 如何在Prompt Learning下引入外部知識達到好文本分類效果
如何在Prompt Learning下引入外部知識達到好文本分類效果
背景
利用Prompt Learning(提示學習)進行文本分類任務是一種新興的利用預訓練語言模型的方式。在提示學習中,我們需要一個標簽詞映射(verbalizer),將[MASK]位置上對于詞表中詞匯的預測轉化成分類標簽。例如{POLITICS: "politics", SPORTS: "sports"} 這個映射下,預訓練模型在[MASK]位置對于politics/sports這個標簽詞的預測分數會被當成是對POLITICS/SPORTS這個標簽的預測分數。
手工定義或自動搜索得到的verbalizer有主觀性強覆蓋面小等缺點,我們使用了知識庫來進行標簽詞的擴展和改善,取得了更好的文本分類效果。同時也為如何在Prompt Learning下引入外部知識提供了參考。
方法
我們提出使用知識庫擴展標簽詞,通過例如相關詞詞表,情感詞典等工具,基于手工定義的初始標簽詞進行擴展。例如,可以將{POLITICS: "politics", SPORTS: "sports"} 擴展為以下的一些詞:
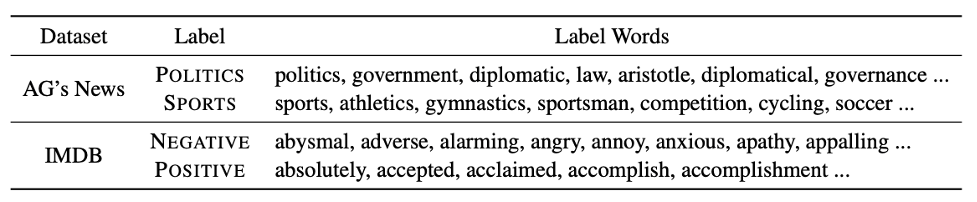
表1: 基于知識庫擴展出的標簽詞。
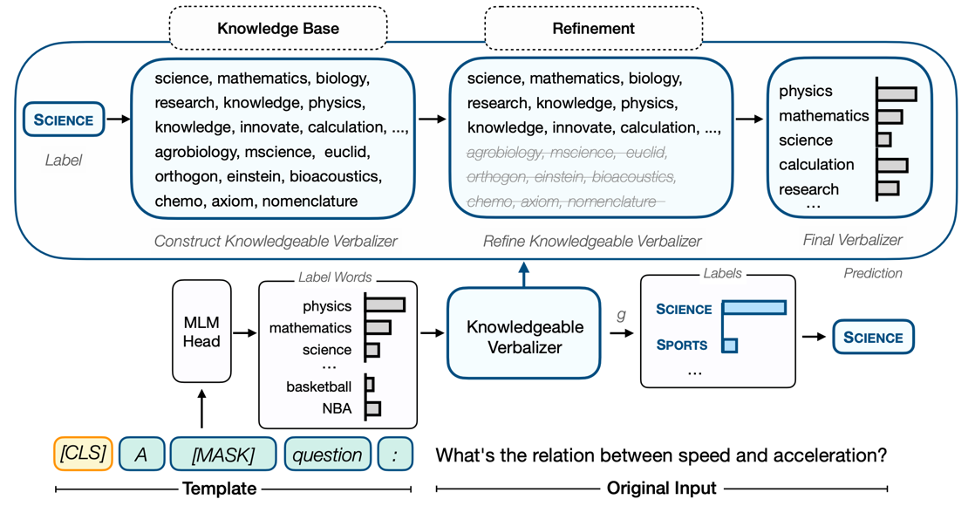
圖1: 以問題分類任務為例的KPT流程圖。
之后我們可以通過一個多對一映射將多個詞上的預測概率映射到某個標簽上。
但是由于知識庫不是為預訓練模型量身定做的,使用知識庫擴展出的標簽詞具有很大噪音。例如SPORTS擴展出的movement可能和POLITICS相關性很大,從而引起混淆;又或者POLITICS擴展出的machiavellian(為奪取權力而不擇手段的)則可能由于詞頻很低不容易被預測到,甚至被拆解成多個token而不具有詞語本身的意思。
因此我們提出了三種精調以及一種校準的方法。
01
頻率精調
我們利用預訓練模型M本身對于標簽詞v的輸出概率當成標簽詞的先驗概率,用來估計標簽詞的先驗出現頻率。我們把頻率較小的標簽詞去掉。
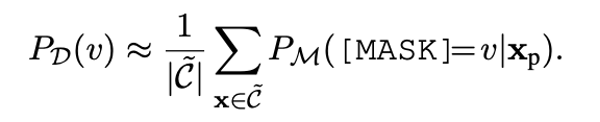
公式1: 頻率精調。C代表語料庫。
02
相關性精調
有的標簽詞和標簽相關性不大,有些標簽詞會同時和不同標簽發生混淆。我們利用TF-IDF的思想來賦予每個標簽詞一個對于特定類別的重要性。
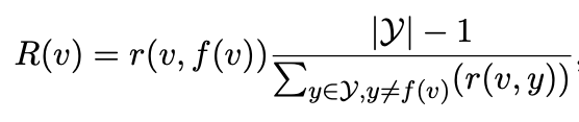
公式2: 相關性精調,r(v,y)是一個標簽詞v和標簽y的相關性,類似于TF項。右邊一項則類似IDF項,我們要求這一項大也就是要求v和其非對應類相關性小。
03
可學習精調
在少樣本實驗中,我們可以為每個標簽詞賦予一個可學習的權重,因此每個標簽詞的重要性就變成:
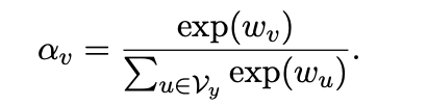
公式3:可學習的標簽詞權重。
04
基于上下文的校準
在零樣本實驗中不同標簽詞的先驗概率可能差得很多,例如預測 basketball可能天然比fencing大,會使得很多小眾標簽詞影響甚微。我們使用校準的方式來平衡這種影響。
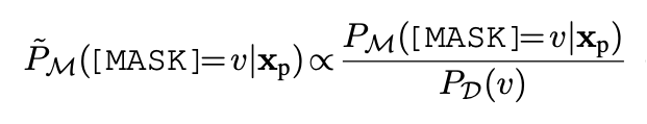
公式4: 基于上下文的校準,分母是公式1中的先驗概率。
使用上以上這些精調方法,我們知識庫擴展的標簽詞就能有效使用了。
實驗
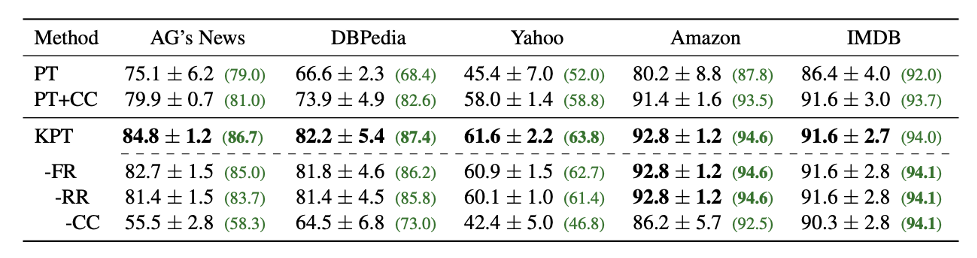
表2:零樣本文本分類任務。
如表2所示,零樣本上相比于普通的Prompt模板,性能有15個點的大幅長進。相比于加上了標簽詞精調的也最多能有8個點的提高。我們提出的頻率精調,相關性精調等也各有用處。
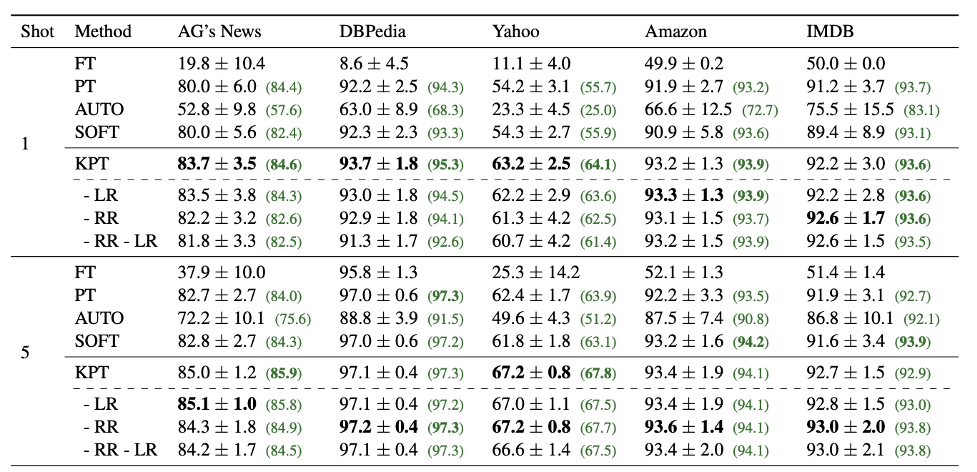
表3:少樣本文本分類任務。
如表3所示,在少樣本上我們提出的可學習精調搭配上相關性精調也有較大提升。AUTO和SOFT都是自動的標簽詞優化方法,其中SOFT以人工定義的標簽詞做初始化,可以看到這兩種方法的效果都不如KPT。
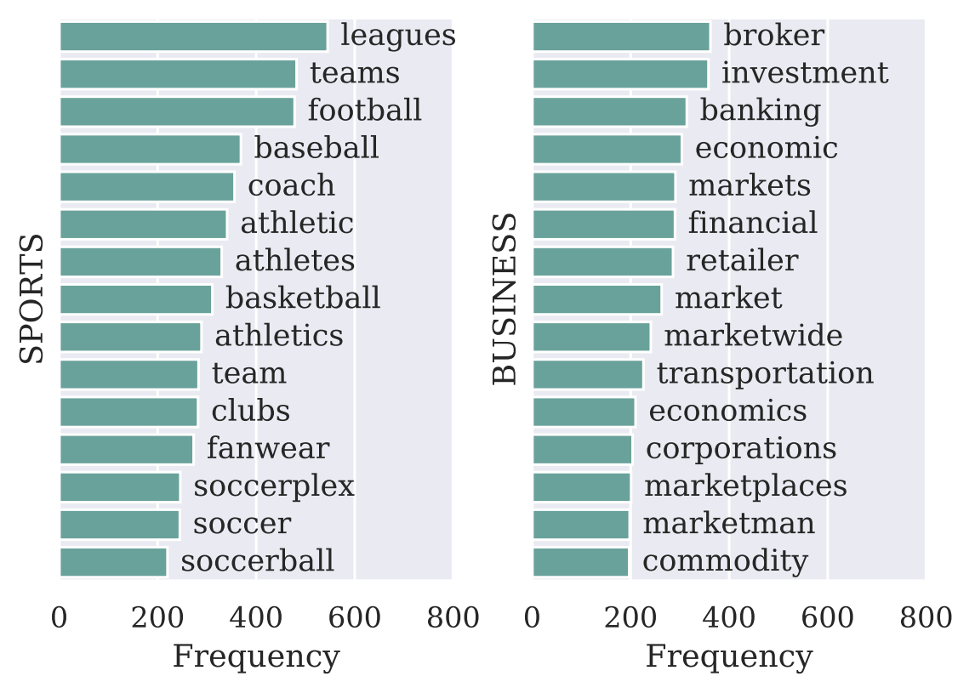
圖2: SPORTS和BUSINESS類的知識庫擴展的標簽詞對于預測的貢獻。
標簽詞的可視化表明,每一條句子可能會依賴不同的標簽詞進行預測,完成了我們增加覆蓋面的預期。
總結
最近比較受關注的Prompt Learning方向,除了template的設計,verbalizer的設計也是彌補MLM和下游分類任務的重要環節。我們提出的基于知識庫的擴展,直觀有效。同時也為如何在預訓練模型的的利用中引入外部知識提供了一些參考。
審核編輯:郭婷
-
頻率
+關注
關注
4文章
1511瀏覽量
59268 -
知識庫
+關注
關注
0文章
10瀏覽量
6726
原文標題:ACL2022 | KPT: 文本分類中融入知識的Prompt Verbalizer
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何使用自然語言處理分析文本數據
如何在文本字段中使用上標、下標及變量

AI對話魔法 Prompt Engineering 探索指南

RK3588 技術分享 | 在Android系統中使用NPU實現Yolov5分類檢測
如何在TMS320C6727 DSP上創建基于延遲的音頻效果

RK3588 技術分享 | 在Android系統中使用NPU實現Yolov5分類檢測
利用TensorFlow實現基于深度神經網絡的文本分類模型
卷積神經網絡在文本分類領域的應用
如何在idf工程中引入mdf WiFi-Mesh函數?
交換機的基本分類
有誰知道如何在熱敏打印機中實現圖片的灰階打印效果嗎?
了解如何使用PyTorch構建圖神經網絡
如何從訓練集中生成候選prompt 三種生成候選prompt的方式





 工商網監
工商網監
評論