 馬爾可夫與語言模型
馬爾可夫與語言模型
從俄國數學家 Andrey Markov (安德烈·馬爾可夫)提出著名的「馬爾科夫鏈」以來,語言建模的研究已經有了 100 多年的歷史。近年來,自然語言處理(NLP)發生了革命性的變化。2001年,Yoshua Bengio 用神經網絡進行參數化的神經語言模型,開啟了語言建模的新時代。其后,預訓練語言模型如 BERT 和 GPT 的出現再次將 NLP 提高到一個新的水平。
最近,字節跳動 AI Lab 的總監李航博士在《ACM通訊》(The Communications of ACM)上發表了一篇綜述文章,展示了他對于語言模型在過去、現在和未來的觀察。
在本文中,李航博士首先介紹了馬爾可夫和香農基于概率論研究的語言建模的基本概念。之后,他討論了喬姆斯基提出的基于形式語言理論的語言模型,描述了作為傳統語言模型的擴展的神經語言模型的定義。其后,他解釋了預訓練語言模型的基本思想,最后討論了神經語言建模方法的優勢和局限性,并對未來的趨勢進行預測。
李航認為,在未來幾年,神經語言模型尤其是預訓練的語言模型仍將是 NLP 最有力的工具。他指出,預訓練語言模型具有兩大優勢,其一,它們可以顯著提高許多 NLP 任務的準確性;例如,可以利用 BERT 模型來實現比人類更好的語言理解性能,在語言生成方面還可以利用 GPT-3 模型生成類似人類寫作的文本。其二,它們是通用的語言處理工具。在傳統的 NLP 中進行基于機器學習的任務,必須標記大量數據來訓練一個模型,相比之下,目前只需要標記少量數據來微調預訓練的語言模型,因為它已經獲得了語言處理所需的大量知識。
在文中,李航還提出一個重要的問題,即如何設計神經網絡來使模型在表征能力和計算效率方面更接近于人類語言處理過程。他建議,我們應當從人類大腦中尋找靈感。
李航,字節跳動人工智能實驗室總監、ACL Fellow、IEEE Fellow、ACM 杰出科學家。他碩士畢業于日本京都大學電氣工程系,后在東京大學取得計算機科學博士學位。畢業之后,他先后就職于 NEC 公司中央研究所(任研究員)、微軟亞洲研究院(任高級研究員與主任研究員)、華為技術有限公司諾亞方舟實驗室(任首席科學家)。李航博士的主要研究方向包括自然語言處理、信息檢索、機器學習、數據挖掘等。
以下是 AI科技評論在不改變原意的基礎上對原文所作編譯。
自然語言處理是計算機科學、人工智能和語言學相交叉的一個子領域,在機器翻譯、閱讀理解、對話系統、文檔摘要、文本生成等方面都有應用。近年來,深度學習已成為 NLP 的基礎技術。
使用數學方法對人類語言建模有兩種主要方法:一種是基于概率理論,另一種是基于形式語言理論。這兩種方法也可以結合使用。從基本框架的角度來看,語言模型屬于第一類。
形式上,語言模型是定義在單詞序列(句子或段落)上的概率分布。它是基于概率論、統計學、信息論和機器學習的自然語言文本建模的重要機制。深度學習的神經語言模型,特別是最近開發的預訓練語言模型,已成為自然語言處理的基本技術。
1馬爾可夫與語言模型
Andrey Markov (安德烈·馬爾可夫)可能是第一位研究語言模型的科學家,盡管當時「語言模型」一詞尚不存在。
假設 w((1)), w((2)), ···, w((N)) 是一個單詞序列。我們可以計算這個單詞序列的概率如下:
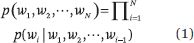
設 p(w((1))|w((0))) = p(w((1))) 。不同類型的語言模型使用不同的方法來計算條件概率 p(w((i))|w((1)), w((2)), ···, w((i-1))) 。學習和使用語言模型的過程稱為語言建模。n-gram 模型是一種基本模型,它假設每個位置出現什么單詞僅取決于前 n-1個 位置上是什么單詞。也就是說,該模型是一個 n–1 階馬爾可夫鏈。
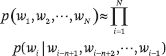
馬爾可夫在 1906 年研究出了馬爾可夫鏈。他一開始考慮的模型非常簡單,在這個模型中,只有兩個狀態和這些狀態之間的轉換概率。他證明,如果根據轉換概率在兩個狀態之間跳躍,那么訪問兩個狀態的頻率將收斂到期望值,這就是馬爾可夫鏈的遍歷定理。在接下來的幾年里,他擴展了該模型,并證明了上述結論在更通用的情況下仍然成立。
這里舉一個具體的例子。1913年,馬爾可夫將他提出的模型應用于亞歷山大·普希金的詩體小說《尤金·奧涅金》中。他去掉文本中的空格和標點符號,將小說的前 20000 個俄語字母分為元音和輔音,從而得到小說中的元音和輔音序列。然后,他用紙和筆計算出元音和輔音之間的轉換概率。最后,這些數據被用來驗證最簡單的馬爾可夫鏈的特征。
非常有趣的是,馬爾可夫鏈最開始被應用的領域是語言。馬爾可夫研究的這個例子就是一個最簡單的語言模型。
2香農與語言模型
1948年, Claude Shannon (克勞德·香農)發表了一篇開創性的論文 “The Mathematical Theory of Communication”(《通信的數學理論》),開辟了信息論這一研究領域。在這篇論文中,香農引入了熵和交叉熵的概念,并研究了 n-gram 模型的性質。(根據馮·諾依曼的建議,香農借用了統計力學中的“熵”一詞。)
熵表示一個概率分布的不確定性,交叉熵則表示一個概率分布相對于另一個概率分布的不確定性。熵是交叉熵的下限。
假設語言(即一個單詞序列)是由隨機過程生成的數據。n-gram 的概率分布熵定義如下:
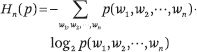
其中 p(w((1)), w((2)), ···, w((n))) 表示 n-gram w((1)), w((2)), ···, w((n)) 的概率。n-gram 概率分布相對于數據“真實”概率分布的交叉熵定義如下:
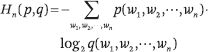
其中, q(w((1)), w((2)), ···, w((n))) 表示 n-gram w((1)), w((2)), ···, w((n)) 的概率,p(w((1)), w((2)), ···, w((n))) 表示 n-gram w((1)), w((2)), ···, w((n)) 的真實概率。以下關系成立:
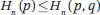
Shannon-McMillan-Breiman 定理指出,當語言的隨機過程滿足平穩性和遍歷性條件時,以下關系成立:
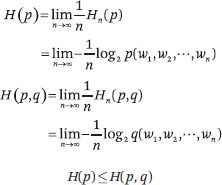
換句話說,當單詞序列長度趨于無窮大時,就可以定義語言的熵。熵取一個常數值,可以從語言數據中進行估計。
如果一種語言模型比另一種語言模型更能準確地預測單詞序列,那么它應該具有較低的交叉熵。因此,香農的工作為語言建模提供了一個評估工具。
需要注意的是,語言模型不僅可以對自然語言進行建模,還可以對形式語言和半形式語言進行建模。
3喬姆斯基與語言模型
與此同時, 美國語言學家 Noam Chomsky(諾姆·喬姆斯基)在 1956 年提出了喬姆斯基語法結構,用于表示語言的句法。他指出,有限狀態語法以及 n-gram 模型在描述自然語言方面具有局限性。
喬姆斯基的理論認為,一種語言由一組有限或無限的句子組成,每個句子包含一系列長度有限的單詞。單詞來自有限的詞匯庫,語法作為一組用于生成句子的規則,可以生成語言中的所有句子。不同的語法可以產生不同復雜程度的語言,從而構成一個層次結構。
有限狀態語法或正則語法,是指能夠生成有限狀態機可以接受的句子的語法。而能夠生成非確定性下推自動機(non-deterministic pushdown automaton)可以接受的句子的語法則是上下文無關語法。有限狀態語法包含在上下文無關語法中。
有限馬爾可夫鏈(或 n-gram 模型)背后的「語法」就是有限狀態語法。有限狀態語法在生成英語句子方面確實有局限性。比方說,英語的表達式之間存在如(i)和(ii)中的語法關系。
(i) If S1, then S2.
(ii) Either S3, or S4.
(iii) Either if S5, then S6, or if S7, then S8
原則上,我們可以無限地將這些關系進行組合以產生正確的英語表達,比如(iii)。然而,有限狀態語法無法窮盡描述所有的組合,而且在理論上,有些英語句子是無法被涵蓋的。因此,喬姆斯基認為,用有限狀態語法包括 n-gram 模型來描述語言有很大的局限性。相反,他指出上下文無關語法可以更有效地建模語言。在他的影響下,接下來的幾十年里,上下文無關語法在自然語言處理中更為常用。在今天,喬姆斯基的理論對自然語言處理的影響不大,但它仍具有重要的科學價值。
4神經語言模型
2001年,Yoshua Bengio 和他的合著者提出了最早的神經語言模型之一,開創了語言建模的新時代。眾所周知,Bengio、Geoffrey Hinton 和 Yann LeCun 在概念和工程上的突破使深度神經網絡成為計算的關鍵部分,他們因此而獲得 2018 年圖靈獎。
n-gram 模型的學習能力有限。傳統方法是使用平滑方法從語料庫中估計模型中的條件概率 p(w((i))|w((i-n+1)), w((i-n+2)), ···, w((i-1))) 。然而,模型中的參數數量為指數級 O(V((n))),其中 V 表示詞匯量。當 n 增大時,由于訓練數據的稀疏性,就無法準確地學習模型的參數。
Bengio 等人提出的神經語言模型從兩個方面改進了 n-gram 模型。首先,被稱為詞嵌入的實值向量,可用于表示單詞或單詞組合。單詞嵌入的維度比單詞的獨熱向量(one-hot vector)的維度要低得多,獨熱向量通過詞匯大小的向量表示文本中的詞,其中只有對應于該詞的項是 1,而其他所有項都是 0。
詞嵌入作為一種「分布式表示」,可以比獨熱向量更有效地表示一個詞,它具有泛化能力、魯棒性和可擴展性。其次,語言模型是由神經網絡表示的,這大大減少了模型中的參數數量。條件概率由神經網絡確定:
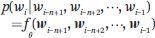
其中 (w((i-n+1)),w((i-n+2)), ···,w((i-1))) 表示單詞 w((i-n+1)), w((i-n+2)), ···, w((i-1)) ;f(·) 表示神經網絡;? 表示網絡參數。模型中的參數數量僅為 O(V) 階。下圖顯示了模型中各表征之間的關系。每個位置都有一個中間表征,它取決于前 n–1個 位置處的單詞嵌入(單詞),這個原則適用于所有位置。使用當前位置的中間表征可以為該位置生成一個單詞。
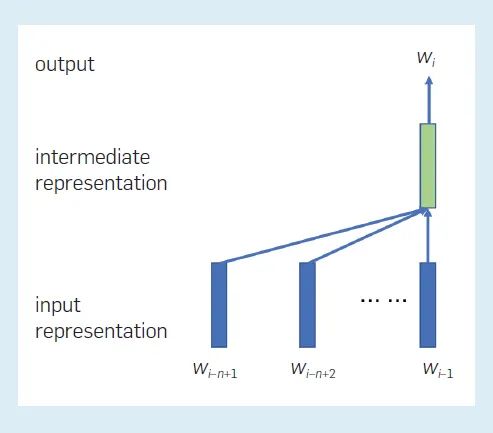
圖 1:在初始神經語言模型中各表征之間的關系
在 Bengio 等人的工作之后,大量的詞嵌入方法和神經語言建模方法被開發出來,從不同的角度未語言建模帶來了改進。
詞嵌入的代表性方法包括 Word2Vec。代表性的神經語言模型是循環神經網絡語言模型 (RNN) ,如長短期記憶語言模型 (LSTM) 。在一個 RNN 語言模型中,每個位置上單詞的條件概率由一個 RNN 決定:
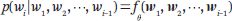
其中w((1)),w((2)), ···,w((i-1)) 表示詞的嵌入w((1)),w((2)), ···,w((i-1));f(·) 表示 RNN;? 表示網絡參數。RNN 語言模型不再使用馬爾可夫假設,每個位置上的單詞都取決于之前所有位置上的單詞。RNN 的一個重要概念是它的中間表征或狀態。詞之間的依賴關系以 RNN 模型中狀態之間的依賴關系為特征。模型的參數在不同的位置可以共享,但在不同的位置得到的表征是不同的。
下圖顯示了 RNN 語言模型中各表征之間的關系。每個位置的每一層都有一個中間表征,它表示到目前為止單詞序列的「狀態」。當前層在當前位置的中間表征,由同一層在前一位置的中間表征和下一層在當前位置的中間表征決定。當前位置的最終中間表征用于計算下一個單詞的概率。
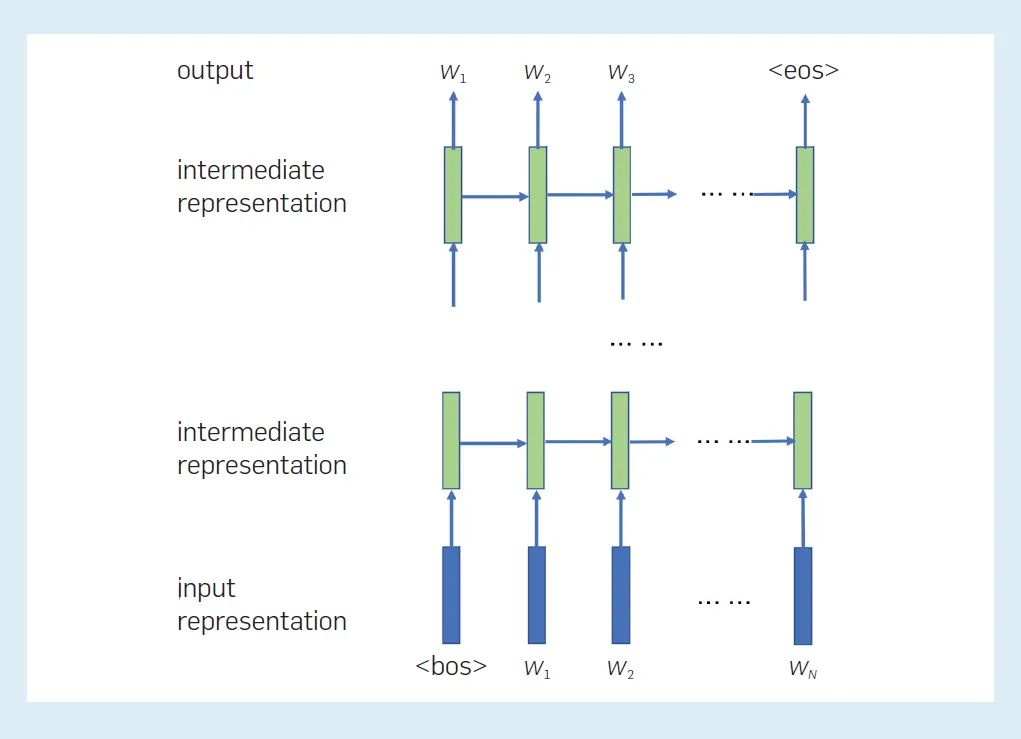
圖 2:RNN 語言模型中各表征之間的關系。這里標記了句首(bos)和句尾(eos)。
語言模型可用于計算語言(詞序列)的概率或生成語言。比如在生成語言方面,可以通過從語言模型中隨機抽樣來生成自然語言的句子或文章。眾所周知,從大量數據中學習的 LSTM 語言模型可以生成非常自然的句子。
對語言模型的一個擴展是條件語言模型,它計算一個詞序列在給定條件下的條件概率。如果條件是另一個詞序列,那么問題就變成了從一個詞序列到另一個詞序列的轉換——即所謂的序列到序列問題,涉及的任務如機器翻譯、文本摘要和生成對話。如果給定的條件是一張圖片,那么問題就變成了從圖片到單詞序列的轉換,比如圖像捕捉任務。
條件語言模型可以用在各種各樣的應用程序中。在機器翻譯中,在保持相同語義的條件下,系統將一種語言的句子轉換成另一種語言的句子。在對話生成中,系統對用戶的話語產生響應,兩條消息構成一輪對話。在文本摘要中,系統將長文本轉換為短文本,后者包含前者的要點。由模型的條件概率分布所表示的語義因應用程序而異,而且它們都是從應用程序中的數據中來學習的。
序列到序列模型的研究為新技術的發展做出了貢獻。一個具有代表性的例子是由 Vaswani 等人開發的 Transformer。Transformer 完全基于注意力機制,利用注意力在編碼器之間進行編碼和解碼,以及在編碼器和解碼器之間進行。目前,幾乎所有的機器翻譯系統都采用了 Transformer 模型,而且機器翻譯已經達到了可以滿足實際需要的水平。現在幾乎所有預訓練的語言模型都采用 Transformer 架構,因為它在語言表示方面具有卓越的能力。
5預訓練語言模型
預訓練語言模型的基本思想如下。首先,基于如 transformer 的編碼器或解碼器來實現語言模型。該模型的學習分兩個階段:一是預訓練階段,通過無監督學習(也稱為自監督學習)使用大量的語料庫來訓練模型的參數;二是微調階段,將預訓練的模型應用于一個特定的任務,并通過監督學習使用少量標記數據進一步調整模型的參數。下表中的鏈接提供了學習和使用預訓練語言模型的資源。

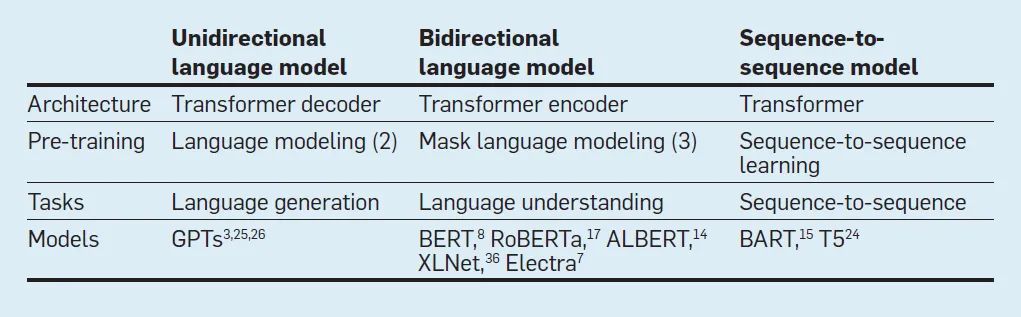
預訓練語言模型有三種: 單向、雙向和序列到序列。由于篇幅所限,這里只介紹前兩種類型。所有主要的預訓練語言模型都采用了 Transformer 架構。下表是對現有的預訓練語言模型的概括。
Transformer 有很強的語言表示能力。一個非常大的語料庫會包含豐富的語言表達(這樣的未標記數據很容易獲得),訓練大規模深度學習模型就會變得更加高效。因此,預訓練語言模型可以有效地表示語言中的詞匯、句法和語義特征。預訓練語言模型如 BERT 和 GPT(GPT-1、GPT-2 和 GPT-3),已成為當前 NLP 的核心技術。
預訓的語言模型的應用為 NLP 帶來了巨大的成功。「微調」的 BERT 在語言理解任務(如閱讀理解)的準確性方面優于人類。「微調」的 GPT-3 在文本生成任務中也達到了驚人的流利程度。要注意的是,這些結果僅表明機器在這些任務中具有更高的性能;我們不應簡單地將其理解為 BERT 和 GPT-3 能比人類更好地理解語言,因為這也取決于如何進行基準測試。從歷史上可以看到,對人工智能技術持有正確的理解和期望,對于機器的健康成長和發展至關重要。
Radford 等人和 Brown 等人開發的 GPT 具有以下架構。輸入是單詞的序列 w((1)), w((2)), ···, w((N))。首先,通過輸入層,創建一系列輸入表征,記為矩陣H(((0)))。在通過 L 個 transformer 解碼器層之后,創建一系列中間表征序列,記為矩陣H(((L)))。
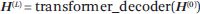
最后,基于該位置的最終中間表征來計算每個位置的單詞概率分布。GPT 的預訓練與傳統的語言建模相同。目標是預測單詞序列的可能性。對于給定的詞序列w= w((1)), w((2)), ···, w((N)),我們計算并最小化交叉熵或負對數似然來估計參數 :
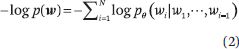
其中 ? 指 GPTs 模型的參數。
下圖顯示了 GPTs 模型中各表征之間的關系。每個位置上的輸入表征由詞嵌入和“位置嵌入”組成。每個位置上的每一層的中間表征是從下一層在先前位置上的中間表征創建的。單詞的預測或生成在每個位置從左到右重復執行。換句話說,GPT 是一種單向語言模型,其中單詞序列是從單一方向建模的。(注意,RNN 語言模型也是單向語言模型。)因此,GPT 更適合解決自動生成句子的語言生成問題。
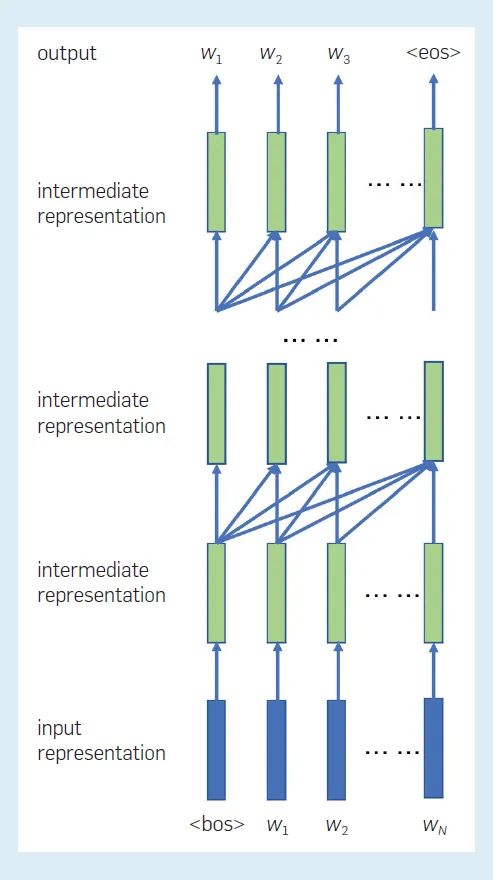
圖 3:GPTs 語言模型中各表征之間的關系。這里標記了句首(bos)和句尾(eos)。
由 Devlin 等人開發的 BERT 具有以下架構。輸入是一個單詞序列,它可以是來自單個文檔的連續句子,也可以是來自兩個文檔的連續句子的串聯。這使得該模型適用于以一個文本為輸入的任務(例如文本分類),以及以兩個文本為輸入的任務(例如回答問題)。首先,通過輸入層,創建一系列輸入表征,記為矩陣 H(((0)))。通過 L 個 transformer 編碼器層之后,創建一個中間表征序列,記為H(((L)))。
最后,可以根據該位置上的最終中間表征,來計算每個位置上單詞的概率分布。BERT 的預訓練被執行為所謂的掩碼語言建模。假設詞序列為w= w((1)), w((2)), ···, w((N))。序列中的幾個單詞被隨機掩蔽——即更改為特殊符號 [mask] —— 從而產生一個新的單詞序列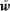 其中掩碼詞的集合記為
其中掩碼詞的集合記為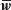 學習的目標是通過計算和最小化下面的負對數似然來估計參數,以恢復被掩蔽的單詞:
學習的目標是通過計算和最小化下面的負對數似然來估計參數,以恢復被掩蔽的單詞:
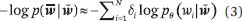
其中 ? 表示 BERT 模型的參數,δ((i)) 取值為 1 或 0,表示位置 i 處的單詞是否被掩蔽。注意,掩碼語言建模已經是一種不同于傳統語言建模的技術。
圖4展示了 BERT 模型中表示之間的關系。每個位置的輸入表示由詞嵌入、「位置嵌入」等組成,每層在每個位置的中間表征,是由下面一層在所有位置的中間表征創建的,詞的預測或生成是在每個掩碼位置獨立進行的--參見(圖3)。也就是說,BERT是一個雙向語言模型,其中單詞序列是從兩個方向建模的。因此,BERT可以自然地應用于語言理解問題,其輸入是整個單詞序列,其輸出通常是一個標簽或一個標簽序列。
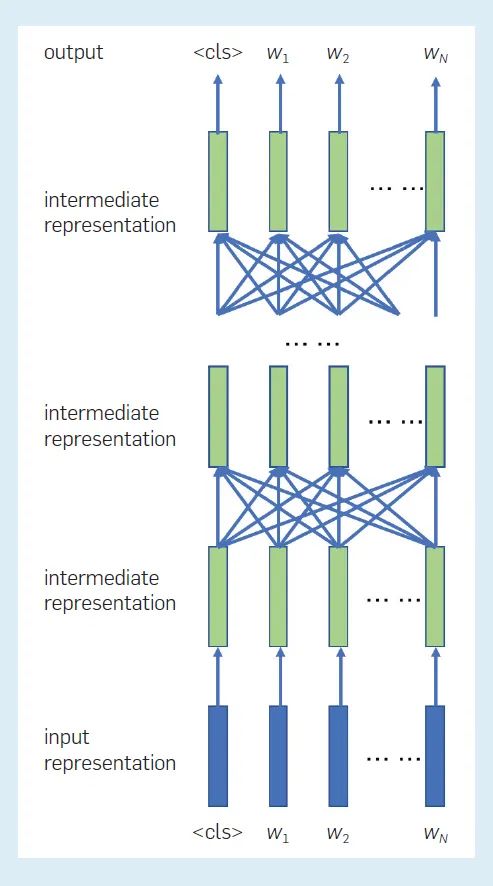
圖 4:BERT 模型中各表征之間的關系。這里表示代表整個輸入序列的特殊符號。
對預訓練語言模型的一個直觀解釋是,機器在預訓練中根據大型語料庫進行了大量的單詞接龍(GPT)或單詞完形填空練習(BERT),捕捉到由單詞組成句子的各種模式,由句子組成文章,并在模型中表達和記憶了這些模式。
一個文本不是由單詞和句子隨機產生的,而是基于詞法、句法和語義規則來構建。GPT 和 BERT 可以分別使用轉化器的解碼器和編碼器,來實現語言的組合性(組合性是語言最基本的特征,它也是由Chomsky 層次結構中的語法所建模的)。換句話說,GPT 和 BERT 在預訓練中已經獲得了相當數量的詞匯、句法和語義知識。因此,當適應微調中的特定任務時,只需少量標記數據即可對模型進行細化,從而實現高性能。例如,人們發現 BERT 的不同層有不同的特點,底層主要代表詞法知識,中間層主要代表句法知識,而頂層主要代表語義知識。
預訓練的語言模型(沒有微調),例如 BERT 和 GPT-3,就包含大量的事實知識,它們可以用來回答諸如「但丁在哪里出生?」之類的問題,只要它們在訓練數據中獲得了知識,就可以進行簡單的推理,例如「48加76是多少?」
但是語言模型本身沒有推理機制,其「推理」能力是基于聯想、而不是真正的邏輯推理。因此,它們在需要復雜推理的問題上表現不佳,包括論證推理、數值和時間推理和話語推理,將推理能力和語言能力集成到 NLP 系統中,將是未來的一個重要課題。
6未來展望
當代科學(腦科學和認知科學)對人類語言處理機制(語言理解和語言生成)的理解有限。在可預見的未來,很難看到有重大突破發生,永遠不會突破的可能性是存在的。另一方面,我們希望不斷推動人工智能技術的發展,開發出對人類有用的語言處理機器,神經語言建模似乎是迄今為止最成功的方法。
目前看來,神經語言建模是迄今為止最成功的方法,它的基本特征沒有改變--那就是,它依賴于在包含所有單詞序列的離散空間中定義的概率分布。學習過程是為了找到最佳模型,以便交叉熵在預測語言數據的準確性方面是最高的(圖5)。
神經語言建模通過神經網絡構建模型,其優點在于,它可以利用復雜的模型、大數據和強大的計算來非常準確地模擬人類語言行為。從 Bengio 等人提出的原始模型、到 RNN 語言模型以及 GPT 和 BERT 等預訓練語言模型,神經網絡的架構變得越來越復雜(如圖1-4),而預測語言的能力也越來越高(交叉熵越來越小)。然而,這并不一定意味著這些模型具有和人類一樣的語言能力,而且其局限性也是不言而喻的。
圖5:機器通過調整其「大腦」內的神經網絡參數來模仿人類語言行為,最終它可以像人類一樣處理語言
那么,有其他可能的發展路徑嗎?目前還不清楚。但可以預見的是,神經語言建模的方法仍有很多改進機會。
目前,神經語言模型與人腦在表示能力和計算效率(功耗方面)方面還有很大差距,成人大腦的工作功率僅為 12 W,而訓練 GPT-3 模型消耗了數千 Petaflop/s-day,這形成了鮮明的對比。能否開發出更好的語言模型、使其更接近人類語言處理,是未來研究的重要方向。我們可以從有限的腦科學發現中學習,技術提升仍然有很多機會。
人類語言處理被認為主要在大腦皮層的兩個大腦區域進行:布羅卡區和韋尼克區(圖6)。前者負責語法,后者負責詞匯。腦損傷導致失語的典型案例有兩種,布羅卡區受傷的患者只能說出零星的單詞而無法說出句子,而韋尼克區受傷的患者可以構建語法正確的句子,但單詞往往缺乏意義。
一個自然的假設是,人類語言處理是在兩個大腦區域中并行進行的,是否需要采用更人性化的處理機制是一個值得研究的課題。正如Chomsky所指出的,語言模型沒有明確地使用語法,也不能無限地組合語言,這是人類語言的一個重要屬性,將語法更直接地結合到語言模型中的能力、將是一個需要研究的問題。
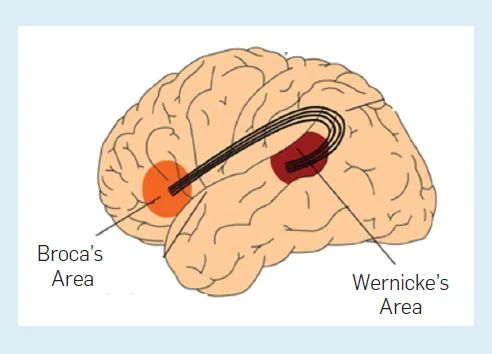
圖6:人腦中負責語言處理的區域
腦科學家認為,人類語言理解是在潛意識中激活相關概念的表征、并在意識中生成相關圖像的過程。表征包括視覺、聽覺、觸覺、嗅覺和味覺表征,它們是人在成長和發育過程中的經歷、在大腦各部分記憶的概念的視覺、聽覺、觸覺、嗅覺和味覺內容。
因此,語言理解與人們的經驗密切相關。生活中的基本概念,比如貓和狗,都是通過視覺、聽覺、觸覺等傳感器的輸入來學習的,當聽到或看到「貓」和「狗」這兩個詞,就會重新激活人們大腦中與其相關的視覺、聽覺和觸覺表征。
機器能否從大量的多模態數據(語言、視覺、語音)中學習更好的模型,從而更智能地處理語言、視覺和語音?多模態語言模型將是未來探索的重要課題。最近,該主題的研究也取得了一些進展——例如,Ramesh 等人發表的「Zero-shot text-to-image generation」,Radford 等人的「Learning transferable visual models from natural language supervision」。
7結語
語言模型的歷史可以追溯到一百多年前,Markov、Shannon 等人沒有預見到他們所研究的模型和理論會在后來產生如此大的影響;對 Bengio 來說,這甚至可能是出乎意料的。
未來一百年,語言模型將如何發展?它們仍然是人工智能技術的重要組成部分嗎?這可能超出了我們所能想象和預測的范圍。但可以看到,語言建模技術在不斷發展。在未來幾年,可能有更強大的模型出現會取代 BERT 和 GPT,我們有幸成為看到巨大成就的技術、并參與研發的第一代。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100719 -
機器學習
+關注
關注
66文章
8408瀏覽量
132567 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13553
原文標題:李航老師對預訓練語言模型發展的一些看法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大語言模型開發語言是什么
大語言模型如何開發
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
大語言模型的預訓練
大語言模型(LLM)快速理解






 工商網監
工商網監
評論