


除了Zen CPU架構和RDNA客戶端GPU架構的更新,AMD最近還更新了他們的CDNA服務器GPU架構和相關的Instinct產品路線圖。在接下來的兩年里,CPU和客戶端GPU的發展可以說是一帆風順,而AMD則打算大幅調整其服務器端GPU產品。
讓我們先從AMD的服務器GPU架構路線圖開始。繼AMD公司目前的CDNA 2架構之后,MI200系列Instinct加速器將采用CDNA 3架構。與AMD的其他路線圖不同的是,該公司此次并沒有提供兩年的路線圖。同時,服務器GPU路線圖只推出到2023年,AMD的下一個服務器GPU架構將于明年推出。

我們對CDNA 3的第一次了解發現了很多細節。AMD透漏了從架構到有關產品的一些基本信息——由CPU和GPU小芯片組成的數據中心APU。
綜上所述,基于CDNA 3架構的GPU將建立在5納米工藝上。就像之前的基于CDNA 2的MI200加速器一樣,它將依賴小芯片將內存、緩存和處理器內核全部組合在一個封裝中。值得注意的是,AMD稱之為“3D芯片”設計,這意味著不僅小芯片堆疊在基板上,而且其他芯片也將堆疊在小芯片之上,就像AMD為Zen 3 CPU設計的V-Cache一樣。
這種比較在這里特別適用,因為AMD將把它的無限緩存技術引入到CDNA 3架構中。而且,就像上面的V-Cache的例子一樣,從AMD的設計來看,他們會將緩存和邏輯堆疊成獨立的芯片,而不是像他們的客戶端GPU那樣將其集成到一個整體芯片中。由于這種堆疊的特性,CDNA 3的無限緩存芯片將位于處理器芯片之下,AMD似乎將非常耗電的邏輯芯片放在堆棧的頂部,以便有效冷卻。
CDNA 3也將采用AMD的第四代無限架構。對于GPU來說,IA4與AMD的芯片創新是攜手并進的。具體來說,它將使2.5D/3D堆疊芯片與IA一起使用,使一個包內的所有芯片共享一個統一的、完全一致的存儲子系統。這相對IA3和目前的MI200加速器是一個巨大的飛躍,雖然提供了內存一致性,但沒有統一的內存地址空間。因此,盡管MI200加速器本質上在一個封裝中充當兩個GPU,但IA4將讓CDNA 3/MI300加速器作為單個芯片運行。
AMD的圖表還顯示,HBM內存再次在這里使用。AMD沒有具體說明HBM的版本,但考慮到2023年的時間框架,很有可能會是HBM3。
在架構上,AMD也將采取一些措施來改善其高性能加速器的AI性能。據該公司稱,他們正在增加對新的混合精確數學格式的支持。雖然還沒有明確說明,但AMD在AI工作負載中的每瓦性能提升超過5倍,這強烈暗示AMD正在為CNDA 3顯著改造和擴展其矩陣內核,因為5倍的性能遠遠超過了單是芯片改進所能提供的性能。
MI300: AMD的第一款分塊數據中心APU
但是AMD不會止步于僅僅建造一個更大的GPU,他們也不會僅僅為了讓GPU在共享內存池中工作而統一多芯片架構的內存池。相反,AMD的野心遠不止于此。有了高性能的CPU和GPU核心,AMD在集成方面邁出了下一步,正在構建一個分體式的數據中心APU——一種將CPU和GPU核心結合到單個封裝中的芯片。
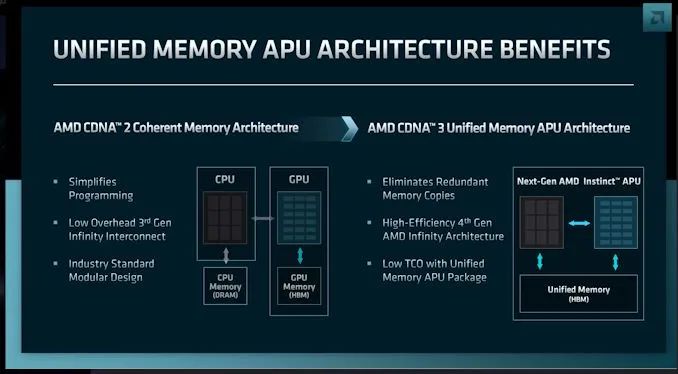
數據中心APU目前的代號是MI300,AMD已經為之努力了一段時間。MI200和Infinity Architecture 3允許AMD CPU和GPU在一個連貫的內存架構下一起工作,下一步是在封裝和內存架構方面將CPU和GPU進一步結合在一起。
對于內存問題來說,統一的架構給MI300帶來了幾個主要的好處。從性能的角度來看,這通過消除冗余的內存拷貝來改善問題;處理器不再需要將數據復制到自己專用的內存池來訪問/修改數據。統一的內存池還意味著不需要第二個內存芯片池——在這種情況下,通常是連接到CPU的DRAM。

MI300將把CDNA 3GPU小芯片和Zen 4 CPU小芯片組合到一個處理器封裝中。反過來,這兩個處理器池將共享封裝HBM內存。而且,大概還有無限緩存。
如前所述,AMD將大量利用小芯片來實現這一目標。CPU內核、GPU內核、Infinity Cache和HBM都是不同的小芯片,其中一些將相互堆疊。因此,這將是不同于AMD之前制造的任何其他芯片的芯片,這將是AMD將芯片集成到他們的產品設計中所付出的最大努力。
與此同時,AMD非常明確地表示,他們正在內存帶寬和應用延遲方面爭奪市場領導地位。如果AMD能做到這一點,對公司來說將是一個重大的成就。話雖如此,他們并不是第一家將HBM與CPU內核配對的公司,英特爾的Sapphire Rapids Xeon同樣使用了這種方法,所以我們將拭目以待MI300如何在這方面獲得優勢。
至于更具體的AI性能問題,AMD聲稱APU將提供優于MI250X加速器8倍的訓練性能。這進一步證明,與MI200系列相比,AMD將對其GPU矩陣內核進行一些重大改進。
總體而言,AMD的服務器GPU發展軌跡與英特爾和英偉達在過去幾個月里公布的非常相似。這三家公司都在致力于CPU+GPU產品的結合;NVIDIA推出了Grace Hopper (Grace + H100),Intel推出了Falcon Shores xpu (CPU + GPU混合搭配),現在MI300在單個封裝上同時使用了CPU和GPU芯片。在這三種情況下,這些技術的目標都是將最好的CPU和最好的GPU結合起來,以應對不受兩者約束的工作負載。就AMD而言,該公司相信他們擁有最好的CPU和最好的GPU。
在接下來的幾個月里,我們有望看到更多關于CDNA 3和MI300的信息。
審核編輯 :李倩
-
amd
+關注
關注
25文章
5570瀏覽量
135987 -
gpu
+關注
關注
28文章
4916瀏覽量
130729 -
服務器
+關注
關注
13文章
9717瀏覽量
87371
原文標題:GPU+CPU=AMD MI300數據中心APU!
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
小型數據中心晶振選型關鍵參數全解

適用于數據中心和AI時代的800G網絡
優化800G數據中心:高速線纜、有源光纜和光纖跳線解決方案
【「芯片通識課:一本書讀懂芯片技術」閱讀體驗】初識芯片樣貌

英特爾數據中心CPU銷量降至14年最低

AMD數據中心業務收入超越Intel


新加坡電信與日立深化合作,共推數據中心與GPU云技術







 工商網監
工商網監

評論