 Kubernetes網絡模型的基礎知識
Kubernetes網絡模型的基礎知識
Kubernetes 是為運行分布式集群而建立的,分布式系統的本質使得網絡成為 Kubernetes 的核心和必要組成部分,了解 Kubernetes 網絡模型可以使你能夠正確運行、監控和排查應用程序故障。
網絡所涉及的內容很多,擁有許多成熟的技術。對于不熟悉的人來說可能會非常痛苦,因為大多數人對網絡都有先入為主的觀念,并且有很多新舊概念需要理解并組合成一個連貫的整體。所說的網絡可能包括網絡命名空間、虛擬接口、IP 轉發和網絡地址轉換等技術。本指南旨在通過討論每種 Kubernetes 相關技術以及如何使用這些技術來啟用 Kubernetes 網絡模型的描述來揭開 Kubernetes 網絡的神秘面紗。
本指南相當長,分為幾個部分。我們首先討論一些基本的 Kubernetes 術語,以確保在整個指南中正確使用術語,然后討論 Kubernetes 網絡模型以及它強加的設計和實施決策。接下來是本指南中最長且最有趣的部分:深入討論如何使用幾個不同的用例展示在Kubernetes內是如何進行通信的。
文章大綱如下: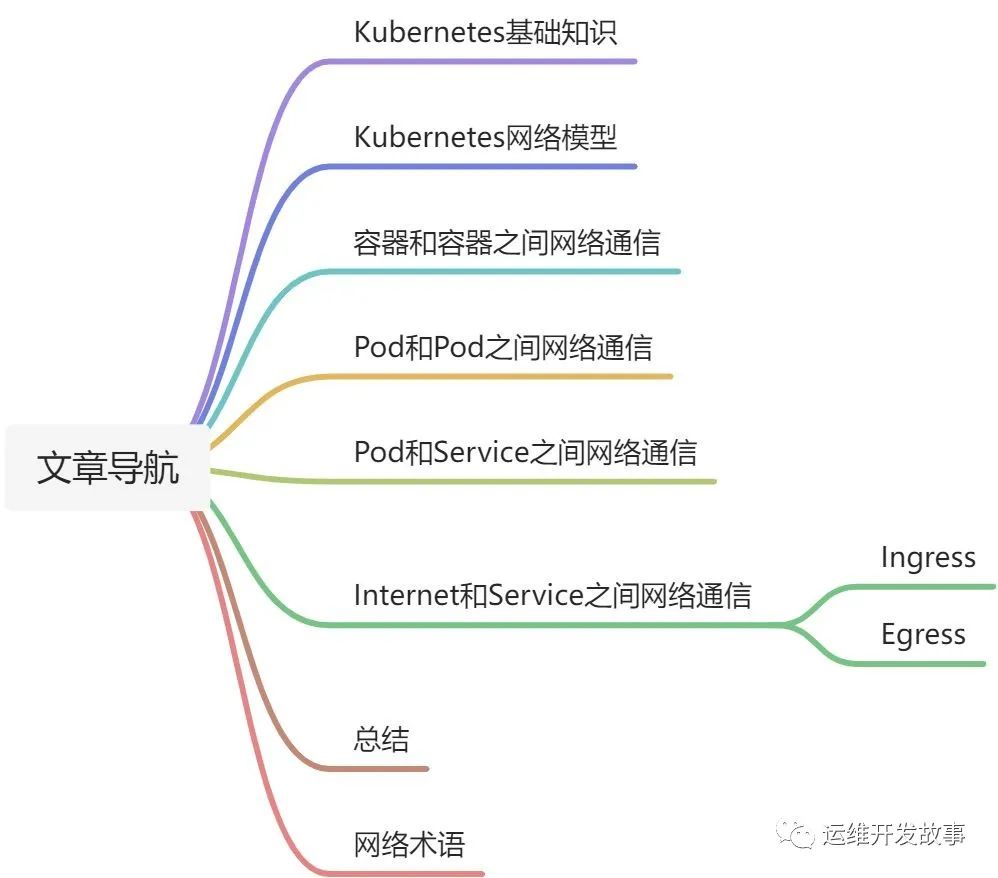
1、Kubernetes基礎知識
Kubernetes 由幾個核心概念構建而成,這些概念組合成越來越強大的功能。本節列出了這些概念中的每一個,并提供了一個簡短的概述,以幫助促進討論。Kubernetes 的內容遠不止此,這里僅僅簡要闡述一些基礎知識。如果您已經熟悉 Kubernetes,請隨意跳過本節。
1.1、Kubernetes API server
在 Kubernetes 中,一切都是由 Kubernetes API 服務器(kube-apiserver)提供的 API 調用。API 服務器是 etcd 數據存儲的網關,它維護應用程序集群的所需狀態。要更新 Kubernetes 集群的狀態,您可以對描述所需狀態的 API 服務器進行 API 調用。
1.2、Controllers
控制器是用于構建 Kubernetes 的核心抽象。一旦您使用 API 服務器聲明了集群的所需狀態,控制器就會通過持續觀察 API 服務器的狀態并對任何更改做出反應來確保集群的當前狀態與所需狀態相匹配。控制器內部實現了一個循環,該循環不斷檢查集群的當前狀態與集群的期望狀態。如果有任何差異,控制器將執行任務以使當前狀態與所需狀態匹配。在偽代碼中:
whiletrue:
X=currentState()
Y=desiredState()
ifX==Y:
return#Donothing
else:
do(taskstogettoY)
例如,當您使用 API 服務器創建新 Pod 時,Kubernetes 調度程序(控制器)會注意到更改并決定將 Pod 放置在集群中的哪個位置。然后它使用 API 服務器(由 etcd 支持)寫入狀態更改。kubelet(一個控制器)然后會注意到新的變化并設置所需的網絡功能以使 Pod 在集群內可訪問。在這里,兩個獨立的控制器對兩個獨立的狀態變化做出反應,以使集群的現實與用戶的意圖相匹配。
1.3、Pods
Pod 是 Kubernetes 的原子——用于構建應用程序的最小可部署對象。單個 Pod 代表集群中正在運行的工作負載,并封裝了一個或多個 Docker 容器、任何所需的存儲和唯一的 IP 地址,組成 pod 的容器被設計為在同一臺機器上共同定位和調度。
1.4、Nodes
節點是運行 Kubernetes 集群的機器。這些可以是裸機、虛擬機或其他任何東西。主機一詞通常與節點互換使用。我將嘗試一致地使用術語節點,但有時會根據上下文使用虛擬機這個詞來指代節點。
2、Kubernetes網絡模型
Kubernetes 對 Pod 的聯網方式做出了自以為是的選擇。特別是,Kubernetes 對任何網絡實現都規定了以下要求:
- 所有 Pod 都可以在不使用網絡地址轉換 (NAT) 的情況下與所有其他 Pod 通信。
- 所有節點都可以在沒有 NAT 的情況下與所有 Pod 通信。
- Pod 認為自己的 IP 與其他人認為的 IP 相同。
鑒于這些限制,我們需要解決四個不同的網絡問題:
- 容器到容器網絡
- Pod 到 Pod 網絡
- Pod 到服務網絡
- Internet 到服務網絡
本指南的其余部分將討論這些問題中的每一個 以及他們的解決方案。
3、容器和容器之間網絡通信
通常,我們將虛擬機中的網絡通信視為直接與以太網設備交互,如圖 1 所示。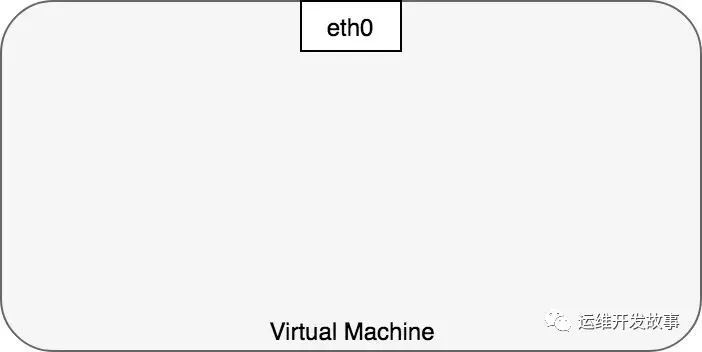
實際上,情況比這更微妙。在 Linux 中,每個正在運行的進程都在一個網絡命名空間內進行通信,該命名空間為邏輯網絡堆棧提供了自己的路由、防火墻規則和網絡設備。本質上,網絡命名空間為命名空間內的所有進程提供了一個全新的網絡堆棧。作為 Linux 用戶,可以使用 ip 命令創建網絡命名空間。例如,以下命令將創建一個名為 ns1 的新網絡命名空間。
$ipnetnsaddns1
創建命名空間時,會在 /var/run/netns 下為其創建一個掛載點,即使沒有附加任何進程,命名空間也可以保留。
您可以通過列出 /var/run/netns 下的所有掛載點或使用 ip 命令來列出可用的命名空間。
$ls/var/run/netns
ns1
$ipnetns
ns1
默認情況下,Linux 將每個進程分配給根網絡命名空間以提供對外部世界的訪問,如圖 2 所示。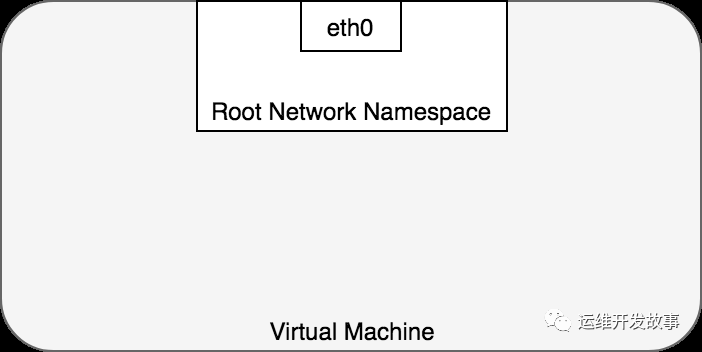
就 Docker 結構而言,Pod 被建模為一組共享網絡命名空間的 Docker 容器。Pod 中的容器都具有相同的 IP 地址和端口空間,這些 IP 地址和端口空間是通過分配給 Pod 的網絡命名空間分配的,并且可以通過 localhost 找到彼此,因為它們位于同一個命名空間中。我們可以為虛擬機上的每個 Pod 創建一個網絡命名空間。這是使用 Docker 作為“Pod 容器”實現的,它保持網絡命名空間打開,而“應用容器”(用戶指定的東西)通過 Docker 的 –net=container: 函數加入該命名空間。圖 3 顯示了每個 Pod 如何由共享命名空間內的多個 Docker 容器 (ctr*) 組成。
Pod 中的應用程序還可以訪問共享卷,這些卷被定義為 Pod 的一部分,并且可以掛載到每個應用程序的文件系統中。
4、Pod和Pod之間網絡通信
在 Kubernetes 中,每個 Pod 都有一個真實的 IP 地址,并且每個 Pod 都使用該 IP 地址與其他 Pod 通信。現在任務是了解 Kubernetes 如何使用真實 IP 實現 Pod 到 Pod 的通信,無論 Pod 部署在集群中的同一個物理節點還是不同的節點上。我們通過考慮駐留在同一臺機器上的 Pod 來開始這個討論,以避免通過內部網絡跨節點通信的復雜性。
從 Pod 的角度來看,它存在于自己的以太網命名空間中,需要與同一節點上的其他網絡命名空間進行通信。值得慶幸的是,可以使用 Linux 虛擬以太網設備或由兩個虛擬接口組成的 veth 對連接命名空間,這些虛擬接口可以分布在多個命名空間上。要連接 Pod 命名空間,我們可以將 veth 對的一側分配給根網絡命名空間,將另一側分配給 Pod 的網絡命名空間。每對 veth 對的工作方式就像一根跳線,連接兩側并允許流量在它們之間流動。這個設置可以復制到機器上的盡可能多的 Pod。圖 4 顯示了將 VM 上的每個 Pod 連接到根命名空間的 veth 對。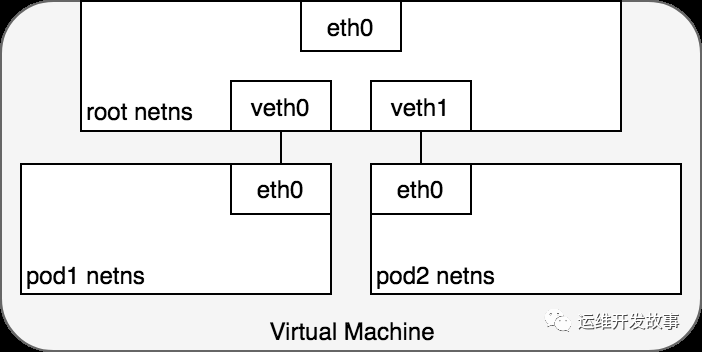
此時,我們已將 Pod 設置為每個都有自己的網絡命名空間,以便它們相信自己擁有自己的以太網設備和 IP 地址,并且它們連接到節點的根命名空間。現在,我們希望 Pod 通過根命名空間相互通信,為此我們使用網橋。
Linux 以太網網橋是一個虛擬的第 2 層網絡設備,用于聯合兩個或多個網段,透明地工作以將兩個網絡連接在一起。網橋通過檢查通過它的數據包的目的地并決定是否將數據包傳遞到連接到網橋的其他網段來維護源和目標之間的轉發表來運行。橋接代碼通過查看網絡中每個以太網設備的唯一 MAC 地址來決定是橋接數據還是丟棄數據。
網橋實現 ARP 協議以發現與給定 IP 地址關聯的鏈路層 MAC 地址。當網橋接收到數據幀時,網橋將幀廣播到所有連接的設備(原始發送者除外),響應該幀的設備存儲在查找表中。具有相同 IP 地址的未來流量使用查找表來發現將數據包轉發到的正確 MAC 地址。
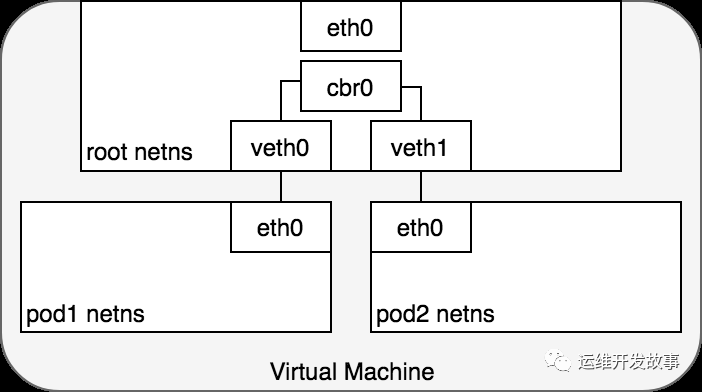 圖5. 使用橋接連接網絡
圖5. 使用橋接連接網絡4.1、同節點Pod通信
給定將每個 Pod 與自己的網絡堆棧隔離的網絡命名空間、將每個命名空間連接到根命名空間的虛擬以太網設備以及將命名空間連接在一起的網橋,我們終于準備好在同一節點上的 Pod 之間進行通信。這如圖 6 所示。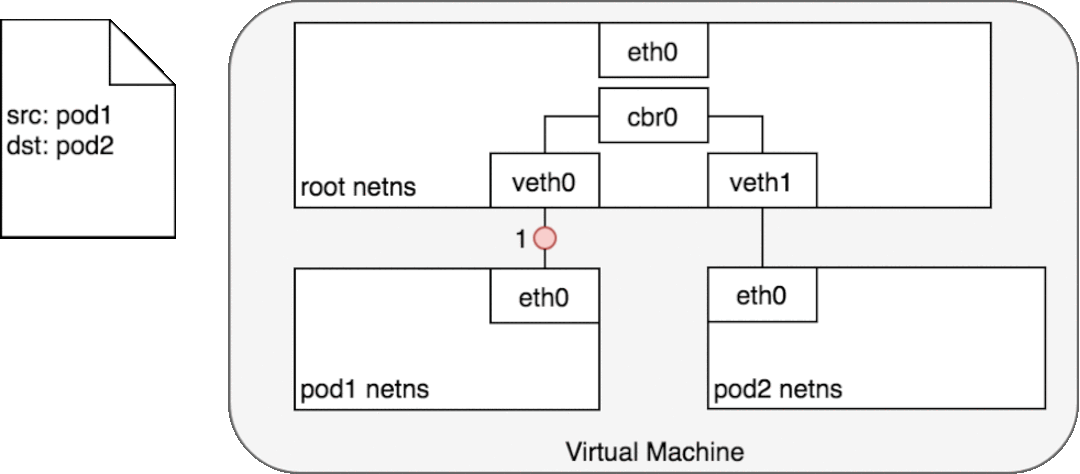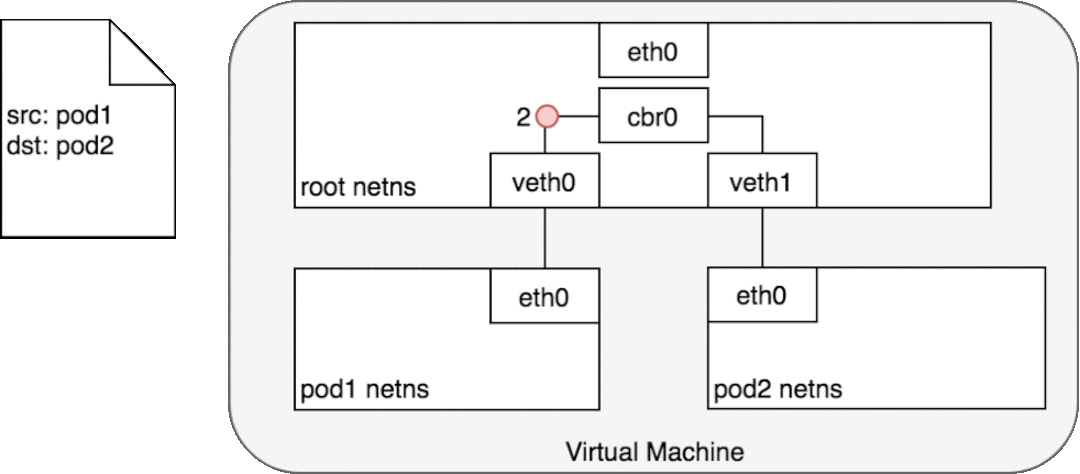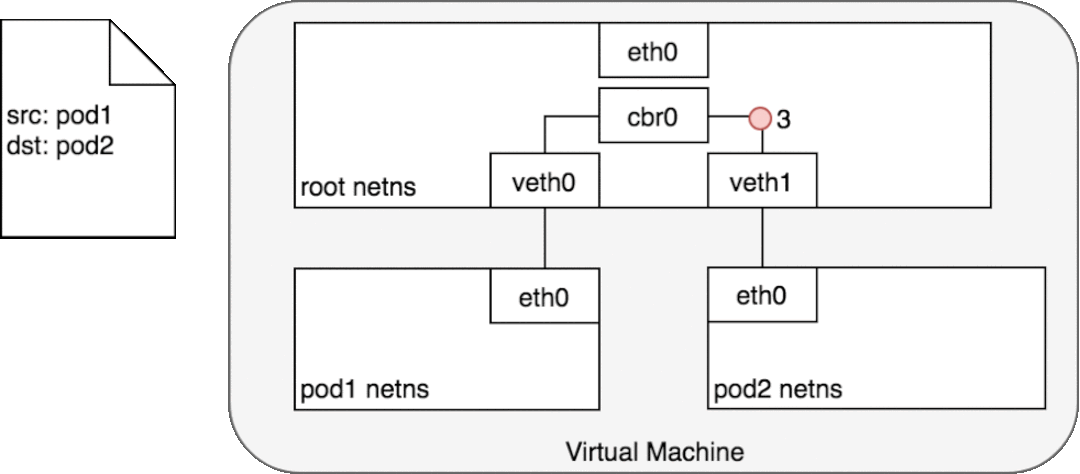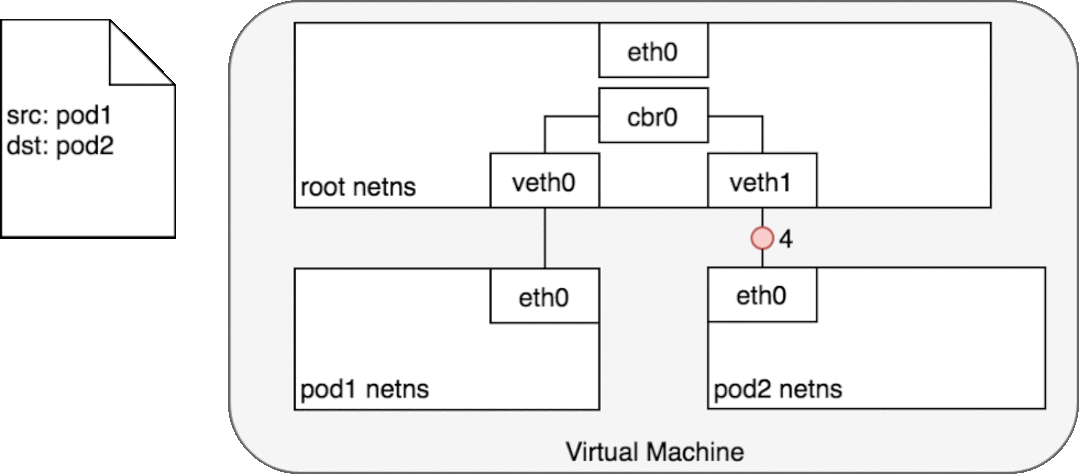
在圖 6 中,Pod 1 將數據包發送到它自己的以太網設備 eth0,該設備可用作 Pod 的默認設備。對于 Pod 1,eth0 通過虛擬以太網設備連接到根命名空間 veth0 (1)。網橋 cbr0 配置有 veth0 連接到它的網段。一旦數據包到達網橋,網橋會解析正確的網段以使用 ARP 協議將數據包發送到 veth1 (3)。當數據包到達虛擬設備 veth1 時,它被直接轉發到 Pod 2 的命名空間和該命名空間內的 eth0 設備 (4)。在整個流量流中,每個 Pod 僅與 localhost 上的 eth0 通信,并且流量被路由到正確的 Pod。使用網絡的開發體驗是開發人員所期望的默認行為。
Kubernetes 的網絡模型規定 Pod 必須可以通過其 IP 地址跨節點訪問。也就是說,一個 Pod 的 IP 地址始終對網絡中的其他 Pod 可見,每個 Pod 看待自己的 IP 地址的方式與其他 Pod 看待它的方式相同。我們現在轉向不同節點上的 Pod 之間如何進行通信的問題。
4.2、跨節點Pod通信
在研究了如何在同一節點上的 Pod 之間如何進行通信之后,我們繼續研究在不同節點上的 Pod 如何進行通信。Kubernetes 網絡模型要求 Pod IP 可以通過網絡訪問,但它沒有指定必須如何完成。
通常,集群中的每個節點都分配有一個 CIDR 塊,指定該節點上運行的 Pod 可用的 IP 地址。一旦流向 CIDR 塊的流量到達節點,節點就有責任將流量轉發到正確的 Pod。圖 7 說明了兩個節點之間的流量流,假設網絡可以將 CIDR 塊中的流量路由到正確的節點。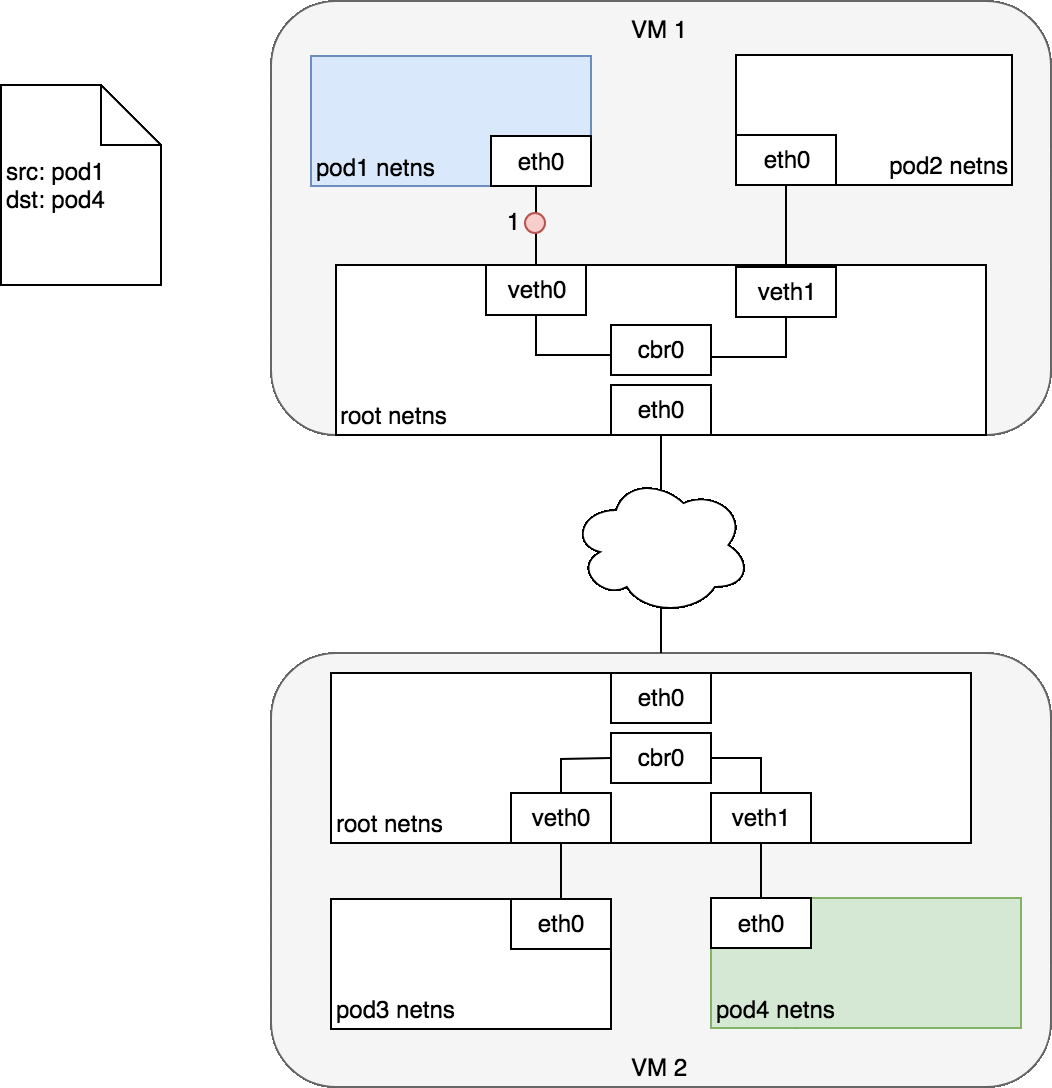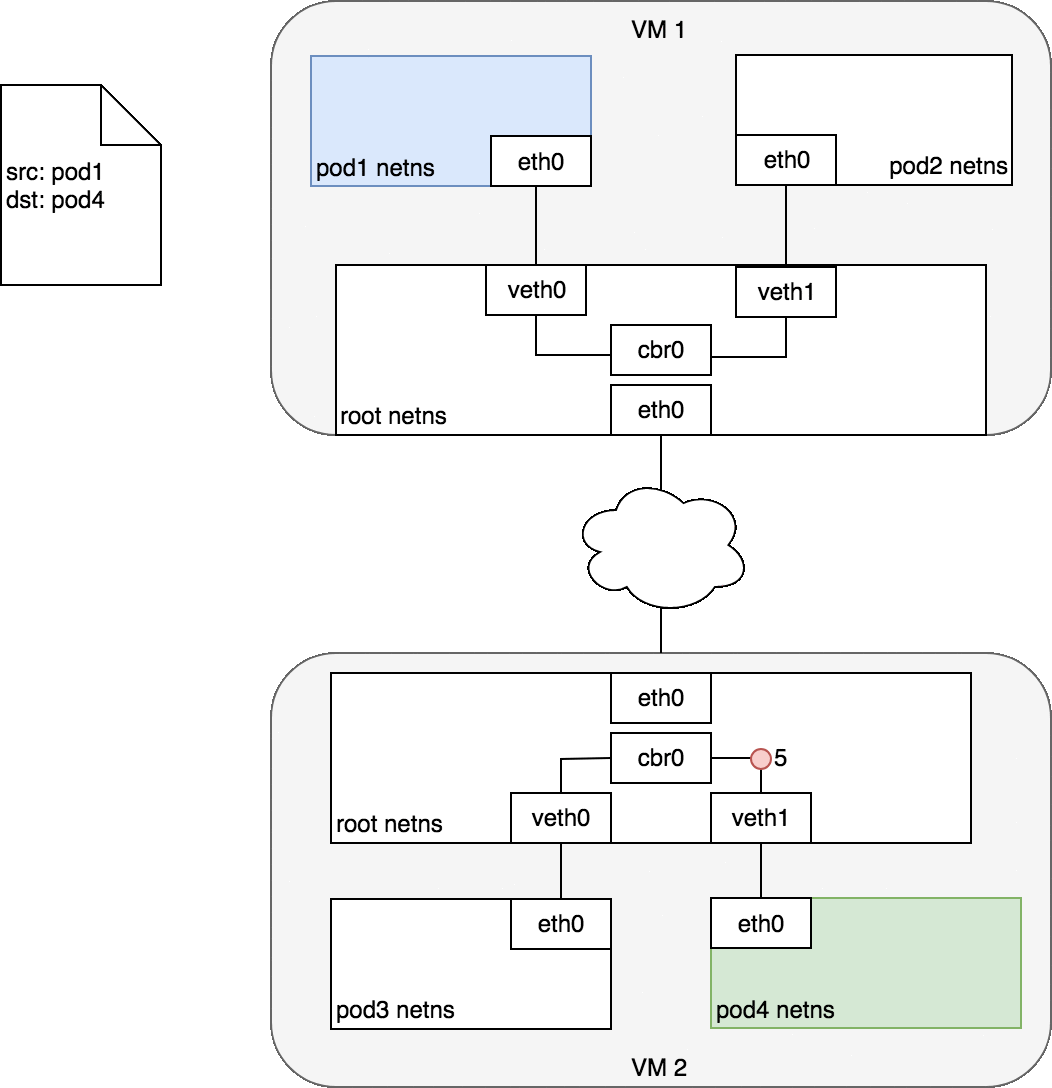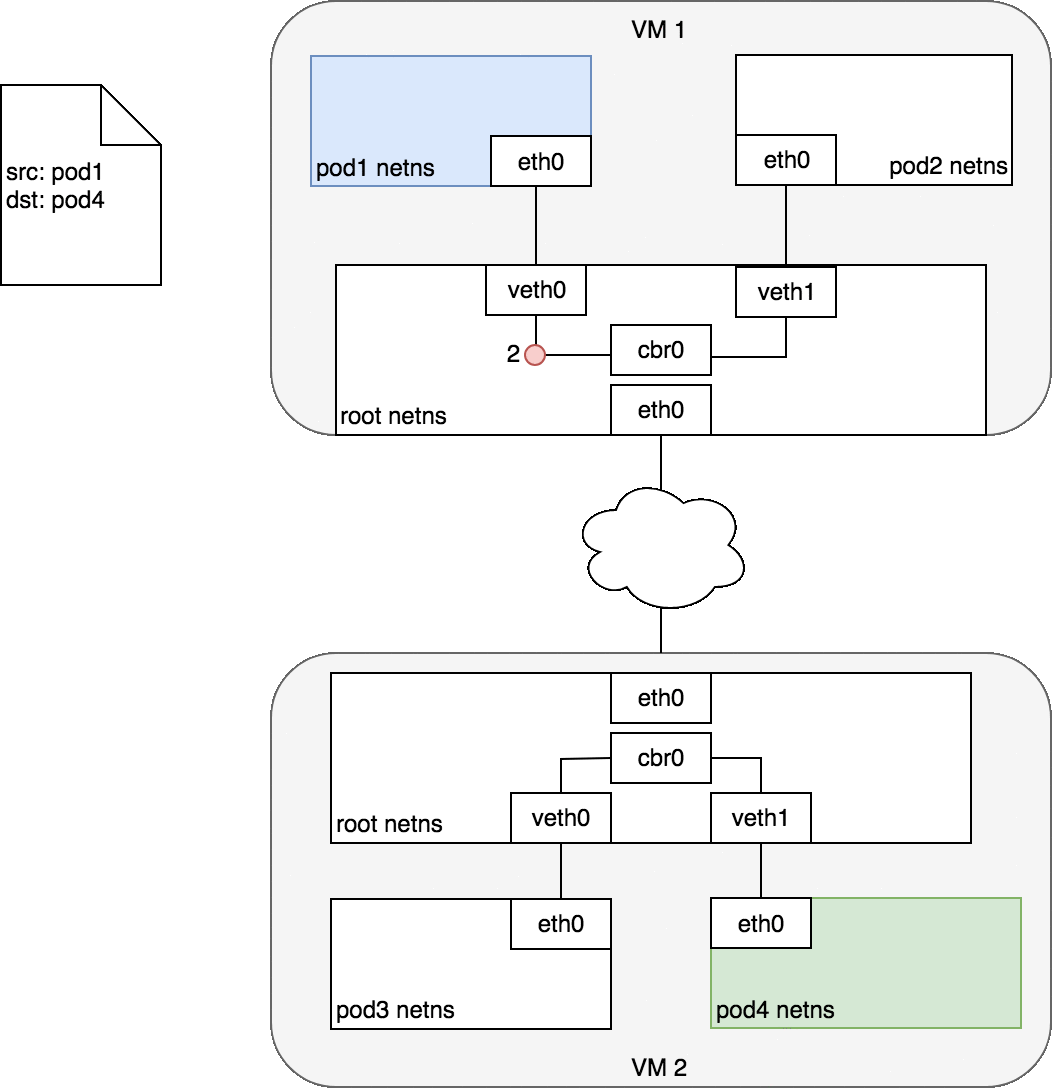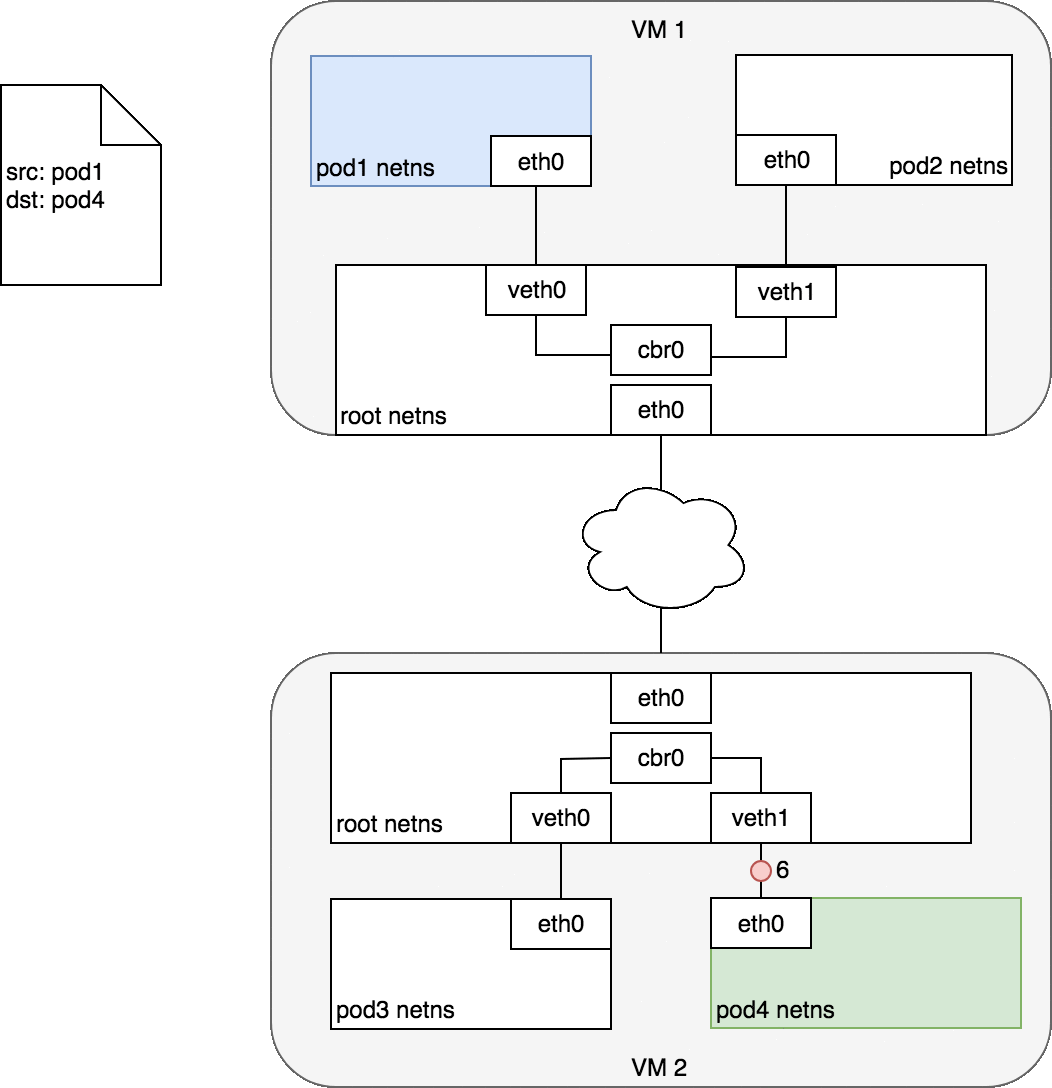
圖 7 以與圖 6 相同的請求開始,但這次,目標 Pod(以綠色突出顯示)與源 Pod(以藍色突出顯示)位于不同的節點上。數據包首先通過 Pod 1 的以太網設備發送,該設備與根命名空間 (1) 中的虛擬以太網設備配對。最終,數據包最終到達根命名空間的網橋 (2)。ARP 將在網橋上失敗,因為沒有設備連接到網橋并具有正確的數據包 MAC 地址。失敗時,網橋將數據包發送到默認路由——根命名空間的 eth0 設備。此時路由離開節點并進入網絡 (3)。我們現在假設網絡可以根據分配給節點的 CIDR 塊將數據包路由到正確的節點 (4)。數據包進入目標節點的根命名空間(VM 2 上的 eth0),在那里它通過網橋路由到正確的虛擬以太網設備 (5)。最后,路由通過位于 Pod 4 的命名空間 (6) 中的虛擬以太網設備對來完成。一般來說,每個節點都知道如何將數據包傳遞給在其中運行的 Pod。一旦數據包到達目標節點,數據包的流動方式與在同一節點上的 Pod 之間路由流量的方式相同。
我們輕松地避開了如何配置網絡以將 Pod IP 的流量轉發到負責這些 IP 的正確節點。這是特定于網絡的,但查看特定示例將提供對所涉及問題的一些見解。例如,借助 AWS,Amazon 為 Kubernetes 維護了一個容器網絡插件,允許節點到節點網絡使用 [容器網絡接口 (CNI) 插件] (?https://github.com/aws/amazon)) 在 Amazon VPC 環境中運行-vpc-cni-k8s)。
容器網絡接口 (CNI) 提供了一個通用 API,用于將容器連接到外部網絡。作為開發人員,我們想知道 Pod 可以使用 IP 地址與網絡通信,并且我們希望此操作的機制是透明的。AWS 開發的 CNI 插件試圖滿足這些需求,同時通過 AWS 提供的現有 VPC、IAM 和安全組功能提供安全和可管理的環境,解決方案是使用彈性網絡接口。
在 EC2 中,每個實例都綁定到一個彈性網絡接口 (ENI),并且所有 ENI 都連接在一個 VPC 內——ENI 無需額外努力即可相互訪問。默認情況下,每個 EC2 實例部署一個 ENI,但您可以自由創建多個 ENI 并將它們部署到您認為合適的 EC2 實例。適用于 Kubernetes 的 AWS CNI 插件通過為部署到節點的每個 Pod 創建一個新的 ENI 來利用這種靈活性。因為 VPC 中的 ENI 已經連接到現有 AWS 基礎設施中,所以這允許每個 Pod 的 IP 地址在 VPC 中本地可尋址。當 CNI 插件部署到集群時,每個節點(EC2 實例)都會創建多個彈性網絡接口并為這些實例分配 IP 地址,從而為每個節點形成一個 CIDR 塊。部署 Pod 時,作為 DaemonSet 部署到 Kubernetes 集群的小型二進制文件會從 Nodes 本地 kubelet 進程接收任何將 Pod 添加到網絡的請求。這個二進制文件從節點的可用 ENI 池中選擇一個可用的 IP 地址,并通過在 Linux 內核中連接虛擬以太網設備和網橋將其分配給 Pod,如在同一節點內聯網 Pod 時所述。有了這個,Pod 流量就可以跨集群內的節點路由。
5、Pod和Service之間網絡通信
我們已經展示了如何在 Pod 及其關聯的 IP 地址之間路由轉發。在我們需要應對變化之前,這很有效。Pod IP 地址不是持久的,并且會隨著擴展或縮減、應用程序崩潰或節點重啟而出現和消失。這些事件中的每一個都可以使 Pod IP 地址在沒有警告的情況下更改。Service被內置到 Kubernetes 中來解決這個問題。
Kubernetes Service 管理一組 Pod 的狀態,允許您跟蹤一組隨時間動態變化的 Pod IP 地址。Service充當對 Pod 的抽象,并將單個虛擬 IP 地址分配給一組 Pod IP 地址。任何發往 Service 虛擬 IP 的流量都將被轉發到與虛擬 IP 關聯的 Pod 集。這允許與 Service 關聯的 Pod 集隨時更改——客戶端只需要知道 Service 的虛擬 IP即可,它不會更改。
創建新的 Kubernetes Service時,會為您創建一個新的虛擬 IP(也稱為集群 IP)。在集群中的任何地方,發往虛擬 IP 的流量都將負載均衡到與服務關聯的一組支持 Pod。實際上,Kubernetes 會自動創建并維護一個分布式集群內負載均衡器,將流量分配到服務相關聯的健康 Pod。讓我們仔細看看它是如何工作的。
5.1、netfilter 和 iptables
為了在集群中執行負載平衡,Kubernetes 依賴于 Linux 內置的網絡框架——netfilter。Netfilter 是 Linux 提供的一個框架,它允許以自定義處理程序的形式實現各種與網絡相關的操作。Netfilter 為數據包過濾、網絡地址轉換和端口轉換提供了各種功能和操作,它們提供了引導數據包通過網絡所需的功能,以及提供禁止數據包到達計算機網絡中敏感位置的能力。
iptables 是一個用戶空間程序,它提供了一個基于表的系統,用于定義使用 netfilter 框架操作和轉換數據包的規則。在 Kubernetes 中,iptables 規則由 kube-proxy 控制器配置,該控制器監視 Kubernetes API 服務器的更改。當對 Service 或 Pod 的更改更新 Service 的虛擬 IP 地址或 Pod 的 IP 地址時,iptables 規則會更新以正確地將指向 Service 的流量轉發到正確的Pod。iptables 規則監視發往 Service 的虛擬 IP 的流量,并且在匹配時,從可用 Pod 集中選擇一個隨機 Pod IP 地址,并且 iptables 規則將數據包的目標 IP 地址從 Service 的虛擬 IP 更改為選定的 Pod。當 Pod 啟動或關閉時,iptables 規則集會更新以反映集群不斷變化的狀態。換句話說,iptables 已經在機器上進行了負載平衡,以將定向到服務 IP 的流量轉移到實際 pod 的 IP。
在返回路徑上,IP 地址來自目標 Pod。在這種情況下,iptables 再次重寫 IP 標頭以將 Pod IP 替換為 Service 的 IP,以便 Pod 認為它一直只與 Service 的 IP 通信。
5.2、IPVS
Kubernetes 的最新版本 (1.11) 包括用于集群內負載平衡的第二個選項:IPVS。IPVS(IP 虛擬服務器)也構建在 netfilter 之上,并將傳輸層負載平衡作為 Linux 內核的一部分實現。IPVS 被合并到 LVS(Linux 虛擬服務器)中,它在主機上運行并充當真實服務器集群前面的負載平衡器。IPVS 可以將基于 TCP 和 UDP 的服務的請求定向到真實服務器,并使真實服務器的服務在單個 IP 地址上表現為虛擬服務。這使得 IPVS 非常適合 Kubernetes 服務。
聲明 Kubernetes Service時,您可以指定是否希望使用 iptables 或 IPVS 完成集群內負載平衡。IPVS 專為負載平衡而設計,并使用更高效的數據結構(哈希表),與 iptables 相比允許幾乎無限的規模。在使用 IPVS 創建負載均衡的 Service 時,會發生三件事:在 Node 上創建一個虛擬 IPVS 接口,將 Service 的 IP 地址綁定到虛擬 IPVS 接口,并為每個 Service IP 地址創建 IPVS 服務器。
未來,IPVS 有望成為集群內負載均衡的默認方法。此更改僅影響集群內負載平衡,并且在本指南的其余部分中,您可以安全地將 iptables 替換為 IPVS 以實現集群內負載平衡,而不會影響其余討論。現在讓我們看看通過集群內負載平衡服務的數據包的生命周期。
5.3、Pod和Service通信
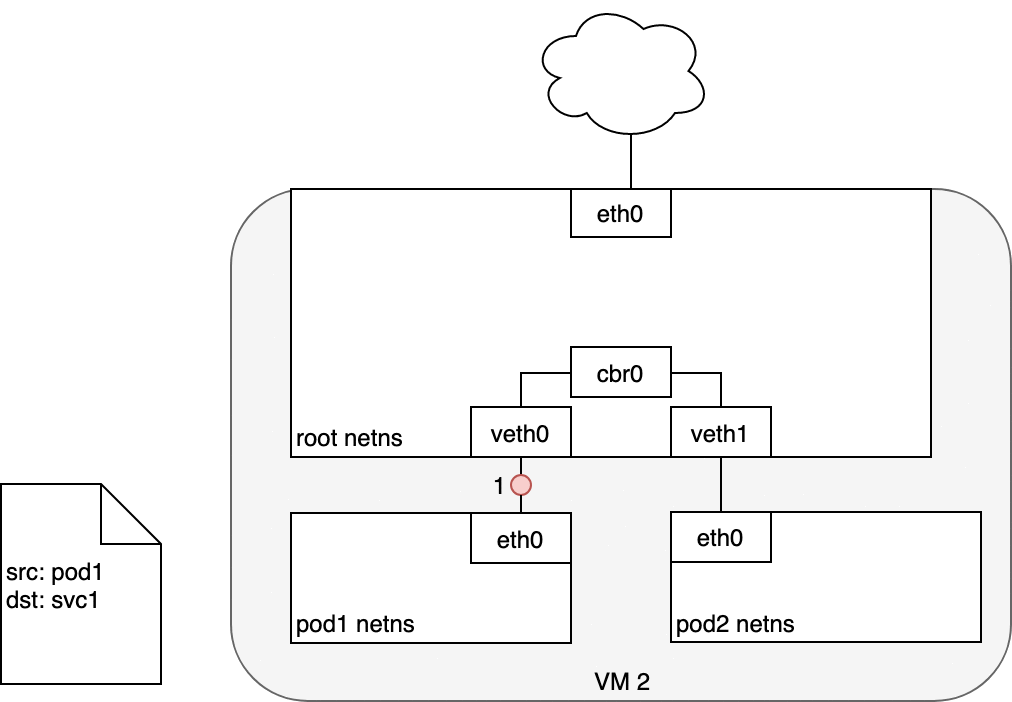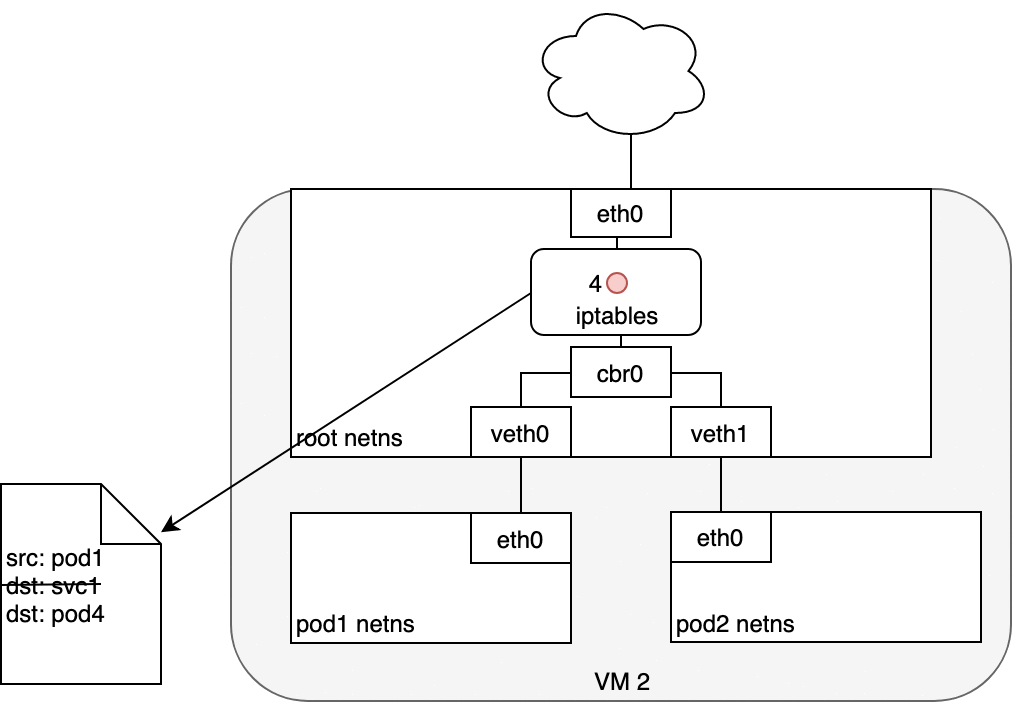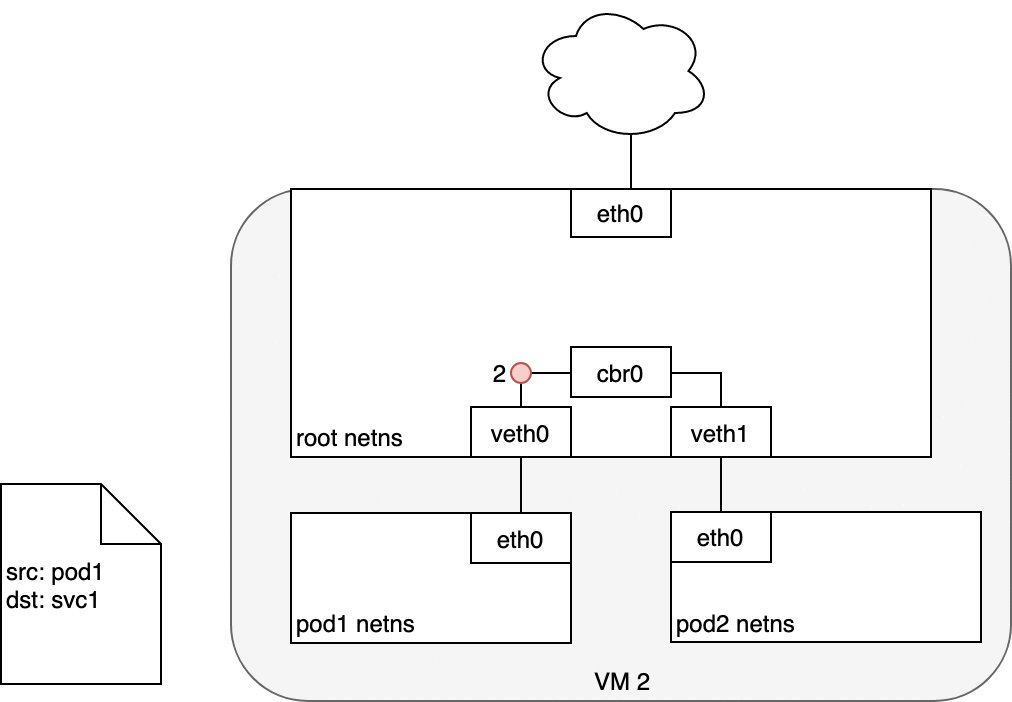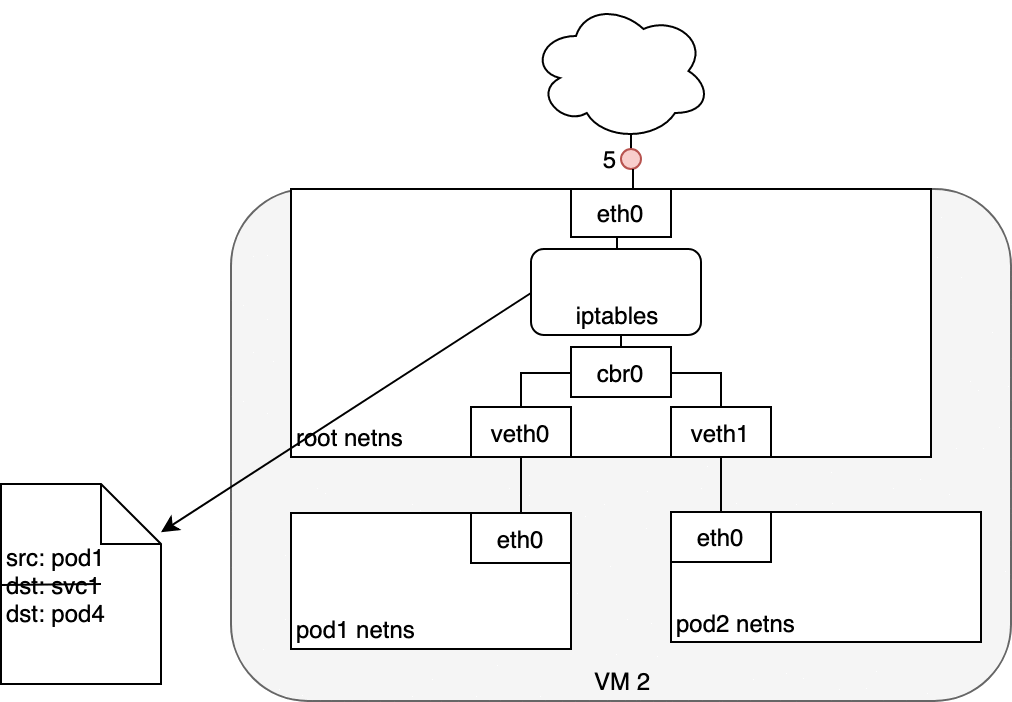 在 Pod 和 Service 之間路由數據包時,與以前相同的方式開始。數據包首先通過連接到 Pod 的網絡命名空間 (1) 的 eth0 接口離開 Pod。然后它通過虛擬以太網設備到達網橋 (2)。網橋上運行的 ARP 協議不知道 Service,因此它通過默認路由 eth0 (3) 將數據包傳輸出去。在這里,發生了一些不同的事情。在 eth0 接受之前,數據包會通過 iptables 過濾。iptables 收到數據包后,使用 kube-proxy 安裝在 Node 上的規則響應 Service 或 Pod 事件,將數據包的目的地從 Service IP 重寫為特定的 Pod IP(4)。數據包現在注定要到達 Pod 4,而不是服務的虛擬 IP。iptables 利用 Linux 內核的 conntrack 實用程序來記住所做的 Pod 選擇,以便將來的流量路由到同一個 Pod(除非發生任何擴展事件)。本質上,iptables 直接在 Node 上做了集群內負載均衡。然后流量使用我們已經檢查過的 Pod 到 Pod 路由流向 Pod (5)。
在 Pod 和 Service 之間路由數據包時,與以前相同的方式開始。數據包首先通過連接到 Pod 的網絡命名空間 (1) 的 eth0 接口離開 Pod。然后它通過虛擬以太網設備到達網橋 (2)。網橋上運行的 ARP 協議不知道 Service,因此它通過默認路由 eth0 (3) 將數據包傳輸出去。在這里,發生了一些不同的事情。在 eth0 接受之前,數據包會通過 iptables 過濾。iptables 收到數據包后,使用 kube-proxy 安裝在 Node 上的規則響應 Service 或 Pod 事件,將數據包的目的地從 Service IP 重寫為特定的 Pod IP(4)。數據包現在注定要到達 Pod 4,而不是服務的虛擬 IP。iptables 利用 Linux 內核的 conntrack 實用程序來記住所做的 Pod 選擇,以便將來的流量路由到同一個 Pod(除非發生任何擴展事件)。本質上,iptables 直接在 Node 上做了集群內負載均衡。然后流量使用我們已經檢查過的 Pod 到 Pod 路由流向 Pod (5)。
5.4、Service和Pod通信
 收到此數據包的 Pod 將響應,將源 IP 識別為自己的 IP,將目標 IP 識別為最初發送數據包的 Pod (1)。進入節點后,數據包流經 iptables,它使用 conntrack 記住它之前所做的選擇,并將數據包的源重寫為服務的 IP 而不是 Pod 的 IP (2)。從這里開始,數據包通過網橋流向與 Pod 的命名空間配對的虛擬以太網設備 (3),然后流向我們之前看到的 Pod 的以太網設備 (4)。
收到此數據包的 Pod 將響應,將源 IP 識別為自己的 IP,將目標 IP 識別為最初發送數據包的 Pod (1)。進入節點后,數據包流經 iptables,它使用 conntrack 記住它之前所做的選擇,并將數據包的源重寫為服務的 IP 而不是 Pod 的 IP (2)。從這里開始,數據包通過網橋流向與 Pod 的命名空間配對的虛擬以太網設備 (3),然后流向我們之前看到的 Pod 的以太網設備 (4)。
5.5、使用DNS
Kubernetes 可以選擇使用 DNS 來避免將服務的集群 IP 地址硬編碼到您的應用程序中。Kubernetes DNS 作為在集群上調度的常規 Kubernetes 服務運行。它配置在每個節點上運行的 kubelet,以便容器使用 DNS 服務的 IP 來解析 DNS 名稱。集群中定義的每個服務(包括 DNS 服務器本身)都被分配了一個 DNS 名稱。DNS 記錄將 DNS 名稱解析為服務的集群 IP 或 POD 的 IP,具體取決于您的需要。SRV 記錄用于指定運行服務的特定命名端口。
DNS Pod 由三個獨立的容器組成:
- kubedns:監視 Kubernetes 主服務器的服務和端點變化,并維護內存中的查找結構以服務 DNS 請求。
- dnsmasq:添加 DNS 緩存以提高性能。
- sidecar:提供一個單一的健康檢查端點來執行 dnsmasq 和 kubedns 的健康檢查。
DNS Pod 本身作為 Kubernetes 服務公開,具有靜態集群 IP,該 IP 在啟動時傳遞給每個正在運行的容器,以便每個容器都可以解析 DNS 條目。DNS 條目通過維護內存中 DNS 表示的 kubedns 系統解析。etcd 是集群狀態的后端存儲系統,kubedns 使用一個庫將 etcd 鍵值存儲轉換為 DNS 整體,以便在必要時重建內存中 DNS 查找結構的狀態。
CoreDNS 與 kubedns 的工作方式類似,但使用插件架構構建,使其更加靈活。從 Kubernetes 1.11 開始,CoreDNS 是 Kubernetes 的默認 DNS 實現。
6、Internet和Service之間網絡通信
到目前為止,我們已經了解了 Kubernetes 集群內的流量是如何轉發的。這一切都很好,但不幸的是,將您的應用程序與外界隔離無助于實現任何銷售目標——在某些時候,您可能希望將您的服務暴露給外部流量。這種需求突出了兩個相關的問題:(1)從 Kubernetes 服務獲取流量到 Internet。(2)從 Internet 獲取流量到您的 Kubernetes 服務。
6.1、Egress-將Kubernetes流量轉發到Internet
從節點到公共 Internet 的流量轉發是特定于網絡的,并且實際上取決于您的網絡如何配置以發布流量。為了使本節更加具體,我將使用 AWS VPC 來討論任何具體細節。
在 AWS 中,Kubernetes 集群在 VPC 中運行,其中每個節點都分配有一個私有 IP 地址,該地址可從 Kubernetes 集群內訪問。要從集群外部訪問流量,您需要將 Internet 網關連接到您的 VPC。Internet 網關有兩個用途:在您的 VPC 路由表中為可路由到 Internet 的流量提供目標,以及為已分配公共 IP 地址的任何實例執行網絡地址轉換 (NAT)。NAT 轉換負責將集群專用的節點內部 IP 地址更改為公共 Internet 中可用的外部 IP 地址。
有了 Internet 網關,VM 就可以自由地將流量路由到 Internet。不幸的是,有一個小問題。Pod 有自己的 IP 地址,與托管 Pod 的節點的 IP 地址不同,并且 Internet 網關的 NAT 轉換僅適用于 VM IP 地址,因為它不知道 Pod 正在運行什么哪些虛擬機——網關不支持容器。讓我們看看 Kubernetes 如何使用 iptables 解決這個問題(再次)。
6.1.1、Node和Internet通信
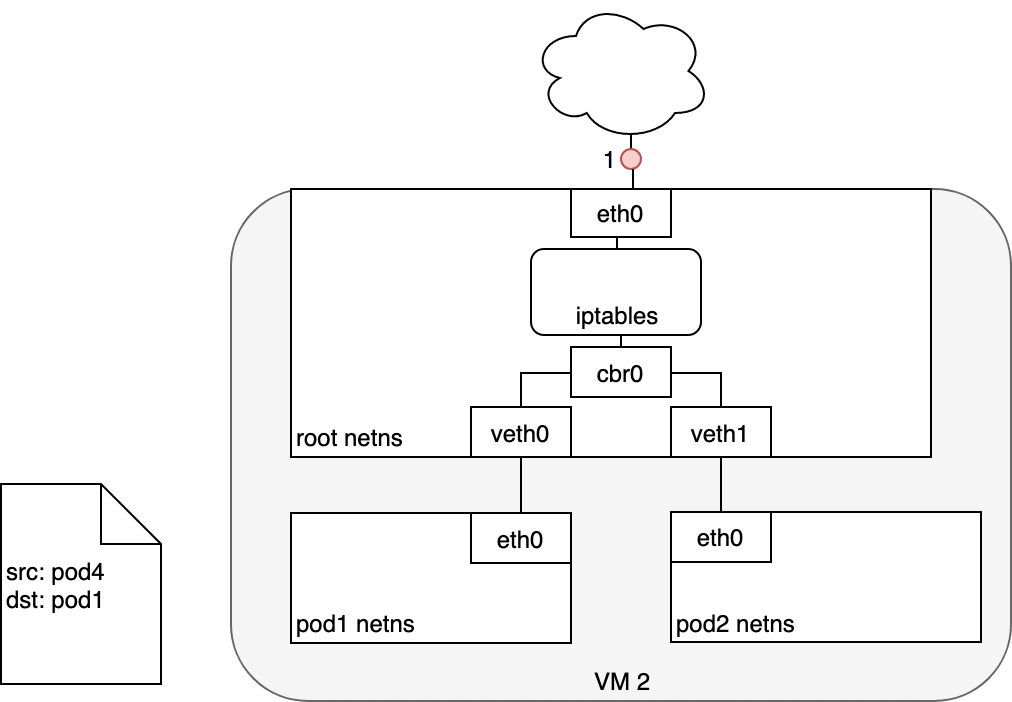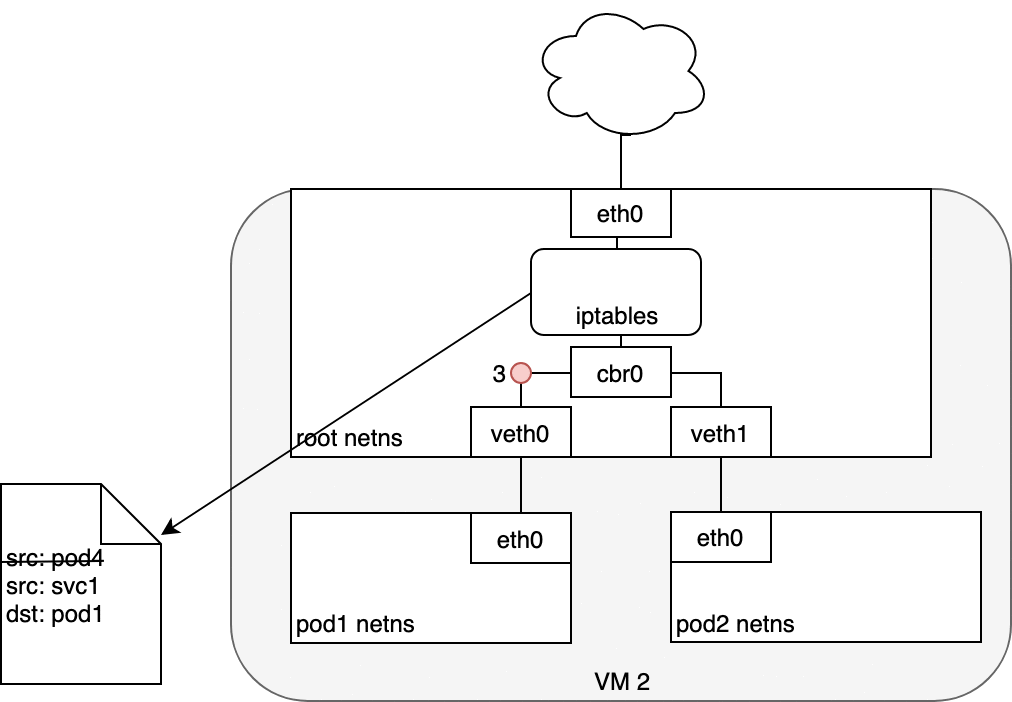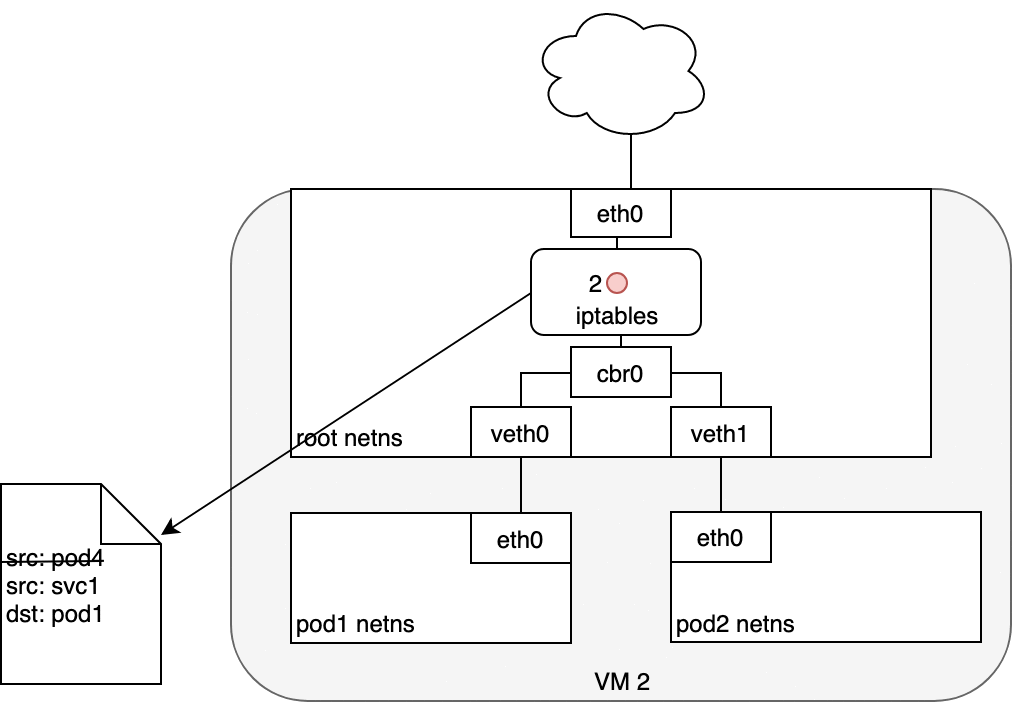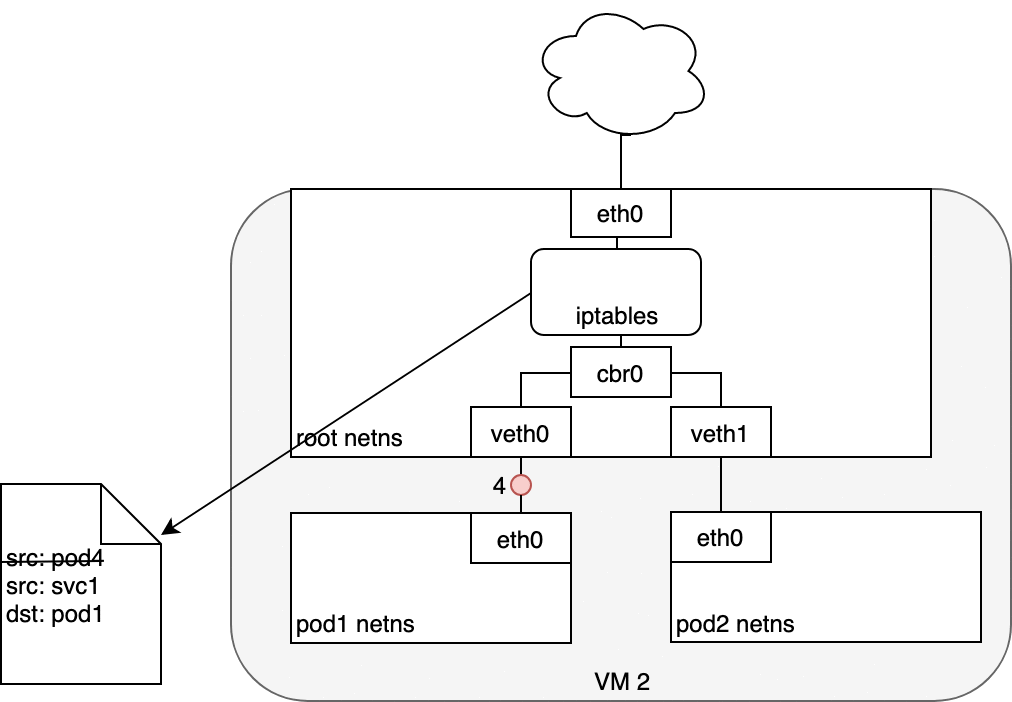
在下圖中,數據包源自 Pod 的命名空間 (1),并經過連接到根命名空間 (2) 的 veth 對。一旦進入根命名空間,數據包就會從網橋移動到默認設備,因為數據包上的 IP 與連接到網橋的任何網段都不匹配。在到達根命名空間的以太網設備 (3) 之前,iptables 會破壞數據包 (3)。在這種情況下,數據包的源 IP 地址是 Pod,如果我們將源保留為 Pod,Internet 網關將拒絕它,因為網關 NAT 只了解連接到 VM 的 IP 地址。解決方案是讓 iptables 執行源 NAT——更改數據包源——使數據包看起來來自 VM 而不是 Pod。有了正確的源 IP,數據包現在可以離開 VM (4) 并到達 Internet 網關 (5)。Internet 網關將執行另一個 NAT,將源 IP 從 VM 內部 IP 重寫為外部 IP。最后,數據包將到達公共 Internet (6)。在返回的路上,數據包遵循相同的路徑,并且任何源 IP 修改都被撤消,以便系統的每一層都接收到它理解的 IP 地址:節點或 VM 級別的 VM 內部,以及 Pod 內的 Pod IP命名空間。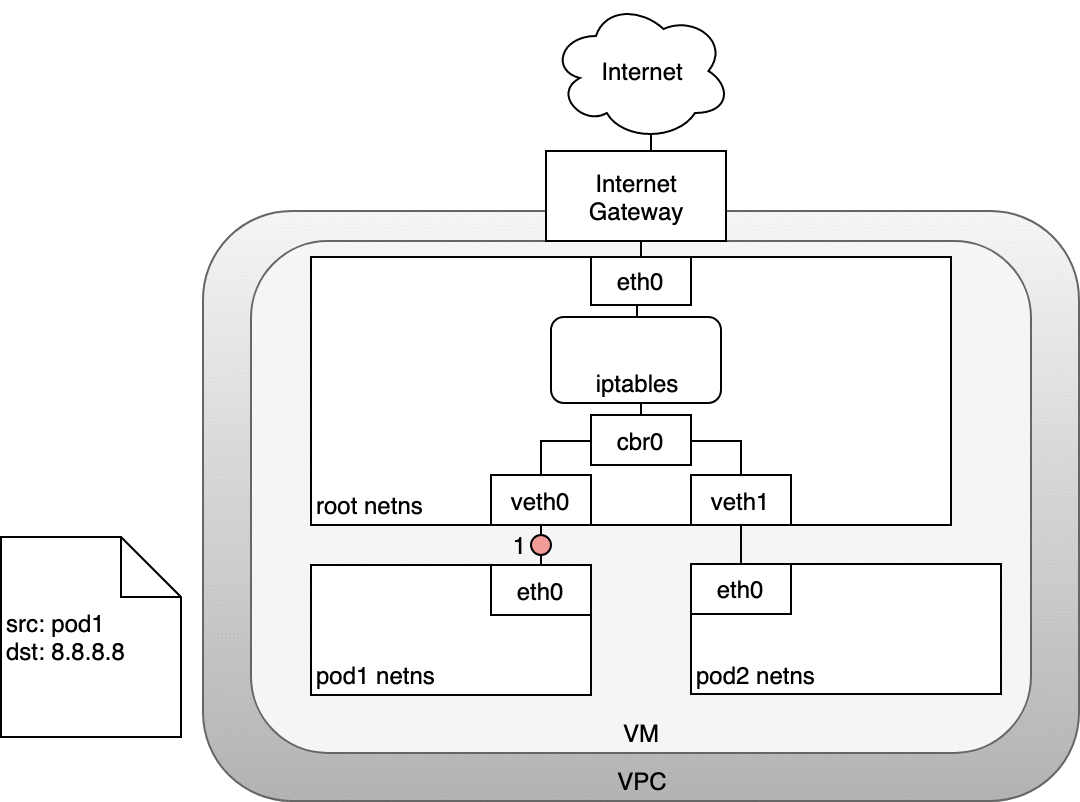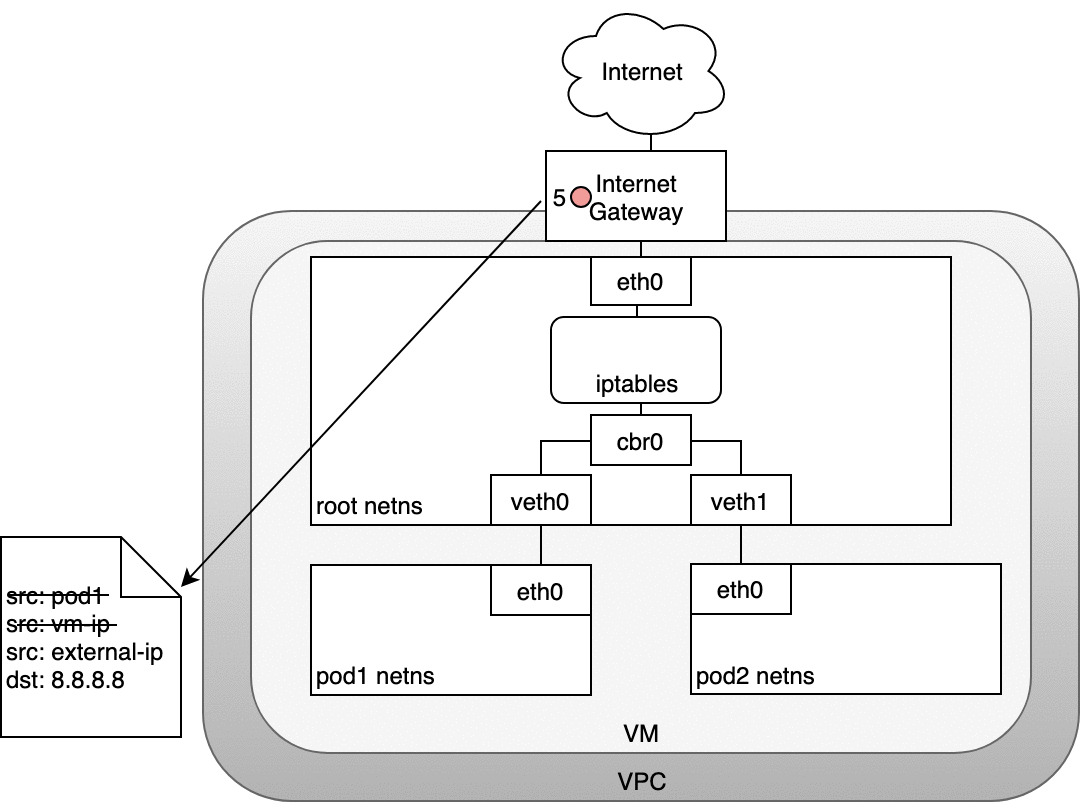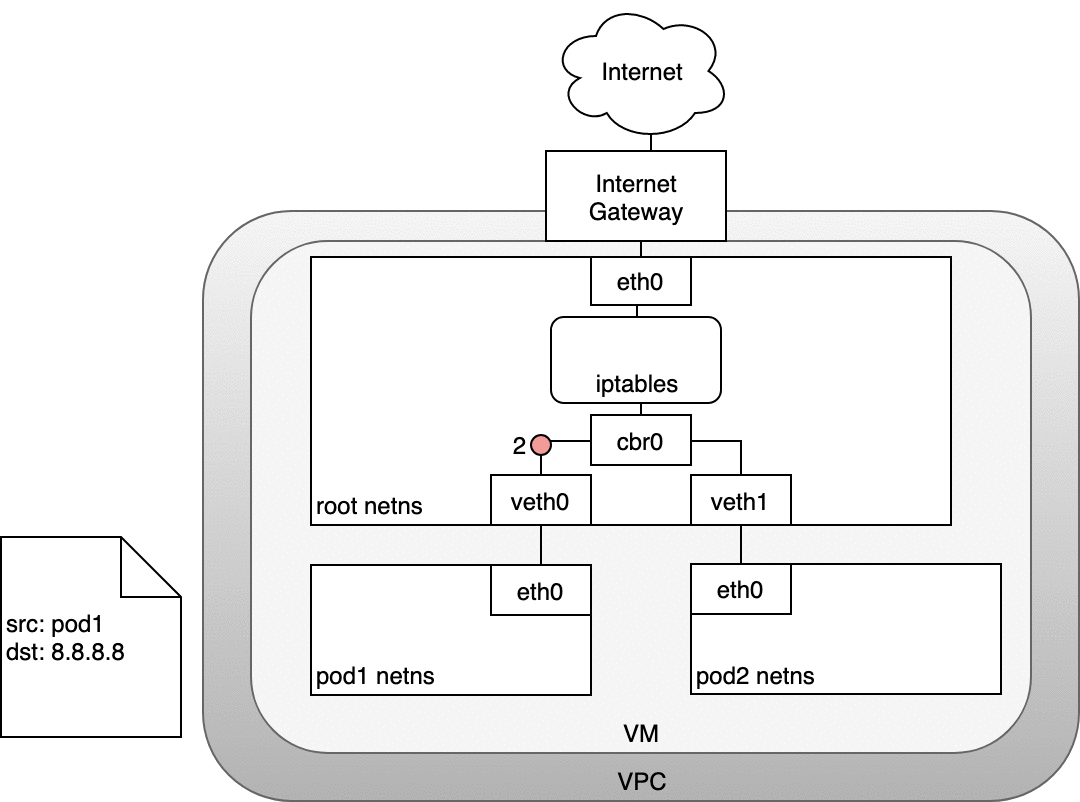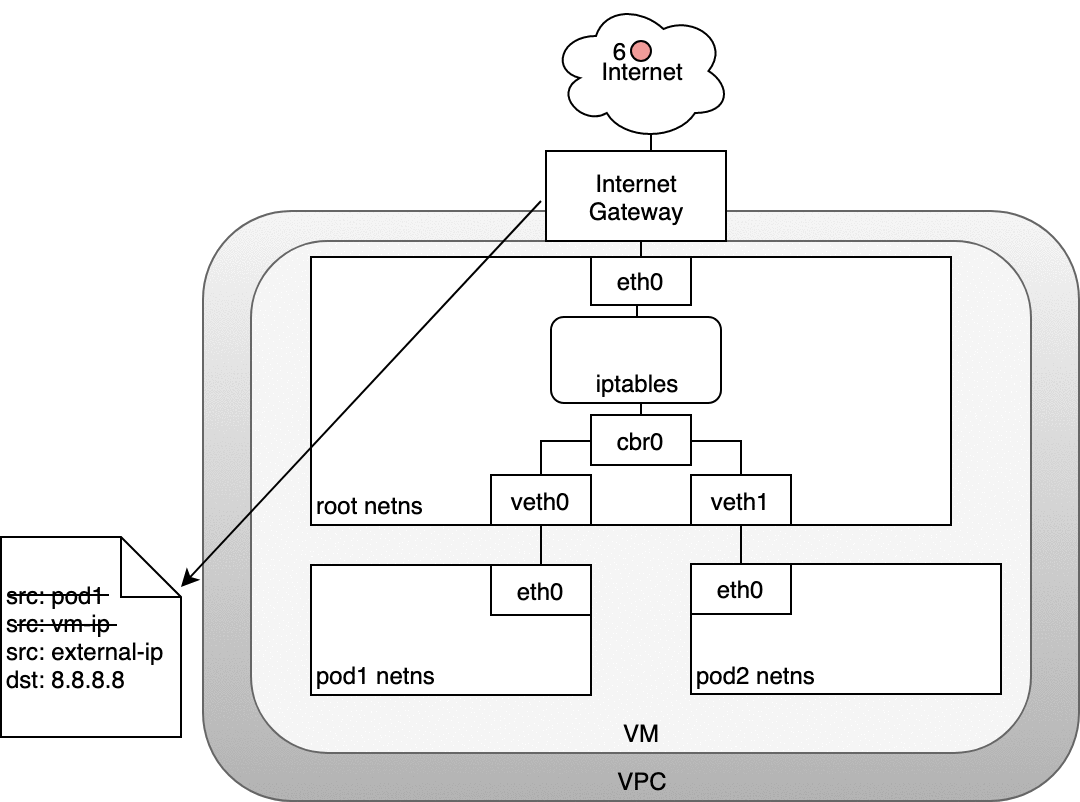
6.2、Ingress-將Internet流量轉發到Kubernetes
入口——讓流量進入你的集群——是一個非常難以解決的問題。同樣,這是特定于您正在運行的網絡的,但一般來說,Ingress 分為兩種解決方案,適用于網絡堆棧的不同部分:(1) 服務負載平衡器和 (2) 入口控制器
6.2.1、四層轉發-Loadbalancer
當你創建一個 Kubernetes 服務時,你可以選擇指定一個 LoadBalancer 來配合它。LoadBalancer 的實現由知道如何為您的服務創建負載均衡器的云控制器提供。創建服務后,它將公布負載均衡器的 IP 地址。作為最終用戶,您可以開始將流量引導到負載均衡器以開始與您的服務通信。
借助 AWS,負載均衡器可以了解其目標組中的節點,并將平衡集群中所有節點的流量。一旦流量到達一個節點,之前為您的服務在整個集群中安裝的 iptables 規則將確保流量到達您感興趣的服務的 Pod。
6.2.2、Loadbalancer和Service通信
讓我們看看這在實踐中是如何工作的。部署服務后,您正在使用的云提供商將為您創建一個新的負載均衡器 (1)。因為負載均衡器不支持容器,所以一旦流量到達負載均衡器,它就會分布在組成集群的所有虛擬機中 (2)。每個 VM 上的 iptables 規則會將來自負載均衡器的傳入流量引導到正確的 Pod (3) — 這些是在服務創建期間實施并在前面討論過的相同 IP 表規則。Pod 到客戶端的響應將返回 Pod 的 IP,但客戶端需要有負載均衡器的 IP 地址。正如我們之前看到的,iptables 和 conntrack 用于在返回路徑上正確重寫 IP。
下圖顯示了托管 Pod 的三個 VM 前面的網絡負載均衡器。傳入流量 (1) 指向您的服務的負載均衡器。一旦負載均衡器收到數據包 (2),它就會隨機選擇一個 VM。在這種情況下,我們病態地選擇了沒有運行 Pod 的 VM:VM 2 (3)。在這里,運行在 VM 上的 iptables 規則將使用 kube-proxy 安裝到集群中的內部負載平衡規則將數據包定向到正確的 Pod。iptables 執行正確的 NAT 并將數據包轉發到正確的 Pod (4)。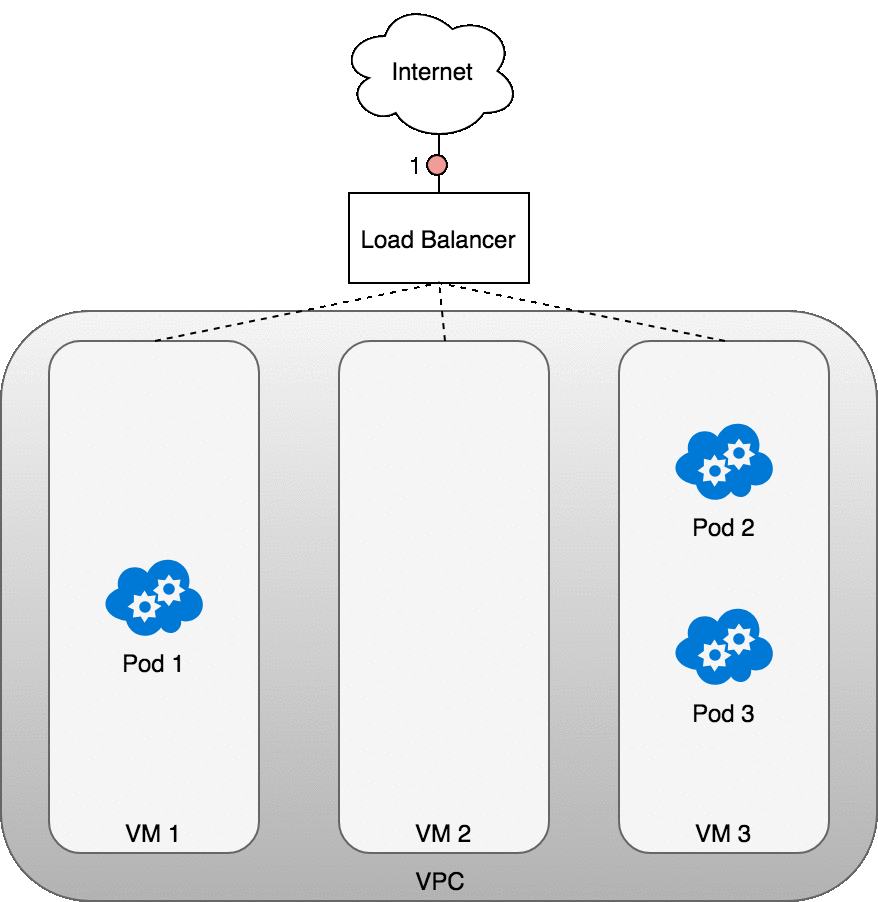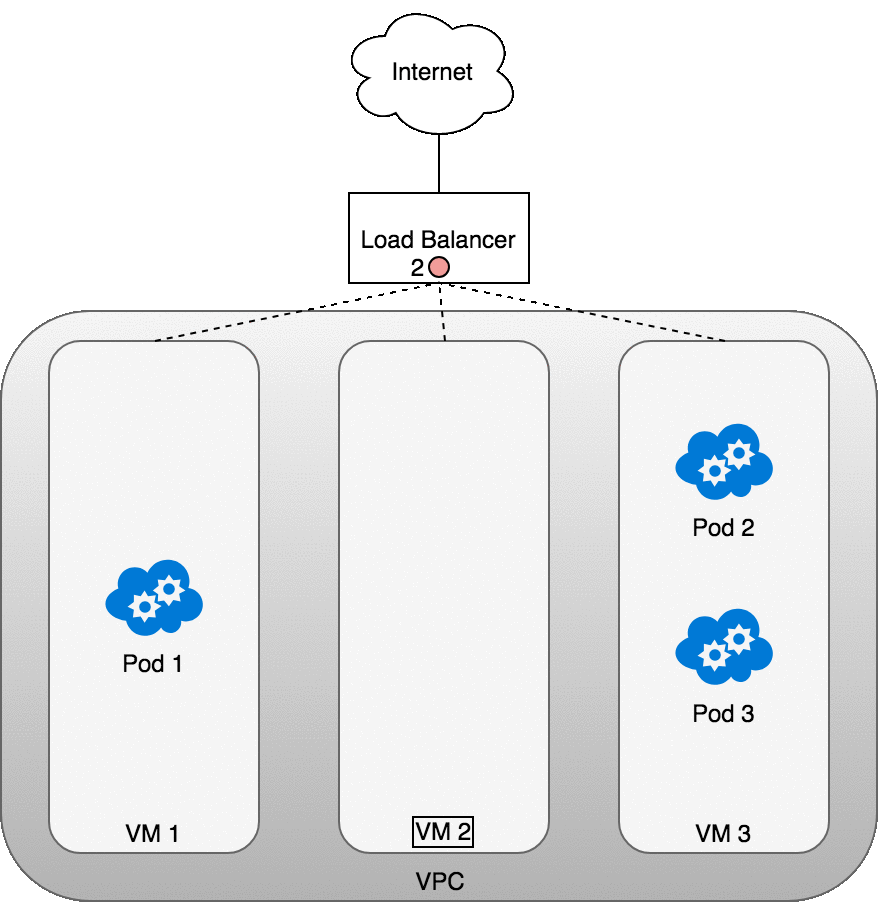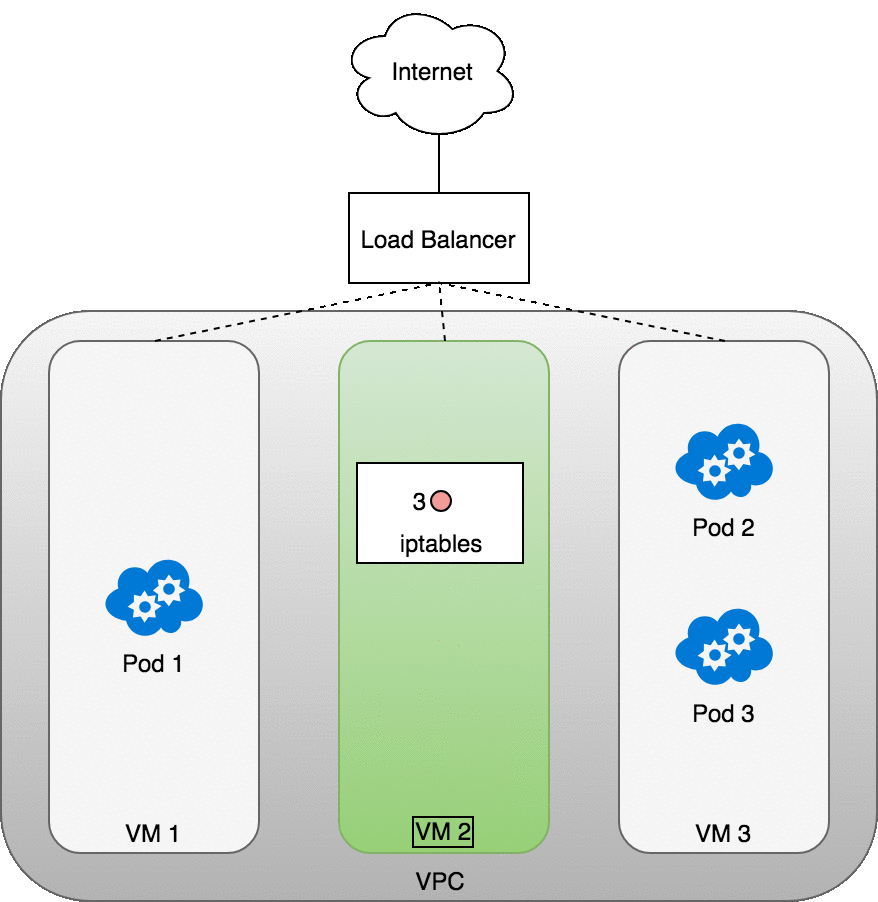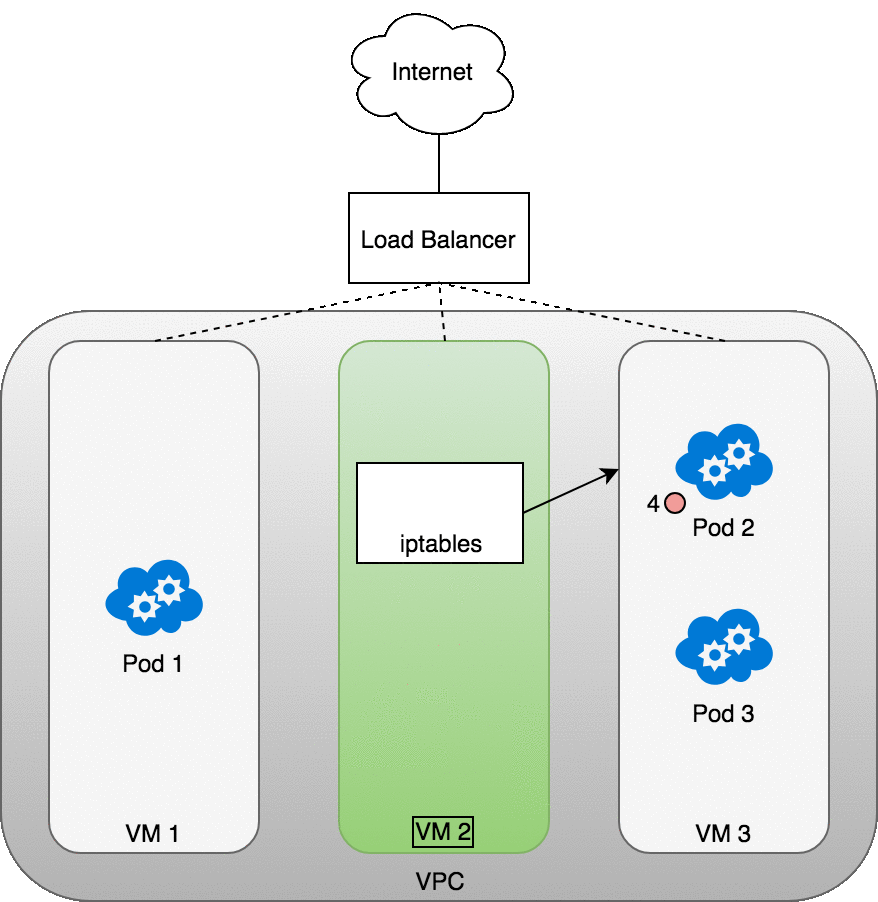
6.2.3、七層轉發-Ingress Controller
第 7 層網絡 Ingress 在網絡堆棧的 HTTP/HTTPS 協議范圍內運行,并構建在 Services 之上。啟用 Ingress 的第一步是使用 Kubernetes 中的 NodePort 服務類型在您的服務上打開一個端口。如果將 Service 的 type 字段設置為 NodePort,Kubernetes master 將從您指定的范圍內分配一個端口,并且每個 Node 都會將該端口(每個 Node 上的相同端口號)代理到您的 Service 中。也就是說,任何指向節點端口的流量都將使用 iptables 規則轉發到服務。這個 Service 到 Pod 的路由遵循我們在將流量從 Service 路由到 Pod 時已經討論過的相同的內部集群負載平衡模式。
要向 Internet 公開節點的端口,您需要使用 Ingress 對象。Ingress 是一個更高級別的 HTTP 負載均衡器,它將 HTTP 請求映射到 Kubernetes 服務。Ingress 方法將根據 Kubernetes 云提供商控制器的實現方式而有所不同。HTTP 負載均衡器,如第 4 層網絡負載均衡器,僅了解節點 IP(而不是 Pod IP),因此流量路由同樣利用由 kube-proxy 安裝在每個節點上的 iptables 規則提供的內部負載均衡。
在 AWS 環境中,ALB 入口控制器使用 Amazon 的第 7 層應用程序負載均衡器提供 Kubernetes 入口。下圖詳細介紹了此控制器創建的 AWS 組件。它還演示了 Ingress 流量從 ALB 到 Kubernetes 集群的路由。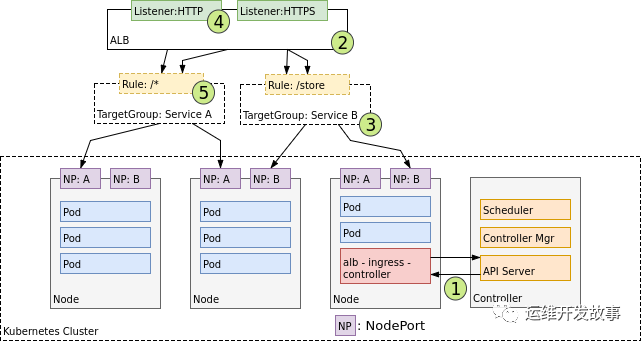
創建后,(1) Ingress Controller 監視來自 Kubernetes API 服務器的 Ingress 事件。當它找到滿足其要求的 Ingress 資源時,它會開始創建 AWS 資源。AWS 將 Application Load Balancer (ALB) (2) 用于 Ingress 資源。負載均衡器與用于將請求路由到一個或多個注冊節點的目標組一起工作。(3) 在 AWS 中為 Ingress 資源描述的每個唯一 Kubernetes 服務創建目標組。(4) Listener 是一個 ALB 進程,它使用您配置的協議和端口檢查連接請求。偵聽器由 Ingress 控制器為您的 Ingress 資源注釋中詳述的每個端口創建。最后,為 Ingress 資源中指定的每個路徑創建目標組規則。這確保了到特定路徑的流量被路由到正確的 Kubernetes 服務 (5)。
6.2.4、Ingress和Service通信
流經 Ingress 的數據包的生命周期與 LoadBalancer 的生命周期非常相似。主要區別在于 Ingress 知道 URL 的路徑(允許并可以根據路徑將流量路由到服務),并且 Ingress 和 Node 之間的初始連接是通過 Node 上為每個服務公開的端口。
讓我們看看這在實踐中是如何工作的。部署服務后,您正在使用的云提供商將為您創建一個新的 Ingress 負載均衡器 (1)。由于負載均衡器不支持容器,因此一旦流量到達負載均衡器,它就會通過為您的服務提供的廣告端口分布在組成集群 (2) 的整個 VM 中。每個 VM 上的 iptables 規則會將來自負載均衡器的傳入流量引導到正確的 Pod (3) — 正如我們之前所見。Pod 到客戶端的響應將返回 Pod 的 IP,但客戶端需要有負載均衡器的 IP 地址。正如我們之前看到的,iptables 和 conntrack 用于在返回路徑上正確重寫 IP。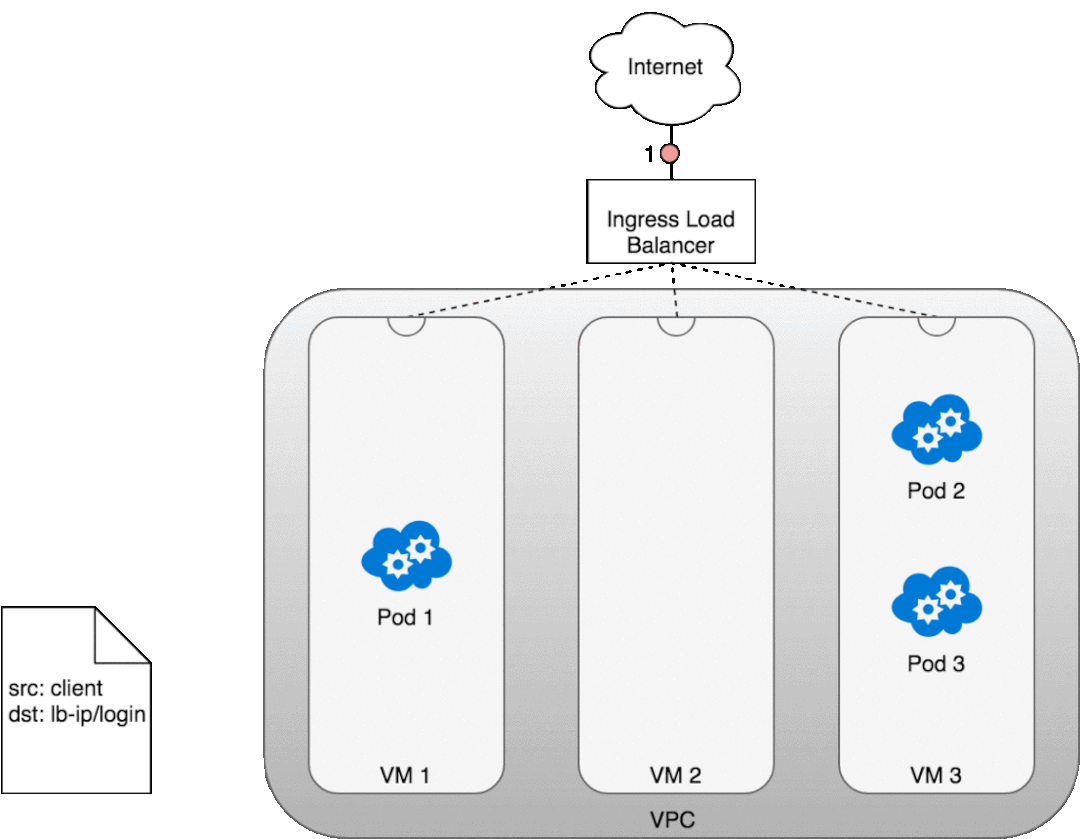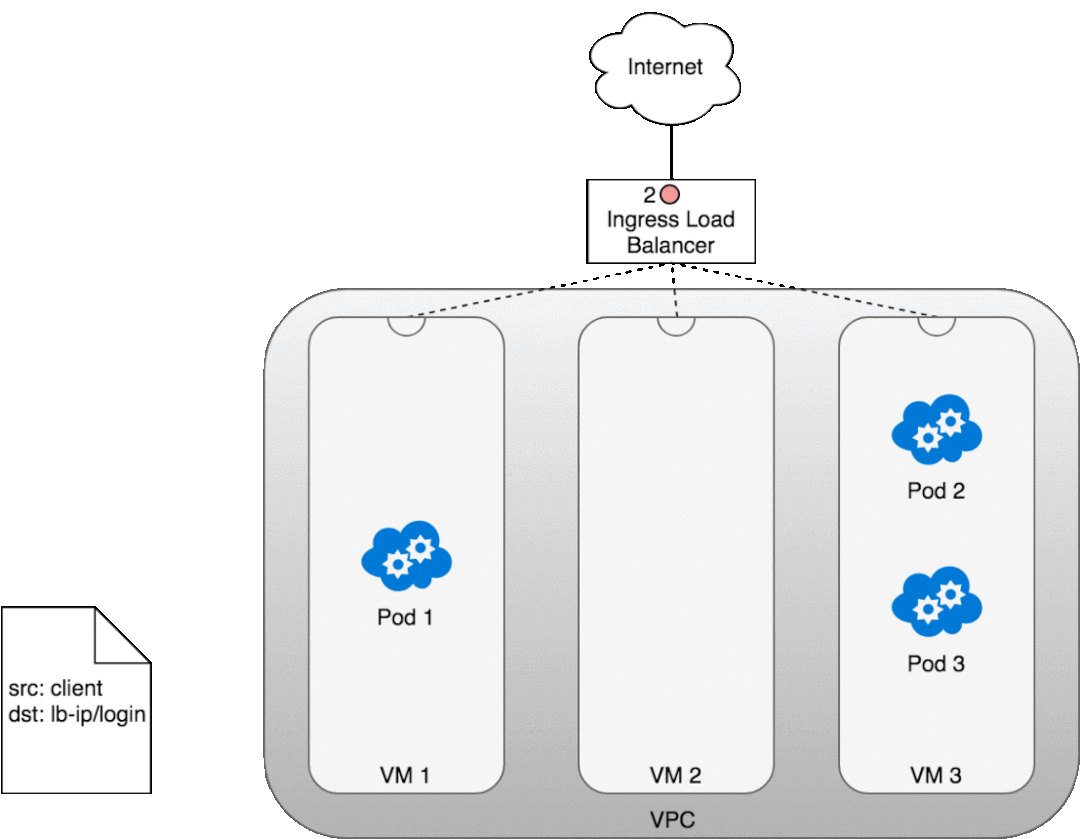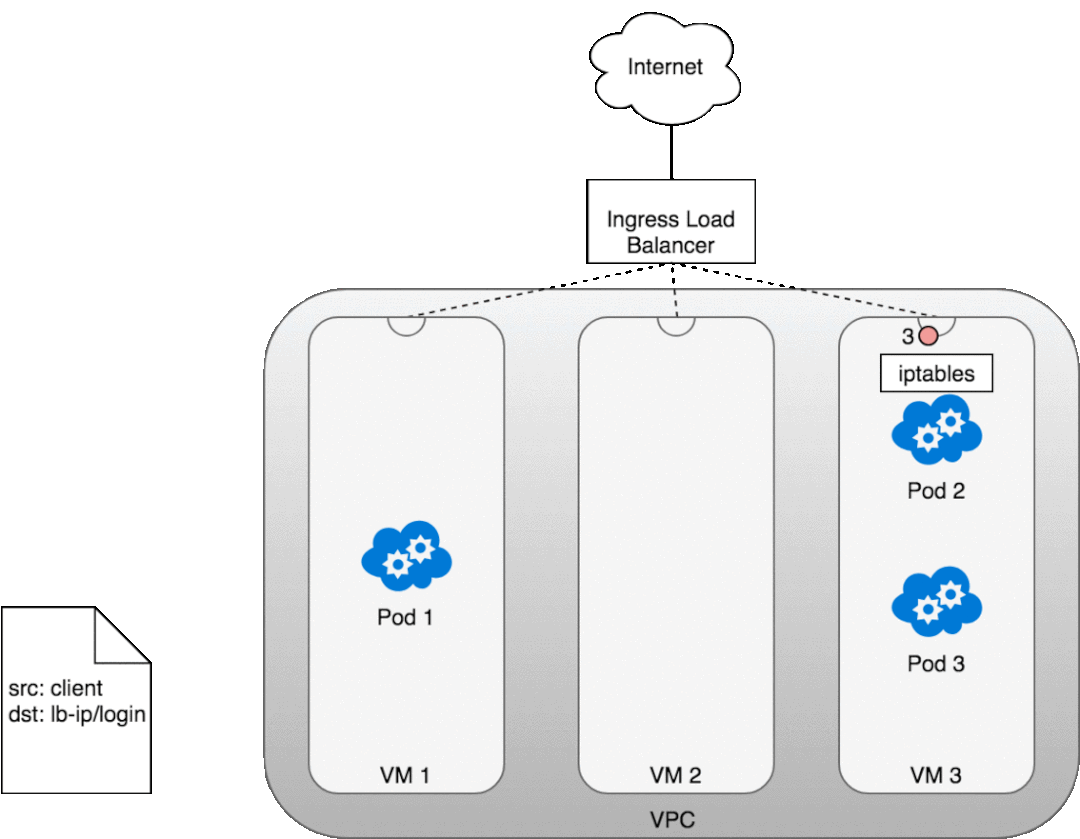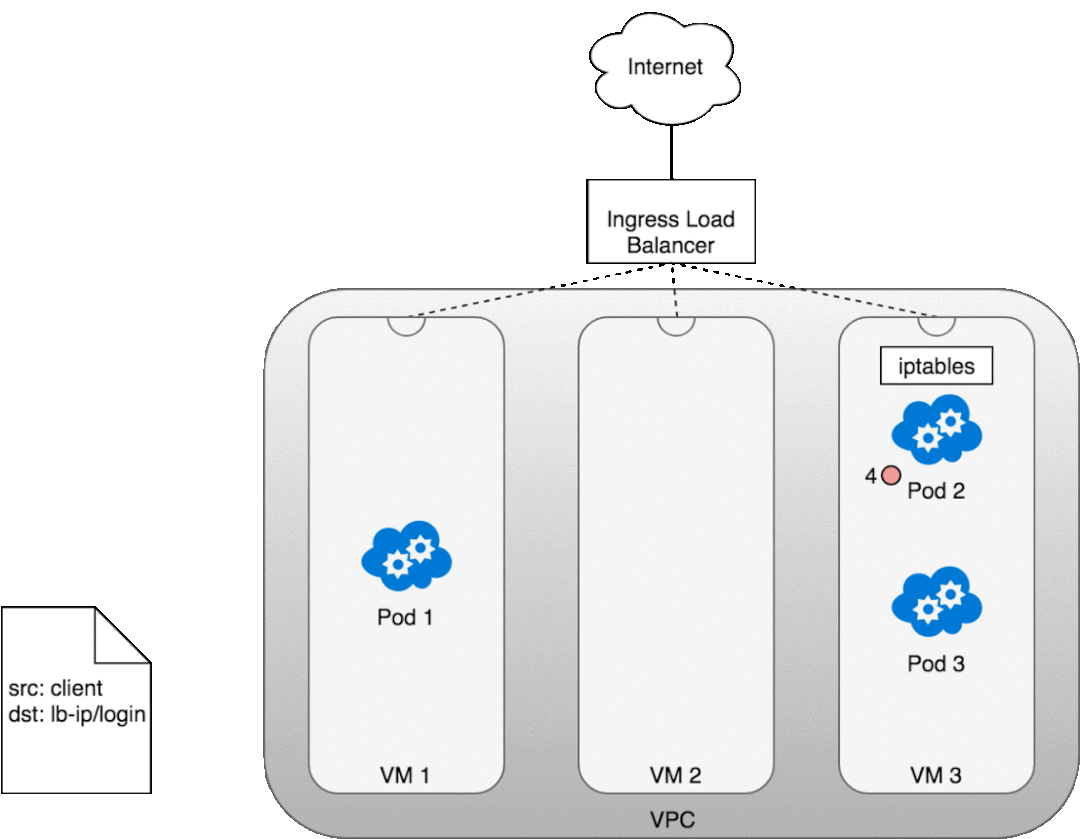
第 7 層負載均衡器的一個好處是它們可以識別 HTTP,因此它們知道 URL 和路徑。這使您可以按 URL 路徑對服務流量進行分段。它們通常還在 HTTP 請求的 X-Forwarded-For 標頭中提供原始客戶端的 IP 地址。
7、總結
本指南為理解 Kubernetes 網絡模型以及它如何支持常見的網絡任務奠定了基礎。網絡領域既廣泛又深入,不可能在這里涵蓋所有內容。本指南應為您提供深入了解您感興趣并想了解更多主題的起點。每當您遇到困難時,請利用 Kubernetes 文檔和 Kubernetes 社區來幫助您找到自己的方式。
8、網絡術語
Kubernetes 依賴于幾種現有技術來構建一個正常運行的集群。全面探索這些技術中的每一個超出了本指南的范圍,但本節將詳細描述這些技術中的每一個,以便進行討論。如果您感到困惑或需要復習,您可以隨意略讀本節,完全跳過它,或者根據需要參考它。
二層網絡
第 2 層是提供節點到節點數據傳輸的數據鏈路層。它定義了在兩個物理連接的設備之間建立和終止連接的協議。它還定義了它們之間的流量控制協議。
四層網絡
傳輸層通過流量控制控制給定鏈路的可靠性。在 TCP/IP 中,這一層是指用于在不可靠網絡上交換數據的 TCP 協議。
七層網絡
應用層是最接近最終用戶的層,這意味著應用層和用戶都直接與軟件應用程序交互。該層與實現通信組件的軟件應用程序交互。通常,第 7 層網絡是指 HTTP。
Nat網絡地址轉換
NAT 或網絡地址轉換是將一個地址空間重新映射到另一個地址空間的 IP 級別。映射通過在數據包通過流量路由設備傳輸時修改數據包的 IP 標頭中的網絡地址信息來實現。
基本 NAT 是從一個 IP 地址到另一個 IP 地址的簡單映射。更常見的是,NAT 用于將多個私有 IP 地址映射到一個公開的 IP 地址。通常,本地網絡使用私有 IP 地址空間,并且該網絡上的路由器在該空間中被賦予私有地址。然后路由器使用公共 IP 地址連接到 Internet。當流量從本地網絡傳遞到 Internet 時,每個數據包的源地址都從私有地址轉換為公共地址,這使得請求看起來好像直接來自路由器。路由器維護連接跟蹤,以將回復轉發到本地網絡上的正確專用 IP。
NAT 提供了一個額外的好處,即允許大型專用網絡使用單個公共 IP 地址連接到 Internet,從而節省公共使用的 IP 地址的數量。
snat-源地址轉換
SNAT 只是指修改 IP 數據包源地址的 NAT 過程。這是上述 NAT 的典型行為。
dnat-目標地址轉換
DNAT 是指修改 IP 數據包的目的地址的 NAT 過程。DNAT 用于將位于專用網絡中的服務發布到可公開尋址的 IP 地址。
網絡名稱空間
在網絡中,每臺機器(真實的或虛擬的)都有一個以太網設備(我們將其稱為 eth0)。所有流入和流出機器的流量都與該設備相關聯。事實上,Linux 將每個以太網設備與一個網絡命名空間相關聯——整個網絡堆棧的邏輯副本,以及它自己的路由、防火墻規則和網絡設備。最初,所有進程共享來自 init 進程的相同默認網絡命名空間,稱為根命名空間。默認情況下,進程從其父進程繼承其網絡命名空間,因此,如果您不進行任何更改,所有網絡流量都會流經為根網絡命名空間指定的以太網設備。
veth虛擬網卡對
計算機系統通常由一個或多個網絡設備(eth0、eth1 等)組成,這些設備與負責將數據包放置到物理線路上的物理網絡適配器相關聯。Veth 設備是虛擬網絡設備,始終以互連的對創建。它們可以充當網絡命名空間之間的隧道,以創建到另一個命名空間中的物理網絡設備的橋接,但也可以用作獨立的網絡設備。您可以將 veth 設備視為設備之間的虛擬跳線——一端連接的設備將連接另一端。
網絡橋接
網橋是從多個通信網絡或網段創建單個聚合網絡的設備。橋接連接兩個獨立的網絡,就好像它們是一個網絡一樣。橋接使用內部數據結構來記錄每個數據包發送到的位置,以作為性能優化。
CIDR
CIDR 是一種分配 IP 地址和執行 IP 路由的方法。對于 CIDR,IP 地址由兩組組成:網絡前綴(標識整個網絡或子網)和主機標識符(指定該網絡或子網上的主機的特定接口)。CIDR 使用 CIDR 表示法表示 IP 地址,其中地址或路由前綴寫有表示前綴位數的后綴,例如 IPv4 的 192.0.2.0/24。IP 地址是 CIDR 塊的一部分,如果地址的初始 n 位和 CIDR 前綴相同,則稱其屬于 CIDR 塊。
CNI
CNI(容器網絡接口)是一個云原生計算基金會項目,由規范和庫組成,用于編寫插件以在 Linux 容器中配置網絡接口。CNI 只關心容器的網絡連接以及在容器被刪除時移除分配的資源。
VIP地址
虛擬 IP 地址或 VIP 是軟件定義的 IP 地址,與實際的物理網絡接口不對應。
netfilter
netfilter 是 Linux 中的包過濾框架。實現此框架的軟件負責數據包過濾、網絡地址轉換 (NAT) 和其他數據包處理。
netfilter、ip_tables、連接跟蹤(ip_conntrack、nf_conntrack)和NAT子系統共同構建了框架的主要部分。
iptables
iptables 是一個允許 Linux 系統管理員配置 netfilter 及其存儲的鏈和規則的程序。IP 表中的每條規則都由許多分類器(iptables 匹配)和一個連接的操作(iptables 目標)組成。
conntrack
conntrack 是建立在 Netfilter 框架之上的用于處理連接跟蹤的工具。連接跟蹤允許內核跟蹤所有邏輯網絡連接或會話,并將每個連接或會話的數據包定向到正確的發送者或接收者。NAT 依靠此信息以相同的方式翻譯所有相關數據包,并且 iptables 可以使用此信息充當狀態防火墻。
IPVS
IPVS 將傳輸層負載平衡作為 Linux 內核的一部分來實現。
IPVS 是一個類似于 iptables 的工具。它基于 Linux 內核的 netfilter 鉤子函數,但使用哈希表作為底層數據結構。這意味著,與 iptables 相比,IPVS 重定向流量更快,在同步代理規則時具有更好的性能,并提供更多的負載平衡算法。
DNS
域名系統 (DNS) 是一個分散的命名系統,用于將系統名稱與 IP 地址相關聯。它將域名轉換為用于定位計算機服務的數字 IP 地址。
-
網絡模型
+關注
關注
0文章
44瀏覽量
8425 -
kubernetes
+關注
關注
0文章
224瀏覽量
8712
原文標題:8、網絡術語
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論