
 【GCC編譯優化系列】使用GCC如何把C文件編譯成可執行文件
【GCC編譯優化系列】使用GCC如何把C文件編譯成可執行文件

1 前言
自參加RTT論壇的【問答有獎】活動以來,回答了300+問題,期間我特意去檢索過【編譯】相關的問題,從下圖可以看得出,編譯問題真的是很常見的問題類型,不管你是新手還是老手,多多少少都遇到過奇奇怪怪的編譯問題。
而我平時非常喜歡研究跟編譯相關的問題,期間也挑了好一些編譯相關的問題,給出了我的答案,我也會盡力在解答問題的過程中,把我解決編譯問題用到的方法論也一并分享出來,希望能幫助到大家。
但是由于回答單個編譯問題,畢竟篇幅有限,只能就特定的場景下,如何解決問題而展開,而不能系統地介紹一些代碼編譯相關的基礎知識,所以我才萌生了通過自己寫一些通識性比較強的技術文章來補充這一部分的知識空白。
本系列的文章,計劃安排兩篇文章,第一篇結合gcc編譯器介紹編譯相關的基礎知識,第二篇結合實際的代碼案例分析如何解決各種編譯相關的問題。當然如果大家想了解編譯相關的其他內容,也歡迎在評論席告知。
本文作為分享的第一篇,主要介紹了C代碼是如何被編譯生成二進制文件的詳細步驟,期間用到了gcc編譯器,希望能提升大家對C代碼編譯的基礎認知以及gcc編譯器的使用技巧。
2 C代碼的編譯步驟
C代碼編譯的步驟,需要經歷預編譯、編譯、匯編、鏈接等幾個關鍵步驟,最后才能生成二進制文件,而這個二進制文件就是能被CPU識別并正確執行指令的唯一憑證。
整個過程有預編譯、編譯器、匯編器、鏈接器在工作,正如這張圖所展示的這樣:
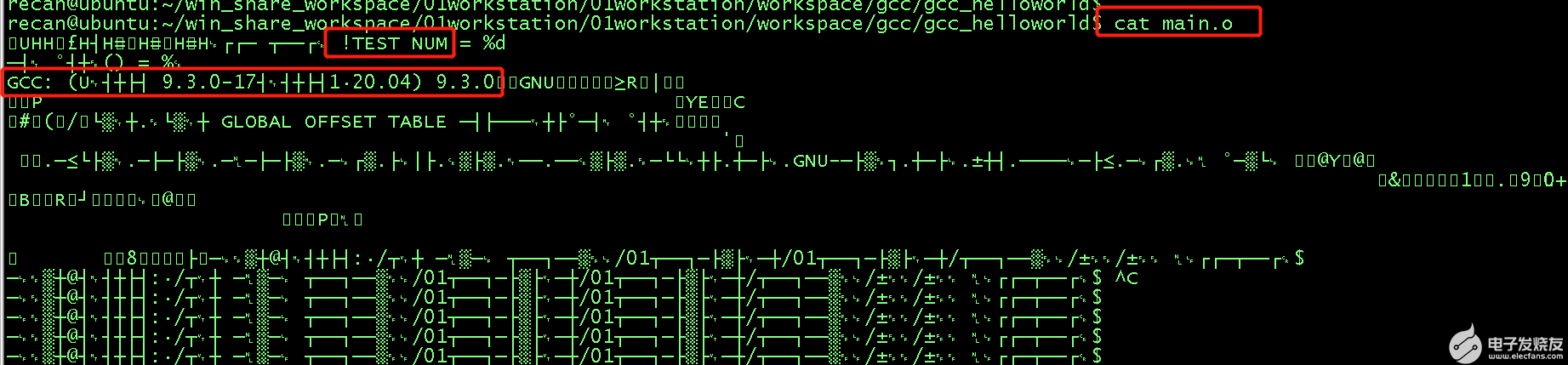
下面簡要介紹下,各個步驟的主要工作。
2.1 預處理(Preprocessing)
預編譯,主要體現在這個預字,它的處理是在編譯的前面。
在C語言里,以“#”號開頭的預處理指令,如文件包含#include、宏定義制定#define、條件編譯#if等。 在源程序中,這些指令都放在函數體的外面,可以放在源文件(.c文件)中,也可以放在頭文件(.h)中。 預編譯這一步要做到事情,就是把預處理的指令進行展開,這里主要介紹上面提到的三類預處理指令。
#include:這個就是把后面的文件直接拷貝到預處理指令的位置,當然這里也會處理依賴include的問題,比如A文件 include B文件,而B文件又include了C文件,那么在A里面是看到C文件的內容的。還有有個盲區就是,include是可以include xxx.c的,這個在C語言的語法上是沒有任何問題的,大家千萬別以為只能C文件 include 頭文件。#define:這個就是處理宏定義的展開,注意宏定義是原封不動的展開、替換,它是不考慮語法規則的,這一點在寫宏定義的時候尤其需要注意,有的時候多寫一些包括可以減少因展開帶來的不必要麻煩。#if:這個就是處理條件編譯,類似的預處理指令有好幾個:#ifdef #ifndef #else #elif #endif等,這些預處理指令后面接一個條件,常常用于控制部分代碼參不參與編譯,這也就是我們常說的代碼裁剪,絕大多數的支持裁剪的軟件代碼,都是通過這種#if條件編譯的形式來實現的。
2.2 編譯(Compilation)
這一步是C代碼編譯的真正開始,主要是把預處理之后的C代碼,編譯成匯編代碼;即由高級語言代碼翻譯成低級語言代碼。 在編譯過程中,編譯器主要作語法檢查和詞法分析。在確認所有指令都符合語法規則之后,將其翻譯成等價的匯編代碼。
2.3 匯編(Assemble)
這一步是將上一步生成的匯編代碼,通過匯編器,將其轉成二進制目標代碼,這個就是我們常說的obj文件。 經過這一步,單個.c文件就編譯完了;換句話說,每一個.c文件編譯到obj文件,都要經過預編譯、編譯、匯編這三步。
2.4 鏈接(Linking)
這一步是通過鏈接器,將上一步生成的所有二進制目標文件、啟動代碼、依賴的庫文件,一并鏈接成一個可執行文件,這個可執行文件可被加載或拷貝到存儲器去執行的。
這里需要注意的是,不同的操作系統下這個可執行文件的格式是不同的:
Windows系統是exe后綴名的可執行文件; Linux系統下是elf文件(沒有后綴名的說法),也是可執行文件; MacOS系統下是Mach-O文件,也是可執行文件。
各種類型的可執行文件的詳細分析,可參見我轉載的一篇博文。
2.5 生成二進制文件(Objcopy)
如果是在嵌入式設備上,使用類似RTOS(Real-Time Operating System)的操作系統,因內存、存儲等資源受限,他們不具備像PC環境下的Linux這種高級操作系統那樣可以解析可執行文件,然后把二進制的指令代碼搬到CPU上去運行,所以在這樣的背景下,我們需要在編譯結束后,就把可執行文件轉換成二進制代碼文件,也就是我們常說的.bin文件。
一般來說,在嵌入式設備中,這種.bin文件是直接燒錄在Flash中的,如果存儲bin文件的Flash支持XIP(eXecute In Place,即芯片內執行)的話,那么指令代碼是可以直接在Flash內執行,而不需要搬到內存中去,這也是最大化地利用嵌入式有限的資源條件。
在生成二進制文件這一步中,不同的編譯器及不同的操作系統下,可能使用的方法是不一樣的,在Linux平臺下使用的是objcopy命令來完成這一操作,具體的用法下文會詳細介紹。
3 gcc如何編譯C代碼
下面以gcc編譯器為例,介紹下在Linux平臺下,一個C代碼工程是如何編譯生成最終的bin文件的。
3.1 gcc命令參數介紹
在介紹如何使用gcc編譯之前,我們需要先了解下gcc的幾個重要的命令行參數,這種命令行參數問題,如果不懂就讓命令行自己告訴你吧:
gcc/gcc_helloworld$ gcc --help
Usage: gcc [options] file...
Options:
-pass-exit-codes Exit with highest error code from a phase.
--help Display this information.
--target-help Display target specific command line options.
--help={common|optimizers|params|target|warnings|[^]{joined|separate|undocumented}}[,...].
Display specific types of command line options.
(Use '-v --help' to display command line options of sub-processes).
--version Display compiler version information.
-dumpspecs Display all of the built in spec strings.
-dumpversion Display the version of the compiler.
-dumpmachine Display the compiler's target processor.
-print-search-dirs Display the directories in the compiler's search path.
-print-libgcc-file-name Display the name of the compiler's companion library.
-print-file-name= Display the full path to library .
-print-prog-name= Display the full path to compiler component .
-print-multiarch Display the target's normalized GNU triplet, used as
a component in the library path.
-print-multi-directory Display the root directory for versions of libgcc.
-print-multi-lib Display the mapping between command line options and
multiple library search directories.
-print-multi-os-directory Display the relative path to OS libraries.
-print-sysroot Display the target libraries directory.
-print-sysroot-headers-suffix Display the sysroot suffix used to find headers.
-Wa, Pass comma-separated on to the assembler.
-Wp, Pass comma-separated on to the preprocessor.
-Wl, Pass comma-separated on to the linker.
-Xassembler Pass on to the assembler.
-Xpreprocessor Pass on to the preprocessor.
-Xlinker Pass on to the linker.
-save-temps Do not delete intermediate files.
-save-temps= Do not delete intermediate files.
-no-canonical-prefixes Do not canonicalize paths when building relative
prefixes to other gcc components.
-pipe Use pipes rather than intermediate files.
-time Time the execution of each subprocess.
-specs= Override built-in specs with the contents of .
-std= Assume that the input sources are for .
--sysroot= Use as the root directory for headers
and libraries.
-B Add to the compiler's search paths.
-v Display the programs invoked by the compiler.
-### Like -v but options quoted and commands not executed.
-E Preprocess only; do not compile, assemble or link.
-S Compile only; do not assemble or link.
-c Compile and assemble, but do not link.
-o Place the output into .
-pie Create a dynamically linked position independent
executable.
-shared Create a shared library.
-x Specify the language of the following input files.
Permissible languages include: c c++ assembler none
'none' means revert to the default behavior of
guessing the language based on the file's extension.
Options starting with -g, -f, -m, -O, -W, or --param are automatically
passed on to the various sub-processes invoked by gcc. In order to pass
other options on to these processes the -W options must be used.
For bug reporting instructions, please see:
.
我們重點要關注-E-S-c-o選項,下面的步驟中分別會使用到這些選項,再詳細介紹下對應的選項。
-E Preprocess only; do not compile, assemble or link.
-S Compile only; do not assemble or link.
-c Compile and assemble, but do not link.
-o Place the output into .3.2 helloworld工程的示例C代碼
這個小工程由3個文件組成,1個.H頭文件,2個.C源文件:
/* sub.h */
#ifndef __SUB_H__
#define __SUB_H__
#define TEST_NUM 1024
extern int sub_func(int a);
#endif /* __SUB_H__ */
/* sub.c */
#include
#include "sub.h"
int sub_func(int a)
{
return a + 1;
}
/* main.c */
#include
#include "sub.h"
#ifdef USED_FUNC
void used_func(void)
{
printf("This is a used function !\n");
}
#endif
int main(int argc, const char *argv[])
{
printf("Hello world !\n");
printf("TEST_NUM = %d\n", TEST_NUM);
printf("sub_func() = %d\n", sub_func(1));
#ifdef USED_FUNC
used_func();
#endif
return 0;
}
代碼邏輯很簡單,sub模塊定義了一個函數sub_func和一個宏定義的整型數,提供給main函數調用;main函數里面分別打印hello world,獲取宏定義整型數的值,調用sub_func接口,以及根據USED_FUNC是否被定義再決定是否調用used_func函數。
這個小小工程中,包含了#include頭文件包含、#define宏定義、#ifdef條件編譯等幾個重要的預處理指令,我認為,稍微有一點點C語言基礎的朋友都應該可以毫無障礙地看懂這幾行代碼。
3.3 預編譯生成.i文件
預編譯是編譯流程的第一步,這里最重點就是預處理指令的處理。
使用gcc編譯器執行預編譯操作,需要用到的主要命令行參數是-E,具體如下:
gcc -E main.c -o main.i
gcc -E sub.c -o sub.i
注意:這里是每一個.c源文件都需要預編譯,-o表示指定生成預編譯后的文件名稱,一般這個文件我們使用.i后綴。
為了了解預編譯究竟干了啥?我們可以打開這些.i文件,一瞧究竟。這里以main.i為例,我們來看看:
# 1 "main.c"
# 1 ""
# 1 ""
# 31 ""
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 32 "" 2
# 1 "main.c"
# 1 "/usr/include/stdio.h" 1 3 4
# 27 "/usr/include/stdio.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/bits/libc-header-start.h" 1 3 4
# 33 "/usr/include/x86_64-linux-gnu/bits/libc-header-start.h" 3 4
# 1 "/usr/include/features.h" 1 3 4
# 461 "/usr/include/features.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 1 3 4
# 452 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/bits/wordsize.h" 1 3 4
# 453 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 2 3 4
# 1 "/usr/include/x86_64-linux-gnu/bits/long-double.h" 1 3 4
# 454 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 2 3 4
# 462 "/usr/include/features.h" 2 3 4
# 485 "/usr/include/features.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/gnu/stubs.h" 1 3 4
# 10 "/usr/include/x86_64-linux-gnu/gnu/stubs.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/gnu/stubs-64.h" 1 3 4
# 11 "/usr/include/x86_64-linux-gnu/gnu/stubs.h" 2 3 4
# 486 "/usr/include/features.h" 2 3 4
# 34 "/usr/include/x86_64-linux-gnu/bits/libc-header-start.h" 2 3 4
# 28 "/usr/include/stdio.h" 2 3 4
/* 篇幅有限,中間省略了內容 */
extern char *ctermid (char *__s) __attribute__ ((__nothrow__ , __leaf__));
# 840 "/usr/include/stdio.h" 3 4
extern void flockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
extern int ftrylockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__)) ;
extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
# 858 "/usr/include/stdio.h" 3 4
extern int __uflow (FILE *);
extern int __overflow (FILE *, int);
# 873 "/usr/include/stdio.h" 3 4
# 3 "main.c" 2
# 1 "sub.h" 1
# 7 "sub.h"
extern int sub_func(int a);
# 5 "main.c" 2
# 13 "main.c"
int main(int argc, const char *argv[])
{
printf("Hello world !\n");
printf("TEST_NUM = %d\n", 1024);
printf("sub_func() = %d\n", sub_func(1));
return 0;
}
就算在不了解預編譯原理的情況下,我們也可以清晰地發現,一個20來行的.c源文件,被生成了一個700多行的.i預編譯處理文件。
為何會多了那么行呢?仔細對比你會發現,其實main.i就是把stdio.h和sub.h這兩個頭文件中除去#開頭的預處理之后的那些內容給搬過來了,這就是#include的作用。
值得提一點的就是,這個.i文件中還是有# xxx這種信息存在,其實這個信息是有作用的,下篇講解決編譯問題的實戰時,再重點介紹下它的作用。
這里,我再介紹一個gcc的參數,可以去掉這些信息,讓.i文件看起來清爽一些。
這個參數就是-P(注意:大寫字母P),這個參數在gcc--help里面沒有介紹,需要問一下男人man:
gcc/gcc_helloworld$ man gcc | grep -w '\-P'
file -M -MD -MF -MG -MM -MMD -MP -MQ -MT -no-integrated-cpp -P -pthread -remap -traditional
inhibited with the negated form -fno-working-directory. If the -P flag is present in the command line, this option
-P Inhibit generation of linemarkers in the output from the preprocessor. This might be useful when running the
troff: :17361: warning [p 110, 20.7i]: can't break line
加上-P參數之后,預編譯出來的main.i文件就清爽多了,一下子就減少到200多行了。
typedef long unsigned int size_t;
typedef __builtin_va_list __gnuc_va_list;
typedef unsigned char __u_char;
typedef unsigned short int __u_short;
typedef unsigned int __u_int;
typedef unsigned long int __u_long;
typedef signed char __int8_t;
typedef unsigned char __uint8_t;
typedef signed short int __int16_t;
typedef unsigned short int __uint16_t;
typedef signed int __int32_t;
typedef unsigned int __uint32_t;
typedef signed long int __int64_t;
typedef unsigned long int __uint64_t;
typedef __int8_t __int_least8_t;
typedef __uint8_t __uint_least8_t;
typedef __int16_t __int_least16_t;
typedef __uint16_t __uint_least16_t;
typedef __int32_t __int_least32_t;
typedef __uint32_t __uint_least32_t;
typedef __int64_t __int_least64_t;
typedef __uint64_t __uint_least64_t;
typedef long int __quad_t;
typedef long int __blksize_t;
typedef long int __blkcnt_t;
typedef long int __blkcnt64_t;
typedef __off64_t __loff_t;
typedef char *__caddr_t;
typedef long int __intptr_t;
typedef unsigned int __socklen_t;
typedef int __sig_atomic_t;
/* 篇幅有限,中間省略了內容 */
extern int pclose (FILE *__stream);
extern char *ctermid (char *__s) __attribute__ ((__nothrow__ , __leaf__));
extern void flockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
extern int ftrylockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__)) ;
extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
extern int __uflow (FILE *);
extern int __overflow (FILE *, int);
extern int sub_func(int a);
int main(int argc, const char *argv[])
{
printf("Hello world !\n");
printf("TEST_NUM = %d\n", 1024);
printf("sub_func() = %d\n", sub_func(1));
return 0;
}3.4 編譯生成.s文件
預編譯處理完了之后,進入到編譯階段,這里需要做到就是語法檢查和詞法分析,最終是會生成匯編代碼,我們一般以.s后綴表示此類文件。
以gcc編譯器為例,執行這一步編譯用到的命令行參數是-S(大寫字母S),具體如下:
gcc -S main.i -o main.s
gcc -S sub.i -o sub.s
像.i文件一樣,以main.s為例,我們也可以打開它,看下它里面長啥樣?
.file "main.c"
.text
.section .rodata
.LC0:
.string "Hello world !"
.LC1:
.string "TEST_NUM = %d\n"
.LC2:
.string "sub_func() = %d\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl %edi, -4(%rbp)
movq %rsi, -16(%rbp)
leaq .LC0(%rip), %rdi
call puts@PLT
movl $1024, %esi
leaq .LC1(%rip), %rdi
movl $0, %eax
call printf@PLT
movl $1, %edi
call sub_func@PLT
movl %eax, %esi
leaq .LC2(%rip), %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:有過匯編語言基礎的朋友,一定不會陌生:“咦,這不就是我們在匯編語言編程課堂上手把手碼出來的匯編代碼嗎?”
是的,這個就是純匯編代碼,它的可讀性比C語言確實差了很多,這也從側面證實了gcc這類C編譯器的厲害之處,它可以把高級語言編寫的C代碼編譯成面向機器的低級語言的匯編代碼。
3.5 匯編生成.o文件
生成匯編代碼之后,接下來的步驟就是使用匯編器生成二進制目標文件,這里使用gcc匯編的命令行如下:
-
gcc -c main.s -o main.o -
gcc -c sub.s -o sub.o
同樣的,你是否也好奇,.o這種目標文件究竟長啥樣?以main.o,我們來看一看?
額,忘了再特別交代下,這貨是二進制文件,它并不像.c、.i、.s文件那樣是可讀的,我一使用cat指令去讀,直接把我的控制臺輸出都給整亂碼了。(< - . - >)
看來,這玩意真不是我們普通肉眼所能看得懂的。
但是,Linux這么多強大的命令行,cat不能解析它,自然有人能敲開它的大門,這次我們用下面這兩個命令簡單看看這個目標文件。
使用file命令先查看下,文件的類型:
gcc/gcc_helloworld$ file main.c
main.c: C source, ASCII text
gcc/gcc_helloworld$
gcc/gcc_helloworld$ file main.i
main.i: C source, ASCII text
gcc/gcc_helloworld$
gcc/gcc_helloworld$ file main.s
main.s: assembler source, ASCII text
gcc/gcc_helloworld$
gcc/gcc_helloworld$ file main.o
main.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
我們可以清晰地對比到不同的文件類型,以及obj文件在Linux平臺上其實是一個ELF文件。
再使用nm命令查看下目標文件的符號列表:
gcc/gcc_helloworld$ nm -a main.o
0000000000000000 b .bss
0000000000000000 n .comment
0000000000000000 d .data
0000000000000000 r .eh_frame
U _GLOBAL_OFFSET_TABLE_
0000000000000000 T main
0000000000000000 a main.c
0000000000000000 r .note.gnu.property
0000000000000000 n .note.GNU-stack
U printf
U puts
0000000000000000 r .rodata
U sub_func
0000000000000000 t .text這里補充一下:
T或t : 表示該符號是在本C文件中實現的函數(符號);U: 表示該符號是外部符號,也就是在其他C文件中實現的;
nm更為詳細的含義列表,感興趣的可以自行man nm。
從nm的輸出,可以看出符號列表跟我們的C代碼實現是吻合的。
3.6 預編譯生成.elf文件
所有的目標文件生成后,編譯流程進入到鏈接階段。
這一步需要做的就是所有生成的二進制目標文件、啟動代碼、依賴的庫文件,一并鏈接成一個可執行文件,這個可執行文件可被加載或拷貝到存儲器中去執行。
在Linux下,可執行文件的本質是一個elf文件,全稱是:Executable and Linkable Format,中文含義就是:可執行、可鏈接的格式文件。
我們來看下,使用gcc命令行如何生成.elf文件的,如下:
gcc main.o sub.o -o test
由于gcc強大的默認選項,我們在輸入的時候,只需要輸入我們的目標文件列表,以及使用-o指定輸出的可執行文件名稱即可。
其實它真正在鏈接的時候是會加入很多其他文件(啟動文件、庫文件等等)和選項的,針對這個問題,下文我特意留了一個疑問。
總之,經過這一步之后,一個elf可執行文件就生成了,在Linux平臺上,通過./test就可以運行我們編寫的C代碼了。
gcc/gcc_helloworld$ ./test
Hello world !
TEST_NUM = 1024
sub_func() = 2執行的輸出,與我們之前設計的代碼邏輯也是保持一致的。
同樣的,我們也使用file和nm命令查看下這個test可執行文件:
gcc/gcc_helloworld$ file test
test: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=2b10713c6b777b4201108c59c41547baffeb9abc, for GNU/Linux 3.2.0, not stripped
gcc/gcc_helloworld$
gcc/gcc_helloworld$ nm -a test
0000000000000000 a
0000000000004010 b .bss
0000000000004010 B __bss_start
0000000000000000 n .comment
0000000000004010 b completed.8060
0000000000000000 a crtstuff.c
0000000000000000 a crtstuff.c
w __cxa_finalize@@GLIBC_2.2.5
0000000000004000 d .data
0000000000004000 D __data_start
0000000000004000 W data_start
00000000000010b0 t deregister_tm_clones
0000000000001120 t __do_global_dtors_aux
0000000000003db8 d __do_global_dtors_aux_fini_array_entry
0000000000004008 D __dso_handle
0000000000003dc0 d .dynamic
0000000000003dc0 d _DYNAMIC
0000000000000488 r .dynstr
00000000000003c8 r .dynsym
0000000000004010 D _edata
0000000000002080 r .eh_frame
0000000000002034 r .eh_frame_hdr
0000000000004018 B _end
0000000000001258 t .fini
0000000000001258 T _fini
0000000000003db8 d .fini_array
0000000000001160 t frame_dummy
0000000000003db0 d __frame_dummy_init_array_entry
00000000000021a4 r __FRAME_END__
0000000000003fb0 d _GLOBAL_OFFSET_TABLE_
w __gmon_start__
0000000000002034 r __GNU_EH_FRAME_HDR
00000000000003a0 r .gnu.hash
0000000000000512 r .gnu.version
0000000000000528 r .gnu.version_r
0000000000003fb0 d .got
0000000000001000 t .init
0000000000001000 t _init
0000000000003db0 d .init_array
0000000000003db8 d __init_array_end
0000000000003db0 d __init_array_start
0000000000000318 r .interp
0000000000002000 R _IO_stdin_used
w _ITM_deregisterTMCloneTable
w _ITM_registerTMCloneTable
0000000000001250 T __libc_csu_fini
00000000000011e0 T __libc_csu_init
U __libc_start_main@@GLIBC_2.2.5
0000000000001169 T main
0000000000000000 a main.c
000000000000037c r .note.ABI-tag
0000000000000358 r .note.gnu.build-id
0000000000000338 r .note.gnu.property
0000000000001020 t .plt
0000000000001050 t .plt.got
0000000000001060 t .plt.sec
U printf@@GLIBC_2.2.5
U puts@@GLIBC_2.2.5
00000000000010e0 t register_tm_clones
0000000000000548 r .rela.dyn
0000000000000608 r .rela.plt
0000000000002000 r .rodata
0000000000001080 T _start
0000000000000000 a sub.c
00000000000011c2 T sub_func
0000000000001080 t .text
0000000000004010 D __TMC_END__
對比之前的main.o,它的文件類型描述中多了一些信息,查看的符號列表中也多了很多沒見過的符號,這些符號是因為依賴的系統庫和啟動文件而導進來的。
3.7 轉換生成.bin文件
如上面章節提及的那樣,資源緊張的嵌入式設備,如果跑到不是嵌入式Linux系統,那么是不可能直接跑.elf這種可執行文件的。
大部分內存只有百來KB的嵌入式設備,是無法支持可執行文件的解析的,所以我們就需要在編譯生成elf文件之后,將elf文件轉換成bin文件,再把bin文件燒錄到Flash中運行代碼。
這一步,在Linux平臺,我們使用的是objcopy命令,使用如下:
-
objcopy -O binary test test.bin
這里-O(大寫字母O)是用于指定輸出二進制內容,它還可以支持ihex等參數,具體可以man objcopy。
這個test.bin的文件類型以及顯示的內容如下所示,毫無疑問,它也是二進制的不可讀。
3.8 all-in-one
有了上面的各個步驟的基礎,從預編譯、編譯、匯編,再到鏈接,每次都需要給gcc輸入不同的參數,有點麻煩呀?
那么有沒有參數可以輸入一次就可以獲取到這些步驟的所有輸出文件啊?
巧了,gcc還真有!這個參數就是-save-temps=obj,我們來實踐下:
gcc/gcc_helloworld$ ./build.sh clean
Clean build done !
gcc/gcc_helloworld$
gcc/gcc_helloworld$ ls
build.sh main.c README.md sub.c sub.h
gcc/gcc_helloworld$
gcc/gcc_helloworld$ ./build.sh allinone
gcc -c main.c -o main.o -save-temps=obj
gcc -c sub.c -o sub.o -save-temps=obj
gcc main.o sub.o -o test
gcc/gcc_helloworld$
gcc/gcc_helloworld$ ls
build.sh main.c main.i main.o main.s README.md sub.c sub.h sub.i sub.o sub.s test就這樣,.i文件、.s文件、以及.o文件都同時輸出來了。
如果工程中,只有一個main.c的源文件的話,還可以這樣就一步搞定。
gcc main.c -o test -save-temps=obj這些.i文件、.s文件、以及.o文件,我們稱之為中間臨時文件,下篇介紹如何解決一些編譯相關的問題,還得好好利用這些中間臨時文件呢。
4 經驗總結
- C代碼編譯要經過預編譯、編譯、匯編、鏈接這幾步,每一步做的事情是不一樣的;
- 要深入了解C代碼的編譯流程,建議摒棄Windows下的IDE編譯器,那玩意除了提高你的編碼速度,對你理解編譯流程和編譯原理,幫助并不大;
- gcc是一個開源的C編譯器,它博大精深,支持一大堆的命令行參數,了解一些基礎、常用的參數,對你理解問題幫助很大;
- 資源受限的嵌入式設備往往跑的是RTOS,這樣的執行環境下,往往只能燒錄bin文件到Flash中,而不支持像高級操作系統那樣,直接加載可執行文件到內存中運行。
5 留個疑問
gcc怎么這么牛逼?
好像啥事都能干?
從命令行上看,gcc既能預處理,也能編譯C代碼,又可以執行匯編ASM代碼,還能鏈接OBJ目標文件生成可執行文件,這里面的操作真的只是gcc在干活嗎?
感興趣的朋友,可以關注下這個疑問,后面有時間把gcc相關的內幕補上。
6 更多分享
本項目的所有測試代碼和編譯腳本,均可以在我的github倉庫01workstation中找到。
歡迎關注我的github倉庫01workstation,日常分享一些開發筆記和項目實戰,歡迎指正問題。
同時也非常歡迎關注我的CSDN主頁和專欄:
【CSDN主頁:架構師李肯】
【RT-Thread主頁:架構師李肯】
【C/C++語言編程專欄】
【GCC專欄】
【信息安全專欄】
【RT-Thread開發筆記】
【freeRTOS開發筆記】
有問題的話,可以跟我討論,知無不答,謝謝大家。
審核編輯:湯梓紅
-
GCC
+關注
關注
0文章
110瀏覽量
25311 -
C代碼
+關注
關注
1文章
90瀏覽量
14720 -
C文件
+關注
關注
0文章
12瀏覽量
3058
發布評論請先 登錄
Linux 下GCC的編譯
嵌入式學習-常用編輯器之GCC編譯器
gcc編譯通過但是arm-linux-gcc不能編譯,以及如何下載文件到arm
請問運行在RK3588板上編譯的可執行文件出現的問題該怎么解決?
用MDK生成bin格式的可執行文件
Linux下可執行文件格式
GCC編譯C語言程序的過程是怎么樣的
【gcc編譯優化系列】如何獲取gcc默認的鏈接腳本
單獨下載可執行文件到MM32F5微控制器
單獨下載可執行文件到MM32F5微控制器





 工商網監
工商網監

評論