]的所有前綴
for(intlen=1;i+len<=?s.length();?len++)?{
????//看看wordDict中是否有單詞能匹配s[i..]的前綴
Stringprefix=s.substring(i,i+len);
if(wordDict.contains(prefix)){
//找到一個單詞匹配s[i..i+len)
//...
}
}
這段代碼和剛才那段代碼的結果是一樣的,但這段代碼的時間復雜度變成了O(N^2),和剛才的代碼不同。
到底哪樣子好呢?這要看題目給的數據范圍。本題說了1 <= s.length <= 300, 1 <= wordDict.length <= 1000,所以O(N^2)的結果較小,這段代碼的實際運行效率應該稍微高一些,這個是一個細節的優化,你可以自己做一下,我就不寫了。
不過即便你優化這段代碼,總的時間復雜度依然是指數級的O(2^N * N^2),是無法通過所有測試用例的,那么問題出在哪里呢?
比如輸入wordDict = ["a", "aa"], s = "aaab",算法無法找到一個可行的組合,所以一定會遍歷整棵回溯樹,但你注意這里面會存在重復的情況:
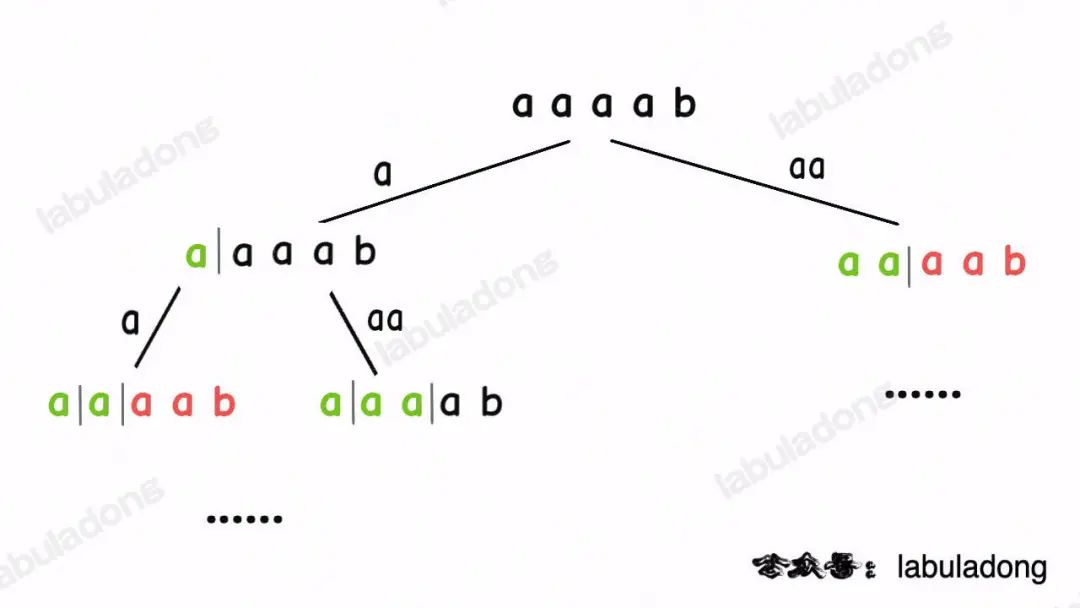
圖中標紅的這兩部分,雖然經歷了不同的切分,但是切分得出的結果是相同的,所以這兩個節點下面的子樹也是重復的,即存在冗余計算,極端情況下會消耗大量時間。
如何消除冗余計算呢?這就要稍微轉變一下思維模式,用「分解問題」的思維模式來考慮這道題。
我們剛才以排列組合的視角思考這個問題,現在我們換一種視角,思考一下是否能夠把原問題分解成規模更小,結構相同的子問題,然后通過子問題的結果計算原問題的結果。
對于輸入的字符串s,如果我能夠從單詞列表wordDict中找到一個單詞匹配s的前綴s[0..k],那么只要我能拼出s[k+1..],就一定能拼出整個s。
換句話說,我把規模較大的原問題wordBreak(s[0..])分解成了規模較小的子問題wordBreak(s[k+1..]),然后通過子問題的解反推出原問題的解。
有了這個思路就可以定義一個dp函數,并給出該函數的定義:
//定義:返回 s[i..]是否能夠被拼出
intdp(Strings,inti);
//計算整個s是否能被拼出,調用dp(s,0)
有了這個函數定義,就可以把剛才的邏輯大致翻譯成偽碼:
ListwordDict;
//定義:返回 s[i..]是否能夠被拼出
intdp(Strings,inti){
//basecase,s[i..]是空串
if(i==s.length()){
returntrue;
}
//遍歷wordDict,
//看看哪些單詞是s[i..]的前綴
for(Strnigword:wordDict){
ifword是s[i..]的前綴{
intlen=word.length();
//只要s[i+len..]可以被拼出,
//s[i..]就能被拼出
if(dp(s,i+len)==true){
returntrue;
}
}
}
//所有單詞都嘗試過,無法拼出整個s
returnfalse;
}
類似之前講的回溯算法,dp函數中的 for 循環也可以優化一下:
//注意,用哈希集合快速判斷元素是否存在
HashSetwordDict;
//定義:返回 s[i..]是否能夠被拼出
intdp(Strings,inti){
//basecase,s[i..]是空串
if(i==s.length()){
returntrue;
}
//遍歷s[i..]的所有前綴,
//看看哪些前綴存在wordDict中
for(intlen=1;i+len<=?s.length();?len++)?{
ifwordDict中存在s[i..len){
//只要s[i+len..]可以被拼出,
//s[i..]就能被拼出
if(dp(s,i+len)==true){
returntrue;
}
}
}
//所有單詞都嘗試過,無法拼出整個s
returnfalse;
}
對于這個dp函數,指針i的位置就是「狀態」,所以我們可以通過添加備忘錄的方式優化效率,避免對相同的子問題進行冗余計算。最終的解法代碼如下:
//用哈希集合方便快速判斷是否存在
HashSetwordDict;
//備忘錄,-1代表未計算,0代表無法湊出,1代表可以湊出
int[]memo;
//主函數
publicbooleanwordBreak(Strings,ListwordDict) {
//轉化為哈希集合,快速判斷元素是否存在
this.wordDict=newHashSet<>(wordDict);
//備忘錄初始化為-1
this.memo=newint[s.length()];
Arrays.fill(memo,-1);
returndp(s,0);
}
//定義:s[i..]是否能夠被拼出
booleandp(Strings,inti){
//basecase
if(i==s.length()){
returntrue;
}
//防止冗余計算
if(memo[i]!=-1){
returnmemo[i]==0?false:true;
}
//遍歷s[i..]的所有前綴
for(intlen=1;i+len<=?s.length();?len++)?{
????????//看看哪些前綴存在wordDict中
Stringprefix=s.substring(i,i+len);
if(wordDict.contains(prefix)){
//找到一個單詞匹配s[i..i+len)
//只要s[i+len..]可以被拼出,s[i..]就能被拼出
booleansubProblem=dp(s,i+len);
if(subProblem==true){
memo[i]=1;
returntrue;
}
}
}
//s[i..]無法被拼出
memo[i]=0;
returnfalse;
}
這個解法能夠通過所有測試用例,我們根據算法時空復雜度使用指南來算一下它的時間復雜度:
因為有備忘錄的輔助,消除了遞歸樹上的重復節點,使得遞歸函數的調用次數從指數級別降低為狀態的個數O(N),函數本身的復雜度還是O(N^2),所以總的時間復雜度是O(N^3),相較回溯算法的效率有大幅提升。
單詞拆分 II
有了上一道題的鋪墊,力扣第 140 題「單詞拆分 II」就容易多了,先看下題目:
相較上一題,這道題不是單單問你s是否能被拼出,還要問你是怎么拼的,其實只要把之前的解法稍微改一改就可以解決這道題。
上一道題的回溯算法維護一個found變量,只要找到一種拼接方案就提前結束遍歷回溯樹,那么在這道題中我們不要提前結束遍歷,并把所有可行的拼接方案收集起來就能得到答案:
//記錄結果
Listres=newLinkedList<>();
//記錄回溯算法的路徑
LinkedListtrack=newLinkedList<>();
ListwordDict;
//主函數
publicListwordBreak(Strings,ListwordDict) {
this.wordDict=wordDict;
//執行回溯算法窮舉所有可能的組合
backtrack(s,0);
returnres;
}
//回溯算法框架
voidbacktrack(Strings,inti){
//basecase
if(i==s.length()){
//找到一個合法組合拼出整個s,轉化成字符串
res.add(String.join("",track));
return;
}
//回溯算法框架
for(Stringword:wordDict){
//看看哪個單詞能夠匹配s[i..]的前綴
intlen=word.length();
if(i+len<=?s.length()
????????????&&?s.substring(i,?i?+?len).equals(word))?{
????????????//找到一個單詞匹配s[i..i+len)
//做選擇
track.addLast(word);
//進入回溯樹的下一層,繼續匹配s[i+len..]
backtrack(s,i+len);
//撤銷選擇
track.removeLast();
}
}
}
這個解法的時間復雜度和前一道題類似,依然是O(2^N * MN),但由于這道題給的數據規模較小,所以可以通過所有測試用例。
類似的,這個問題也可以用分解問題的思維解決,把上一道題的dp函數稍作修改即可:
HashSetwordDict;
//備忘錄
List[]memo;
publicListwordBreak(Strings,ListwordDict) {
this.wordDict=newHashSet<>(wordDict);
memo=newList[s.length()];
returndp(s,0);
}
//定義:返回用 wordDict 構成 s[i..]的所有可能
Listdp(Strings,inti) {
Listres=newLinkedList<>();
if(i==s.length()){
res.add("");
returnres;
}
//防止冗余計算
if(memo[i]!=null){
returnmemo[i];
}
//遍歷s[i..]的所有前綴
for(intlen=1;i+len<=?s.length();?len++)?{
????????//看看哪些前綴存在wordDict中
Stringprefix=s.substring(i,i+len);
if(wordDict.contains(prefix)){
//找到一個單詞匹配s[i..i+len)
ListsubProblem=dp(s,i+len);
//構成s[i+len..]的所有組合加上prefix
//就是構成構成s[i]的所有組合
for(Stringsub:subProblem){
if(sub.isEmpty()){
//防止多余的空格
res.add(prefix);
}else{
res.add(prefix+""+sub);
}
}
}
}
//存入備忘錄
memo[i]=res;
returnres;
}
這個解法依然用備忘錄消除了重疊子問題,所以dp函數遞歸調用的次數減少為O(N),但dp函數本身的時間復雜度上升了,因為subProblem是一個子集列表,它的長度是指數級的。
再加上 Java 中用+拼接字符串的效率并不高,且還要消耗備忘錄去存儲所有子問題的結果,所以這個算法的時間復雜度并不比回溯算法低,依然是指數級別。
綜上,我們處理排列組合問題時一般使用回溯算法去「遍歷」回溯樹,而不用「分解問題」的思路去處理,因為存儲子問題的結果就需要大量的時間和空間,除非重疊子問題的數量較多的極端情況,否則得不償失。
以上就是本文的全部內容,希望你能對回溯思路和分解問題的思路有更深刻的理解。
審核編輯 :李倩
-
代碼
+關注
關注
30文章
4791瀏覽量
68680 -
二叉樹
+關注
關注
0文章
74瀏覽量
12338 -
回溯算法
+關注
關注
0文章
10瀏覽量
6619
原文標題:高頻面試系列:單詞拆分問題
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大陸集團計劃拆分汽車業務并獨立上市
霍尼韋爾考慮拆分航空航天業務
解決高頻高溫環境下電感損耗大 溫升高難題 科達嘉推出大電流電感CPEA系列
基于OpenCV的拆分和合并圖像通道實驗案例分享_基于RK3568教學實驗箱
AS1000系列變頻電源SPWM高頻脈寬調制?應用

如何選擇高頻pcb板材型號
博通上調收入預期并宣布股票拆分
國巨 | 高頻MLCC CQ系列推出01005 因應高頻極小化需求
power Integrations推出InnoSwitch4-QR系列高頻準諧振反激式開關IC






 工商網監
工商網監
評論