 生成式摘要的經典模型
生成式摘要的經典模型
寫在前面
在一文詳解生成式文本摘要經典論文Pointer-Generator中我們介紹了生成式摘要的經典模型,今天我們來分享一篇帶風格的標題生成的經典工作。

以往的標題模型產生的都是平實性標題,即簡單語言描述的事實性標題。但是,實際上我們可能更需要有記憶點的爆款標題來增加點擊量/曝光率。因此,衍生出了一個新任務——帶有風格的標題生成,即Stylistic Headline Generation,簡稱SHG。
本篇文章將介紹TitleStylist模型,該模型是針對SHG任務提出的,它可以生成相關、通順且具有風格的標題,其中風格主要包括三種:幽默、浪漫、標題黨。
論文名稱:《Hooks in the Headline: Learning to Generate Headlines with Controlled Styles》
論文鏈接:https://arxiv.org/abs/2004.01980v1
代碼地址:https://github.com/jind11/TitleStylist
1. 問題定義
首先假設我們有兩類數據和:是由文章-標題對組成的數據;是由具有某種特定風格的句子組成的數據。
我們用來表示數據,其中表示文章,表示標題。此外,我們用來表示數據。需要注意的是,中的句子可以是書本中的句子,不一定是標題。
假設我們有、、。那么,SHG任務目的是從中學習,也就是從分布、中學習出條件分布。
2. 核心思想
TitleStylist模型整體上是一個Transformer結構,分為Encoder(編碼器)和Decoder(解碼器)。TitleStylist利用多任務學習,同時進行兩個任務:
標題生成:有監督任務;在數據S上,根據文章原文生成相應標題。
帶有風格的文本重構:無監督或自監督;在數據上,輸入為擾亂后的句子,生成原句。
標題生成與帶有風格的文本重構兩個任務的數據集和模型都是獨立的。為了生成帶有風格的標題,TitleStylist通過參數共享將二者融合。
3. 模型細節
3.1 序列到序列模型架構(Seq2Seq Model Architecture)
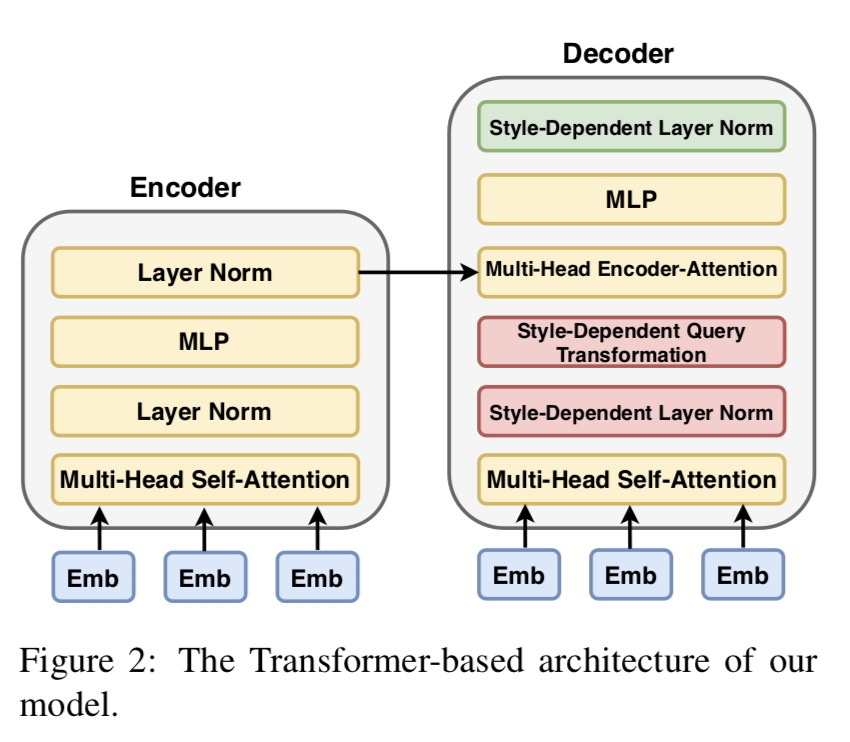
如上圖,TitleStylist采用了Transformer架構的seq2seq模型,它包含編碼器和解碼器。為了提高生成的標題的質量,TitleStylist使用MASS模型來初始化模型參數。
3.2 多任務學習
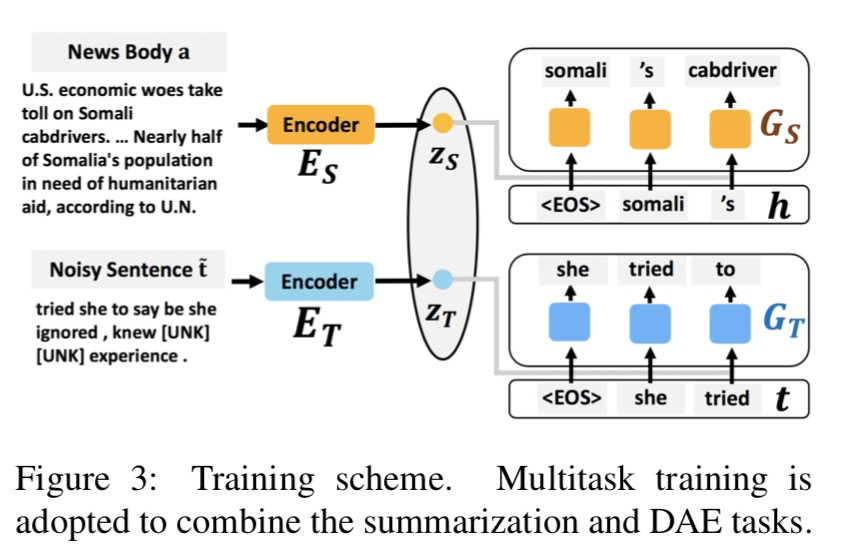
為了分離文本的風格和內容,模型引入多任務學習框架。在這里主要包含兩個任務:標題生成及DAE(Denoising Autoencoder)。根據論文描述,我們在這里將DAE稱為帶風格的文本重構。
有監督的標題生成
在標題生成任務中,首先我們輸入文章原文,然后經過編碼器獲得向量表征;接著,再利用解碼器生成標題。
換句話說,在標題生成任務中,我們是利用編碼器和解碼器學習條件分布。我們設是編碼器的待優化參數,是解碼器的待優化參數,那么標題生成任務的損失函數如下:
其中是單向語言模型,即:
這里代表句子的長度。
無監督/自監督的風格文本重構
在文本重構任務中,對于句子,我們通過隨機刪除或者遮蓋某些詞,或者改變文本中詞的順序可以獲得破壞版本的句子。將作為模型輸入,經過編碼器獲得中間表征,再經過解碼器進行還原獲得。這個任務的目的是在還原句子時使模型學到風格化句子的能力。
同樣我們設是編碼器的待優化參數,是解碼器的待優化參數,那么文本重構任務的損失函數如下:
聯合學習
最終,多任務學習會最小化將兩部分的損失函數之和:
3.3 如何生存帶有特定風格的相關標題
到目前為止,大家可能會有所疑問:兩個任務除了損失函數是一同優化外再沒有看到其他任何關聯, 那么TitleStylist怎么可能學到問題部分定義的終極目標,畢竟我們只有來自分布、的數據,并沒有來自分布的數據。
實際上,TitleStylist通過設計參數共享策略,讓兩個任務的編碼器及解碼器存在某種關聯,最終以此來建模。那么如何進行參數共享呢?
最簡單的,可以直接共享所有參數(與共享,與共享)。這樣模型等于同時學了標題生成與帶風格的文本重構兩個任務。其中標題生成的任務讓模型學到了如何生成與文章內容相關的標題;帶風格的文本重構則讓模型學到了如何在還原文本時保留文本具有的風格。在兩個任務的相互加持下,模型就可以生成和文章相關的又具有特定風格的標題。
好了,我們就想到這里。接下來看看TitleStylist究竟是怎么做的。
3.4 參數共享
剛才我們所說的直接共享所有參數的方式存在一個問題,就是模型并沒有真正地顯式地區分開文本內容與文本風格,那么模型就是又學了中的事實性風格,又學了中的特定風格(比如幽默、浪漫或標題黨)。
TitleStylist為了更好地區分開文本內容與文本風格,顯式地學習數據中所包含的風格,選擇讓編碼器共享所有參數,解碼器共享部分參數。個人認為編碼器端之所以完全共享參數,是想在編碼時盡可能保留原文信息。
如上圖所示,解碼器端的參數主要被分成兩部分:黃色部分表示不依賴風格的參數,是共享的;剩余依賴風格的參數,不共享。
具體地,存在于Layer Normalization及Decoder Attention,即層歸一化及解碼器注意力兩部分:
(1) 帶風格的層歸一化(Style Layer Normalization)
帶風格的層歸一化這個部分是借鑒圖像風格遷移的思想。其中分別是的的均值和標準方差,是模型需要學習的與風格相關的參數。
(2) 帶風格的解碼器注意力(Style-Guided Encoder Attention)
TitleStylist認為兩個任務的解碼器端在逐個生成下一個詞時的注意力機制應該有所不同。在這里,TitleStylist主要是設置了不同的,以此生成不同的從而形成不同的注意力模式。
這里代表風格,對標題生成而言其實可以算作事實性風格;對文本重構而言,可能是幽默、浪漫或標題黨風格。
TitleStylist結合完全共享參數的編碼器與部分參數共享的解碼器來實現其目標模型,最終可以生成帶有特定風格的又與原文內容相關的標題。
總結
好了,帶風格的標題生成論文《Hooks in the Headline: Learning to Generate Headlines with Controlled Styles》的內容就到這里了。在本篇文章中,我們就論文思想與論文所提出的模型的結構設計進行了介紹。論文實驗部分小喵沒有細看,大家感興趣的話可以下載原文并結合源碼進行學習。
審核編輯 :李倩
-
解碼器
+關注
關注
9文章
1143瀏覽量
40718 -
編碼器
+關注
關注
45文章
3639瀏覽量
134429
原文標題:文本生成 | 一篇帶風格的標題生成的經典工作
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA推出全新生成式AI模型Fugatto
在設備上利用AI Edge Torch生成式API部署自定義大語言模型

NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型

聲智完成多項生成式算法和大模型服務備案

經典卷積網絡模型介紹
如何用C++創建簡單的生成式AI模型
生成式AI與神經網絡模型的區別和聯系
Runway發布Gen-3 Alpha視頻生成模型
大語言模型:原理與工程時間+小白初識大語言模型
世界數字技術院發布:生成式AI安全測試標準及大語言模型
生成式 AI 進入模型驅動時代

小白學大模型:什么是生成式人工智能?

OpenAI 在 AI 生成視頻領域扔出一枚“王炸”,視頻生成模型“Sora”






 工商網監
工商網監
評論