") 擴散模型和其在文本生成圖像任務上的應用
擴散模型和其在文本生成圖像任務上的應用
本文主要介紹擴散模型和其在文本生成圖像任務上的應用,從擴散模型的理論知識開始,再到不同的指導技巧,最后介紹文本生成圖像的應用,帶讀者初探擴散模型的究竟。如有遺漏或錯誤,歡迎大家指正。
引言:擴散模型是一類生成模型,通過迭代去噪過程將高斯噪聲轉(zhuǎn)換為已知數(shù)據(jù)分布的樣本,生成的圖片具有較好的多樣性和寫實性。文本生成圖像是多模態(tài)的任務之一,目前該任務的很多工作也是基于擴散模型進行構(gòu)建的,如GLIDE、DALL·E2、Imagen等,生成的圖片讓人驚嘆。本文從介紹擴散模型的理論部分開始,主要介紹DDPM一文中涉及到的數(shù)學公式,然后介紹擴散模型中常用到的指導技巧,最后會介紹文本生成圖像的一些應用。 1. 擴散模型
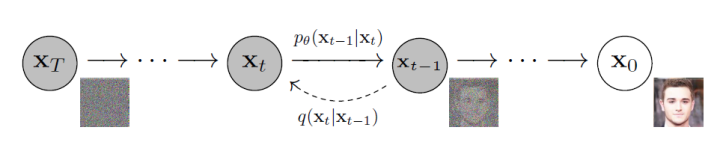
上圖展示了擴散模型的兩個過程。其中,從右到左(從到)表示正向過程或擴散過程,從左到右(從到)表示的是逆向過程。擴散過程逐步向原始圖像添加高斯噪聲,是一個固定的馬爾科夫鏈過程,最后圖像也被漸進變換為一個高斯噪聲。而逆向過程則通過去噪一步步恢復原始圖像,從而實現(xiàn)圖像的生成。下面形式化介紹擴散過程、逆擴散過程和目標函數(shù),主要參考DDPM[1]論文和What are Diffusion Models?[2]博客內(nèi)容。1.1 擴散過程設(shè)原始圖像,擴散過程進行步,每一步都向數(shù)據(jù)中添加方差為每一步都向數(shù)據(jù)中添加方差為,最終。所以,由馬爾科夫鏈的無記憶性,可對擴散過程進行如下定義:
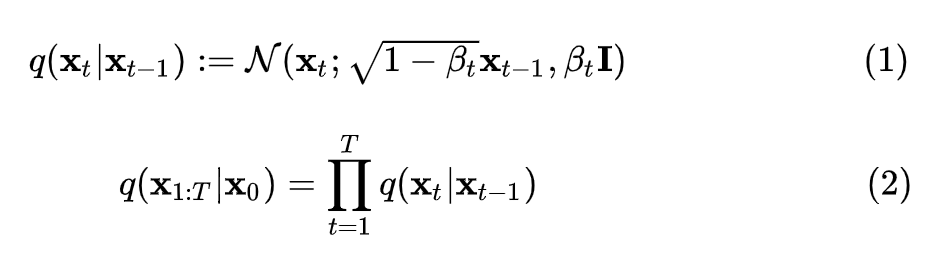
所以,擴散過程的均值和方差是已知的,其均值為,方差為。 擴散過程有一個顯著特性,我們可以對任意 進行采樣。為了證明該性質(zhì)需要使用參數(shù)重整化技巧:假設(shè)要從高斯分布中采樣時,可以先從采樣出 ,然后計算 ,這樣可以解決梯度無法回傳問題。 所以首先將進行重參數(shù)化:設(shè), 故: 設(shè),: 其中 ,第三行到第四行進行了兩個正態(tài)分布的相加。所以,重整化后 ,即 1.2 逆擴散過程 逆擴散過程是從給定的高斯噪聲中恢復原始數(shù)據(jù),也是一個馬爾可夫鏈過程,但每個時刻 的均值和方差需要我們?nèi)W習,所以,我們可以構(gòu)建生成模型 : 1.3 目標函數(shù)擴散模型使用負對數(shù)似然最小化的思想,采用近似的技術(shù)等價地要求負對數(shù)似然最小化。同時,由于KL散度具有非負性,因而將和的KL散度添加至負對數(shù)似然函數(shù)中,形成新的上界。 對于全部的訓練數(shù)據(jù),添加上式兩邊同乘 ,即:對上式進行化簡:上式中第四行到第五行,利用了馬爾可夫鏈的無記憶性和貝葉斯公式:第六行到第七行是第二個求和符號展開并化簡的結(jié)果。 上述過程在DDPM論文中的附錄部分也有展示。 觀察可知,項的兩個分布均已知,同時DDPM文中將項設(shè)置為一個特殊的高斯分布。故最后的目標只和有關(guān)。 同時,雖然無法直接給出,但當我們加入作為條件時,設(shè) 類似上面的處理,根據(jù)貝葉斯公式和馬爾可夫性質(zhì),可知 然后由公式(1)(4)可知: 由于高斯分布的概率密度函數(shù)是: 將上面兩個式子進行一一對應,可以得到均值: 所以,由高斯分布的KL散度計算式可知,可化為: 因此,我們可以直觀地看到其目標含義是模型預測的均值要盡可能和接近。然后,由公式 可知,輸入 不含參數(shù),則在給定時,若 能夠預測出,則也能夠計算出均值,所以同樣進行參數(shù)重整化,可得: 所以: DDPM論文中最終的簡化目標為: 所以可以看出,從預測均值變?yōu)榱酥苯宇A測噪聲,加快了推理速度。 2. Guided Diffusion DDPM論文提出之后,擴散模型就可以生成質(zhì)量比較高的圖片,具有較強的多樣性,但是在具體的指標數(shù)值上沒有超過GAN。同時,在協(xié)助用戶進行藝術(shù)創(chuàng)作和設(shè)計時,對生成的圖像進行細粒度控制也是一個重要的考慮因素。所以之后嘗試將一些具體的指導融入擴散模型中去。 2.1 Classifier Guidance 用于圖像生成的GAN的相關(guān)工作大量使用了類標簽,而我們也希望生成的圖片更加寫實,所以有必要探索在類標簽上調(diào)整擴散模型。具體來說,Diffusion Models Beat GANs[3]一文中使用了額外的分類器,在前面我們描述的無條件的逆向過程的基礎(chǔ)上,將類別作為條件進行生成,具體公式如下:
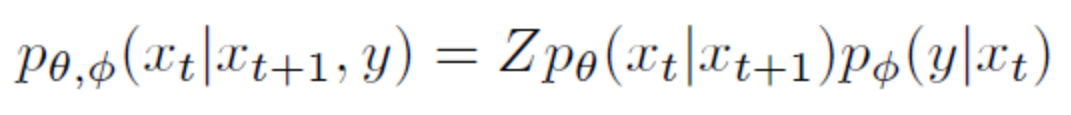
上式的含義是加入類別作為條件進行生成,可以看作無條件的生成和分類兩者的結(jié)合。具體而言,用分類模型對生成的圖片進行分類,得到預測與目標類別的交叉熵,從而使用梯度幫助模型的采樣和生成。 實際中,分類器是在噪聲數(shù)據(jù)上訓練的。 采樣過程的算法如下:

可以看到該過程中同時學習均值和方差,然后加入分類器的梯度引導采樣過程。 2.2 Semantic Diffusion Guidance (SDG) 看到分類器指導的圖像生成的有效性后,自然而然可以想到:是否可以將圖像類別信息換為其他不同類型的指導呢?比如使用CLIP模型作為圖像和文本之間的橋梁,實現(xiàn)文本指導的圖像生成。 Semantic Diffusion Guidance(SDG)[4]是一個統(tǒng)一的文本引導和圖像引導框架,通過使用引導函數(shù)來注入語義輸入,以指導無條件擴散模型的采樣過程,這使得擴散模型中的生成更加可控,并為語言和圖像引導提供了統(tǒng)一的公式。
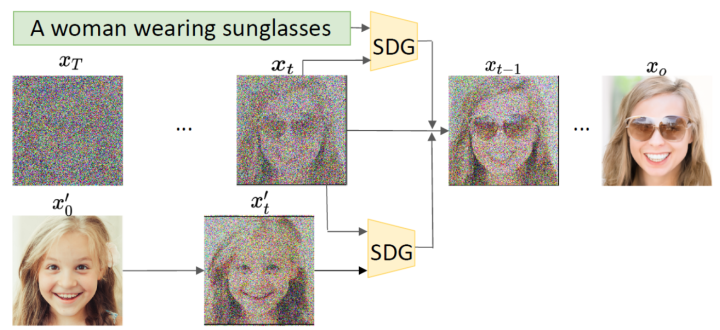

從采樣過程可以看出,不同的引導其實就是中的不同,可以是文本、圖像,也可以是兩者的結(jié)合。 2.3 Classifier-Free Guidance 以上方法都是使用了額外的模型,成本比較高,而且須在噪聲數(shù)據(jù)上進行訓練,無法使用預訓練好的分類器。Classifier-Free Guidance[5]一文提出在沒有分類器的情況下,純生成模型可以進行引導:共同訓練有條件和無條件擴散模型,并發(fā)現(xiàn)將兩者進行組合,可以得到樣本質(zhì)量和多樣性之間的權(quán)衡。 原來分類器指導的式子如下,表示條件,和含義類似:
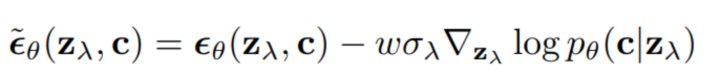
Classifier-Free Guidance方法將模型的輸入分為兩種,一種是無條件的 ,另一種是有條件的,使用一個神經(jīng)網(wǎng)絡來參數(shù)化兩個模型,對于無條件模型,我們可以在預測分數(shù)時簡單地為類標識符設(shè)為零,即。我們聯(lián)合訓練無條件和條件模型,只需將隨機設(shè)置為無條件類標識符即可。然后,使用以下有條件和無條件分數(shù)估計的線性組合進行抽樣:
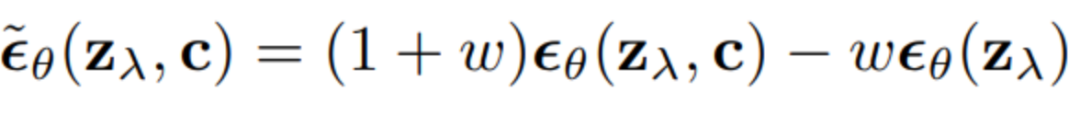
3. 應用
3.1 GLIDE OpenAI的GLIDE[6]將擴散模型和Classifier-Free Guidance進行結(jié)合去生成圖像。同時文中比較了兩種不同的引導策略:CLIP Guidance和Classifier-Free Guidance,然后發(fā)現(xiàn)Classifier-Free Guidance在照片寫實等方面更受人類評估者的青睞,并且通常會產(chǎn)生很逼真的樣本,并能實現(xiàn)圖像編輯。其中,Classifier-Free Guidance中的條件是文本。

下表是GLIDE在MS-COCO上的實驗結(jié)果。
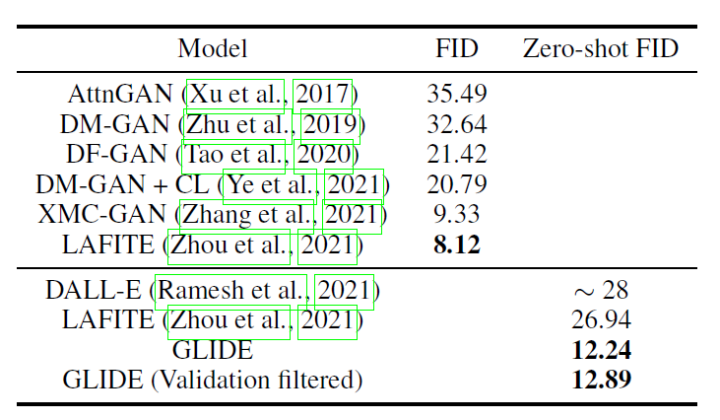
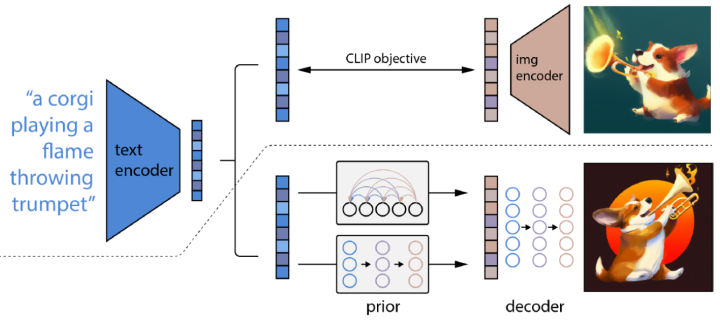
除了零樣本生成之外,GLIDE還具有編輯功能,允許迭代地改進模型樣本。 3.2 DALL·E 2 DALL·E2[7]利用CLIP來生成圖像,提出了一個兩階段模型:一個先驗prior網(wǎng)絡用于生成一個給定文本下的 CLIP 圖像嵌入,一個解碼器decoder在給定圖像編碼的情況下生成圖像。DALL·E2對解碼器使用擴散模型,并對先驗網(wǎng)絡使用自回歸模型和擴散模型進行實驗,發(fā)現(xiàn)后者在計算上更高效,并產(chǎn)生更高質(zhì)量的樣本。 具體來說:
prior :在給定文本條件下生成CLIP圖像的編碼,并且文中探索了兩種實現(xiàn)方式:自回歸和擴散,均使用classifier-free guidance,并且發(fā)現(xiàn)擴散模型的效果更好:
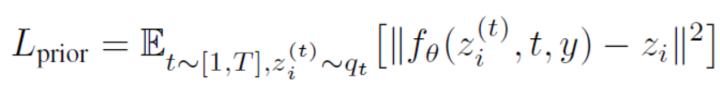
注意此處目標和前面有所不同,prior直接去預測圖像特征,而不是預測噪聲
decoder:在圖像編碼(和可選的文本標題)條件下生成圖像;使用擴散模型并利用classifier-free guidance和CLIP guidance在給定CLIP圖像編碼的情況下生成圖像。為了生成高分辨率圖像,訓練了兩個擴散上采樣模型,分別用于將圖像從64*64上采樣到256*256、進一步上采樣到1024*1024。
將這兩個部分疊加起來會得到一個生成模型可以在給定標題下生成圖像:。第一個等號是由于和是一對一的關(guān)系。
所以DALL·E2可以先用prior采樣出,然后用decoder得到;
DALL·E2能夠生成高分辨率、風格多樣的圖片,并且能夠給定一張圖,生成許多風格類似的圖片;可以進行兩張圖片的插值,實現(xiàn)風格的融合等,在具體數(shù)值上也超越了GLIDE。
3.3 Imagen 下圖是谷歌提出的Imagen[8]的模型架構(gòu):
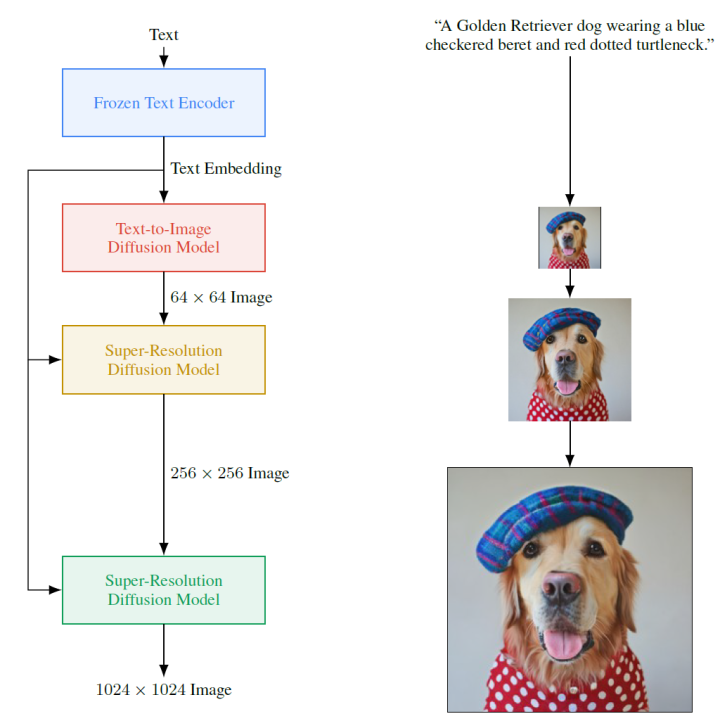
Imagen由一個文本編碼器和一連串條件擴散模型組成。
預訓練文本編碼器:語言模型是在文本語料庫上訓練的,該語料庫比配對的圖像-文本數(shù)據(jù)要大得多,因此可以接觸到非常豐富和廣泛的文本分布。文中使用Frozen Text Encoder進行文本的編碼
擴散模型和classifier-free guidance:使用前面提到的classifier-free guidance,將文本編碼作為條件,進行圖像的生成。同樣,后面也有兩個擴散模型進行分辨率的提升,最終可以生成1024*1024分辨率的圖像。文本到圖像擴散模型使用改進的U-Net 架構(gòu),生成64*64 圖像,后面兩個擴散模型使用本文提出Efficient U-Net,可以更節(jié)省內(nèi)存和時間。
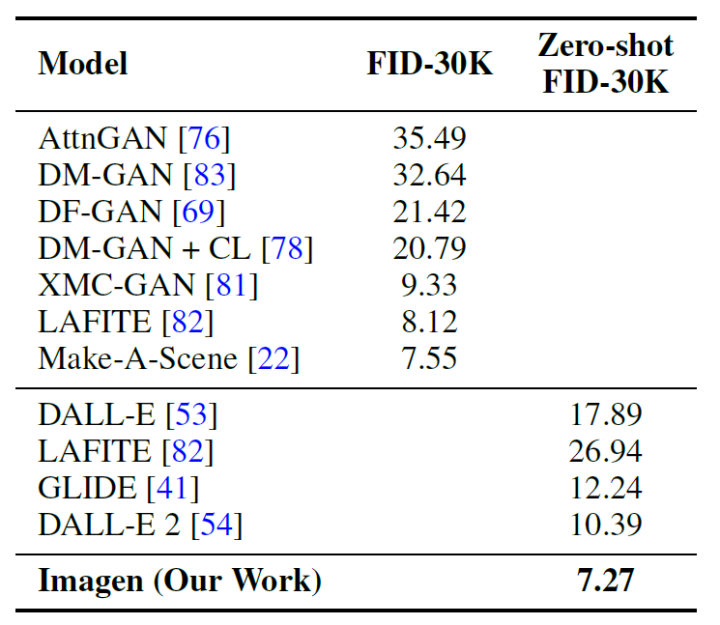
我們使用FID分數(shù)在COCO驗證集上評估Imagen,下表展示了結(jié)果。Imagen在COCO上實現(xiàn)了最好的zero-shot效果,其FID為7.27,優(yōu)于前面的一系列工作。

審核編輯 :李倩
-
圖像
+關(guān)注
關(guān)注
2文章
1087瀏覽量
40499 -
模型
+關(guān)注
關(guān)注
1文章
3261瀏覽量
48914 -
擴散模型
+關(guān)注
關(guān)注
0文章
5瀏覽量
5554
原文標題:文本生成 | 擴散模型與其在文本生成圖像領(lǐng)域的應用
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
借助谷歌Gemini和Imagen模型生成高質(zhì)量圖像

擴散模型的理論基礎(chǔ)

如何使用 Llama 3 進行文本生成
如何評估AI大模型的效果
AI大模型在自然語言處理中的應用
【《大語言模型應用指南》閱讀體驗】+ 基礎(chǔ)知識學習
Transformer語言模型簡介與實現(xiàn)過程
llm模型和chatGPT的區(qū)別
【大語言模型:原理與工程實踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
OpenVINO?協(xié)同Semantic Kernel:優(yōu)化大模型應用性能新路徑
KOALA人工智能圖像生成模型問世
Stability AI試圖通過新的圖像生成人工智能模型保持領(lǐng)先地位

Adobe提出DMV3D:3D生成只需30秒!讓文本、圖像都動起來的新方法!

深入探索知名大模型的實際應用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論