


人體活動(dòng)識(shí)別(HAR)是一種使用人工智能(AI)從智能手表等活動(dòng)記錄設(shè)備產(chǎn)生的原始數(shù)據(jù)中識(shí)別人類活動(dòng)的方法。當(dāng)人們執(zhí)行某種動(dòng)作時(shí),人們佩戴的傳感器(智能手表、手環(huán)、專用設(shè)備等)就會(huì)產(chǎn)生信號(hào)。這些收集信息的傳感器包括加速度計(jì)、陀螺儀和磁力計(jì)。人類活動(dòng)識(shí)別有各種各樣的應(yīng)用,從為病人和殘疾人提供幫助到像游戲這樣嚴(yán)重依賴于分析運(yùn)動(dòng)技能的領(lǐng)域。我們可以將這些人類活動(dòng)識(shí)別技術(shù)大致分為兩類:固定傳感器和移動(dòng)傳感器。在本文中,我們使用移動(dòng)傳感器產(chǎn)生的原始數(shù)據(jù)來(lái)識(shí)別人類活動(dòng)。 
在本文中,我將使用LSTM (Long - term Memory)和CNN (Convolutional Neural Network)來(lái)識(shí)別下面的人類活動(dòng):
下樓
上樓
跑步
坐著
站立
步行
概述
你可能會(huì)考慮為什么我們要使用LSTM-CNN模型而不是基本的機(jī)器學(xué)習(xí)方法? 機(jī)器學(xué)習(xí)方法在很大程度上依賴于啟發(fā)式手動(dòng)特征提取人類活動(dòng)識(shí)別任務(wù),而我們這里需要做的是端到端的學(xué)習(xí),簡(jiǎn)化了啟發(fā)式手動(dòng)提取特征的操作。  ? 我將要使用的模型是一個(gè)深神經(jīng)網(wǎng)絡(luò),該網(wǎng)絡(luò)是LSTM和CNN的組合形成的,并且具有提取活動(dòng)特征和僅使用模型參數(shù)進(jìn)行分類的能力。 ? 這里我們使用WISDM數(shù)據(jù)集,總計(jì)1.098.209樣本。通過我們的訓(xùn)練,模型的F1得分為0.96,在測(cè)試集上,F(xiàn)1得分為0.89。 ?
? 我將要使用的模型是一個(gè)深神經(jīng)網(wǎng)絡(luò),該網(wǎng)絡(luò)是LSTM和CNN的組合形成的,并且具有提取活動(dòng)特征和僅使用模型參數(shù)進(jìn)行分類的能力。 ? 這里我們使用WISDM數(shù)據(jù)集,總計(jì)1.098.209樣本。通過我們的訓(xùn)練,模型的F1得分為0.96,在測(cè)試集上,F(xiàn)1得分為0.89。 ?
導(dǎo)入庫(kù)
首先,我們將導(dǎo)入我們將需要的所有必要庫(kù)。
from pandas import read_csv, unique import numpy as np from scipy.interpolate import interp1dfrom scipy.stats import mode from sklearn.preprocessing import LabelEncoderfrom sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay from tensorflow import stackfrom tensorflow.keras.utils import to_categoricalfrom keras.models import Sequentialfrom keras.layers import Dense, GlobalAveragePooling1D, BatchNormalization, MaxPool1D, Reshape, Activationfrom keras.layers import Conv1D, LSTMfrom keras.callbacks import ModelCheckpoint, EarlyStoppingimport matplotlib.pyplot as plt%matplotlib inline import warningswarnings.filterwarnings("ignore")我們將使用Sklearn,Tensorflow,Keras,Scipy和Numpy來(lái)構(gòu)建模型和進(jìn)行數(shù)據(jù)預(yù)處理。使用PANDAS 進(jìn)行數(shù)據(jù)加載,使用matplotlib進(jìn)行數(shù)據(jù)可視化。
數(shù)據(jù)集加載和可視化
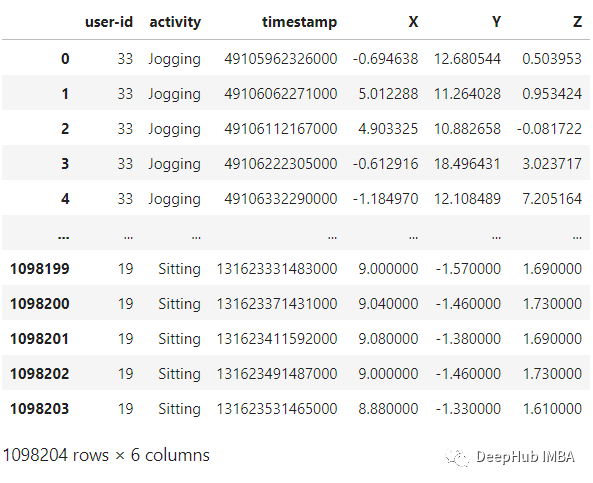
WISDM是由個(gè)人腰間攜帶的移動(dòng)設(shè)備上的加速計(jì)記錄下來(lái)。該數(shù)據(jù)收集是由個(gè)人監(jiān)督的可以確保數(shù)據(jù)的質(zhì)量。我們將使用的文件是WISDM_AR_V1.1_RAW.TXT。使用PANDAS,可以將數(shù)據(jù)集加載到DataAframe中,如下面代碼:
def read_data(filepath): df = read_csv(filepath, header=None, names=['user-id', 'activity', 'timestamp', 'X', 'Y', 'Z']) ## removing ';' from last column and converting it to float df['Z'].replace(regex=True, inplace=True, to_replace=r';', value=r'') df['Z'] = df['Z'].apply(convert_to_float) return df
def convert_to_float(x): try: return np.float64(x) except: return np.nan
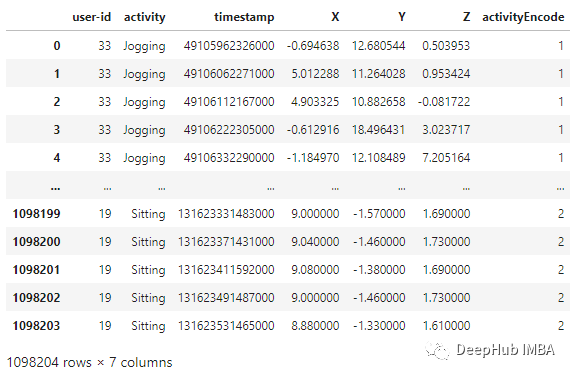
df = read_data('Dataset/WISDM_ar_v1.1/WISDM_ar_v1.1_raw.txt')df
plt.figure(figsize=(15, 5))
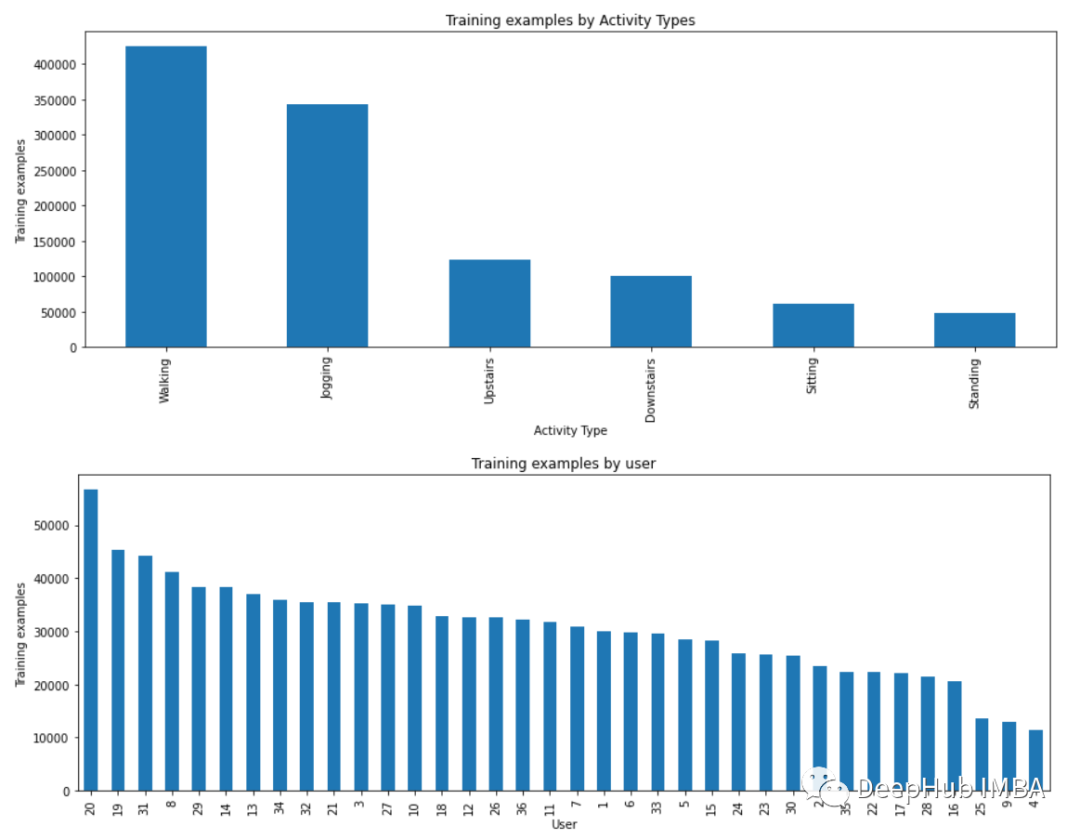
plt.xlabel('Activity Type')plt.ylabel('Training examples')df['activity'].value_counts().plot(kind='bar', title='Training examples by Activity Types')plt.show()
plt.figure(figsize=(15, 5))plt.xlabel('User')plt.ylabel('Training examples')df['user-id'].value_counts().plot(kind='bar', title='Training examples by user')plt.show()
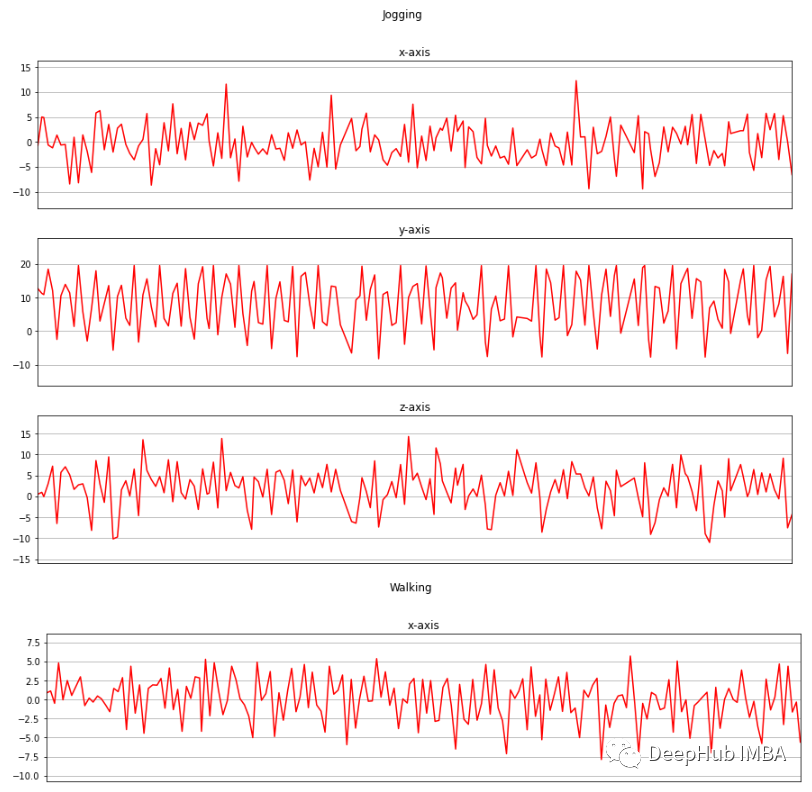
 ? 現(xiàn)在我將收集的三個(gè)軸上的加速度計(jì)數(shù)據(jù)進(jìn)行可視化。 ?
? 現(xiàn)在我將收集的三個(gè)軸上的加速度計(jì)數(shù)據(jù)進(jìn)行可視化。 ?
def axis_plot(ax, x, y, title): ax.plot(x, y, 'r') ax.set_title(title) ax.xaxis.set_visible(False) ax.set_ylim([min(y) - np.std(y), max(y) + np.std(y)]) ax.set_xlim([min(x), max(x)]) ax.grid(True) for activity in df['activity'].unique(): limit = df[df['activity'] == activity][:180] fig, (ax0, ax1, ax2) = plt.subplots(nrows=3, sharex=True, figsize=(15, 10)) axis_plot(ax0, limit['timestamp'], limit['X'], 'x-axis') axis_plot(ax1, limit['timestamp'], limit['Y'], 'y-axis') axis_plot(ax2, limit['timestamp'], limit['Z'], 'z-axis') plt.subplots_adjust(hspace=0.2) fig.suptitle(activity) plt.subplots_adjust(top=0.9) plt.show()
數(shù)據(jù)預(yù)處理
數(shù)據(jù)預(yù)處理是一項(xiàng)非常重要的任務(wù),它使我們的模型能夠更好地利用我們的原始數(shù)據(jù)。這里將使用的數(shù)據(jù)預(yù)處理方法有:
標(biāo)簽編碼
線性插值
數(shù)據(jù)分割
歸一化
時(shí)間序列分割
獨(dú)熱編碼
標(biāo)簽編碼 由于模型不能接受非數(shù)字標(biāo)簽作為輸入,我們將在另一列中添加' activity '列的編碼標(biāo)簽,并將其命名為' activityEncode '。標(biāo)簽被轉(zhuǎn)換成如下所示的數(shù)字標(biāo)簽(這個(gè)標(biāo)簽是我們要預(yù)測(cè)的結(jié)果標(biāo)簽)
Downstairs [0]
Jogging [1]
Sitting [2]
Standing [3]
Upstairs [4]
Walking [5]
label_encode = LabelEncoder()df['activityEncode'] = label_encode.fit_transform(df['activity'].values.ravel())df
 ? 線性插值 利用線性插值可以避免采集過程中出現(xiàn)NaN的數(shù)據(jù)丟失的問題。它將通過插值法填充缺失的值。雖然在這個(gè)數(shù)據(jù)集中只有一個(gè)NaN值,但為了我們的展示,還是需要實(shí)現(xiàn)它。
? 線性插值 利用線性插值可以避免采集過程中出現(xiàn)NaN的數(shù)據(jù)丟失的問題。它將通過插值法填充缺失的值。雖然在這個(gè)數(shù)據(jù)集中只有一個(gè)NaN值,但為了我們的展示,還是需要實(shí)現(xiàn)它。
interpolation_fn = interp1d(df['activityEncode'] ,df['Z'], kind='linear')null_list = df[df['Z'].isnull()].index.tolist()for i in null_list: y = df['activityEncode'][i] value = interpolation_fn(y) df['Z']=df['Z'].fillna(value) print(value)數(shù)據(jù)分割 根據(jù)用戶id進(jìn)行數(shù)據(jù)分割,避免數(shù)據(jù)分割錯(cuò)誤。我們?cè)谟?xùn)練集中使用id小于或等于27的用戶,其余的在測(cè)試集中使用。
df_test = df[df['user-id'] > 27]df_train = df[df['user-id'] <= 27]歸一化 在訓(xùn)練之前,需要將數(shù)據(jù)特征歸一化到0到1的范圍內(nèi)。我們用的方法是:
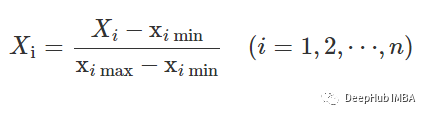 ?
?
df_train['X'] = (df_train['X']-df_train['X'].min())/(df_train['X'].max()-df_train['X'].min())df_train['Y'] = (df_train['Y']-df_train['Y'].min())/(df_train['Y'].max()-df_train['Y'].min())df_train['Z'] = (df_train['Z']-df_train['Z'].min())/(df_train['Z'].max()-df_train['Z'].min())df_train
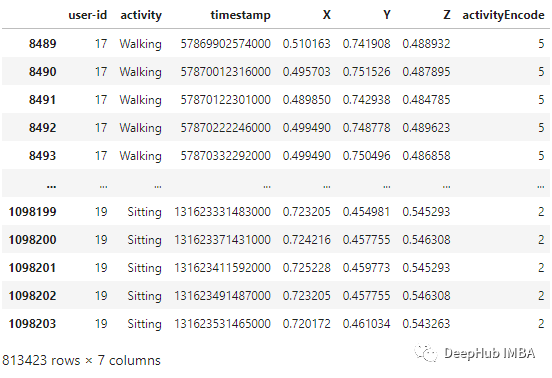 ? 時(shí)間序列分割 因?yàn)槲覀兲幚淼氖菚r(shí)間序列數(shù)據(jù), 所以需要?jiǎng)?chuàng)建一個(gè)分割的函數(shù),標(biāo)簽名稱和每個(gè)記錄的范圍進(jìn)行分段。此函數(shù)在x_train和y_train中執(zhí)行特征的分離,將每80個(gè)時(shí)間段分成一組數(shù)據(jù)。
? 時(shí)間序列分割 因?yàn)槲覀兲幚淼氖菚r(shí)間序列數(shù)據(jù), 所以需要?jiǎng)?chuàng)建一個(gè)分割的函數(shù),標(biāo)簽名稱和每個(gè)記錄的范圍進(jìn)行分段。此函數(shù)在x_train和y_train中執(zhí)行特征的分離,將每80個(gè)時(shí)間段分成一組數(shù)據(jù)。
def segments(df, time_steps, step, label_name): N_FEATURES = 3 segments = [] labels = [] for i in range(0, len(df) - time_steps, step): xs = df['X'].values[i:i+time_steps] ys = df['Y'].values[i:i+time_steps] zs = df['Z'].values[i:i+time_steps]
label = mode(df[label_name][i:i+time_steps])[0][0] segments.append([xs, ys, zs]) labels.append(label)
reshaped_segments = np.asarray(segments, dtype=np.float32).reshape(-1, time_steps, N_FEATURES) labels = np.asarray(labels)
return reshaped_segments, labels
TIME_PERIOD = 80STEP_DISTANCE = 40LABEL = 'activityEncode'x_train, y_train = segments(df_train, TIME_PERIOD, STEP_DISTANCE, LABEL)
這樣,x_train和y_train形狀變?yōu)椋?
print('x_train shape:', x_train.shape)print('Training samples:', x_train.shape[0])print('y_train shape:', y_train.shape)
x_train shape: (20334, 80, 3)Training samples: 20334y_train shape: (20334,)
這里還存儲(chǔ)了一些后面用到的數(shù)據(jù):時(shí)間段(time_period),傳感器數(shù)(sensors)和類(num_classes)的數(shù)量。
time_period, sensors = x_train.shape[1], x_train.shape[2]num_classes = label_encode.classes_.sizeprint(list(label_encode.classes_)) ['Downstairs', 'Jogging', 'Sitting', 'Standing', 'Upstairs', 'Walking']最后需要使用Reshape將其轉(zhuǎn)換為列表,作為keras的輸入:
input_shape = time_period * sensorsx_train = x_train.reshape(x_train.shape[0], input_shape)print("Input Shape: ", input_shape)print("Input Data Shape: ", x_train.shape)
Input Shape: 240Input Data Shape: (20334, 240)
最后需要將所有數(shù)據(jù)轉(zhuǎn)換為float32。
x_train = x_train.astype('float32')y_train = y_train.astype('float32')
獨(dú)熱編碼 這是數(shù)據(jù)預(yù)處理的最后一步,我們將通過編碼標(biāo)簽并將其存儲(chǔ)到y(tǒng)_train_hot中來(lái)執(zhí)行。
y_train_hot = to_categorical(y_train, num_classes)print("y_train shape: ", y_train_hot.shape)y_train shape: (20334, 6)
模型
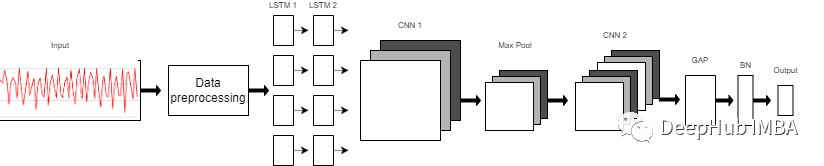 ? 我們使用的模型是一個(gè)由8層組成的序列模型。模型前兩層由LSTM組成,每個(gè)LSTM具有32個(gè)神經(jīng)元,使用的激活函數(shù)為Relu。然后是用于提取空間特征的卷積層。 ? 在兩層的連接處需要改變LSTM輸出維度,因?yàn)檩敵鼍哂?個(gè)維度(樣本數(shù),時(shí)間步長(zhǎng),輸入維度),而CNN則需要4維輸入(樣本數(shù),1,時(shí)間步長(zhǎng),輸入)。 ? 第一個(gè)CNN層具有64個(gè)神經(jīng)元,另一個(gè)神經(jīng)元有128個(gè)神經(jīng)元。在第一和第二CNN層之間,我們有一個(gè)最大池層來(lái)執(zhí)行下采樣操作。然后是全局平均池(GAP)層將多D特征映射轉(zhuǎn)換為1-D特征向量,因?yàn)樵诖藢又胁恍枰獏?shù),所以會(huì)減少全局模型參數(shù)。然后是BN層,該層有助于模型的收斂性。 ? 最后一層是模型的輸出層,該輸出層只是具有SoftMax分類器層的6個(gè)神經(jīng)元的完全連接的層,該層表示當(dāng)前類的概率。 ?
? 我們使用的模型是一個(gè)由8層組成的序列模型。模型前兩層由LSTM組成,每個(gè)LSTM具有32個(gè)神經(jīng)元,使用的激活函數(shù)為Relu。然后是用于提取空間特征的卷積層。 ? 在兩層的連接處需要改變LSTM輸出維度,因?yàn)檩敵鼍哂?個(gè)維度(樣本數(shù),時(shí)間步長(zhǎng),輸入維度),而CNN則需要4維輸入(樣本數(shù),1,時(shí)間步長(zhǎng),輸入)。 ? 第一個(gè)CNN層具有64個(gè)神經(jīng)元,另一個(gè)神經(jīng)元有128個(gè)神經(jīng)元。在第一和第二CNN層之間,我們有一個(gè)最大池層來(lái)執(zhí)行下采樣操作。然后是全局平均池(GAP)層將多D特征映射轉(zhuǎn)換為1-D特征向量,因?yàn)樵诖藢又胁恍枰獏?shù),所以會(huì)減少全局模型參數(shù)。然后是BN層,該層有助于模型的收斂性。 ? 最后一層是模型的輸出層,該輸出層只是具有SoftMax分類器層的6個(gè)神經(jīng)元的完全連接的層,該層表示當(dāng)前類的概率。 ?
model = Sequential()model.add(LSTM(32, return_sequences=True, input_shape=(input_shape,1), activation='relu'))model.add(LSTM(32,return_sequences=True, activation='relu'))model.add(Reshape((1, 240, 32)))model.add(Conv1D(filters=64,kernel_size=2, activation='relu', strides=2))model.add(Reshape((120, 64)))model.add(MaxPool1D(pool_size=4, padding='same'))model.add(Conv1D(filters=192, kernel_size=2, activation='relu', strides=1))model.add(Reshape((29, 192)))model.add(GlobalAveragePooling1D())model.add(BatchNormalization(epsilon=1e-06))model.add(Dense(6))model.add(Activation('softmax'))
print(model.summary())

訓(xùn)練和結(jié)果
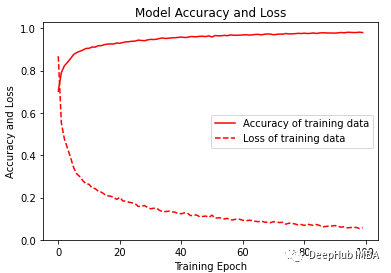
經(jīng)過訓(xùn)練,模型給出了98.02%的準(zhǔn)確率和0.0058的損失。訓(xùn)練F1得分為0.96。
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])history = model.fit(x_train, y_train_hot, batch_size= 192, epochs=100 )
 ? 可視化訓(xùn)練的準(zhǔn)確性和損失變化圖。 ?
? 可視化訓(xùn)練的準(zhǔn)確性和損失變化圖。 ?
plt.figure(figsize=(6, 4))plt.plot(history.history['accuracy'], 'r', label='Accuracy of training data')plt.plot(history.history['loss'], 'r--', label='Loss of training data')plt.title('Model Accuracy and Loss')plt.ylabel('Accuracy and Loss')plt.xlabel('Training Epoch')plt.ylim(0)plt.legend()plt.show()
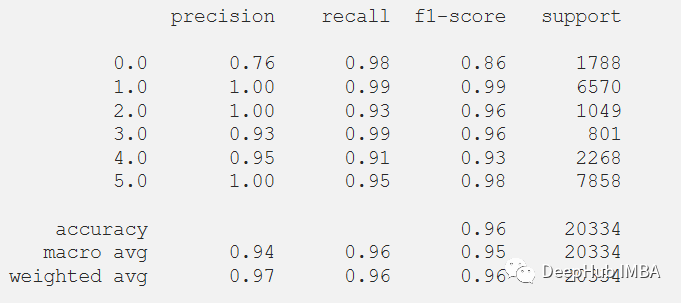
y_pred_train = model.predict(x_train)max_y_pred_train = np.argmax(y_pred_train, axis=1)print(classification_report(y_train, max_y_pred_train))
 ? 在測(cè)試數(shù)據(jù)集上測(cè)試它,但在通過測(cè)試集之前,需要對(duì)測(cè)試集進(jìn)行相同的預(yù)處理。 ?
? 在測(cè)試數(shù)據(jù)集上測(cè)試它,但在通過測(cè)試集之前,需要對(duì)測(cè)試集進(jìn)行相同的預(yù)處理。 ?
df_test['X'] = (df_test['X']-df_test['X'].min())/(df_test['X'].max()-df_test['X'].min())df_test['Y'] = (df_test['Y']-df_test['Y'].min())/(df_test['Y'].max()-df_test['Y'].min())df_test['Z'] = (df_test['Z']-df_test['Z'].min())/(df_test['Z'].max()-df_test['Z'].min())x_test, y_test = segments(df_test, TIME_PERIOD, STEP_DISTANCE, LABEL)
x_test = x_test.reshape(x_test.shape[0], input_shape)x_test = x_test.astype('float32')y_test = y_test.astype('float32')y_test = to_categorical(y_test, num_classes)
在評(píng)估我們的測(cè)試數(shù)據(jù)集后,得到了89.14%的準(zhǔn)確率和0.4647的損失。F1測(cè)試得分為0.89。
score = model.evaluate(x_test, y_test)print("Accuracy:", score[1])print("Loss:", score[0])
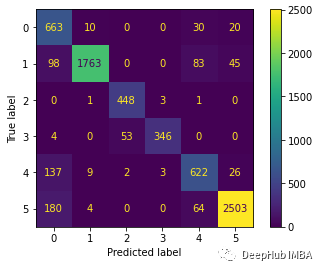
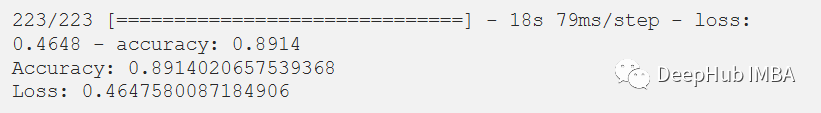 ? 下面繪制混淆矩陣更好地理解對(duì)測(cè)試數(shù)據(jù)集的預(yù)測(cè)。 ?
? 下面繪制混淆矩陣更好地理解對(duì)測(cè)試數(shù)據(jù)集的預(yù)測(cè)。 ?
predictions = model.predict(x_test)predictions = np.argmax(predictions, axis=1)y_test_pred = np.argmax(y_test, axis=1)cm = confusion_matrix(y_test_pred, predictions)cm_disp = ConfusionMatrixDisplay(confusion_matrix= cm)cm_disp.plot()plt.show()
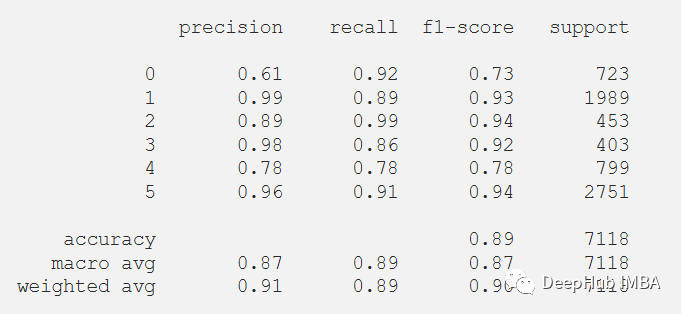
 ? 還可以在測(cè)試數(shù)據(jù)集上評(píng)估的模型的分類報(bào)告。 ?
? 還可以在測(cè)試數(shù)據(jù)集上評(píng)估的模型的分類報(bào)告。 ?
print(classification_report(y_test_pred, predictions))
總結(jié)
LSTM-CNN模型的性能比任何其他機(jī)器學(xué)習(xí)模型要好得多。本文的代碼可以在GitHub上找到。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7259瀏覽量
92018 -
人工智能
+關(guān)注
關(guān)注
1807文章
49050瀏覽量
250004 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8506瀏覽量
134723 -
移動(dòng)傳感器
+關(guān)注
關(guān)注
0文章
8瀏覽量
8652
發(fā)布評(píng)論請(qǐng)先 登錄
使用移動(dòng)傳感器產(chǎn)生的原始數(shù)據(jù)來(lái)識(shí)別人類活動(dòng)
使用ADS1298出來(lái)的8通道原始數(shù)據(jù)是多少?
如何使用 CYW20829 將獲得的傳感器數(shù)據(jù)發(fā)送到廣播中?
如何通過波形原始數(shù)據(jù)獲得頻率
LSM303AGR如何消除原始數(shù)據(jù)失真?
通過DMA1將原始數(shù)據(jù)寫入DAC寄存器
請(qǐng)問STEVAL-IDB011V1板為什么無(wú)法通過BLE發(fā)送原始數(shù)據(jù)呢
如何將陀螺儀的原始數(shù)據(jù)轉(zhuǎn)換成角速度呢
ABPDLNN100MG2A3壓力傳感器如何將原始數(shù)據(jù)轉(zhuǎn)換為毫巴?
MPU6050原始數(shù)據(jù)處理
MPU6050的原始數(shù)據(jù)怎么處理能得到向x,y,z方向移動(dòng)的距離?
基于模板的SAR原始數(shù)據(jù)模擬
基于DCT-TCQ的SAR原始數(shù)據(jù)壓縮算法
用STM32實(shí)現(xiàn)MPU6050原始數(shù)據(jù)的讀取

使用通用傳感器API的人類活動(dòng)識(shí)別





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論