 如何設計更智能的Edge AI
如何設計更智能的Edge AI
作為一名擁有 40 多年半導體業務研發總監和 CMO 經驗的工程師,我認為我自己和我的同行是合乎邏輯的。然而,我們當中有多少人可以誠實地說我們沒有被諸如“我的小部件比你的快?”這樣的說法所誘惑。恐怕這只是人性,尤其是當我們對你的專業知識沒有信心來調查這些說法時。
問題始終是一個定義:我如何定義“更快”或“更低功率”或“更便宜”?這是基準試圖解決的問題——它是關于具有一致的上下文和外部標準,以確保您將同類與同類進行比較。任何使用基準測試的人都非常清楚這一點(aiMotive 誕生于一家領先的 GPU 基準測試公司)。
在嘗試比較汽車 AI 應用的硬件平臺時,解決這種轟炸式索賠的需求從未像現在這樣緊迫。
10 TOPS 什么時候不是 10 TOPS?
無論是否有專用的 NPU,大多數 SoC 都將其執行 NN 工作負載的能力稱為 TOPS:每秒 Tera 操作。這只是 NPU(或整個 SoC)原則上每秒可以執行的算術運算總數,無論全部集中在專用 NPU 中還是分布在多個計算引擎中,例如 GPU、CPU 矢量協處理器、或其他加速器。
但是,沒有任何硬件執行引擎能以 100% 的效率執行任何工作負載的各個方面。對于神經網絡推理,某些層(例如池化或激活)在數學上與卷積非常不同。在卷積本身(或其他層,如池化)可以開始之前,數據必須重新排列或從一個地方移動到另一個地方。其他時候,NPU 可能需要等待來自控制它的主機 CPU 的新指令或數據,每個層甚至每個數據塊。這些都導致完成的計算更少,從而限制了理論上的最大容量。
硬件利用率——不是它看起來的樣子
許多 NPU 供應商會引用硬件利用率來表明他們的 NPU 執行給定 NN 工作負載的情況。這基本上是說,“這就是我的 NPU 的理論容量有多少被用于執行 NN 工作負載。” 當然,這告訴我我需要知道什么。
不幸的是沒有。硬件利用率的問題是定義之一:數量完全取決于 NPU 供應商選擇如何定義它。事實上,硬件利用率和 TOPS 的問題在于它們只告訴你硬件引擎理論上能夠實現什么,而不是它實現的程度。
這可能會導致一些誤導性信息。下面的圖 1 顯示了我們在額定 4 TOPS 的 aiWare3P NPU 與另一個額定為 8 TOPS 的知名 NPU 之間進行的比較。
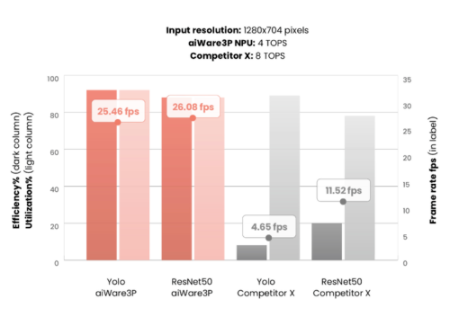
圖 1:兩個汽車推理 NPU 的利用率與效率比較
對于兩個不同的知名基準,競爭對手 X NPU 聲稱 8 TOPS 容量,而 aiWare3P 的 4 TOPS。這應該意味著它將提供大約 2 倍于 aiWare3P 的 fps 性能。然而,實際上,情況正好相反:aiWare3P 的性能提高了 2 到 5 倍,盡管它只是聲稱的 TOPS 的一半!
結論:TOPS 是衡量 AI 硬件能力的一種非常糟糕的方法;硬件利用率幾乎與 TOPS 一樣具有誤導性。
NPU 效率和自主性:優化 PPA 的關鍵
這就是為什么我認為您必須根據執行一組代表性工作負載時的效率而不是原始理論硬件容量來評估 NPU 能力。效率定義為為一幀執行特定 CNN 需要多少操作,占聲稱的 TOPS 總數的百分比。該數字僅基于定義任何 CNN 的基礎數學算法計算得出,無論 NPU 實際如何評估它。它比較了實際與聲稱的性能,這才是真正重要的。
展示出高效率的 NPU 意味著它將充分利用用于實現它的每平方毫米硅片,這意味著更低的芯片成本和更低的功耗。效率可為汽車 SoC 或 ASIC 提供最佳 PPA(性能、功率和面積)。
NPU 的自治性是另一個重要因素。NPU 在主機 CPU 上放置多少 CPU 負載才能達到最高性能?這與內存子系統有什么關系?NPU 必須被視為任何 SoC 或 ASIC 中的大塊——它對芯片和子系統其余部分的影響不容忽視。
結論
在設計任何 SoC 或 ASIC 汽車時,AI 工程師必須專注于構建能夠可靠執行其算法的生產平臺,同時實現卓越的 PPA:最低功耗、最低成本、更高性能。他們還必須在設計周期的早期就選擇硬件平臺,通常是在開發最終算法之前。
效率是實現這一目標的最佳方式;TOPS 和硬件利用率都不是好的衡量標準。如果要滿足苛刻的生產目標,評估 NPU 的自主性也至關重要。
審核編輯:郭婷
-
cpu
+關注
關注
68文章
10901瀏覽量
212686 -
soc
+關注
關注
38文章
4199瀏覽量
218815 -
AI
+關注
關注
87文章
31490瀏覽量
269915
發布評論請先 登錄
相關推薦
人工智能和機器學習以及Edge AI的概念與應用
北斗智聯入選2024 EDGE AWARDS年度汽車科技榜
康普推出RUCKUS Edge云托管邊緣平臺
貿澤開售適用于AI和機器學習應用的 AMD Versal AI Edge VEK280評估套件
在設備上利用AI Edge Torch生成式API部署自定義大語言模型

Google AI Edge Torch的特性詳解

AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
人工智能ai4s試讀申請
使用TI Edge AI Studio和AM62A進行基于視覺AI的缺陷檢測

Edge AI工控機的定義、挑選考量與常見應用
凌華智能推出全新AI 邊緣服務器MEC-AI7400 (AI Edge Server)系列
意法半導體ST Edge AI Suite人工智能開發套件上線
**十萬級口語識別,離線自然說技術,讓智能照明更懂你**
【ALINX 技術分享】AMD Versal AI Edge 自適應計算加速平臺之 Versal 介紹(2)





 工商網監
工商網監
評論