") 利用視覺語言模型對檢測器進行預(yù)訓(xùn)練
利用視覺語言模型對檢測器進行預(yù)訓(xùn)練
本文簡要介紹了發(fā)表于CVPR 2022的論文“Vision-Language Pre-Trainingfor Boosting Scene Text Detector”的相關(guān)工作。大規(guī)模預(yù)訓(xùn)練在視覺任務(wù)中有著重要的作用,而視覺語言模型與多模態(tài)的特征聯(lián)合近期也收到了廣泛的關(guān)注。本文針對場景文本檢測的問題,提出了利用視覺語言模型對檢測器進行預(yù)訓(xùn)練,通過設(shè)計Image-text Contrastive Learning、Masked LanguageModeling和Word-in-image Prediction三個預(yù)訓(xùn)練任務(wù)有效得結(jié)合文本、圖像兩個模態(tài)的特征,幫助主干網(wǎng)絡(luò)提取到更豐富的視覺與語義特征,以此提高文本檢測器的性能。該預(yù)訓(xùn)練方法可以有效提升各文本檢測器在各大公開場景文本數(shù)據(jù)集上的評估結(jié)果。
一、研究背景
預(yù)訓(xùn)練通常被用于自然語言處理以及計算機視覺領(lǐng)域,以增強主干網(wǎng)絡(luò)的特征提取能力,達到加速訓(xùn)練和提高模型泛化性能的目的。該方法亦可以用于場景文本檢測當(dāng)中,如最早的使用ImageNet預(yù)訓(xùn)練模型初始化參數(shù),到使用合成數(shù)據(jù)直接預(yù)訓(xùn)練檢測器再在真實數(shù)據(jù)上Finetune,再到通過定義一些預(yù)訓(xùn)練任務(wù)訓(xùn)練網(wǎng)絡(luò)參數(shù)等。但這些方法都存在一些問題,比如中合成數(shù)據(jù)與真實數(shù)據(jù)的Domain Gap導(dǎo)致模型在真實場景下Finetune效果不佳,中沒有充分利用視覺與文本之間的聯(lián)系。基于這些觀察,本文提出了一個通過視覺語言模型進行圖像、文本兩個模態(tài)特征對齊的預(yù)訓(xùn)練方法VLPT-STD,用于提升場景文本檢測器的性能。
二、方法介紹
本文提出了一個全新的用于場景文本檢測預(yù)訓(xùn)練的框架—VLPT-STD,它基于視覺語言模型設(shè)計,可以有效地利用文本、圖像兩種模態(tài)的特征,使得網(wǎng)絡(luò)提取到更豐富的特征表達。其算法流程如圖1所示,主要分為Image Encoder,Text Encoder以及Cross-model Encoder三個部分,并且設(shè)計了三個預(yù)訓(xùn)練任務(wù)讓網(wǎng)絡(luò)學(xué)習(xí)到跨模態(tài)的表達,提高網(wǎng)絡(luò)的特征提取能力。
2.1 模型結(jié)構(gòu)
Image Encoder用于提取場景文本圖片的視覺特征編碼,Text Encoder則提取圖片中文本內(nèi)容的編碼,最后視覺特征編碼和文本內(nèi)容編碼一起輸入Cross-model Encoder當(dāng)中進行多模態(tài)特征融合。
Image Encoder 包含了一個ResNet50-FPN的主干網(wǎng)絡(luò)結(jié)構(gòu)和一個注意力池化層。場景文本圖像首先輸入到ResNet50-FPN中得到特征,然后通過注意力池化層得到一個圖像特征編碼序列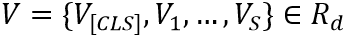 ,
,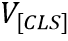 代表[CLS] Token的編碼,S代表視覺Token的數(shù)量,d是維度。注意力池化層是一層Transformer中的多頭注意力模塊。
代表[CLS] Token的編碼,S代表視覺Token的數(shù)量,d是維度。注意力池化層是一層Transformer中的多頭注意力模塊。
Text Encoder先將輸入的文本轉(zhuǎn)化成一個編碼序列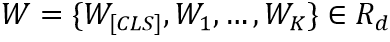 ,K代表序列長度,然后通過三層多頭注意力模塊得到文本特征編碼。
,K代表序列長度,然后通過三層多頭注意力模塊得到文本特征編碼。
Cross-model由四個相同的Transformer Decoder組成,它將視覺編碼序列和文本編碼序列W結(jié)合到了一起,并將其最后的輸出用于預(yù)測Masked Language Modeling預(yù)訓(xùn)練任務(wù)。
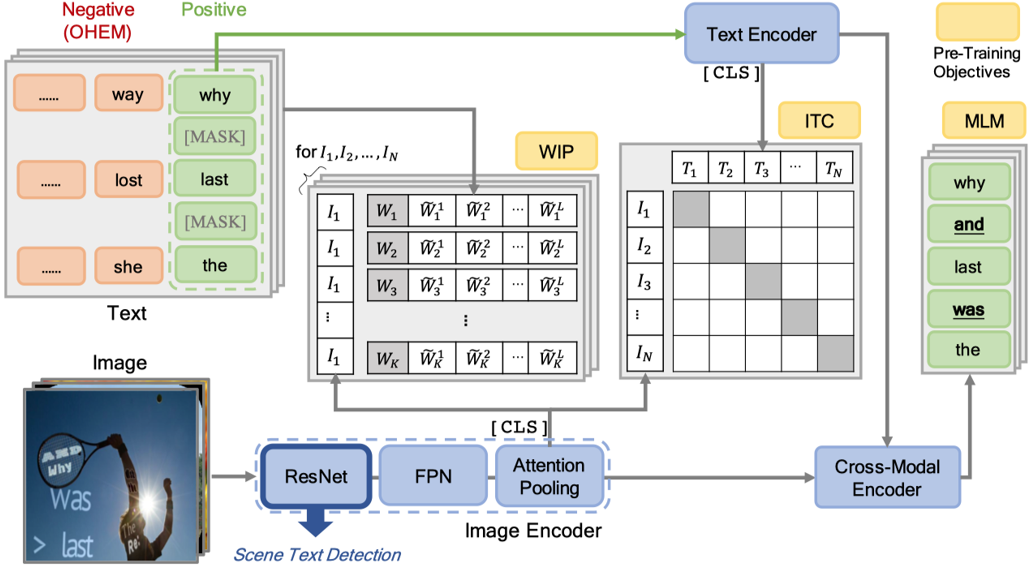
圖1 VLPT-STD整體框架
2.2 預(yù)訓(xùn)練任務(wù)
本文定義了三個預(yù)訓(xùn)練任務(wù),包括Image-text Contrastive Learning(ITC)、Word-in-image Prediction(WIP)和Masked Language Modeling(MLM)。
Image-text Contrastive Learning(ITC)的目的是使得文本編碼序列的每一項都能在視覺編碼序列中找到最相似的編碼,也就是讓每個單詞的文本編碼與其對應(yīng)的文本圖片區(qū)域視覺特征匹配(例如,“Last”的Text Embedding與圖片中“Last”位置的區(qū)域特征相似度最高)。
該任務(wù)對每個圖像編碼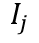 和文本編碼
和文本編碼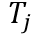 分別運用InfoNCE loss[4]去計算相似度。
分別運用InfoNCE loss[4]去計算相似度。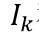 和
和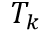 代表一個Batch內(nèi)所有的圖像編碼和文本編碼,它們分別為Image Encoder得到的和Text Encoder得到的
代表一個Batch內(nèi)所有的圖像編碼和文本編碼,它們分別為Image Encoder得到的和Text Encoder得到的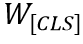 。
。
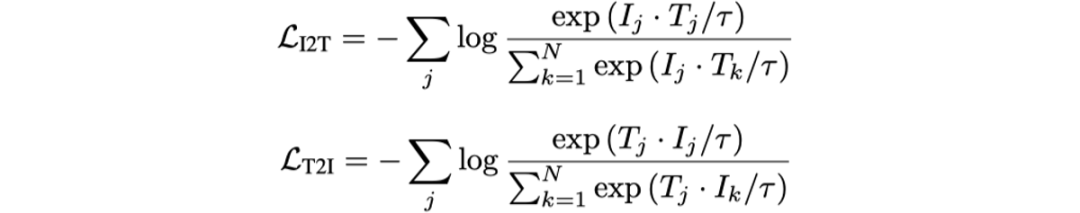
N代表Batch Size。ITC任務(wù)最終的損失函數(shù)為: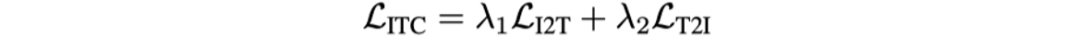
Word-in-Image Prediction(WIP)是通過在圖像編碼和文本單詞編碼中應(yīng)用對比學(xué)習(xí)去區(qū)分出現(xiàn)在圖片中的文本(正類)與不存在德文本(負類),從而預(yù)測給定的一組單詞是否出現(xiàn)在輸入圖片中。如圖1左上角所示,訓(xùn)練時圖片中有的單詞作為正樣本,其編碼為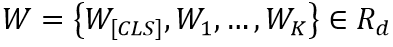 ;負樣本則是訓(xùn)練過程中基于文本編碼的相似度進行采樣得到(如對于正樣本“Lost”,負樣本可為“Lose”,“Last”等),文中選取的是Top-L(L=63)相似的文本,對于每一個正樣本的編碼
;負樣本則是訓(xùn)練過程中基于文本編碼的相似度進行采樣得到(如對于正樣本“Lost”,負樣本可為“Lose”,“Last”等),文中選取的是Top-L(L=63)相似的文本,對于每一個正樣本的編碼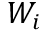 ,其負樣本編碼為
,其負樣本編碼為
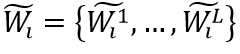
。輸入圖片為I,WIP的損失函數(shù)定義如下:
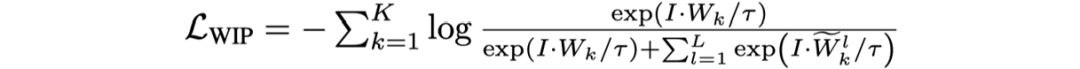
MaskedLanguage Modeling (MLM)類似于BERT,該任務(wù)首先隨機掩蓋文本編碼w,然后讓網(wǎng)絡(luò)利用所有的視覺特征編碼v和未被掩蓋的文本編碼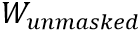 預(yù)測缺失的單詞文本
預(yù)測缺失的單詞文本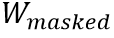 。如圖1所示,圖片中的文本“And”,“Was”等被掩蓋,MLM任務(wù)是將它們預(yù)測恢復(fù)。其損失函數(shù)如下所示:
。如圖1所示,圖片中的文本“And”,“Was”等被掩蓋,MLM任務(wù)是將它們預(yù)測恢復(fù)。其損失函數(shù)如下所示:
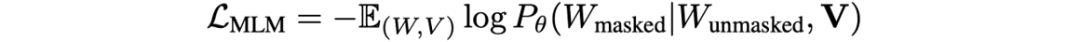
最終的損失函數(shù)為:
三、實驗
3.1 實驗細節(jié)
本文提出的VLPT-STD在SynthText [5]上進行預(yù)訓(xùn)練,然后將預(yù)訓(xùn)練得到的主干網(wǎng)絡(luò)用于EAST [6],PSENet [7]和DB[2]這三個文本檢測器在各個公開的真實場景數(shù)據(jù)集上進行Finetune。實驗使用了八塊v100,Batch Size為800。
3.2 與State-of-the-art的方法比較
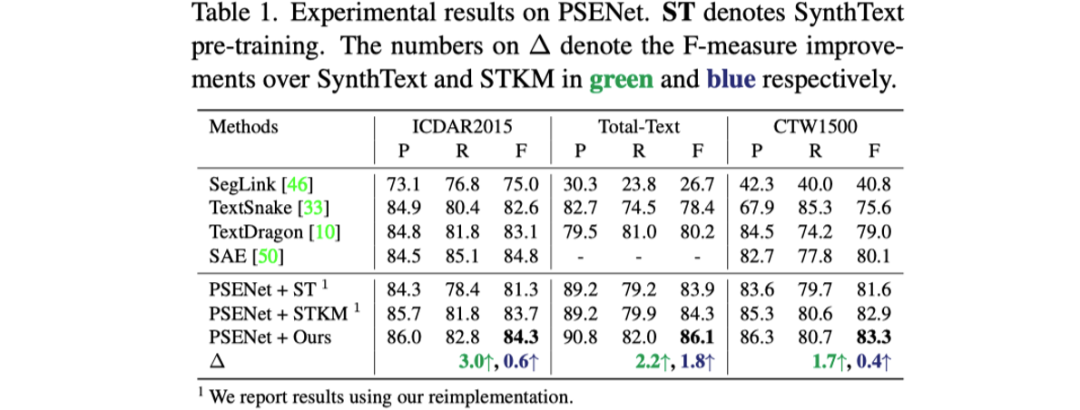
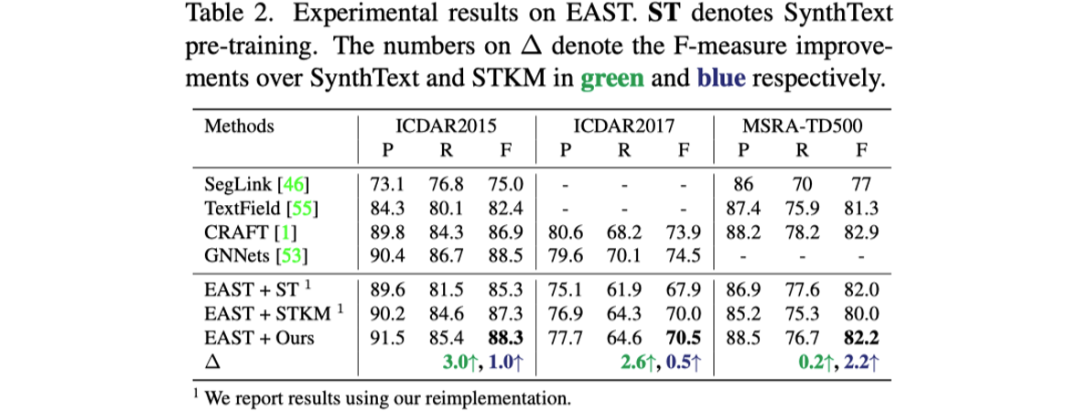
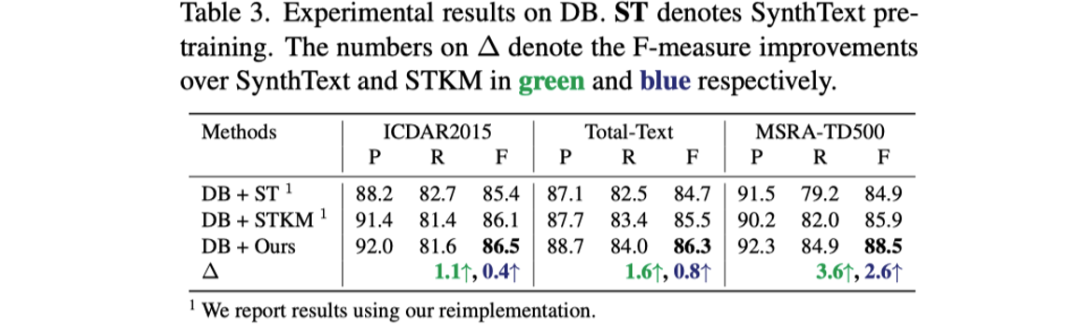
表格1到表格3展示了文章提出的預(yù)訓(xùn)練方法與之前預(yù)訓(xùn)練方法對于三個不同的文本檢測器性能提升的對比。
3.2 消融實驗
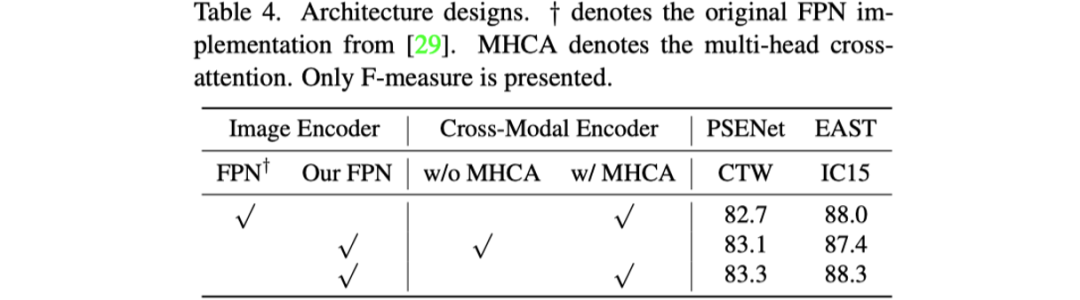
首先是對模型設(shè)計的消融實驗,如表格4所示。文章探究了Image Encoder中作者改進的FPN結(jié)構(gòu)和Cross-model Encoder中Cross-attention的作用。
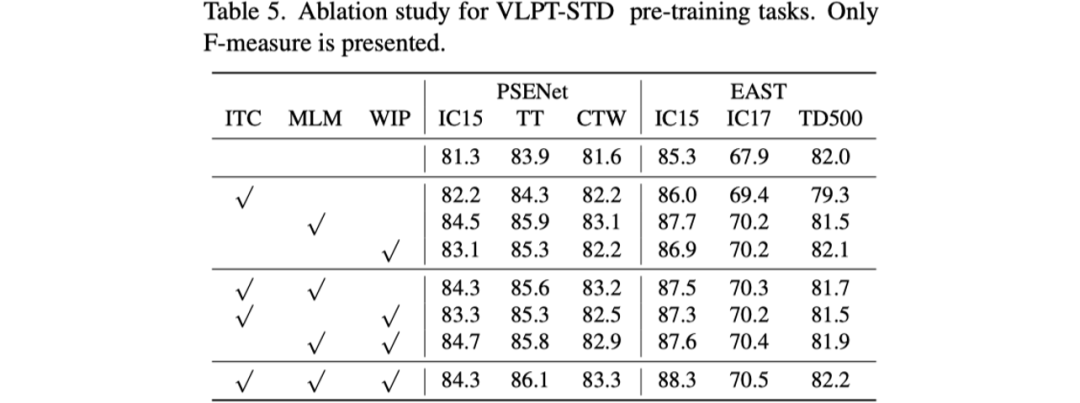
其次是對預(yù)訓(xùn)練任務(wù)的消融實驗,如表格5所示。
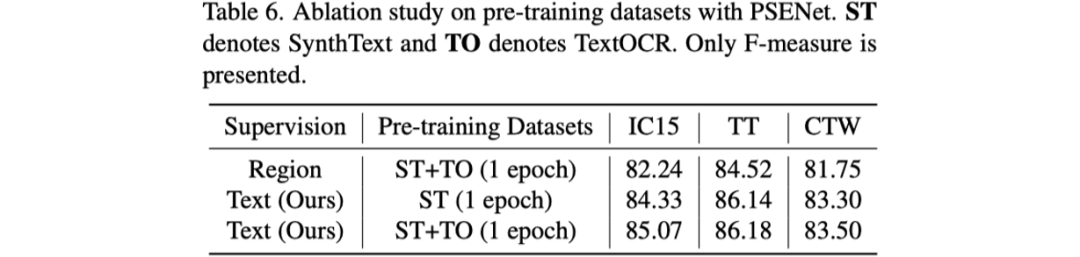
最后是對預(yù)訓(xùn)練的數(shù)據(jù)集進行了探究,作者對比了SynthText和TextOCR [8]兩種數(shù)據(jù)集,結(jié)果如表6所示。
3.3 可視化結(jié)果
文章首先展示了Cross-model當(dāng)中Attention Map的可視化結(jié)果。可以看到一個文本是與Attention Map中高亮區(qū)域是一一匹配的。

然后文章展示了和之前預(yù)訓(xùn)練方法STKM [3] 對比的檢測結(jié)果。

四、總結(jié)與討論
在場景文本檢測當(dāng)中,本文是第一篇用視覺語言模型以及多模態(tài)特征融合的思路去設(shè)計預(yù)訓(xùn)練任務(wù)以提升文本檢測性能的工作,它設(shè)計了三個簡單有效的任務(wù),提高了主干網(wǎng)絡(luò)對文本圖像特征的表征能力。如何利用文本和圖像兩種模態(tài)的特征也是未來OCR領(lǐng)域的一個重要方向。
原文作者:Sibo Song, Jianqiang Wan, Zhibo Yang, Jun Tang, Wenqing Cheng, Xiang Bai, Cong Yao
審核編輯:郭婷
-
檢測器
+關(guān)注
關(guān)注
1文章
863瀏覽量
47676 -
計算機
+關(guān)注
關(guān)注
19文章
7488瀏覽量
87849
原文標(biāo)題:CVPR 2022 | 阿里&華科提出:針對場景文本檢測的視覺語言模型預(yù)訓(xùn)練
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
一文詳解知識增強的語言預(yù)訓(xùn)練模型
【大語言模型:原理與工程實踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實踐】大語言模型的預(yù)訓(xùn)練
預(yù)訓(xùn)練語言模型設(shè)計的理論化認識
一種脫離預(yù)訓(xùn)練的多尺度目標(biāo)檢測網(wǎng)絡(luò)模型

如何向大規(guī)模預(yù)訓(xùn)練語言模型中融入知識?

基于預(yù)訓(xùn)練視覺-語言模型的跨模態(tài)Prompt-Tuning






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論