 如何在不增加額外參數量的前提下把模型的表達能力挖掘到極致
如何在不增加額外參數量的前提下把模型的表達能力挖掘到極致
今天跟大家分享一篇來自CMU等機構的論文《Sliced Recursive Transformer》,該論文已被 ECCV 2022 接收。
目前 vision transformer 在不同視覺任務上如分類、檢測等都展示出了強大的性能,但是其巨大的參數量和計算量阻礙了該模型進一步在實際場景中的應用。基于這個考慮,本文重點研究了如何在不增加額外參數量的前提下把模型的表達能力挖掘到極致,同時還要保證模型計算量在合理范圍內,從而可以在一些存儲容量小,計算能力弱的嵌入式設備上部署。
基于這個動機,Zhiqiang Shen、邢波等研究者提出了一個 SReT 模型,通過循環遞歸結構來強化每個 block 的特征表達能力,同時又提出使用多個局部 group self-attention 來近似 vanilla global self-attention,在顯著降低計算量 FLOPs 的同時,模型沒有精度的損失。

論文地址:https://arxiv.org/abs/2111.05297
代碼和模型:https://github.com/szq0214/SReT
總結而言,本文主要有以下兩個創新點:
使用類似 RNN 里面的遞歸結構(recursive block)來構建 ViT 主體,參數量不漲的前提下提升模型表達能力;
使用 CNN 中 group-conv 類似的 group self-attention 來降低 FLOPs 的同時保持模型的高精度;
此外,本文還有其他一些小的改動:
網絡最前面使用三層連續卷積,卷積核為 3x3,結構直接使用了研究者之前 DSOD 里面的 stem 結構;
Knowledge distillation 只使用了單獨的 soft label,而不是 DeiT 里面 hard 形式的 label 加 one-hot ground-truth,因為研究者認為 soft label 包含的信息更多,更有利于知識蒸餾;
使用可學習的 residual connection 來提升模型表達能力;
如下圖所示,本文所提出的模型在參數量(Params)和計算量(FLOPs)方面相比其他模型都有明顯的優勢:
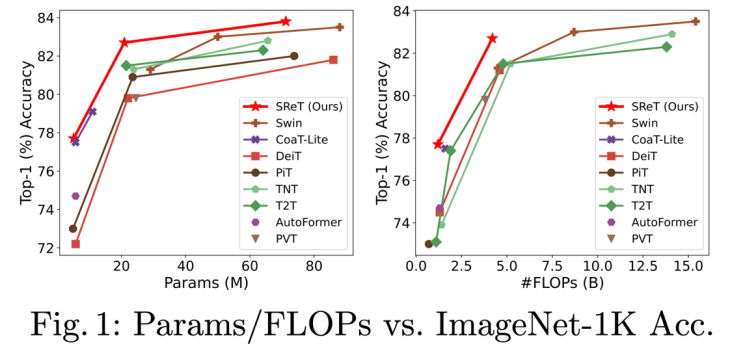
下面我們來解讀這篇文章: 1.ViT 中的遞歸模塊 遞歸操作的基本組成模塊如下圖:
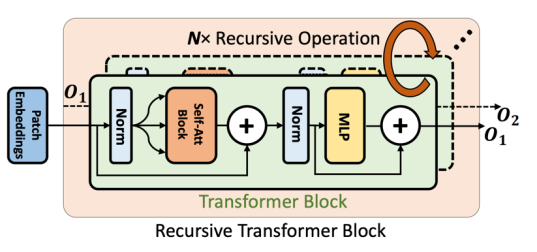
該模塊非常簡單明了,類似于 RNN 結構,將模塊當前 step 的輸出作為下個 step 的輸入重新輸進該模塊,從而增強模型特征表達能力。 研究者展示了將該設計直接應用在 DeiT 上的結果,如下所示:
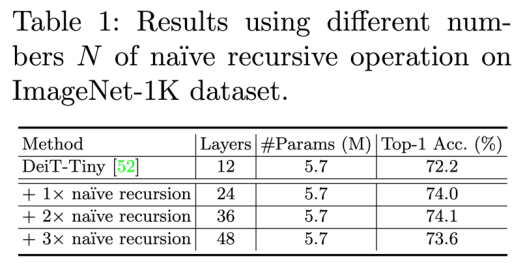
可以看到在加入額外一次簡單遞歸操作之后就可以得到將近 2% 的精度提升。 當然具體到全局網絡結構層面還有不同的遞歸構建方法,如下圖:
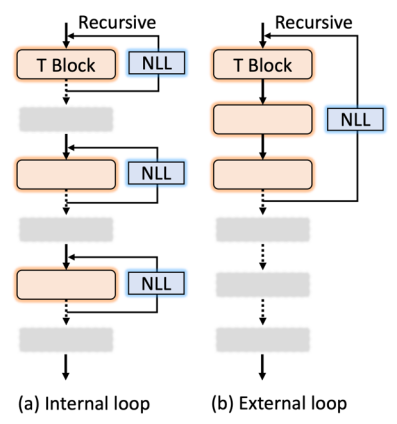
其中 NLL 層(Non-linear Projection Layer)是用來保證每個遞歸模塊輸入輸出不完全一致。論文提出使用這個模塊的主要原因是發現在上述 Table 1 里面更多次數的遞歸操作并沒有進一步提升性能,說明網絡可能學到了一個比較簡單的狀態,而 NLL 層可以強制模型輸入輸出不一致從而緩解這種情況。同時,研究者從實驗結果發現上圖 (1) internal loop 相比 external loop 設計擁有更好的 accuracy-FLOPs 結果。 2. 分組的 Group Self-attention 模塊 如下圖所示,研究者提出了一種分組的 group self-attention 策略來降低模型的 FLOPs,同時保證 self-attention 的全局注意力,從而使得模型沒有明顯精度損失:
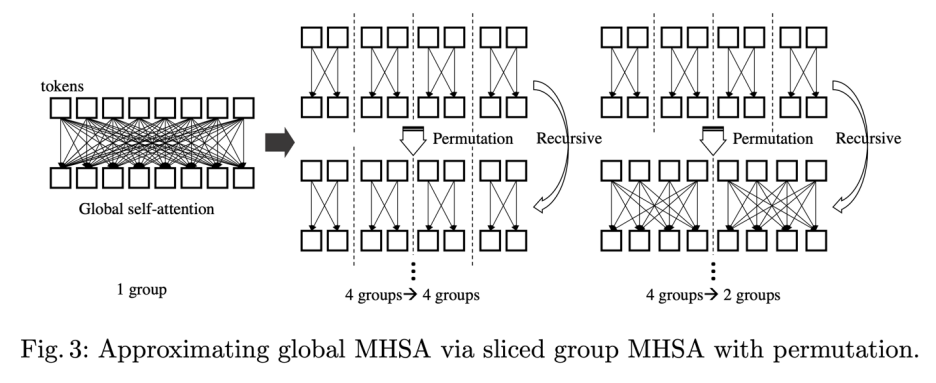
Group Self-attention 模塊具體形式如下:
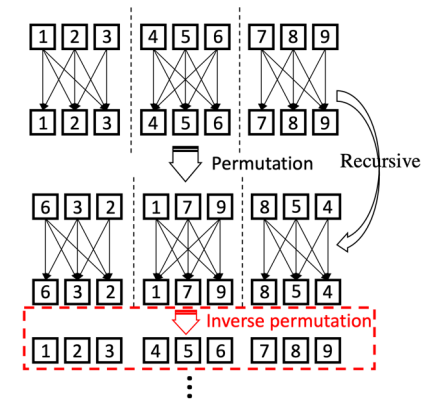
Group self-attention 的缺點是只有局部區域會相互作用,研究者提出通過使用 Permutation 操作來近似全局 self-attention 的機制,同時通過 Inverse Permutation 來復原和保留 tokens 的次序信息,針對這個部分的消融實驗如下所示:
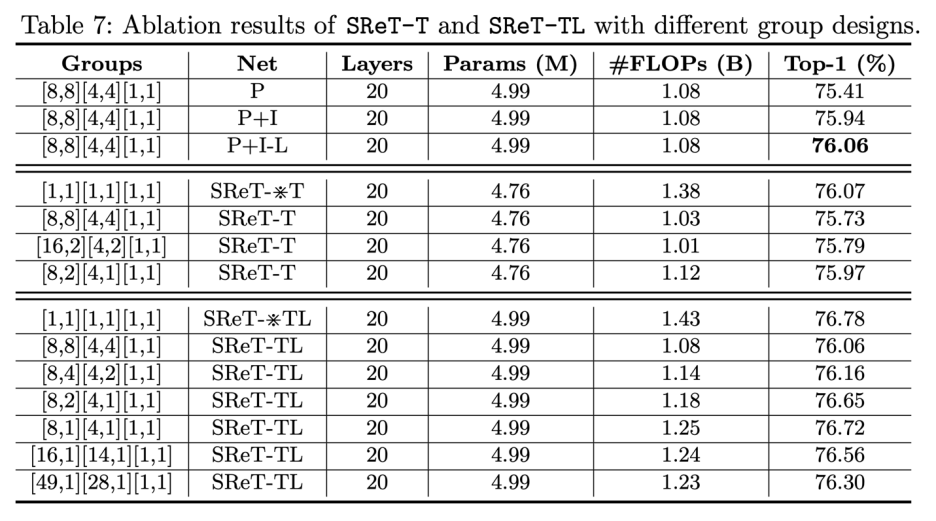
其中 P 表示加入 Permutation,I 表示加入 Inverse Permutation,-L 表示如果 group 數為 1,就不使用 P 和 I(比如模型最后一個 stage)。根據上述表格的結果,研究者最后采用了 [8, 2][4,1][1,1] 這種分組設計。 3. 其他設計 可學習的殘差結構 (LRC):
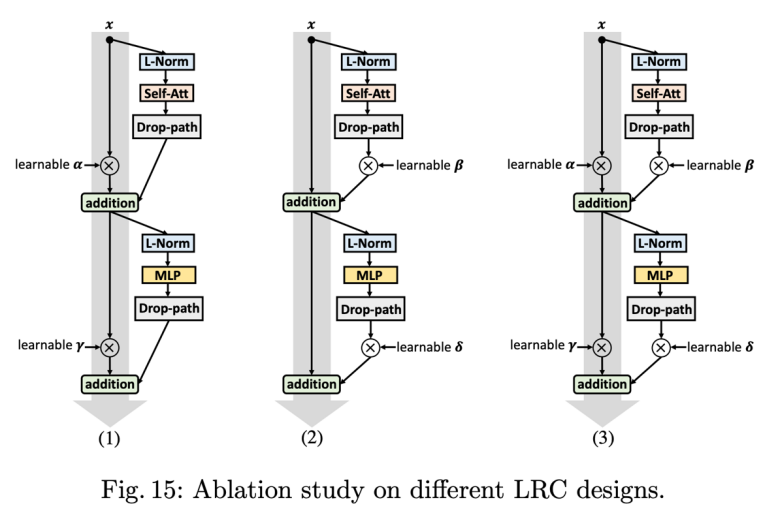
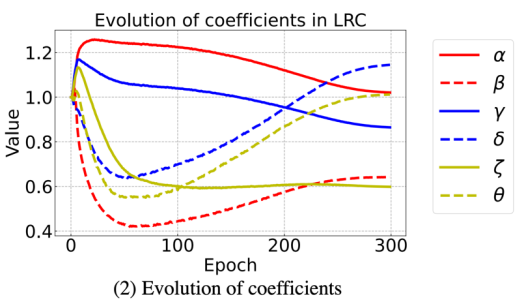
研究者嘗試了上圖三種結構,圖(3)結果最佳。具體而言,研究者在每個模塊里面添加了 6 個額外參數(4+2,2 個在 NLL 層),這些參數會跟模型其他參數一起學習,從而使網絡擁有更強的表達能力,參數初始化都為 1,在訓練過程 6 個參數的數值變化情況如下所示:
Stem 結構組成:
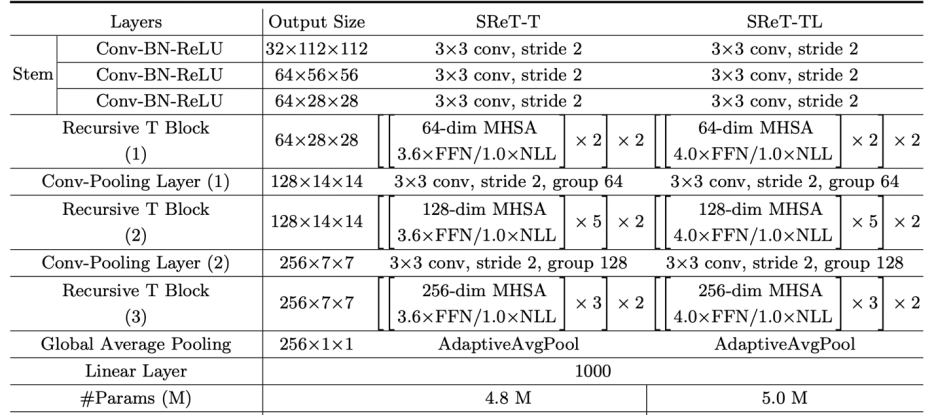
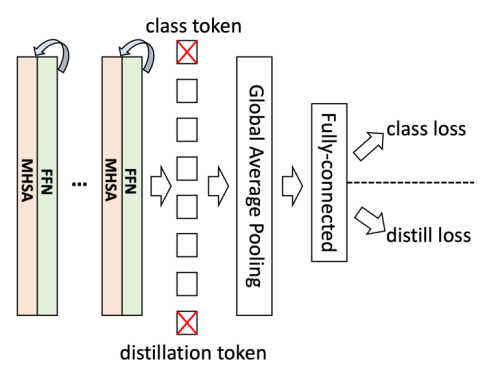
如上表所示,Stem 由三個 3x3 的連續卷積組成,每個卷積 stride 為 2。 整體網絡結構: 研究者進一步去掉了 class token 和 distillation token,并且發現精度有少量提升。
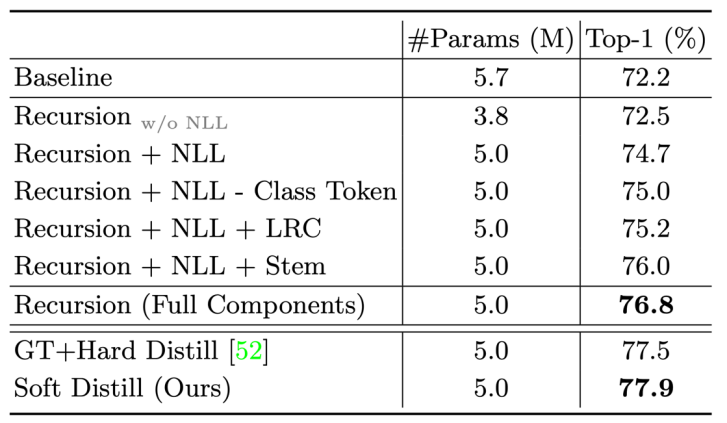
消融實驗:
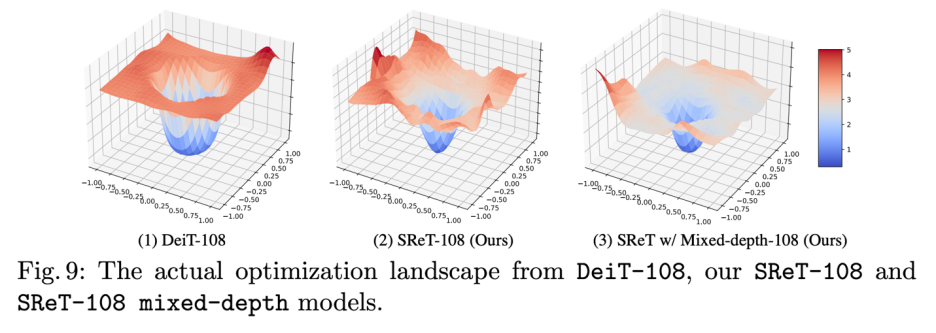
模型混合深度訓練: 研究者進一步發現分組遞歸設計還有一個好處就是:可以支持模型混合深度訓練,這種訓練方式可以大大降低深度網絡結構優化復雜度,研究者展示了 108 層不同模型結構優化過程的 landscape 可視化,如下圖所示,可以很明顯的看到混合深度結構優化過程困難程度顯著低于另外兩種結構。
最后,分組 group self-attention 算法 PyTorch 偽代碼如下:

審核編輯 :李倩
-
模型
+關注
關注
1文章
3227瀏覽量
48809 -
遞歸
+關注
關注
0文章
28瀏覽量
9013 -
cnn
+關注
關注
3文章
352瀏覽量
22204
原文標題:ECCV 2022 | 視覺Transformer上進行遞歸!SReT:不增參數,計算量還少!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI時代,華天科技熱仿真分析為芯片散熱保駕護航
PCB層數增加對成本有哪些影響
PCB層數增加對成本的影響分析

OPA320與OPA320S在確保運放精度能達到穩定的前提下盡量做到低功耗應該如何選擇?
USB頻譜分析儀在滿足低成本預算的前提下能夠提供出色的性能
安寶特產品 3D Evolution : 基于特征實現無損CAD格式轉換
科普講座 | 讓AIGC提高你的專業表達和創作能力

微軟發布MatterSim模型,精準預測材料性能與行為
STM32跟wifi模塊通過USB在沒有host的前提下如何交互呢?
【大語言模型:原理與工程實踐】大語言模型的應用
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
NTT、NEC聯手完成首個跨洋7280千米光網絡傳輸實驗,提升帶寬
5G RedCap通信標準化工作進程





 工商網監
工商網監
評論