 計算機視覺中不同的特征提取方法對比
計算機視覺中不同的特征提取方法對比
概述
特征提取是計算機視覺中的一個重要主題。不論是SLAM、SFM、三維重建等重要應用的底層都是建立在特征點跨圖像可靠地提取和匹配之上。特征提取是計算機視覺領域經久不衰的研究熱點,總的來說,快速、準確、魯棒的特征點提取是實現上層任務基本要求。
特征點是圖像中梯度變化較為劇烈的像素,比如:角點、邊緣等。FAST(Features from Accelerated Segment Test)是一種高速的角點檢測算法;而尺度不變特征變換SIFT(Scale-invariant feature transform)仍然可能是最著名的傳統局部特征點。也是迄今使用最為廣泛的一種特征。特征提取一般包含特征點檢測和描述子計算兩個過程。描述子是一種度量特征相似度的手段,用來確定不同圖像中對應空間同一物體,比如:BRIEF(Binary Robust IndependentElementary Features)描述子。可靠的特征提取應該包含以下特性:
(1)對圖像的旋轉和尺度變化具有不變性;(2)對三維視角變化和光照變化具有很強的適應性;(3)局部特征在遮擋和場景雜亂時仍保持不變性;(4)特征之間相互區分的能力強,有利于匹配;(5)數量較多,一般500×500的圖像能提取出約2000個特征點。
近幾年深度學習的興起使得不少學者試圖使用深度網絡提取圖像特征點,并且取得了階段性的結果。圖1給出了不同特征提取方法的特性。本文中的傳統算法以ORB特征為例,深度學習以SuperPoint為例來闡述他們的原理并對比性能。
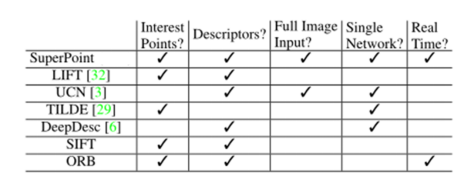
圖1 不同的特征提取方法對比
傳統算法—ORB特征
盡管SIFT是特征提取中最著名的方法,但是因為其計算量較大而無法在一些實時應用中使用。為了研究一種快速兼顧準確性的特征提取算法,Ethan Rublee等人在2011年提出了ORB特征:“ORB:An Efficient Alternative to SIFT or SURF”。ORB算法分為兩部分,分別是特征點提取和特征點描述。ORB特征是將FAST特征點的檢測方法與BRIEF特征描述子結合起來,并在它們原來的基礎上做了改進與優化。其速度是SIFT的100倍,是SURF的10倍。Fast特征提取從圖像中選取一點P,如圖2。按以下步驟判斷該點是不是特征點:以P為圓心畫一個半徑為3 pixel的圓;對圓周上的像素點進行灰度值比較,找出灰度值超過 l(P)+h 和低于 l(P)-h 的像素,其中l(P)是P點的灰度, h是給定的閾值;如果有連續n個像素滿足條件,則認為P為特征點。一般n設置為9。為了加快特征點的提取,首先檢測1、9、5、13位置上的灰度值,如果P是特征點,那么這四個位置上有3個或3個以上的像素滿足條件。如果不滿足,則直接排除此點。

圖2 FAST特征點判斷示意圖上述步驟檢測出的FAST角點數量很大且不確定,因此ORB對其進行改進。對于目標數量K為個關鍵點,對原始FAST角點分別計算Harris響應值,,然后根據響應值來對特征點進行排序,選取前K個具有最大響應的角點作為最終的角點集合。除此之外,FAST不具有尺度不變性和旋轉不變性。ORB算法構建了圖像金字塔,對圖像進行不同層次的降采樣,獲得不同分辨率的圖像,并在金字塔的每一層上檢測角點,從而獲得多尺度特征。最后,利用灰度質心法計算特征點的主方向。作者使用矩來計算特征點半徑范圍內的質心,特征點坐標到質心形成一個向量作為該特征點的方向。矩定義如下:
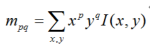
計算圖像的0和1階矩:
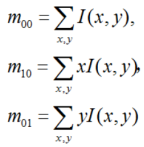
則特征點的鄰域質心為:
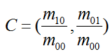
進一步得到特征點主方向:
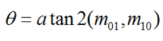
描述子計算BRIEF算法計算出來的是一個二進制串的特征描述符,具有高速、低存儲的特點。具體步驟是在一個特征點的鄰域內,選擇n對像素點pi、qi(i=1,2,…,n)。然后比較每個點對的灰度值的大小。如果I(pi)》 I(qi),則生成二進制串中的1,否則為0。所有的點對都進行比較,則生成長度為n的二進制串。一般n取128、256或512。另外,為了增加特征描述符的抗噪性,算法首先需要對圖像進行高斯平滑處理。在選取點對的時候,作者測試了5種模式來尋找一種特征點匹配的最優模式(pattern)。

圖3 測試分布方法最終的結論是,第二種模式(b)可以取得較好的匹配結果。
深度學習的方法—SuperPoint
深度學習解決特征點提取的思路是利用深度神經網絡提取特征點而不是手工設計特征,它的特征檢測性能與訓練樣本、網絡結構緊密相關。一般分為特征檢測模塊和描述子計算模塊。在這里以應用較為廣泛的SuperPoint為例介紹該方法的主要思路。該方法采用了自監督的全卷積網絡框架,訓練得到特征點(keypoint)和描述子(descriptors)。自監督指的是該網絡訓練使用的數據集也是通過深度學習的方法構造的。該網絡可分為三個部分(見圖1),(a)是BaseDetector(特征點檢測網絡),(b)是真值自標定模塊。(c)是SuperPoint網絡,輸出特征點和描述子。雖然是基于深度學習的框架,但是該方法在Titan X GPU上可以輸出70HZ的檢測結果,完全滿足實時性的要求。
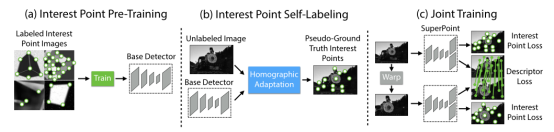
圖4 SuperPoint 網絡結構示意圖下面分別介紹一下三個部分:BaseDetector特征點檢測:首先創建一個大規模的合成數據集:由渲染的三角形、四邊形、線、立方體、棋盤和星星組成的合成數據,每個都有真實的角點位置。渲染合成圖像后,將單應變換應用于每個圖像以增加訓練數據集。單應變換對應著變換后角點真實位置。為了增強其泛化能力,作者還在圖片中人為添加了一些噪聲和不具有特征點的形狀,比如橢圓等。該數據集用于訓練 MagicPoint 卷積神經網絡,即BaseDetector。注意這里的檢測出的特征點不是SuperPoint,還需要經過Homographic Adaptation操作。
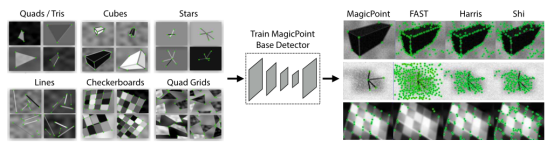
圖5 預訓練示意圖特征檢測性能表現如下表:
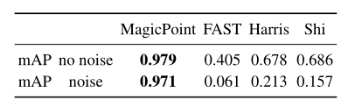
圖 6 MagicPoint 模型在檢測簡單幾何形狀的角點方面優于經典檢測器真值自標定:Homographic Adaptation 旨在實現興趣點檢測器的自我監督訓練。它多次將輸入圖像進行單應變換,以幫助興趣點檢測器從許多不同的視點和尺度看到場景。以提高檢測器的性能并生成偽真實特征點。
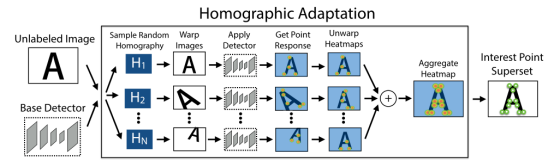
圖7 Homographic Adaptation操作Homographic Adaptation可以提高卷積神經網絡訓練的特征點檢測器的幾何一致性。該過程可以反復重復,以不斷自我監督和改進特征點檢測器。在我們所有的實驗中,我們將Homographic Adaptation 與 MagicPoint 檢測器結合使用后的模型稱為 SuperPoint。

圖8 Iterative Homographic AdaptationSuperPoint網絡:SuperPoint 是全卷積神經網絡架構,它在全尺寸圖像上運行,并在單次前向傳遞中產生帶有固定長度描述符的特征點檢測(見圖 9)。該模型有一個共享的編碼器來處理和減少輸入圖像的維數。在編碼器之后,該架構分為兩個解碼器“頭”,它們學習特定任務的權重——一個用于特征檢測,另一個用于描述子計算。大多數網絡參數在兩個任務之間共享,這與傳統系統不同,傳統系統首先檢測興趣點,然后計算描述符,并且缺乏在兩個任務之間共享計算和表示的能力。
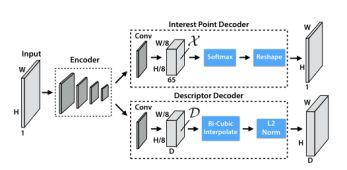
圖 9 SuperPoint DecodersSuperPoint 架構使用類似VGG編碼器來降低圖像的維度。編碼器由卷積層、通過池化的空間下采樣和非線性激活函數組成。解碼器對圖片的每個像素都計算一個概率,這個概率表示的就是其為特征點的可能性大小。描述子輸出網絡也是一個解碼器。先學習半稠密的描述子(不使用稠密的方式是為了減少計算量和內存),然后進行雙三次插值算法(bicubic interpolation)得到完整描述子,最后再使用L2標準化(L2-normalizes)得到單位長度的描述。最終損失是兩個中間損失的總和:一個用于興趣點檢測器 Lp,另一個用于描述符 Ld。我們使用成對的合成圖像,它們具有真實特征點位置和來自與兩幅圖像相關的隨機生成的單應性 H 的地面實況對應關系。同時優化兩個損失,如圖 4c 所示。使用λ來平衡最終的損失:
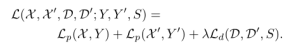
實驗效果對比:
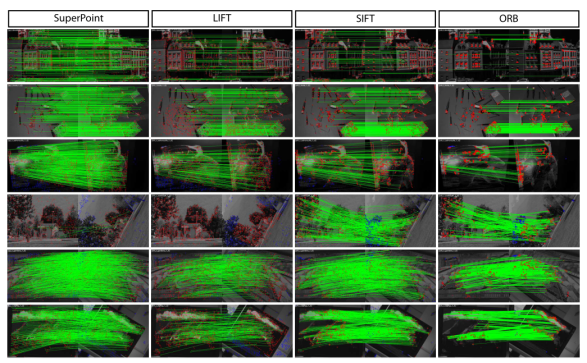
圖10 不同的特征檢測方法定性比較
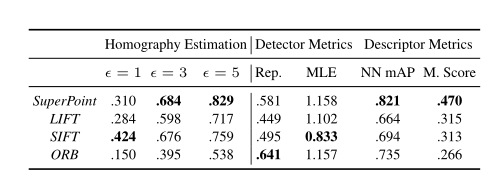
圖 11 檢測器和描述符性能的相關指標
結論
在特征檢測上,傳統方法通過大量經驗設計出了特征檢測方法和描述子。盡管這些特征在光照變化劇烈,旋轉幅度大等情況下還存在魯棒性問題,但仍然是目前應用最多、最成熟的方法,比如ORB-SLAM使用的ORB特征、VINS-Mono使用的FAST特征等都是傳統的特征點。深度學習的方法在特征檢測上表現了優異的性能,但是:(1)存在模型不可解釋性的問題;(2)在檢測和匹配精度上仍然沒有超過最經典的SIFT算法。(3)大部分深度學習的方案在CPU上運實時性差,需要GPU的加速。(4)訓練需要大量不同場景的圖像數據,訓練困難。本文最后的Homograpyhy Estimation指標,SuperPiont超過了傳統算法,但是評估的是單應變換精度。單應變換在并不能涵蓋所有的圖像變換。比如具有一般性質的基礎矩陣或者本質矩陣的變換,SurperPoint表現可能不如傳統方法。
原文標題:特征提取:傳統算法 vs 深度學習
文章出處:【微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
-
計算機視覺
+關注
關注
8文章
1698瀏覽量
45976 -
計算模塊
+關注
關注
0文章
16瀏覽量
6195 -
深度學習
+關注
關注
73文章
5500瀏覽量
121111
原文標題:特征提取:傳統算法 vs 深度學習
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機視覺有哪些優缺點
圖像識別算法的核心技術是什么
計算機視覺的工作原理和應用
機器人視覺與計算機視覺的區別與聯系
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
計算機視覺怎么給圖像分類
深度學習在計算機視覺領域的應用
機器視覺與計算機視覺的區別
計算機視覺的主要研究方向
計算機視覺的十大算法






 工商網監
工商網監
評論