") TinyML設備的設備上持續(xù)學習
TinyML設備的設備上持續(xù)學習
隨著現(xiàn)代人工智能技術的興起,對設備上模型訓練的需求已成為一個重要的研究領域。任務復雜性和工作量的增加強調了將 AI 模型訓練帶到邊緣的必要性。
在邊緣進行推理之后,需要在邊緣的設備上持續(xù)訓練 AI 模型,以處理具有非平穩(wěn)輸入的不確定情況。深度學習模型在部署到嵌入式設備之前在遠程服務器上進行訓練。但是已經(jīng)發(fā)生了向持續(xù)學習的轉變,設備上的個性化可以通過新獲取的數(shù)據(jù)增加基于用戶交互的自適應功能。
在設備上更新和重新訓練已經(jīng)訓練過的模型可能需要很長時間,這對于實時輸入來說幾乎是不可能完成的任務。即使只是簡單地更新預測模型,新的傳入數(shù)據(jù)也會導致災難性的遺忘,其中人工神經(jīng)網(wǎng)絡在學習新信息時會完全突然地忘記先前學習的信息。
持續(xù)學習 (CL) 是隨著不斷變化的外部環(huán)境、動態(tài)傳入數(shù)據(jù)而增量學習的能力,以及泛化分布外和執(zhí)行遷移和元學習的能力。由于內存和計算量的增加,神經(jīng)網(wǎng)絡僅在部署到嵌入式設備之前進行推理訓練。直到最近,對超低功耗設備的深度學習模型的研究仍基于訓練后部署假設,其中靜態(tài)模型無法在不斷變化的環(huán)境中采用。為了改變動態(tài),在基于 Latent Replay 的 CL 技術上開展的工作,超低功耗 TinyML 設備對計算和內存的需求一直是個問題。
實時持續(xù)學習的潛在回放
持續(xù)學習的 Latent Replay 方法實際上意味著可以從上面的架構圖中理解的幾個方面。在潛在重放中,不是將過去數(shù)據(jù)的一部分存儲在輸入空間中,而是將數(shù)據(jù)存儲在某個中間層的激活卷中。這反過來又解決了計算和存儲問題,為此在復雜的視頻上進行了基準測試,例如 CORe50 NICv2 和 OpenLORIS。
查看 Latent Replay 的架構圖,離輸入層更近的層,通常稱為表示層,通常會執(zhí)行低級特征提取。預訓練模型的權重是穩(wěn)定的,可以跨應用程序重復使用,而更高級別的模型提取特定于類的特征,對于最大限度地提高準確性至關重要。為了保持穩(wěn)定性,所提出的方法在 Latent Replay 之下的層采用減慢學習速度,并讓上面的層以自己的速度學習。
即使較低層的速度減慢到零,也可以節(jié)省計算和存儲,因為需要在網(wǎng)絡中向前和向后流動的模式的一小部分。但在表示層未凍結為零的正常情況下,存儲在外部存儲器中的激活會經(jīng)歷老化效應。如果層的訓練很慢,老化效應不會破壞,因為外部記憶有時間恢復新的模式。
具有量化潛在重放的設備上持續(xù)學習
在最近基于 Pellegrini 所做工作的研究中,研究人員致力于開發(fā)一個 TinyML 平臺,用于通過量化的潛在回放進行設備上的持續(xù)學習。這項工作采用 VEGA,這是一個基于 PULP 的深度學習 TinyML 平臺,它是一種采用 22nm 工藝技術制造的端節(jié)點片上系統(tǒng)原型。CL 的 Latent Replay 已經(jīng)在智能嵌入式設備上進行了測試,包括在 Snapdragon-845 CPU 上運行的智能手機。但這項工作更側重于超低功耗 TinyML 設備,以節(jié)省與之相關的計算和內存限制。
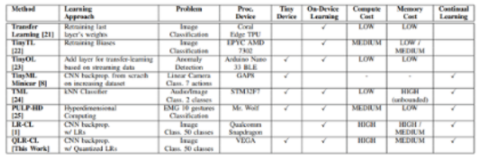
該研究提出了擴展 Latent Replay 算法以使用 8 位量化和凍結前端的想法。這不會影響 CL 過程并支持帶有量化的 Latent Replay 壓縮,從而將內存需求減少多達 4.5 倍。這被稱為持續(xù)學習的量化潛在重放。CL 原語包括常見層的前向和后向傳播,如卷積、深度卷積和全連接層,它們經(jīng)過調整以在 VEGA 上優(yōu)化執(zhí)行。
可以根據(jù)應用程序和可用資源定義的計算和存儲精度之間始終存在權衡。用于持續(xù)學習的潛在重放是適用于從嵌入式設備到智能小工具的各種系統(tǒng)的最有效方式。
審核編輯:郭婷
-
嵌入式
+關注
關注
5089文章
19167瀏覽量
306720 -
cpu
+關注
關注
68文章
10898瀏覽量
212536 -
深度學習
+關注
關注
73文章
5511瀏覽量
121376
發(fā)布評論請先 登錄
相關推薦
在邊緣設備上設計和部署深度神經(jīng)網(wǎng)絡的實用框架
AI編程在工業(yè)自動化設備上應用趨勢
PLC設備的數(shù)據(jù)采集上云解決方案
焊接設備維護技巧
可穿戴設備上的血壓監(jiān)測申請簡介

第二屆大會回顧第25期 | OpenHarmony上的Python設備應用開發(fā)

2024工業(yè)設備上云產(chǎn)業(yè)調研報告:誰在乘“云”而上?
把好事辦好:工業(yè)設備更新上云難題與破解
工業(yè)機床CNC設備如何上云?
工業(yè)平板電腦雕刻機設備上的應用

工業(yè)平板電腦在印刷機械設備上的應用
手持設備上使用的掃碼模組






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論