 邏輯推理MRC的兩個數據集和對應方法
邏輯推理MRC的兩個數據集和對應方法
1.背景
機器閱讀理解(Machine Reading Comprehension, MRC)作為自然語言處理領域中的一個基本任務,要求模型就給定的一段文本和與文本相關的問題進行作答。正如同我們使用閱讀理解測驗來評估人類對于一段文本的理解程度一樣,閱讀理解同樣可以用來評估一個計算機系統對于人類語言的理解程度。近年來,隨著預訓練語言模型在NLP領域的成功,許多預訓練語言模型在流行的MRC數據集上的表現達到甚至超過了人類,例如:BERT、RoBERTa、XLNet、GPT3等。因此,為了促進更深層次的語言理解,許多更加具有挑戰的MRC數據集被提出,它們從不同的角度考察模型能力,例如:多文檔證據整合能力[1]、離散數值推理能力[2]、常識推理能力[3]等。
邏輯推理(Logical Reasoning)指對于日常語言中的論點進行檢查、分析和批判性評價的能力,其是人類智能的關鍵組成部分,在談判、辯論、寫作等場景中發揮著重要作用。然而,流行的MRC數據集中沒有或僅有很少的數據考察邏輯推理能力,例如,根據Sugawara和Aizawa[4]的研究,MCTest數據集中0%的數據和SQuAD中1.2%的數據需要邏輯推理能力作答。因此,ReClor[5]和LogiQA[6]這兩個側重考察邏輯推理能力的MRC數據集被提出。與邏輯推理MRC任務相關的一個任務是自然語言推理(Natural Language Inference, NLI),其要求模型對給定句對的邏輯關系分類,NLI任務僅僅考慮了句子級別的三種簡單的邏輯關系(蘊含、矛盾、無關),而邏輯推理MRC需要綜合篇章級別的多種復雜邏輯關系預測答案,因此更加具有挑戰性。
本文介紹了目前邏輯推理MRC的兩個數據集和對應方法。
2.數據集簡介
2.1 LogiQA
LogiQA[5]是一個四選一的單項選擇問答數據集,針對輸入的問題、篇章和四個選項,模型需要根據問題和篇章找出唯一正確的選項作為答案。LogiQA的數據來自于中國的國家公務員考試題目,其旨在考察公務員候選人的批判性思維和解決問題的能力。原始數據經過篩選、過濾后得到8678條數據,這些數據被五名專業的英文使用者由中文翻譯到英文,數據集的中文版本Chinese LogiQA也被同時發布。LogiQA的例子如圖1所示,這些數據按照81的比例隨機劃分為訓練集、開發集和測試集。
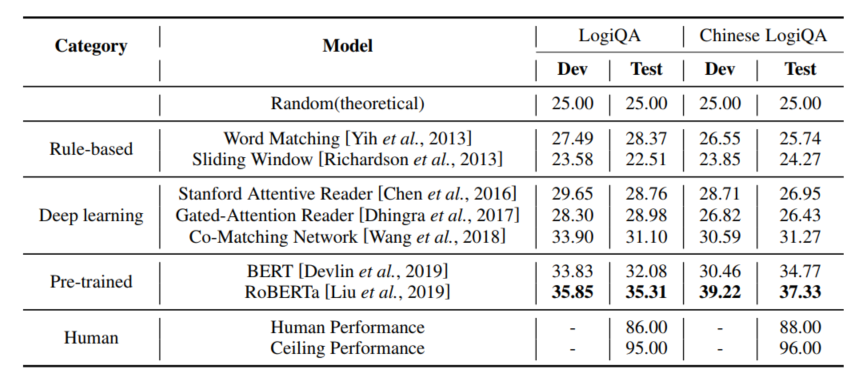
作者評估了基于規則的方法、深度學習方法以及基于預訓練語言模型的方法在LogiQA上的表現,實驗結果如表1所示,可以看到人類(研究生)在LogiQA上可以取得86%的平均準確率,這說明該數據集的難度對于人類受試者來說并不高,而另一方面,被測試的所有方法的表現均顯著低于人類,即便是表現最好的RoBERTa模型也僅能取得35.31%的準確率,這說明目前的預訓練語言模型的邏輯推理能力還相當弱。

圖1 LogiQA中的例子(正確選項使用紅色標出)
表1 各類方法在LogiQA上的實驗結果(accuracy%)
2.2 ReClor
ReClor[6]與LogiQA一樣,是一個四選一的單項選擇問答數據集,其來自于美國的兩個標準化研究生入學考試:研究生管理科入學考試(GMAT)和法學院入學考試(LSAT),經過篩選、過濾得到6138條考察邏輯推理能力的數據,這些數據被隨機劃分為4638,500,1000條來分別用作訓練集、開發集和測試集。ReClor數據集的一個具體例子如圖2所示,可以看到只有基于篇章、問題和選項進行邏輯推理和分析才能得到正確的答案。
正如上面介紹的那樣,ReClor來自側重考察邏輯推理的考試,由人類的專家構建,這意味著biases有可能被引入,這導致模型可能無需真正理解文本,僅僅利用這些biases就可以在任務上取得很好的表現。而將這些biased數據與unbiased數據區分開可以更加全面的評價模型在ReClor上的表現。為此,作者去除掉問題和篇章,僅僅將選項作為預訓練語言模型的輸入,如果模型僅僅依賴選項就可以成功預測出正確選項,那么這樣的biased數據就被歸為EASY-SET,其余數據被歸為HARD-SET,這樣,ReClor的測試集被分為了EASY-SET和HARD-SET兩部分。
作者在ReClor的EASY-SET和HARD-SET上分別評估了預訓練語言模型和人類的表現,實驗結果如圖3所示,實驗結果顯示:預訓練語言模型在EASY-SET上可以取得很好的表現,但是在HARD-SET上表現很差,而人類則在兩個集合上取得了相當的表現,這說明目前的模型雖然擅長利用數據集中存在的biases,但是還遠遠做不到真正的邏輯推理。

圖2 ReClor中的一個例子(修改自2019年的LSAT)
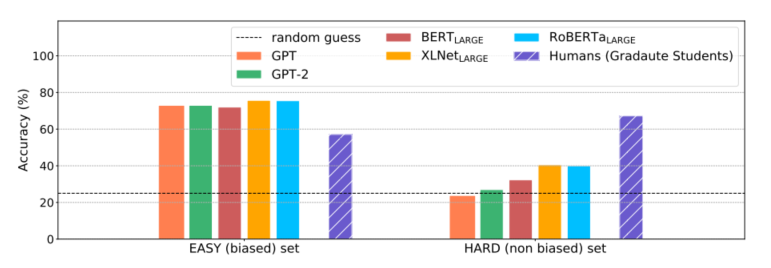
圖3 預訓練語言模型與人類(研究生)在ReClor測試集的EASY-SET和HARD-SET上的表現對比
3.方法
下面將介紹幾篇近兩年邏輯推理MRC的相關工作,目前的已有方法可以大致分為兩類:一類方法是利用預定義的規則基于篇章、選項構建圖結構,圖中節點對應文本中的邏輯單元(這里的邏輯單元指有意義的句子、從句或文本片段),而圖中的邊則表示邏輯單元間的關系,然后利用GNN、Graph Transformer等方法建模邏輯推理過程,從而增強模型的邏輯推理能力。另一類則是從預訓練角度出發,基于一些啟發式規則捕捉大規模文本語料中存在的邏輯關系,針對其設計相應的預訓練任務,對已有的預訓練語言模型進行二次預訓練,從而增強預訓練語言模型的邏輯推理能力。
3.1 基于圖的精調方法
3.1.1 DAGN
針對邏輯推理MRC篇章中復雜的邏輯關系,僅僅關注句子級別tokens之間的交互是不夠的,需要在篇章級別對句子之間的關系進行建模。但是邏輯結構隱式存在與文本中,難以直接抽取,大多數數據集也并不包含對文本中邏輯結構的標注。因此,DAGN提出使用語篇關系(discourse relation)來表示文本中的邏輯信息,語篇關系分為顯式和隱式兩類,顯式語篇關系指文本中的語篇狀語(如“instead”)、從屬連詞(如“because”),而隱式語篇關系則指連接文本片段的標點符號(句號、逗號、分號等)。語篇關系一定程度上對應著文本中的邏輯關系,例如:“because”指示因果關系,“if”指示假設關系等。
DAGN[7]使用來自PDTB2.0[8]中的語篇關系中作為分隔符,將文本劃分為多個基本語篇單元(Elementary Discourse Units, EDUs),以EDUs作為節點、EDUs間的語篇關系作為邊就得到了語篇圖結構,語篇圖的構建過程實例如圖4的左半部分所示。然后,作者利用圖網絡來從語篇圖中學習篇章的語篇特征,該特征與由預訓練語言模型得到的上下文表示合并,共同預測問題的答案。
DAGN使用EDUs作為基本的推理單元,利用學習得到的基于語篇的特征增強預訓練語言模型上下文表示,在ReClor和LogiQA兩個數據集上取得了有競爭力的表現。
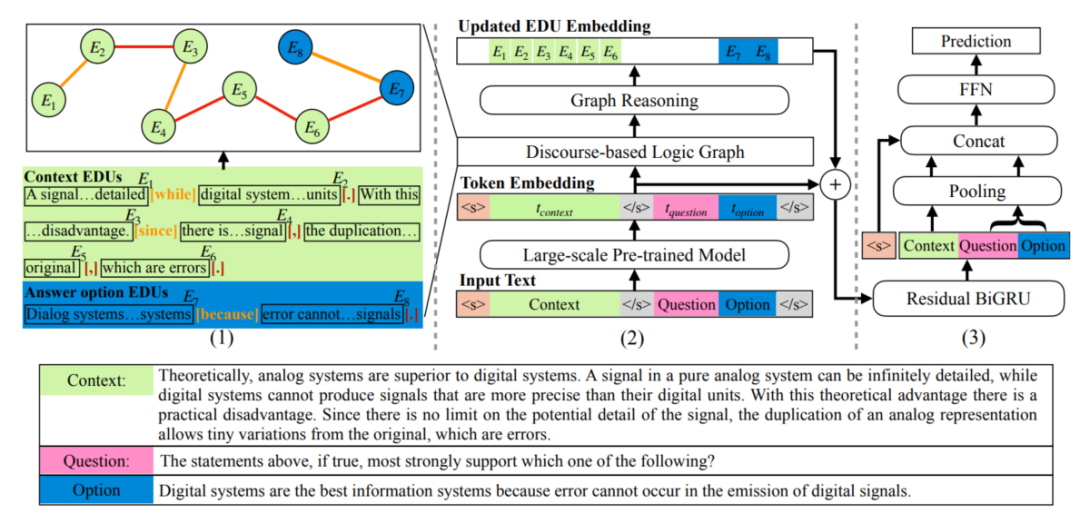
圖4 DAGN結構
3.1.2 AdaLoGN
傳統的神經模型無法很好地建模邏輯推理,而能夠進行邏輯推理的符號推理器卻無法直接應用于文本。同時,前面介紹的DAGN模型雖然基于語篇關系構建了語篇圖結構,但是語篇關系能否充分表示基于邏輯關系的符號推理仍然有待商榷,且該圖結構十分稀疏,由長路徑組成,這限制了GNN模型中節點與節點間的消息傳遞,導致篇章和選項間的交互不夠充分。
為了解決上述挑戰,AdaLoGN[9]這一神經-符號方法被提出,其整體框架與DAGN類似,由圖構建和基于圖的推理兩部分組成,區別在于采用有向的文本邏輯圖(Text Logic Graph,TLG)代替DAGN中的語篇圖,TLG仍然將EDUs作為節點,邊則采用了六種預定義的邏輯關系,其中合取(conj)、析取(disj)、蘊含(impl)、否定(neg)是命題邏輯中的標準邏輯連接詞,而rev表示反向的蘊含關系,unk表示未知的關系。作者首先使用Graphene[10]這一信息抽取工具抽取EDUs之間的修辭關系,然后將部分修辭關系映射為邏輯關系,具體映射如表2所示。
表2 Graphene中修辭關系到TLG中邏輯關系的映射

使用TLG相比起語篇圖的優勢在于可以使用符號化的推理規則對原始語篇圖進行擴展,基于已知推理得到未知的邏輯關系,AdaLoGN中作者使用的推理規則如圖5所示,包括命題邏輯中的假言三段論、置換規則以及作者自定義的一條規則。上述符號化推理過程得到的新關系可能對于后續GNN消息傳遞過程提供關鍵連接,幫助正確答案的預測,即符號推理增強了神經推理。而對基于推理規則得到的演繹閉包全盤接受也可能會引入不相關的連接,誤導后續的消息傳遞過程,因此,作者提出使用神經推理計算得到的信號來自適應地接納相關擴展,即神經推理增強了符號推理。
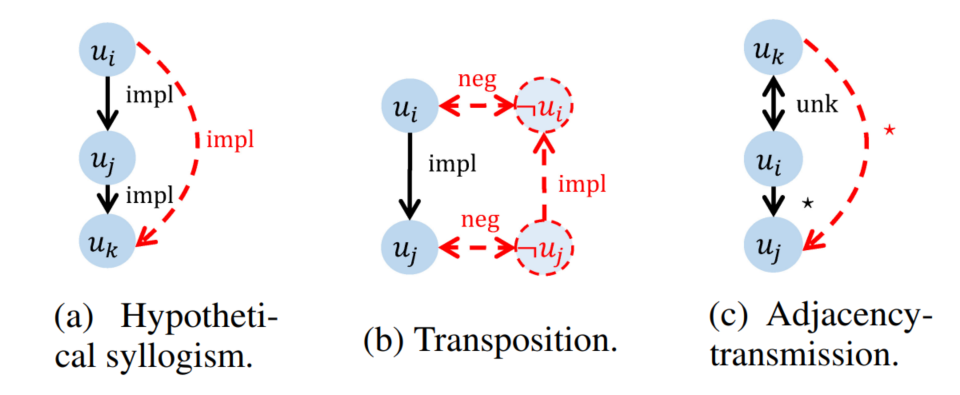
圖5 AdaLoGN中使用的推理規則,推理得到的新的節點與關系用紅色虛線表示
AdaLoGN的整體結構如圖6所示,可以看到自適應地擴展TLG、消息傳遞過程通過迭代多輪來使得符號推理和神經推理彼此充分交互。最終每一輪得到的擴展TLG表示和由RoBERTa得到的上下文token特征共同用于答案預測。AdaLoGN在LogiQA和ReClor數據集上取得了比DAGN更好的表現。
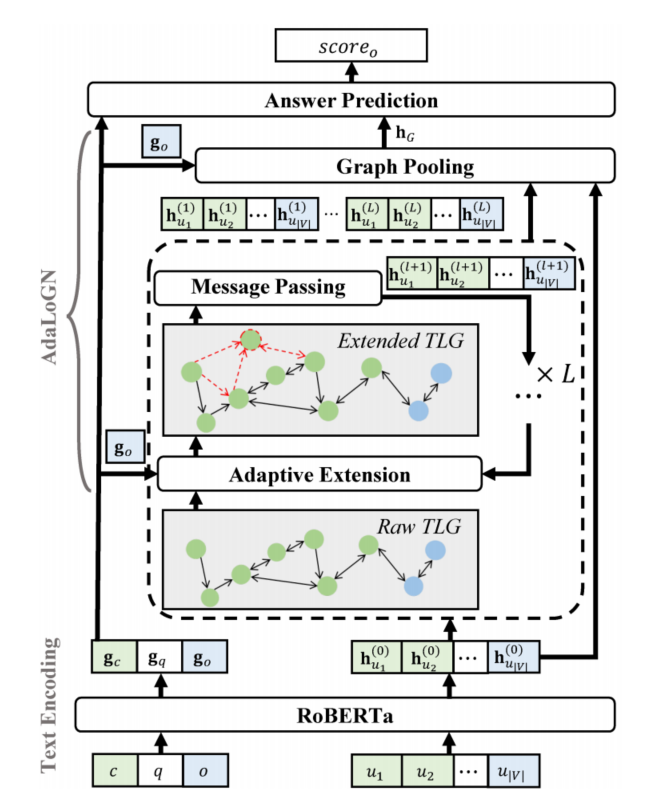
圖6 AdaLoGN結構
3.1.3 Loigformer
Logiformer[11]的作者認為,對于邏輯推理MRC任務來說,除了需要從文本中抽取邏輯單元外,還需要對邏輯單元間的長距離依賴進行建模,如圖7中展示的一個來自ReClor數據集的具體例子,從中可以看到因果關系與否定、共現關系普遍存在于邏輯推理任務中,針對這一點,作者提出基于篇章分別構建邏輯圖和句法圖,對上述的因果關系以及共現關系分別進行表示,然后使用一個兩支的graph transformer網絡來從兩個角度建模長距離依賴。

圖7 來自ReClor的具體例子及上下文中邏輯單元間的關系
Logiformer的結構如圖8所示,與之前的方法類似其首先基于文本中表示因果關系的邏輯單詞(如:if、unless、because等)以及標點符號構建邏輯圖,并基于因果關系為條件節點到結果節點間插入邊。句法圖則以文本中的句子作為節點,然后基于句子之間的token級別的重疊度來判斷句子之間的共現關系,為具有共現關系的節點插入邊。接著,作者使用兩個獨立的graph transformer分別對邏輯圖和句法圖中的依賴關系進行建模,并通過將圖對應的鄰接矩陣引入attention計算過程從而將圖的結構信息引入。邏輯圖的graph transformer示意圖如圖9所示。最后使用得到的token級別表示、句法節點表示和邏輯節點表示共同預測答案。Logiformer在LogiQA和ReClor數據集上取得了目前單模型的SOTA表現。
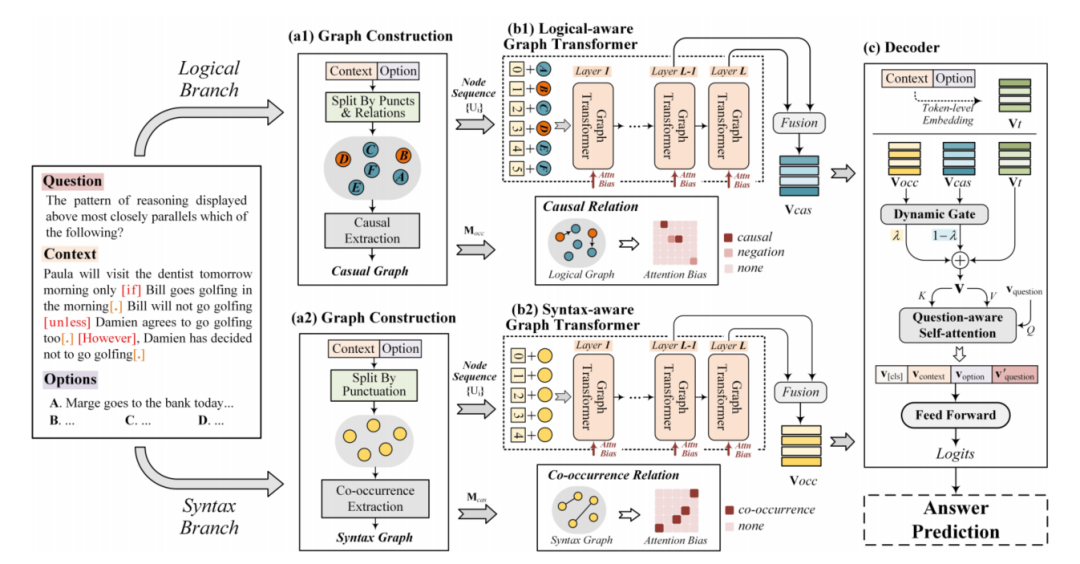
圖8 Logiformer結構
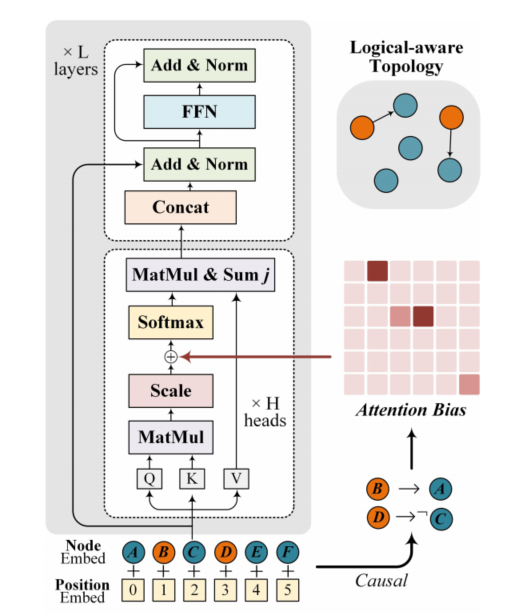
圖9 邏輯圖對應的graph transformer示意圖(句法圖對應的計算過程類似)
3.2 預訓練方法
3.2.1 MERIt
3.1節中介紹的基于圖的方法將關于邏輯關系的先驗知識引入模型,依賴于標注好的訓練數據,導致其在標注數據不足的情況下存在過擬合以及泛化性差的問題。MERIt[12]提出利用規則基于大量無標簽的文本數據仿照邏輯推理MRC任務形式構造用于對比學習自監督預訓練的數據,MERIt整體框架如圖10所示,其主要基于這樣一個直覺:文本中邏輯結構可以被由一系列關系三元組構成的推理路徑表示,而實體之間的元路徑(meta-path)先天地提供了表示邏輯一致性的手段。
MERIt的目標是基于大規模無標簽文本,構建上下文和選項,正確選項應當與上下文邏輯一致,而錯誤選項與上下文邏輯相悖,模型借助對比學習作為預訓練目標。MERIt首先識別文本中的實體,并基于實體在文本中的共現關系構建圖,對于該圖結構中直接相鄰任意兩個節點,如果它們之間具有其他元路徑,則將該節點這兩個節點之間的邊對應的句子作為正確選項,將元路徑上邊對應的句子作為上下文,這樣就得到了正例。負例的構建則是通過對已有正例進行修改完成的,為了防止模型在預訓練過程中基于自身掌握的常識知識而非邏輯一致性做出判斷,作者還采用了反事實的數據增強對文本中的實體進行替換,迫使模型基于邏輯進行預測。基于MERIt構造的數據二次預訓練得到的模型在下游任務上取得了相較于原預訓練模型更好的表現,且模型可以與3.1節中的方法同時使用來取得更優的結果。
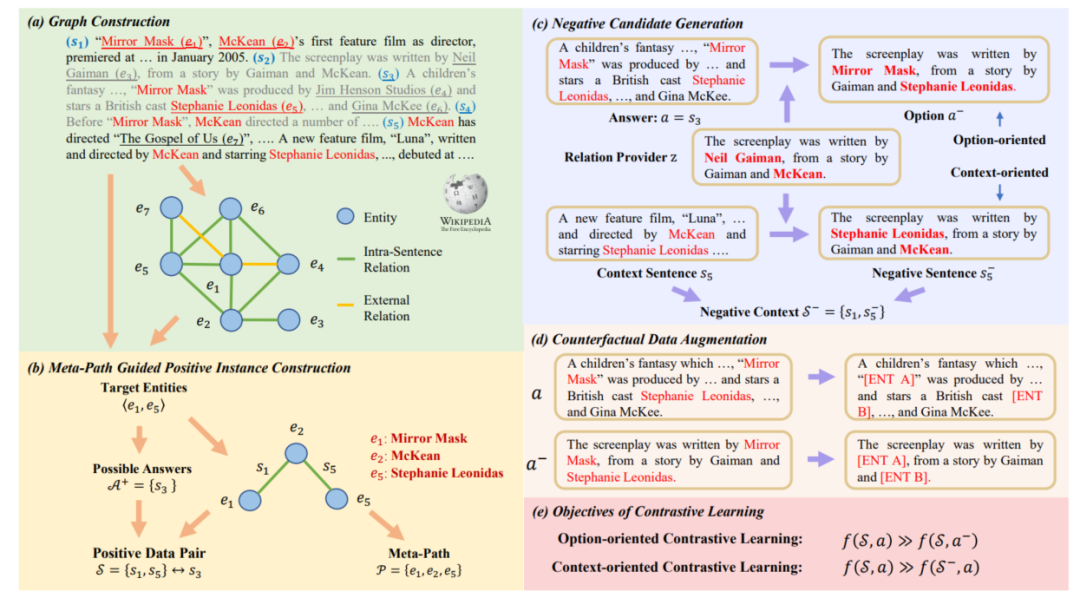
圖10 MERIt框架
3.2.2 LogiGAN
LogiGAN[13]將視線轉向了生成式模型(T5)以及包括邏輯推理MRC在內的多種需要推理能力任務上,旨在通過對MLM預訓練任務進行改進來強化模型的邏輯推理能力,并引入驗證器(verifier)來為生成式模型提供額外反饋,同時其通過簡單的策略規避了序列GAN中beam search帶來的不可導問題。
LogiGAN首先使用預先指定的邏輯指示器(例如:“therefore”、“due to”、“we may infer that”)來從大規模無標簽文本中識別邏輯推理現象,然后對邏輯指示器后面的表達進行mask,訓練生成式模型對被mask的表達(statement)進行恢復。例如對于“Bob made up his mind to lose weight. Therefore, he decides to go on a diet.”這段話中Therefore就是一個邏輯指示器,因此其后面的表達“he decides to go on a diet.”就會被mask然后交給模型預測。這種基于已知推出未知的訓練目標相比起隨機的MLM更能增強模型的邏輯推理能力。
LogiGAN的框架如圖11所示,模型由生成器和驗證器兩部分組成,驗證器執行一個文本分類任務:以上下文和表達作為輸入,判斷該表達來自于原文的真實表達還是構造得到偽表達,判別器本質上就是在判斷上下文和表達的邏輯一致性。偽表達有兩個來源:從生成器中通過beam search得到的生成概率較高的句子(self-sampling)和基于真實表達從語料庫中檢索得到的近似表達(retrieved)。生成器除了需要學習生成真實表達外,還要讓自己生成偽表達的似然得分分布與判別器給出邏輯一致性得分分布盡可能一致。LogiGAN在包括LogiQA和ReClor在內的12個需要推理的下游任務上相較于vanilla T5都取得了明顯的提升。
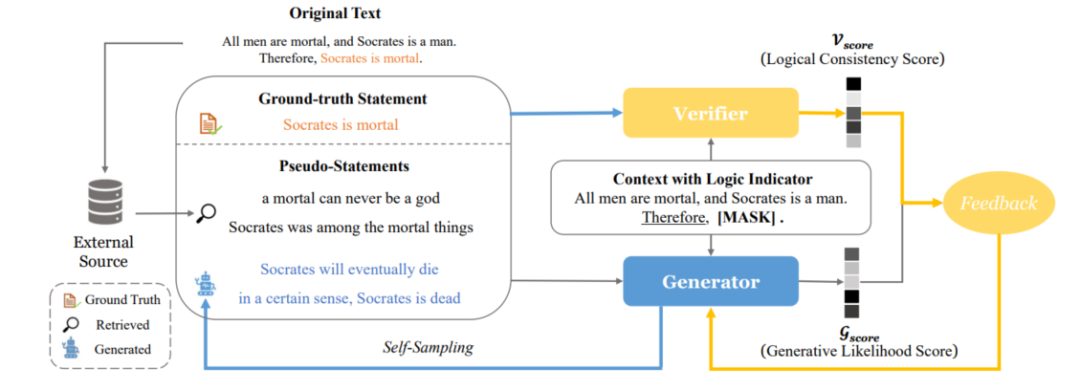
圖11 LogiGAN框架
4.總結
目前針對邏輯推理MRC任務主要從精調和預訓練兩個角度出發,精調階段的方法主要圍繞圖的構建與使用展開,如何將文本劃分為邏輯單元,指定邏輯單元之間的邏輯關系,引入符號化的推理規則是這類工作的重點。而預訓練階段的方法則側重于如何發掘大規模無標簽文本中蘊含的邏輯推理現象,設計合理的預訓練任務。已有方法在兩個邏輯推理MRC數據集上的表現距離人類仍有較大差距,期待未來能有更大規模的新數據集和更有效的新方法被提出。
審核編輯:郭婷
-
數據集
+關注
關注
4文章
1208瀏覽量
24737 -
深度學習
+關注
關注
73文章
5507瀏覽量
121272
原文標題:邏輯推理閱讀理解任務及方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何把兩個數據返回給調用函數
ADC124S021同時使用兩個通道,兩個通道的轉換數據發生串擾怎么解決?
ADS125H01測量結果在兩個數值之間跳變,如何規避此類問題?
邏輯異或和邏輯或的比較分析
CISC(復雜指令集)與RISC(精簡指令集)的區別
兩個PLC之間如何交互信號
【大語言模型:原理與工程實踐】大語言模型的評測

傳感器之外—兩個數據庫之間的“連接”查詢
arcgis中如何關聯兩個屬性表
PSOC同時使用兩個Em_EEPROM,有一個數據會丟失的原因?
二進制與邏輯電平的變化范圍

百川智能發布角色大模型,零代碼復刻角色





 工商網監
工商網監
評論