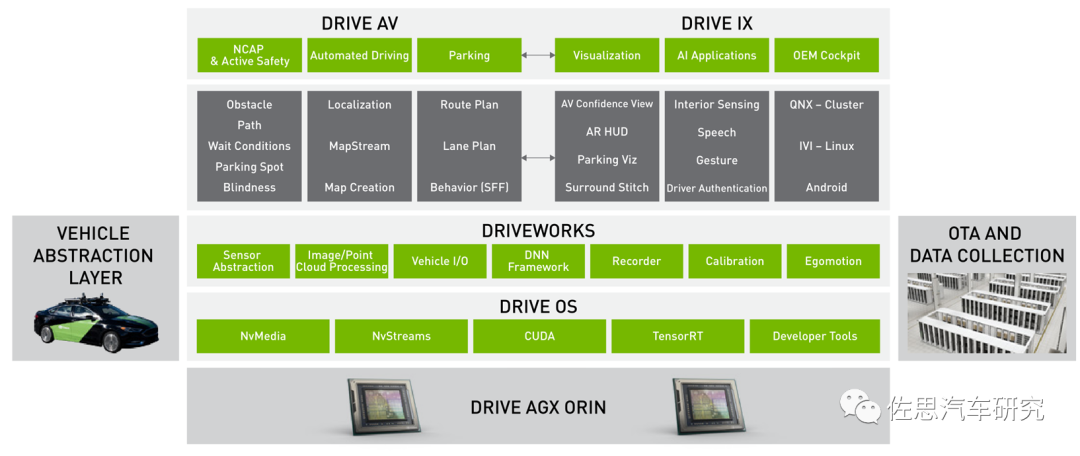
 英偉達Orin算法庫主要三類算法
英偉達Orin算法庫主要三類算法
做自動駕駛芯片必須軟硬一體,最多的工作不是芯片本身,而是與之對應的算法庫。對于自動駕駛,英偉達提供兩種合作模式。
圖片來源:互聯網
一種是車企交出全部靈魂,英偉達提供全套解決方案,包括底層OS,中間件DRIVEWORKS,上層應用模塊DRIVE AV包括座艙的模塊DRIVE IX也一起提供。不過中國禁止國外廠家上路采集信息,也就是用于識別的訓練數據集還是需要中國廠家自己去做。如果是在美國,訓練數據集英偉達也可以提供。
另一種是車企交出部分靈魂,英偉達提供底層的基礎算法,這些算法大多基于手工模型,和深度學習沒關聯。實際深度學習或者說AI是自動駕駛領域最容易做的部分,搜集數據,標注數據,訓練數據,提取權重模型。這也是為什么AI不具備可解釋性,無法迭代,好在AI可溯源。工作量最大,難度最高的都是非深度學習部分。手工模型,傳統算法的好處是可解釋,可迭代,具備確定性。
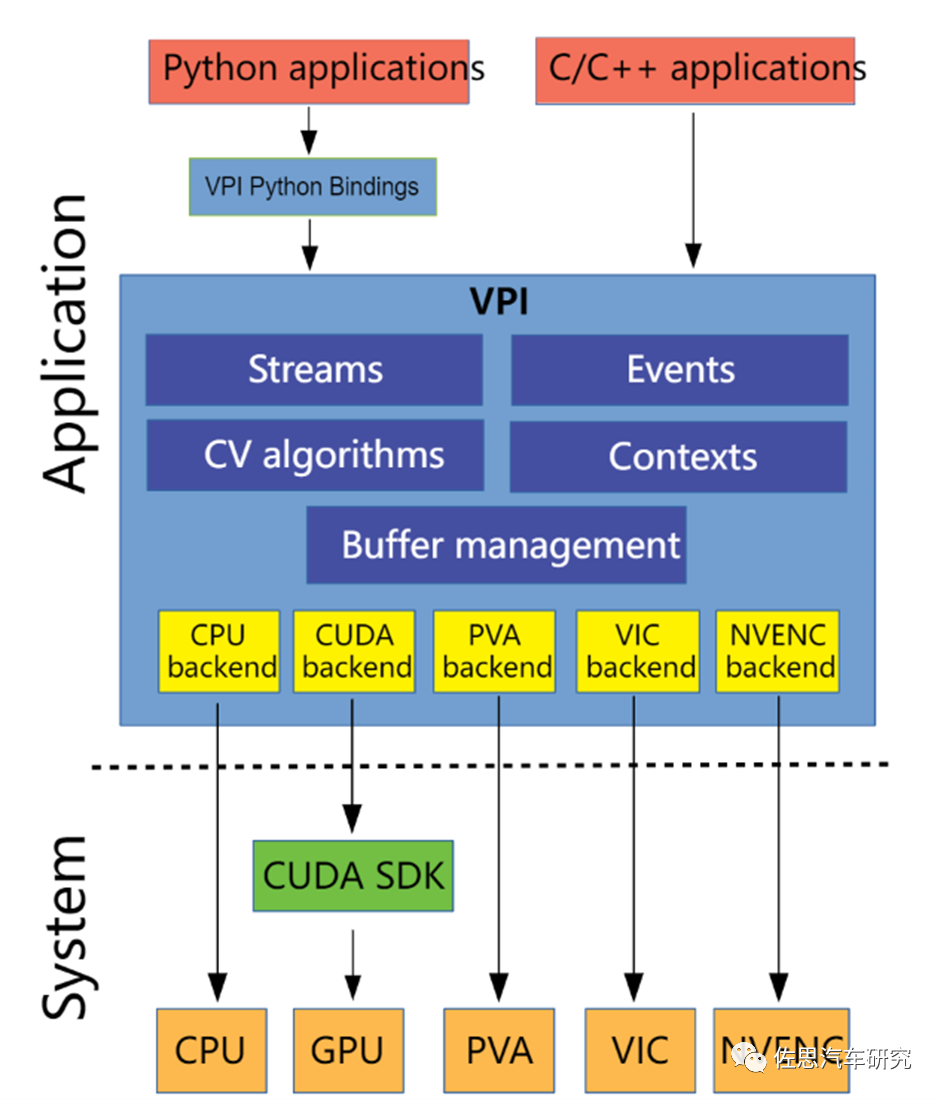
后一種的算法庫,英偉達稱之為VPI,即Vision Programming Interface,2021年2月發布,目前是2.0版本,VPI除了針對智能駕駛,也能用在任何計算機視覺領域,英偉達Jeston系列硬件平臺都支持VPI。VPI提供一系列軟件庫,可在英偉達的硬件平臺上得到加速,通常加速器還叫Backend后端。VPI用來取代NVIDIAVisionWorks。VPI可以最大化利用硬件,特別是Xavier和Orin的PVA、VIC、OFA。簡單地說VPI將一些簡單的算法封裝成了類似硬件指令集的指令,對用戶幾乎透明,可直接調用,讓原本需要N行代碼才能完成的算法函數,只需一行指令就完成,讓不熟悉基礎算法的人也能勝任。大大縮減了開發周期和開發人員,效率顯著提升。缺點是被英偉達深度捆綁,想換個平臺絕無可能。
圖片來源:互聯網
PVA(Programmable Vision Accelerator),可編程視覺加速器;
VIC(Video Image Compositor),做一些固定功能的圖像處理,如縮放、色彩轉換、消噪;
NVENC(NVIDIA Encoder Engine),主要做視覺編碼,也能做稠密光流應用。
整個VPI的執行概念,就是提供適合實時圖像處理應用的異步計算管道,由一個或多個異步計算流(streams)組成,這些流在可用計算后端(backends)的緩沖區(buffers)上運行算法(algorithms),流之間使用事件(events)進行同步。VPI將數據封裝到需要使用的每個算法的緩沖區中,提供Images(二維圖像)、Arrays(一維數組)和Pyramids(二維圖像金字塔)的三種抽象,以及用戶分配內存包裝,由VPI直接分配和管理。
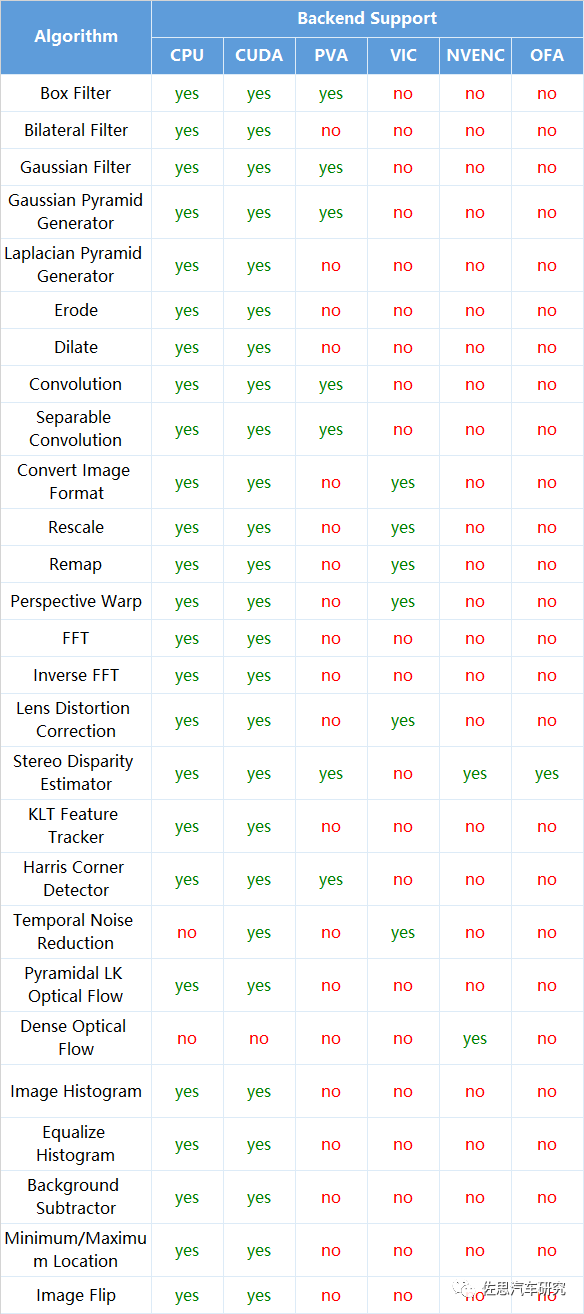
英偉達VPI 2.0算法對應硬件。
圖片來源:互聯網
算法庫主要包含三類算法:
一是簡單的圖像前處理,包括各種平滑濾波、鏡頭畸變矯正、縮放、透視、拼接、直方圖、消噪、快速傅里葉變換等;
二是針對立體雙目視差的獲得;
三是光流追蹤。
OFA即光流加速器,為Orin平臺獨有,Xavier平臺不支持。OFA只針對一個算法,就是立體雙目視差估算。
英偉達VPI核心算法即圖中這六大算法

圖片來源:互聯網
盡管只有奔馳和豐田用英偉達處理器處理立體雙目,新型造車除了RIVIAN目前都不使用立體雙目(小鵬小米可能在將來使用立體雙目),但英偉達每一次硬件升級都不忘對立體雙目部分特別關照。
英偉達立體雙目處理流程
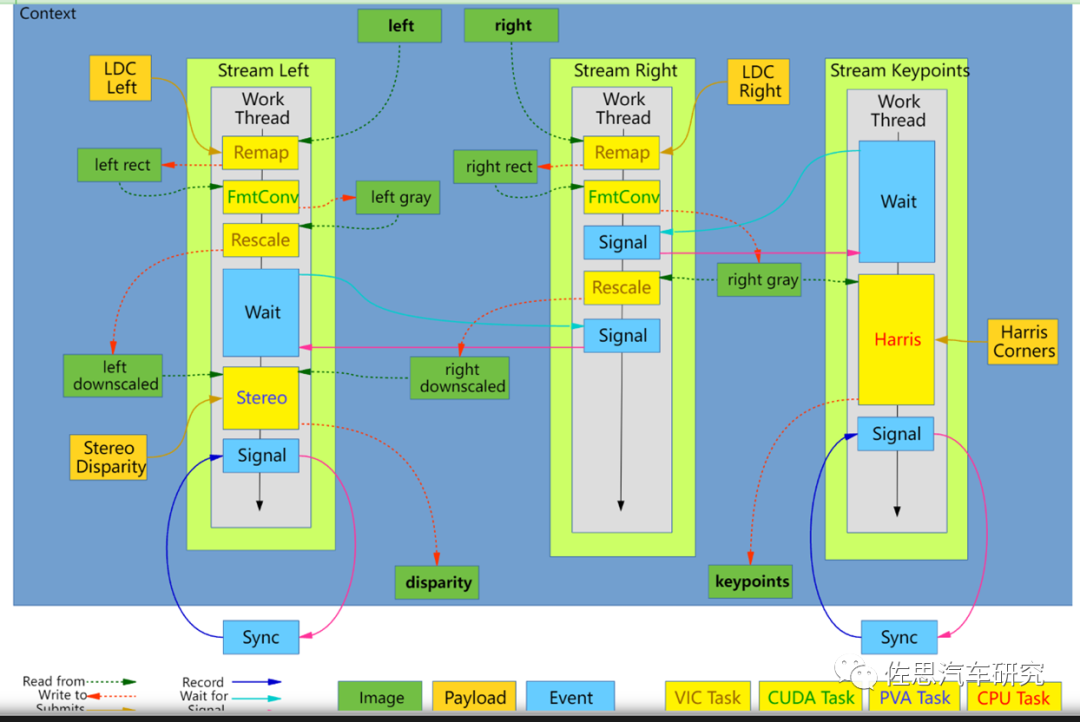
圖片來源:互聯網
立體雙目視差的獲得需要多種運算資源的參加,包括了VIC、GPU(CUDA)、CPU和PVA。
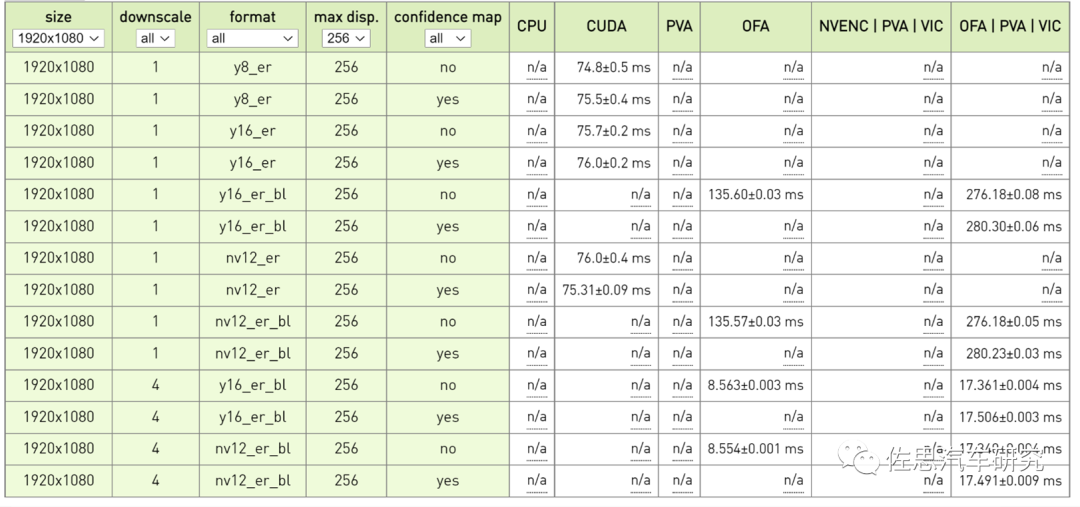
圖片來源:互聯網
英偉達Orin平臺立體雙目視差測試成績,要達到每秒30幀,那么處理時間必須低于30毫秒,考慮到還有后端決策與控制系統的延遲,處理時間必須低于20毫秒。1個下取樣情況下,顯然都無法滿足30幀的要求,4個下取樣,不加置信度圖時,單用OFA就可以滿足。加置信圖后,需要OFA/PVA/VIC聯手,也能滿足30幀需求。但這只是200萬像素,300萬像素估計就無法滿足了。

圖片來源:互聯網
并且此時是火力全開,運行頻率如下:
CPU: 12x ARMv8 Processor rev 1 (v8l) running at 2.2016 GHz
EMC freq.: 3.1990 GHz
GPU freq.: 1.3005 GHz
PVA/VPS freq.: 1.1520 GHz
PVA/AXI freq.: 832.8 MHz
VIC freq.: 729.6 GHz
Power mode: MAXN
Fan speed: MAX
這種火力全開情況下,恐怕不能持續太長時間。
光流Optical Flow追蹤主要用于目標的行駛軌跡的預測。
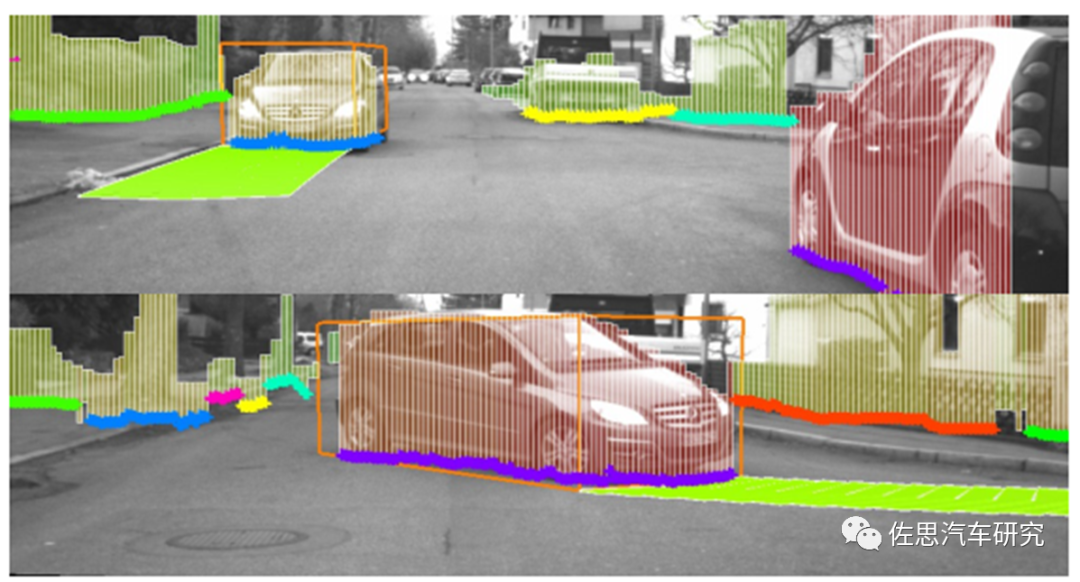
圖片來源:互聯網 上圖就是奔馳用光流法預測車輛行駛軌跡。
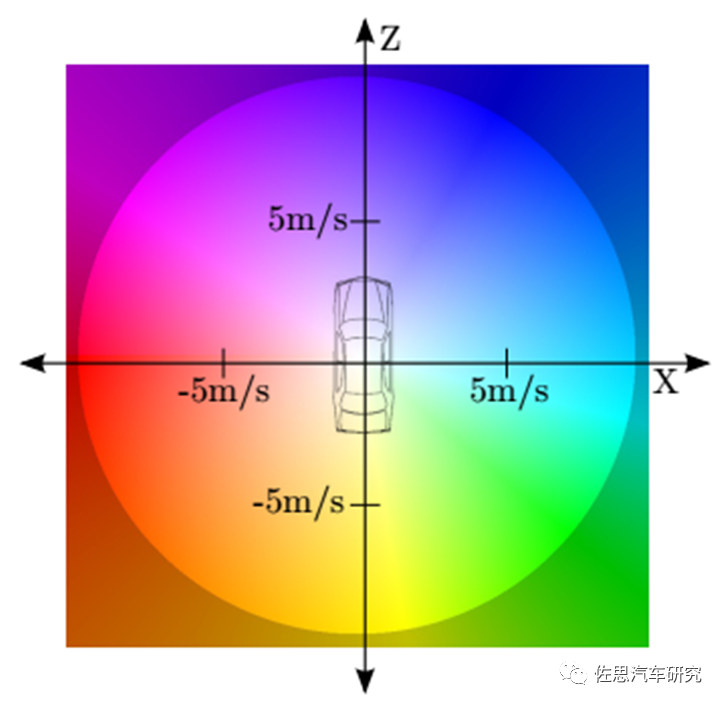
圖片來源:互聯網
上圖是奔馳的顏色編碼,不同的顏色代表車輛即將行駛的速度和方位角。
光流是利用圖像序列中像素在時間域上的變化以及相鄰幀之間的相關性來找到上一幀跟當前幀之間存在的對應關系,從而計算出相鄰幀之間物體的運動信息的一種方法。研究光流場的目的就是為了從圖片序列中近似得到不能直接得到的運動場,其本質是一個二維向量場,每個向量表示了場景中該點從前一幀到后一幀的位移。那對于光流的求解,即輸入兩張連續圖像(圖像像素),輸出二維向量場的過程。除了智能駕駛,體育比賽中各種球類的軌跡預測,軍事行動中的目標軌跡預測都能用到。光流場是運動場在二維圖像平面上的投影。因為立體雙目和激光雷達都是3D傳感器,而單目或三目是2D傳感器,所以單目或三目的光流非常難做。光流再分為稀疏和稠密(Dense)兩種,稀疏光流對部分特征點進行光流解算,稠密光流則針對的是所有點的偏移。
最常見的光流算法即KLT特征追蹤,源自1981年,早期的光流算法都是稀疏光流,手工模型或者說傳統算法。2015年有人提出深度學習光流法,在CVPR2017上發表改進版本FlowNet2.0,成為當時最先進的方法。截至目前,FlowNet和FlowNet2.0依然是深度學習光流估計算法中引用率最高的論文。傳統算法計算資源消耗少,實時性好,效果比較均衡,但魯棒性不佳。深度學習消耗大量的運算資源,魯棒性好,但容易出現極端,即某個場景非常差,但無法解釋,與訓練數據集關聯程度高。即使強大的Orin也無法FlowNet2.0做到實時性,畢竟Orin不能只做光流這一件事。因此英偉達還是推薦KLT。產業領域光流法主流還是KLT。但學術領域已經是深度學習了。
硬件與算法互相推動,硬件算力的增強讓人們敢于部署越來越大規模的深度學習模型,反過來,這又推動硬件算力的需求,特別是自動駕駛,傳統可解釋算法研究的人越來越少,因為投入產出比太低,深度學習正橫掃一切,但深度學習不可解釋,汽車領域需要的是可解釋可預測可確定。否則無法迭代,無法劃出安全邊際線。這也是自動駕駛難以落地的主要原因。
審核編輯 :李倩
-
算法
+關注
關注
23文章
4607瀏覽量
92835 -
英偉達
+關注
關注
22文章
3770瀏覽量
90986 -
自動駕駛
+關注
關注
784文章
13784瀏覽量
166386
原文標題:英偉達Orin算法庫都有什么算法?
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

Orin芯片的編程語言支持
Orin芯片的技術特點






 工商網監
工商網監
評論