


說來慚愧,之前寫了一篇對向量召回的總結(jié)(前沿重器[28] | 前沿的向量召回都是怎么做的),萬萬沒想到現(xiàn)在就來寫新文章了,而且上面的總結(jié)還沒提到,大家當(dāng)做擴(kuò)展和補(bǔ)充吧。
眾所周知,在語義相似度上,交互式方案總會比非交互方案更容易獲得較好的效果,然而在召回上,非交互式方案(也就是表征式)具有得天獨厚的優(yōu)勢,我們最終使用的,又不得不是非交互的方案,因此我們會嘗試進(jìn)一步優(yōu)化非交互方案。
最近開始發(fā)現(xiàn)一些從交互式蒸餾到交互的方案,例如21年年末美團(tuán)提出的VIRT(VIRT: Improving Representation-based Models for Text Matching through Virtual Interaction),今天我們來聊的是百度在22年5月份提出的方案,我認(rèn)為這篇論文是這個領(lǐng)域內(nèi)目前比較有代表性的,主要有這幾個原因:
整理了一些比較好的蒸餾思路和方向。
對這些蒸餾方案做了一些消融實驗。
試驗了一些前處理的方案,甚至包括一些furture pretrain。
論文和有關(guān)資料放這里:
原論文:ERNIE-Search: Bridging Cross-Encoder with Dual-Encoder via Self On-the-fly Distillation for Dense Passage Retrieval
文章講解:
https://zhuanlan.zhihu.com/p/522301876
https://blog.csdn.net/moxibingdao/article/details/125713542
https://zhuanlan.zhihu.com/p/518577648
表征式能逼近交互式嗎
之所以想先聊這個,是因為想說一下這兩者之間存在的可能性,即表征式是否可以達(dá)到交互式的效果,從蘇神有關(guān)這塊的推理來看(https://spaces.ac.cn/archives/8860),其實是可行的,雖然這塊的推理并不算嚴(yán)格,但是這個推理已經(jīng)相對可靠了,換言之,我們可能可以找到更好的學(xué)習(xí)方法,找到這樣一組參數(shù),使表征式能達(dá)到交互式效果的這個理論高度。
ERNIE-Search模型結(jié)構(gòu)
模型結(jié)構(gòu),我比較想從損失函數(shù)開始講,其實從損失函數(shù)看就能看出本文很大部分的貢獻(xiàn):
這個損失的內(nèi)容非常多,我把他分為兩個部分,一個是獨立訓(xùn)練的部分(不帶箭頭的),另一個是蒸餾部分(帶箭頭的)。首先是獨立訓(xùn)練的部分,這部分主要是直接針對標(biāo)簽進(jìn)行訓(xùn)練的,無論是teacher模型還是student模型,其實都是需要這個部分的。
:cross-encoder,交互式的方案,在這篇論文里,使用的是ERNIE2.0(4.1.3中提到)。
:late-interaction,延遲交互方案,這里是指介于交互式和表征式之間的方案,開頭是雙塔,后續(xù)的交互式并非cos而是更復(fù)雜的交互方式,如ColBERT(ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT)。
:Dual-encoder,表征式方案,就是常說的雙塔,本文用的是同樣是ERNIE2.0(4.1.3中提到)。
另一部分則是蒸餾部分,這里的蒸餾部分作者是做了很多的心血進(jìn)行分析的,構(gòu)造了好幾個損失函數(shù),分別是這些,這里的幾個蒸餾損失函數(shù)用的都是KL散度:
:交互方案蒸餾到延遲交互方案。
:延遲交互方案蒸餾到表征式方案(和共同形成級聯(lián)蒸餾)。
:交互方案蒸餾到表征式方案。
:最特別的一個。實質(zhì)上是一個token級別的交互損失,旨在希望延遲交互得到的attn矩陣和交互式的attn矩陣盡可能接近。
回到損失函數(shù)本身,其實會發(fā)現(xiàn)這個損失函數(shù)是由多個損失函數(shù)組合起來的,敏銳的我們可以發(fā)現(xiàn),這里的幾個損失之間的權(quán)重是完全一樣的,估計調(diào)整下可能還有些空間吧,不過也考慮到損失函數(shù)實在夠多了,調(diào)起來真的不容易。
說起效果,這點作者是做了消融實驗的:
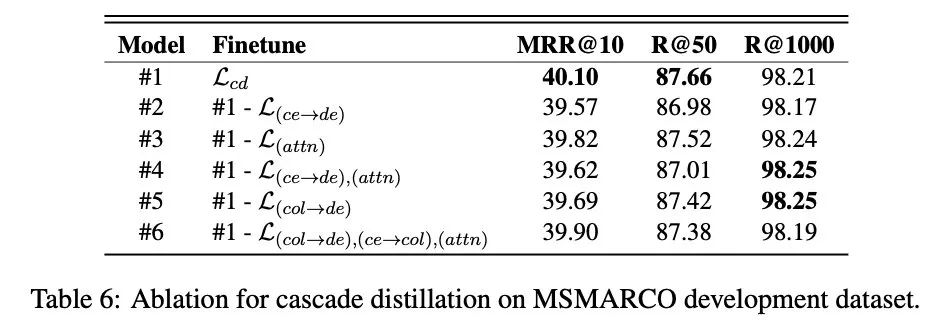
損失函數(shù)消融實驗
從實驗結(jié)果來看,其中貢獻(xiàn)最大的是,也就是交互方案蒸餾到延遲交互方案,其二是(我感覺就是),這個也挺符合直覺的吧,但是比較神奇的是去掉了比較多以后,就是#6的實驗,好像最終對結(jié)果的損失反而會變少,這個有些神奇,有待進(jìn)一步實驗和探索吧,當(dāng)然,我感覺這里可能和權(quán)重也有關(guān)。
訓(xùn)練策略
還需要提一個關(guān)鍵點就是文章在4.1.3中提到的訓(xùn)練策略,這個特別的訓(xùn)練策略為最終的結(jié)果貢獻(xiàn)度不少(可以參考消融實驗),因此展開說一下:
使用對應(yīng)語料對預(yù)訓(xùn)練模型(應(yīng)該就是ERNIR2.0)進(jìn)行繼續(xù)預(yù)訓(xùn)練,這個階段在文中也被稱為post-train。
對QA任務(wù),使用交互式蒸餾到表征式的方案,訓(xùn)練表征式模型。
對QA任務(wù),再使用上面的級聯(lián)蒸餾方案,訓(xùn)練表征式模型,和上一條被聯(lián)合稱為finetune階段。
另外,在3.4中,有提到一個訓(xùn)練策略叫Dual Regularization(DualReg),其實我感覺這個和r-dropout很相似(前沿重器[15] | R-Dropout——一次不行就兩次),用兩個不同隨機(jī)種子的dropout對表征式進(jìn)行前向訓(xùn)推理,得到兩個表征結(jié)果,用KL散度進(jìn)行學(xué)習(xí),而因為雙塔,實際上要對q1和q2都這么做一次,所以實際上會多兩個損失函數(shù)。

訓(xùn)練策略消融實驗
這些訓(xùn)練策略的效果,在4.3.1中有進(jìn)行消融實驗,如上圖所示,直觀地,從這個表其實可以發(fā)現(xiàn)幾個信息:
ID'(也就是交互式蒸餾)具有一定的優(yōu)勢,尤其是在Finetuning階段,但是在Post-train中的收益似乎不那么明顯。
DualReg似乎是有些效果的,但是不清楚為什么要把CB(RocketQA中的提到的跨batch負(fù)采樣策略)也放一起,就感覺這個東西和本文的創(chuàng)新點沒啥關(guān)系,讓我們并不知道是CB的貢獻(xiàn),還是DualReg的貢獻(xiàn)了。
但是感覺做的有一些馬虎,主要是為了證明這個ID'(也就是交互式整流)的方案比較厲害,但是從這個表來看收效沒有想象的大額,不過有一說一,前面的繼續(xù)預(yù)訓(xùn)練還是非常值得我們學(xué)習(xí)和嘗試的,這點我在(前沿重器[26] | 預(yù)訓(xùn)練模型的領(lǐng)域適配問題)中有提到過。
小結(jié)
總結(jié)下來,這篇文章最大的特點是把“通過學(xué)習(xí)交互式,來讓表征式效果進(jìn)一步提升”這個思路發(fā)揮很極致,讓我們知道了這個方案的潛力,這個是有些實驗和落地價值的。
除此之外,這篇文章在初讀的時候,其實發(fā)現(xiàn)了不少新的概念(可能也是我有些匱乏吧),所以挖了不少坑,論文里的下面這張表其實都值得我好好讀一下,當(dāng)然也包括introduction里面的。
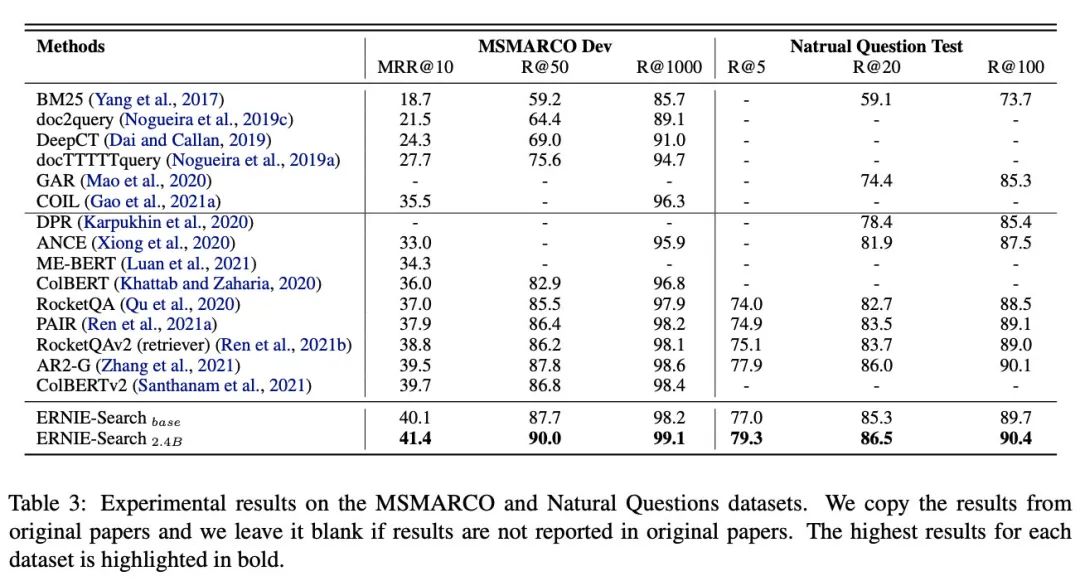
對比實驗
審核編輯 :李倩
-
函數(shù)
+關(guān)注
關(guān)注
3文章
4379瀏覽量
64806 -
模型
+關(guān)注
關(guān)注
1文章
3517瀏覽量
50383
原文標(biāo)題:ERNIE-Search:向交互式學(xué)習(xí)的表征式語義匹配代表作
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
大模型推理顯存和計算量估計方法研究
Say Hi to ERNIE!Imagination GPU率先完成文心大模型的端側(cè)部署






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論