 開發嵌入式神經網絡的現實
開發嵌入式神經網絡的現實
關于將人工智能用于越來越智能的車輛的文章已經很多。但是,您如何將在服務器場上開發的神經網絡 (NN) 壓縮到量產汽車中資源受限的嵌入式硬件中呢?本文探討了我們應該如何授權汽車生產 AI 研發工程師在將 NN 從原型到生產的整個過程中改進 NN,而不是像今天過早地將 NN 移交給嵌入式軟件團隊的過程。
“如果我們要充分利用嵌入式硬件資源,我們需要讓生產 AI 團隊在軟件移植過程中利用他們對 NN 的知識”(來源:Marton Feher,SVP 硬件工程,AImotive)
嵌入式人工智能:嵌入式軟件——但不是我們所知道的
對于任何注定要在批量生產中部署的嵌入式軟件,一旦完成并驗證了其核心功能的實現,就會在代碼中投入大量精力。這個優化階段是關于最小化所需的內存、CPU 和其他資源,以便盡可能多地保留軟件功能,同時將執行它所需的資源減少到絕對最低限度。
這種從基于實驗室的算法創建嵌入式軟件的過程使生產工程師能夠將軟件功能成本工程化為可量產的形式,與用于開發它的海量計算數據中心相比,所需的芯片和硬件更便宜、功能更差。但是,它通常需要從一開始就凍結功能,只進行代碼修改以改進算法本身的執行方式。對于大多數軟件來說,這很好:確實,它可以使用嚴格的驗證方法來確保嵌入過程保留所需的所有功能。
然而,當嵌入基于 NN 的 AI 算法時,這可能是一個主要問題。為什么?因為從一開始就凍結功能,您正在刪除可以優化執行的主要方法之一。
問題是什么?
有兩種根本不同的方法可以解決將復雜的 NN 從實驗室中不受約束、資源豐富的 NN 訓練環境移植到受嚴格約束的嵌入式硬件平臺的任務:
優化執行NN的代碼
優化神經網絡本身
當嵌入式軟件工程師發現性能問題,例如內存帶寬瓶頸或底層嵌入式硬件平臺利用率低下時,傳統的嵌入式軟件技術會鼓勵您深入挖掘底層代碼并找出問題所在。
這反映在當今可用于嵌入式MCU和DSP的許多先進而復雜的工具中。它們使您能夠了解軟件中正在發生的事情的最低水平,并識別和改進軟件本身的執行——希望不會改變其功能。
對于神經網絡來說,優化與傳統的嵌入式軟件完全不同——至少如果你想用可用的硬件資源實現盡可能最佳的結果。對于神經網絡,通過改變拓撲神經網絡本身(神經網絡的各個層如何連接,以及每個層做什么)和使用更新的約束和輸入重新訓練來實現改進。這是因為功能不是由神經網絡“軟件”定義的,而是在訓練期間應用的目標和約束,以創建定義神經網絡最終行為的權重。
因此,在執行神經網絡的嵌入過程時,需要凍結神經網絡的目標性能,而不是如何實現它。如果您從嵌入過程開始就約束神經網絡拓撲,那么您就是在刪除生產工程師需要的提高性能的工具。
這意味著您需要新的不同工具來完成將NNs從實驗室移植到嵌入式平臺的任務。低級軟件工程師無法完成這項工作——你需要人工智能工程師根據工具提供的性能信息來調整神經網絡及其訓練。這是新的:當研發工程師將經過培訓的神經網絡交給生產工程師時,他們再也不能說“工作完成了”!
不同的方法
通過采用將 AI 研發工程師置于嵌入式軟件移植任務中心的開發工作流程,任何芯片都可以實現卓越的結果。使用以層為中心的分析,輔以從編譯改進的卷積神經網絡 (CNN) 到查看目標神經處理器單元 (NPU) 的準確性能結果的幾分鐘內快速周轉,開發人員可以使用相同的底層硬件實現 100% 或更多的增益. 這是因為修改 CNN 本身,而不是只修改用于執行相同 CNN 的代碼,為 AI 工程師提供了更大的靈活性來識別和實施性能改進。
在開發我們的 aiWare NPU 時,AImotive 使用了我們自己的 AI 工程師將移植過程移植到具有廣泛 NPU 功能的多個不同芯片的經驗。我們希望找到更好的方法來幫助我們自己的 AI 工程師完成這項任務,因此在開發我們對 aiWare NPU 本身和支持它的 aiWare Studio 工具的要求時,我們確定了我們在過去的:
高度確定性的 NPU 架構,使時序非常可預測
準確的基于層(不是基于時序或低級代碼)的性能估計,以便任何 AI 研發工程師都可以看到更改其訓練標準(例如添加或更改使用的場景,或修改目標 KPI)的影響; / 或 NN 拓撲快速
準確的離線性能估計,以便在第一個硬件可用之前執行所有 NN 優化(因為第一個原型總是稀缺的!)
點擊查看完整大小的圖片
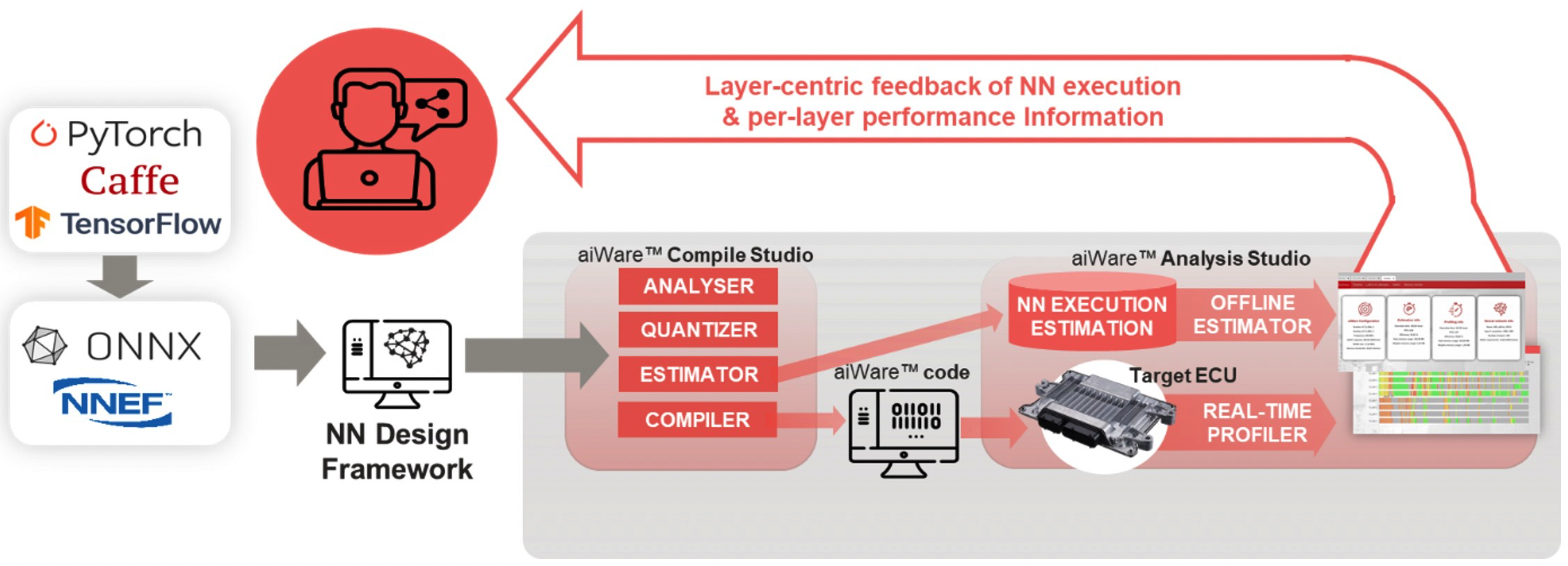
圖 1:aiWare Studio 使用戶能夠優化他們的 NN,而不是用于執行它們的代碼。這為 AI 設計人員提供了更大的靈活性,可以更快地實現出色的結果。(來源:AImotive)
結果是一組工具使 AI 研發工程師能夠在實驗室環境中對目標硬件進行幾乎所有優化,并在最終目標硬件的 5% 范圍內展示性能——這一切都在任何人看到硬件之前完成。
最終檢查
當然,在芯片和硬件原型可用時測量最終硬件至關重要。這種開發環境中實時硬件分析功能的可用性使工程師能夠訪問由此類工具支持的 NPU 內的一系列深度嵌入式硬件寄存器和計數器。雖然芯片開銷很小(因為許多 NPU 主要由內存而非邏輯控制),但這些功能可以在執行期間實現前所未有的、非侵入式的實時性能測量。然后可以將其用于直接與離線性能估計器結果進行比較,以確認準確性。
點擊查看完整大小的圖片
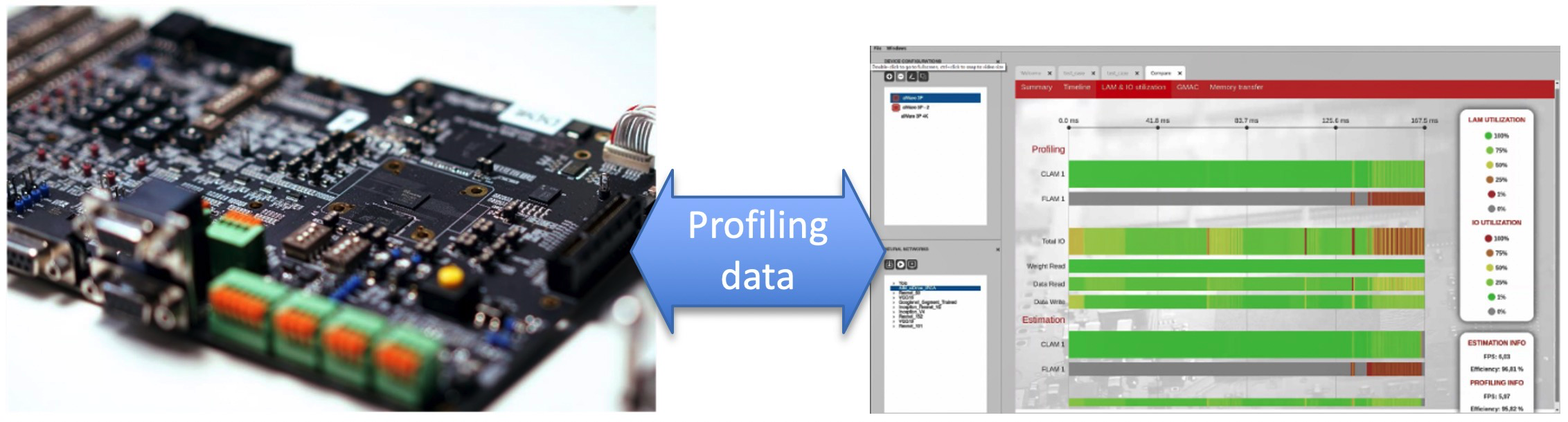
圖 2:使用嵌入式寄存器和計數器,aiWare Studio 可以準確測量最終芯片性能,與離線估計結果相比,通常在 1%-5% 以內。(來源:AImotive 和 Nextchip Co. Ltd)
結論
這種新方法為汽車行業提供了一種新的、更好的方式來開發、優化和在生產車輛中部署人工智能。使用協同 NPU 硬件和工具,人工智能工程師可以為汽車應用設計、實施和優化更好的 CNN。
審核編輯 黃昊宇
-
嵌入式
+關注
關注
5082文章
19108瀏覽量
304836 -
神經網絡
+關注
關注
42文章
4771瀏覽量
100720 -
AI
+關注
關注
87文章
30757瀏覽量
268902
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論