 帶寬進步推動 PCIe 標準
帶寬進步推動 PCIe 標準
Peripheral Component Interconnect Express (PCIe) 總線標準有很多依賴。或者更準確地說,需要容納大量流經它的數據。
相對成熟的非易失性內存快速 (NVMe) 協議以及剛剛起步但快速發展的計算快速鏈路 (CXL) 都在利用無處不在的 PCIe,預計 6.0 將于 2021 年底廣泛發布。
Microchip Technology 數據中心業務部主管 Mark Orthodoxou 表示,PCIe 的價值在于它無處不在,因為它可以跨 CPU 互操作,而且它的開放性允許圍繞它建立一個生態系統。他說 PCIe 的缺點源于它隨著時間的推移變得相當復雜,但這些挑戰是可以克服的,因為有很多可授權的 IP 可以利用。
點擊查看完整大小的圖片
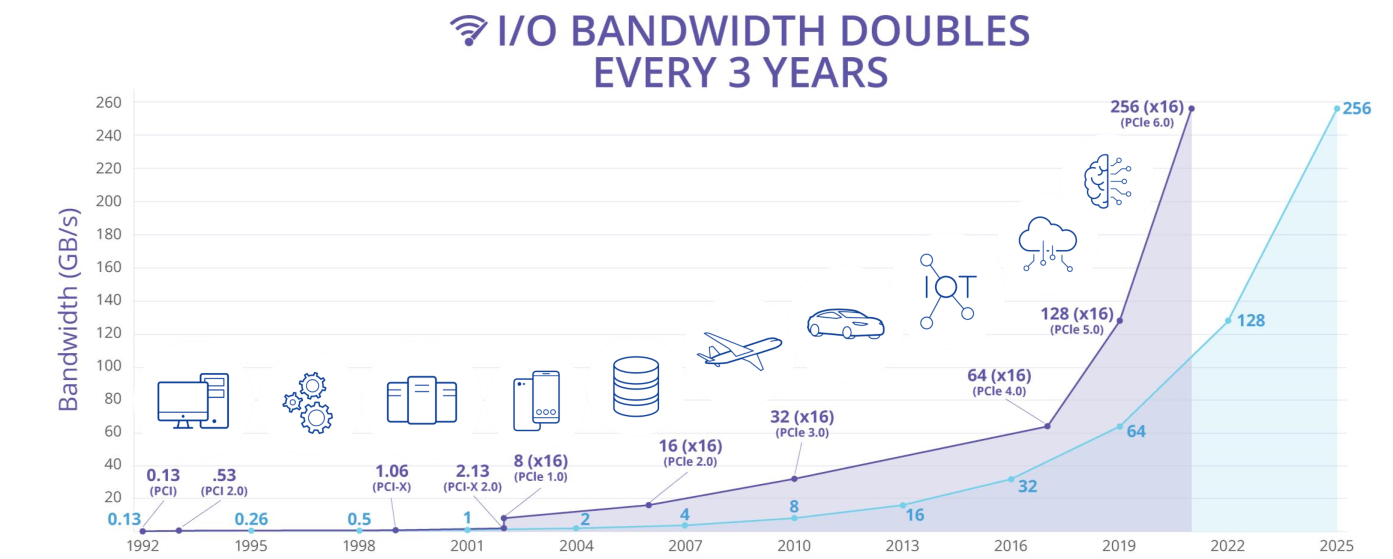
隨著移動和汽車領域出現新機遇,PCIe I/O 總線規范預計將繼續每三年更新一次,NVMe 和 CXL 會利用它提高存儲和內存性能訪問。(由 PCI-SIG 提供)
缺點之一是當今存在的某些特性和功能甚至在 PCIe 的早期階段都沒有想到。Orthodoxou 說,隨著新應用程序的映射,出現了意想不到的問題。一個示例是以熱插拔 NVMe SSD 的形式從服務器中移除設備。“它不是作為熱插拔接口設計的,所以需要做一些工作來處理這樣的事情。隨著時間的推移,PCIe 變得越來越復雜,因為人們找到了不同的使用方式。” 他說,即使出現了利用 PCIe 的新用途,例如 CXL,也沒有任何內在限制創新。“最終,它是一種僅存在于 PCIe 電氣設備上的協議。”
雖然 CXL 有可能比其他設備更早地利用 PCIe 6.0,但 Orthodoxou 表示,CXL 聯盟可能需要盡可能多的時間來整理 CXL 需要什么樣的外觀來支持需要最新和最好的 PCIe 的用例. “如果我們有一些不同的電氣接口可用,CXL 不會移動得更快。”
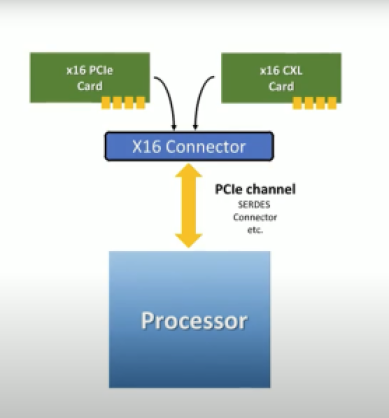
CXL 使用靈活的處理器端口,可以自動協商到標準 PCIe 事務協議或備用 CXL 事務協議。(來源:CXL)
Microchip 在不同的業務部門擁有許多產品,這些產品利用了 PCIe,包括工業、汽車和數據中心市場,包括 PCIe 交換機和 NVMe 控制器。“PCIe 為我們創造了大量的市場機會,”他說。然而,除了其 CXL Retimer 之外,該公司還沒有宣布任何 CXL 產品,但它在財團中很活躍。
與此同時,IDC 固態存儲和支持技術研究副總裁 Jeff Janukowicz 指出,NVMe 的采用已經將近十年,但去年標志著一個拐點,超過一半的企業在閃存 SSD 上的支出是 NVMe PCIe。“實現這一轉變需要一些時間,但我們看到圍繞 PCIe 的許多好處開始顯現。” 他說NVMe 2.0 的發布將允許圍繞 PCIe 的進一步發展,以及圍繞硬盤驅動器無法實現的外形尺寸的創新。“從硬件的角度來看,我們開始擺脫一些限制。”
Janukowicz 表示,雖然 PCIe 已成為一項基礎技術,但 CXL 等協議的出現反映了工作負載日益多樣化。“有很多創新試圖滿足不同的環境,而你開始看到一些興趣是圍繞 CXL 之類的東西。” 雖然 NVMe 的構建考慮了固態存儲,但他表示 CXL 是圍繞內存而非存儲構建的,以推動更高的性能和更低的復雜性,并包括內存連接設備、內存擴展和加速器。
Janukowicz 說,與 PCIe 一樣,價值主張的很大一部分是它是一個開放標準,任何人都可以參與創建解決工作負載方向的解決方案。“我們看到對擴展內存池以支持某些下一代工作負載的興趣越來越大,無論是內存類型的應用程序和內存數據庫,還是人工智能 (AI) 和機器學習等新興應用程序。 ”

史蒂夫·伍
但并不是每個人都認為 PCIe 的開放標準方法是唯一的選擇。Nvidia 選擇開發自己的 PCIe 替代品 NVLink。用于近距離半導體通信的基于有線的通信協議于 2014 年首次推出,可用于 CPU 和 GPU 之間以及僅在 GPU 之間的處理器系統中的數據和控制代碼傳輸。
Nvidia 產品管理高級總監 Paresh Kharya 表示,雖然 PCIe 可能無處不在,但其速度遠遠低于 Nvidia 在自己的服務器中為人工智能和高性能計算等工作負載提供的速度。“對計算能力的需求不斷增加。擴展計算的方法之一是讓多個 GPU 協同工作。” NVLink 提供快速且可擴展的互連,因此 Nvidia GPU 可以作為巨型加速器協同工作。他說,當它首次推出時,NVLink 提供的帶寬是 PCIe 3.0 的五倍,現在提供每秒 600 GB 的雙向帶寬,幾乎是主導 PCIe 4.0 的 10 倍。
雖然 NVLink 是 Nvidia 的專有技術,但其 GPU 仍然支持 PCIe。“這就是我們今天連接到 CPU 的方式,”Kharya 說。他說,雖然 IBM 等其他供應商已與 Nvidia 合作,將 NVLink 整合到他們的處理器中,但總的來說,這種互連主要用于使用 Nvidia GPU 加速工作負載。Nvidia 為已經具有 NVLink 功能的服務器提供基板和主板,以加速更廣泛的生態系統的采用,并且世界上一些最快的超級計算機使用 NVLink。
Kharya 表示,NVLink 使 Nvidia 能夠快速創新并不斷提高其客戶的性能。“我們希望繼續以盡可能快的速度發展 NLink 鏈接。” 他說,但它也積極與 CXL 社區合作并參與 PCIe 標準的推進,盡管 Nvidia 認為 NVLink 是當今提供的帶寬的明顯贏家。“我們真的希望 PCIe 標準能夠盡快發展。”
Janukowicz 表示,定制方法確實有其優點,并圍繞特定環境的性能延遲、成本或功耗等某些指標進行了優化,但開放標準僅在為市場帶來一些規模經濟方面提供了很多好處。“從歷史上看,開放標準對于推動市場確實是必要的。” 他說,客戶總是不愿與特定的供應商鎖定,尤其是考慮到當今大流行帶來的供應鏈挑戰。“它強調了一些靈活性的必要性,你往往會在更多的開放環境中獲得這種靈活性,在這種環境中,你當然可以雙源或有多種選擇。”
與此同時,隨著 CXL 的發展,對 PCIe 的更新正在繼續快速進行。Rambus 研究員 Steve Woo 表示,CXL 是數據如何推動架構發展的一個例子,而高帶寬內存 (HBM) 和圖形 DDR (GDDR) 標準的發展速度比以往更快,以響應數據和這些架構的重要性。“像 CXL 這樣的重要驅動因素將繼續推動行業提高 PCIe 速度,”他說。“它可靠,人們理解它,它在這個行業已經存在了一段時間,并且值得信賴。”
亞內斯
Woo 說,數據移動已經開始成為瓶頸,而不是內存或計算。隨著圖形分辨率和幀速率的提高,過去是圖形市場推動 PCIe 變得更快。但他說,這些數據速率與今天的節奏相去甚遠。數據量每兩年翻一番,這意味著管道的性能必須跟上。
PCIe 6.0 承諾做到這一點。在 5 月下旬由定義 PCIe I/O 總線規范和相關外形尺寸的組織 PCI Express 特別興趣小組 (PCI-SIG) 的網絡研討會更新中,最新的迭代被描述為自 PCIe 遷移以來最顯著的飛躍2.0 到 PCIe 3.0。即將到來的更新使其數據傳輸速率翻倍,并提供比其前身更高的信號速率和更嚴格的信號完整性要求。盡管 PCI Express 0.71 規范草案已在 7 月初發布供會員審查,但預計將在今年年底正式發布。預計草案 0.9 將遵循并對任何最終問題進行為期兩個月的審查。
PCIe 6.0 實現 PAM4 信令,允許它在串行通道上將更多位打包到相同的時間量中包括低延遲前向糾錯 (FEC) 以及其他機制,以提高帶寬效率和提高可靠性。它還通過應用 AES-GCM 對整個 TLP 進行加密和經過身份驗證的保護來提供 TLP 的完整性和數據加密 (IDE)。單個 PCIe 6.0 x16 可支持 800G 以太網。這一最新迭代針對高帶寬應用程序,例如云、人工智能和機器學習以及邊緣計算。
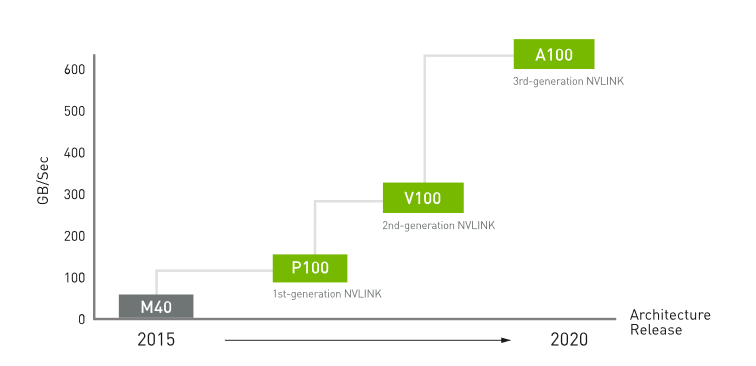
Nvidia 七年前選擇開發自己的 PCIe 替代品。在 NVIDIA A100 中,NVLink 將 GPU 間通信帶寬提高了一倍,幾乎是 PCIe Gen4 帶寬的 10 倍。(由英偉達提供)
它的完成將在 PCIe 5.0 設備預計開始進入企業市場之際完成。該規范于 2019 年 5 月發布,將其前身的帶寬增加了一倍,同時保持與所有 PCIe 代的向后兼容性。PCIe 5.0 還具有電氣變化,以提高連接器的信號完整性和機械性能。
PCI-SIG 總裁兼董事會主席 Al Yanes 表示,該組織的成員繼續“蓬勃發展”,在全球范圍內擁有近 900 名成員,重點是 PCIe 在移動領域采用的全系列設備以及汽車行業的大量興趣。“我們成立了一個工作組并獲得了很多參與,所以這就是我們的新目標行業。”
他預計每三年或更短時間更新一次,并繼續關注合規性和向后兼容性,這兩者都是總線標準成功秘訣的重要組成部分。
審核編輯 黃昊宇
-
帶寬
+關注
關注
3文章
926瀏覽量
40913 -
PCIe
+關注
關注
15文章
1234瀏覽量
82584
發布評論請先 登錄
相關推薦
PCIe數據傳輸協議詳解
如何選擇適合的PCIe配置
PCIe 4.0與3.0的區別 PCIe設備的故障排除方法
pcie擴展槽的使用技巧
pcie 4.0與pcie 5.0的區別
pcie帶寬對計算性能的影響
PCIe連接器的類型和規格
如何測試PCIe插槽的速度
PCIe 4.0與PCIe 3.0的性能對比
家用電腦的PCIe接口如何設計PCB?

家用電腦的PCIe接口如何設計PCB?
FPGA的PCIE接口應用需要注意哪些問題
什么是PCIe?PCIe有什么用途?什么是PCIe通道
PCIe Tx/Rx 物理層信號完整性測試方法詳解

PCIE相關概念和帶寬計算方法






 工商網監
工商網監
評論