 編譯器把代碼轉化為機器碼的過程
編譯器把代碼轉化為機器碼的過程
編譯器,是把高級語言轉化為機器語言的工具軟件。
高級語言的代碼也是個文本字符串,所以編譯器的前端與sed、gawk、grep是差不多的,都是廣義上的字符串匹配。
編譯器把代碼轉化為機器碼的過程如下:
1,詞法分析,
這是編譯器里最簡單的模塊。
詞法分析,就是通過查看下一個字符來確定怎么把代碼字符串分割成一個個的語法詞匯。
起始符、終止符,是詞法分析的主要概念。
intday =24 * 3600;
這行代碼的第1個詞是int,起始符是i,終止符是空格。
在詞法分析時它是一個標志符,也就是字母、下劃線、數字組成的一個字符串,必須以字母或下劃線開頭。
在分析出int這個標志符之后,它后面的空格就沒用了,直接丟棄它。
第2個詞day也是一個標志符,起始符是d,終止符也是空格。
習慣把代碼寫得密集的人可能這么寫:int day=24*3600;
這時day的終止符是=,它同時還是下一個詞的起始符,在把day加入詞匯序列之后需要從=開始接著分析。
第3個詞是=,第4個詞是24,第5個詞是*,第6個詞是3600,第7個詞是分號;
在詞法分析時要把數字字符串24和3600轉化為整數24和3600,這兩個在程序里是不同的。
10進制、16進制、8進制、2進制、浮點數的支持,都是詞法分析時的任務。
另外,轉義字符串也要在這里支持。
'' 在源代碼里是字符串文本,包含著4個字符' 0 ',要轉義成單個字符0。
' ' ' ' ' '的處理和''一樣。
詞法分析還是很好寫的。
2,語法分析,
這是編譯器前端最難寫的模塊,它需要把源代碼轉化成一棵描述整個程序結構的多叉樹。
這個多叉樹叫做抽象語法樹(英文縮寫AST)。
類型、變量、運算符、函數定義、函數調用、if語句、for/while循環,都是這個這棵樹的一部分。
抽象語法樹的層次結構,與源代碼的結構是一樣的。
如果是這樣的源代碼的話:
int sum = 0;
for (int i = 0; i < 8; i++) {
if (i % 2 == 0)
sum += i;
}
那么語法樹是這樣的:
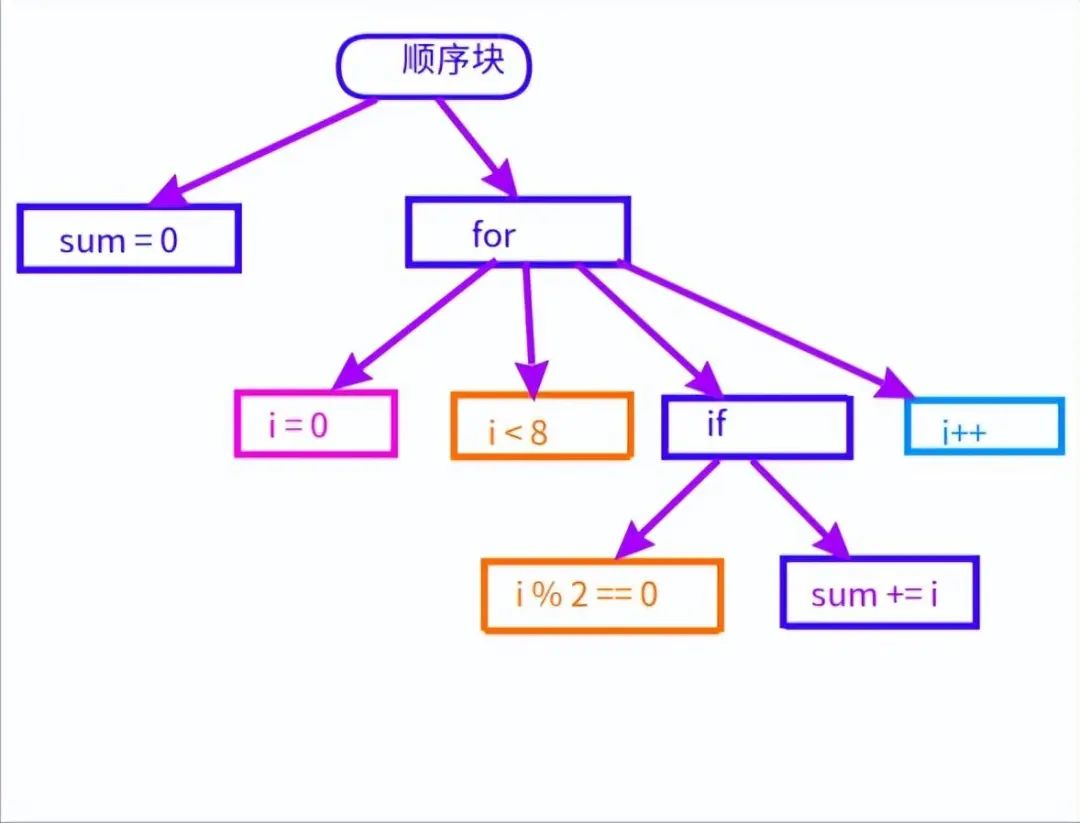
語法樹
初始化語句sum = 0與后續的for循環是順序執行的,它們屬于同一個順序塊,在語法樹上有同一個父節點。
for循環有4個子節點:初始化表達式i = 0,條件i < 8,循環體if語句、更新表達式i++。
其中循環體又是個if語句,具有2個子節點:條件表達式i % 2 == 0,主體sum += i。
while循環的結構與for類似,只要去掉初始化表達式和更新表達式就行,只有2個節點。
把詞法分析之后的詞匯序列轉化成抽象語法樹時,常用的方法是有限自動機。
也可以把代碼直接寫成遞歸函數調用,但是后續改起語法來就比較麻煩。
我一開始就是把scf的parse模塊寫成了遞歸函數調用,后來為了可以編輯語法,又自己做了個簡單的有限自動機。
3,語義分析,
把語法樹遍歷一遍,檢查一下類型是否匹配,就是語義分析。
如果要支持面向對象的話,就可以在這里進行函數重載和運算符重載。
常量表達式也要在這里計算出來,int day = 24 *3600要轉化成day = 86400。
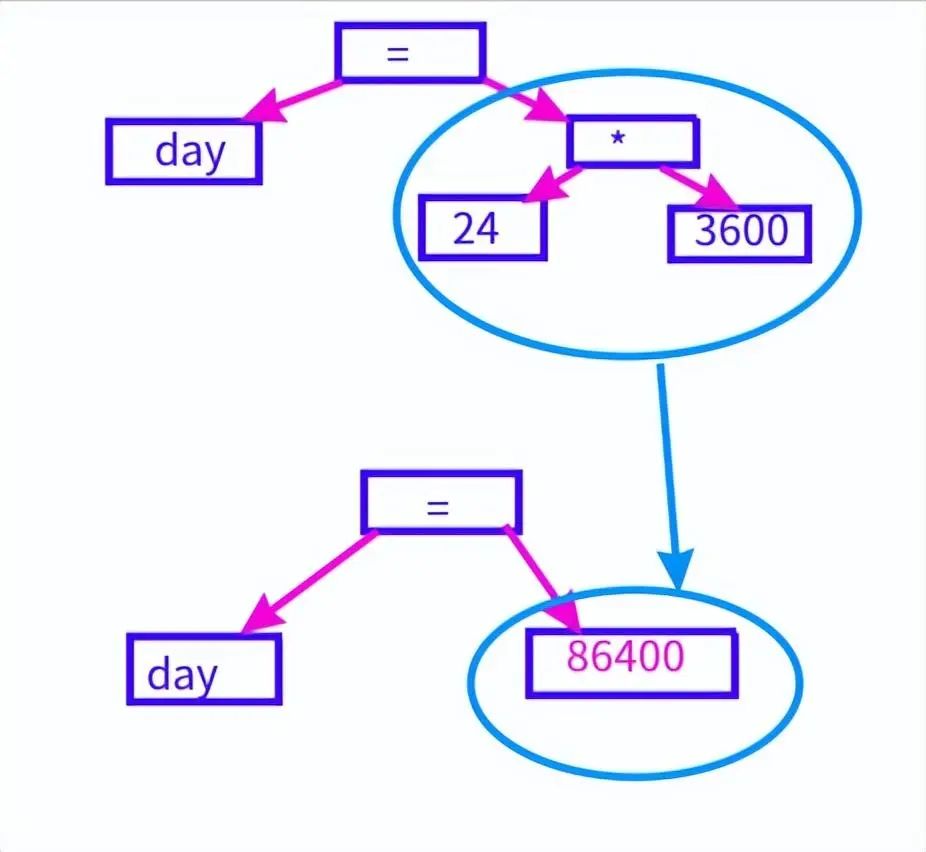
常量表達式的計算
對語法樹進行遍歷時,不同的語法節點使用的處理函數是不同的,這就是語義。
符號=要當作賦值,符號+要當作加法,其他類似。
C語言里常見的函數調用,語法樹是這樣的:
int printf(const char* fmt, ...);
int main()
{
printf("hello world ");
}
函數調用也是一個運算符,具有一個單獨的語法節點,它的子節點都是它的參數:
其中函數名也是一個參數,要轉化為對應的函數體的節點的指針。
通過這個指針才可以找到函數的代碼,進行內聯優化(inline)。
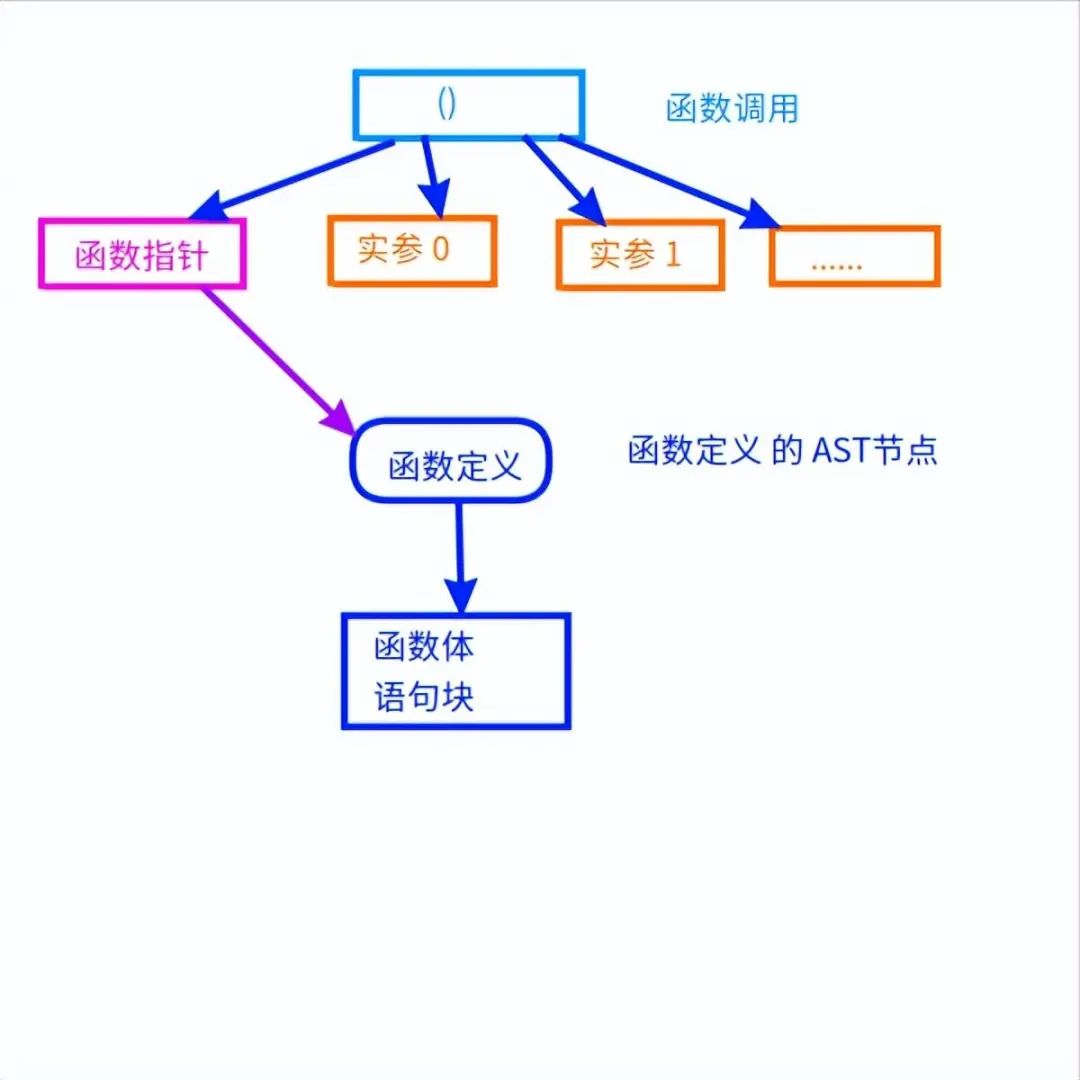
函數調用和定義
如果要是調用的外部函數,只有聲明沒有實現,那就沒法內聯了。
4,中間代碼生成(三地址碼),從這里開始就是編譯器的后端了。
這一步也是對語法樹進行遍歷,把對應的表達式、函數、if語句、for循環都變成類似匯編的三地址碼。
上面那段for循環,這時會被變成如下的三地址碼序列:
assign sum, 0
assign i, 0
start: // for循環的開頭
cmp i, 8
jge end //條件不成立,則結束循環
assignt, i % 2 // t是編譯器生成的臨時變量
cmp t, 0
jne next
add sum, sum, i // 這行才是三地址碼
next: // 下一輪for循環
inc i // 循環變量+1
jmp start //跳轉回開頭,繼續循環
end:// for循環結束
到了這里,那個復雜的樹型結構已經變成線形結構了,可以按順序寫到一個文本文件里,這就是匯編代碼。
到這里,編譯器就可以生成類似gcc -S的匯編代碼了。
5,中間代碼優化,
這是編譯器后端的主要部分,屬于機器無關優化,這部分的優化是不依賴于CPU平臺的。
scf框架的這部分包含以下功能:
1)內聯函數,
2)有向無環圖DAG的生成,
3)帶二級指針參數的函數調用分析,
4)指針別名分析,也就是分析指針指向的變量,
5)活躍變量分析,
6)變量的加載保存分析,
7)需要自動內存管理的變量分析,
8)代碼流程圖的深度優先排序,
9)自動內存管理代碼的添加,
10)基本塊內的優化,
11)循環分析,
會把一些變量盡量在循環的入口加載,在循環出口保存,減少循環內的內存讀寫。
沒有常量傳播的優化,哪天有空我把它添上
6,寄存器分配,
使用圖的著色算法,之前的文章寫過。
7,指令選擇,
直接寫在代碼里的,沒做龍書里提到的那個樹的覆蓋。
8,機器碼生成,
根據intel x64的手冊編寫機器碼就行。
9,目標文件生成,
也就是gcc -c 得到那個.o文件。
Linux上的elf文件是什么樣的就怎么寫,可以參考linux的man手冊里對elf的講解。
10,可執行文件的生成,
這是連接器的功能,它把多個.o .a .so文件連接成一個可執行文件。
這一步的代碼在scf/elf目錄,有興趣的可以看看。
連接之后的文件就可以在shell命令行里運行了。
審核編輯:湯梓紅
-
機器碼
+關注
關注
0文章
12瀏覽量
8310 -
代碼
+關注
關注
30文章
4779瀏覽量
68524 -
編譯器
+關注
關注
1文章
1623瀏覽量
49108
原文標題:編譯器的代碼架構
文章出處:【微信號:yikoulinux,微信公眾號:一口Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機器碼提取, 芯片破譯
如何將高級C語言編譯成機器碼
arm7和arm9采用的指令系統的機器碼應該是不同的吧
C編譯器的設計文檔與源代碼
編譯器是如何工作的_編譯器的工作過程詳解
MPLAB? XC8 C編譯器的架構特性

如何對單片機的機器碼進行反編譯代碼免費下載





 工商網監
工商網監
評論