") 深入了解神經(jīng)網(wǎng)絡(luò)
深入了解神經(jīng)網(wǎng)絡(luò)
本章將介紹用于解決實際問題的深度學(xué)習(xí)架構(gòu)的不同模塊。前一章使用PyTorch的低級操作構(gòu)建了如網(wǎng)絡(luò)架構(gòu)、損失函數(shù)和優(yōu)化器這些模塊。本章將介紹用于解決真實問題的神經(jīng)網(wǎng)絡(luò)的一些重要組件,以及PyTorch如何通過提供大量高級函數(shù)來抽象出復(fù)雜度。本章還將介紹用于解決真實問題的算法,如回歸、二分類、多類別分類等。
本章將討論如下主題:
?詳解神經(jīng)網(wǎng)絡(luò)的不同構(gòu)成組件;
?探究PyTorch中用于構(gòu)建深度學(xué)習(xí)架構(gòu)的高級功能;
?應(yīng)用深度學(xué)習(xí)解決實際的圖像分類問題。
3.1詳解神經(jīng)網(wǎng)絡(luò)的組成部分
上一章已經(jīng)介紹了訓(xùn)練深度學(xué)習(xí)算法需要的幾個步驟。
1.構(gòu)建數(shù)據(jù)管道。
2.構(gòu)建網(wǎng)絡(luò)架構(gòu)。
3.使用損失函數(shù)評估架構(gòu)。
4.使用優(yōu)化算法優(yōu)化網(wǎng)絡(luò)架構(gòu)的權(quán)重。
上一章中的網(wǎng)絡(luò)由使用PyTorch數(shù)值運算構(gòu)建的簡單線性模型組成。盡管使用數(shù)值運算為玩具性質(zhì)的問題搭建神經(jīng)架構(gòu)很簡單,但當需要構(gòu)建解決不同領(lǐng)域的復(fù)雜問題時,如計算機視覺和自然語言處理,構(gòu)建一個架構(gòu)就迅速變得復(fù)雜起來。大多數(shù)深度學(xué)習(xí)框架,如PyTorch、TensorFlow和Apache MXNet,都提供了抽象出很多復(fù)雜度的高級功能。這些深度學(xué)習(xí)框架的高級功能稱為層(layer)。它們接收輸入數(shù)據(jù),進行如同在前面一章看到的各種變換,并輸出數(shù)據(jù)。解決真實問題的深度學(xué)習(xí)架構(gòu)通常由1~150個層組成,有時甚至更多。抽象出低層的運算并訓(xùn)練深度學(xué)習(xí)算法的過程如圖3.1所示。
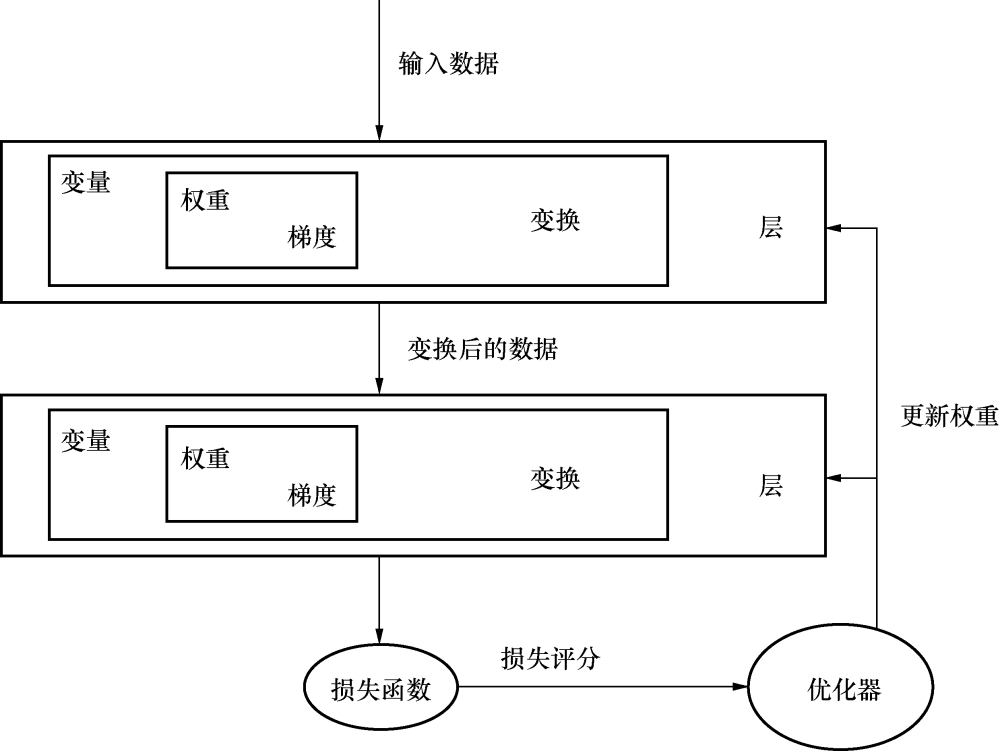
圖3.1
3.1.1層——神經(jīng)網(wǎng)絡(luò)的基本組成
在本章的剩余部分,我們會見到各種不同類型的層。首先,先了解其中最重要的一種層:線性層,它就是我們前面講過的網(wǎng)絡(luò)層結(jié)構(gòu)。線性層應(yīng)用了線性變換:
Y=Wx+b
線性層之所以強大,是因為前一章所講的功能都可以寫成單一的代碼行,如下所示。
上述代碼中的myLayer層,接受大小為10的張量作為輸入,并在應(yīng)用線性變換后輸出一個大小為5的張量。下面是一個簡單例子的實現(xiàn):
可以使用屬性weights和bias訪問層的可訓(xùn)練參數(shù):
線性層在不同的框架中使用的名稱有所不同,有的稱為dense層,有的稱為全連接層(fully connected layer)。用于解決真實問題的深度學(xué)習(xí)架構(gòu)通常包含不止一個層。在PyTorch中,可以用多種方式實現(xiàn)。
一個簡單的方法是把一層的輸出傳入給另一層:
每一層都有自己的學(xué)習(xí)參數(shù),在多個層的架構(gòu)中,每層都學(xué)習(xí)出它本層一定的模式,其后的層將基于前一層學(xué)習(xí)出的模式構(gòu)建。把線性層簡單堆疊在一起是有問題的,因為它們不能學(xué)習(xí)到簡單線性表示以外的新東西。我們通過一個簡單的例子看一下,為什么把線性層堆疊在一起的做法并不合理。
假設(shè)有具有如下權(quán)重的兩個線性層:
層 權(quán)重
Layer1 3.0
Layer2 2.0
以上包含兩個不同層的架構(gòu)可以簡單表示為帶有另一不同層的單層。因此,只是堆疊多個線性層并不能幫助我們的算法學(xué)習(xí)任何新東西。有時,這可能不太容易理解,我們可以用下面的數(shù)學(xué)公式對架構(gòu)進行可視化:
Y= 2(3X1) -2Linear layers
Y= 6(X1) -1Linear layers
為解決這一問題,相較于只是專注于線性關(guān)系,我們可以使用不同的非線性函數(shù),幫助學(xué)習(xí)不同的關(guān)系。
深度學(xué)習(xí)中有很多不同的非線性函數(shù)。PyTorch以層的形式提供了這些非線性功能,因為可以采用線性層中相同的方式使用它們。
一些流行的非線性函數(shù)如下所示:
?sigmoid
?tanh
?ReLU
?Leaky ReLU
3.1.2非線性激活函數(shù)
非線性激活函數(shù)是獲取輸入,并對其應(yīng)用數(shù)學(xué)變換從而生成輸出的函數(shù)。我們在實戰(zhàn)中可能遇到數(shù)個非線性操作。下面會講解其中幾個常用的非線性激活函數(shù)。
1.sigmoid
sigmoid激活函數(shù)的數(shù)學(xué)定義很簡單,如下:
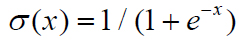
簡單來說,sigmoid函數(shù)以實數(shù)作為輸入,并以一個0到1之間的數(shù)值作為輸出。對于一個極大的負值,它返回的值接近于0,而對于一個極大的正值,它返回的值接近于1。圖3.2所示為sigmoid函數(shù)不同的輸出。
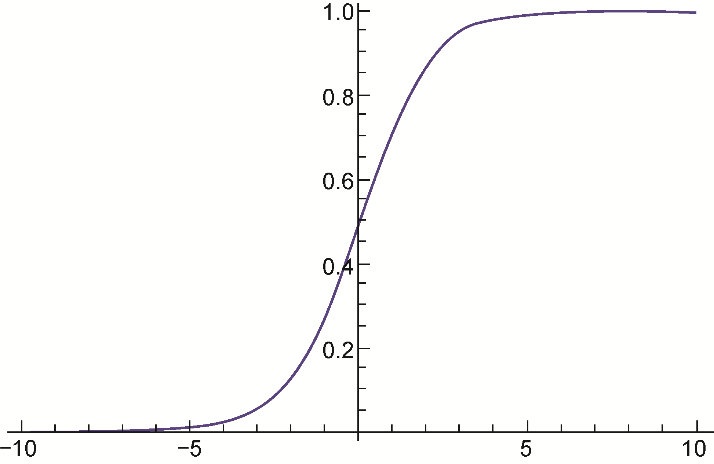
圖3.2
sigmoid函數(shù)曾一度被不同的架構(gòu)使用,但由于存在一個主要弊端,因此最近已經(jīng)不太常用了。當sigmoid函數(shù)的輸出值接近于0或1時,sigmoid函數(shù)前一層的梯度接近于0,由于前一層的學(xué)習(xí)參數(shù)的梯度接近于0,使得權(quán)重不能經(jīng)常調(diào)整,從而產(chǎn)生了無效神經(jīng)元。
2.tanh
非線性函數(shù)tanh將實數(shù)值輸出為-1到1之間的值。當tanh的輸出極值接近-1和1時,也面臨梯度飽和的問題。不過,因為tanh的輸出是以0為中心的,所以比sigmoid更受偏愛,如圖3.3所示。
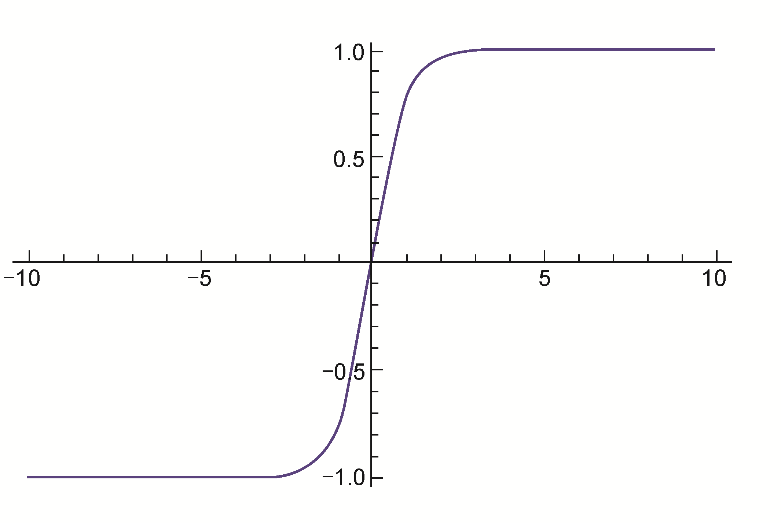
圖3.3
3.ReLU
近年來ReLU變得很受歡迎,我們幾乎可以在任意的現(xiàn)代架構(gòu)中找到ReLU或其某一變體的身影。它的數(shù)學(xué)公式很簡單:
f(x)=max(0,x)
簡單來說,ReLU把所有負值取作0,正值保持不變。可以對ReLU函數(shù)進行可視化,如圖3.4所示。
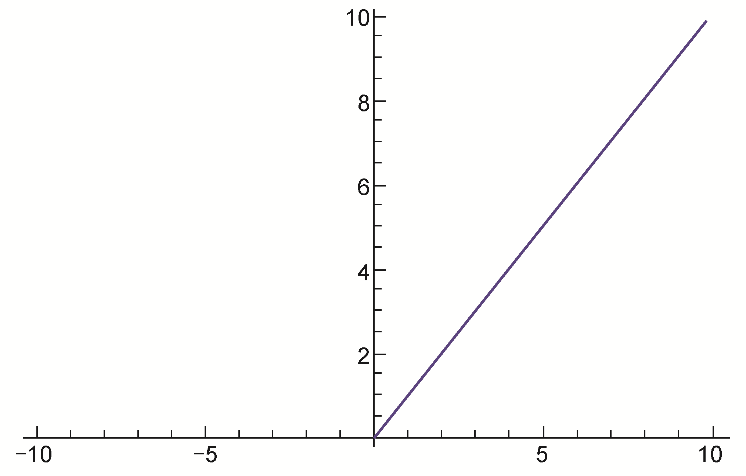
圖3.4
使用ReLU函數(shù)的一些好處和弊端如下。
?有助于優(yōu)化器更快地找到正確的權(quán)重集合。從技術(shù)上講,它使隨機梯度下降收斂得更快。
?計算成本低,因為只是判斷了閾值,并未計算任何類似于sigmoid或tangent函數(shù)計算的內(nèi)容。
?ReLU有一個缺點,即當一個很大的梯度進行反向傳播時,流經(jīng)的神經(jīng)元經(jīng)常會變得無效,這些神經(jīng)元稱為無效神經(jīng)元,可以通過謹慎選擇學(xué)習(xí)率來控制。我們將在第4章中討論調(diào)整學(xué)習(xí)率的不同方式時,了解如何選擇學(xué)習(xí)率。
4.Leaky ReLU
Leaky ReLU嘗試解決一個問題死角,它不再將飽和度置為0,而是設(shè)為一個非常小的數(shù)值,如0.001。對某些用例,這一激活函數(shù)提供了相較于其他激活函數(shù)更優(yōu)異的性能,但它不是連續(xù)的。
審核編輯 黃昊宇
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100720 -
人工智能
+關(guān)注
關(guān)注
1791文章
47208瀏覽量
238294
發(fā)布評論請先 登錄
相關(guān)推薦
神經(jīng)網(wǎng)絡(luò)教程(李亞非)
labview BP神經(jīng)網(wǎng)絡(luò)的實現(xiàn)
卷積神經(jīng)網(wǎng)絡(luò)如何使用
【案例分享】ART神經(jīng)網(wǎng)絡(luò)與SOM神經(jīng)網(wǎng)絡(luò)
人工神經(jīng)網(wǎng)絡(luò)實現(xiàn)方法有哪些?
卷積神經(jīng)網(wǎng)絡(luò)原理及發(fā)展過程
如何構(gòu)建神經(jīng)網(wǎng)絡(luò)?
基于BP神經(jīng)網(wǎng)絡(luò)的PID控制
神經(jīng)網(wǎng)絡(luò)移植到STM32的方法
遷移學(xué)習(xí)
機器學(xué)習(xí)簡介與經(jīng)典機器學(xué)習(xí)算法人才培養(yǎng)
卷積神經(jīng)網(wǎng)絡(luò)CNN架構(gòu)分析-LeNet

帶你了解深入深度學(xué)習(xí)的核心:神經(jīng)網(wǎng)絡(luò)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論