 佐思汽研發布《2022年中國自動駕駛數據閉環研究報告》
佐思汽研發布《2022年中國自動駕駛數據閉環研究報告》
佐思汽研發布《2022年中國自動駕駛數據閉環研究報告》。
一、自動駕駛發展逐步從技術驅動轉向數據驅動
如今,自動駕駛傳感器方案及計算平臺已日趨同質化,供應商技術差距日益收窄。近兩年自動駕駛技術迭代飛速推進,量產落地加速。根據佐思數據中心,2021年,國內L2級輔助駕駛乘用車上險量累計達479.0萬輛,同比增長 58.0%。2022年1-6月,中國L2級輔助駕駛在乘用車新車市場滲透率攀升至32.4%。
對于自動駕駛而言,數據貫穿研發、測試、量產、運營維護等全生命周期。伴隨智能網聯汽車傳感器數量的快速增加,ADAS和自動駕駛車輛數據的生成量也呈現指數級增長,從GB到TB、PB、EB直至將來的ZB。以數據驅動的汽車進化,滿足用戶個性化的需求,車企才能走實走遠。
根據《汽車采集數據處理安全指南》,汽車采集數據是指汽車傳感設備、控制單元采集的數據,以及對其進行加工后產生的數據,可細分為車外數據、座艙數據、運行數據和位置軌跡數據等。
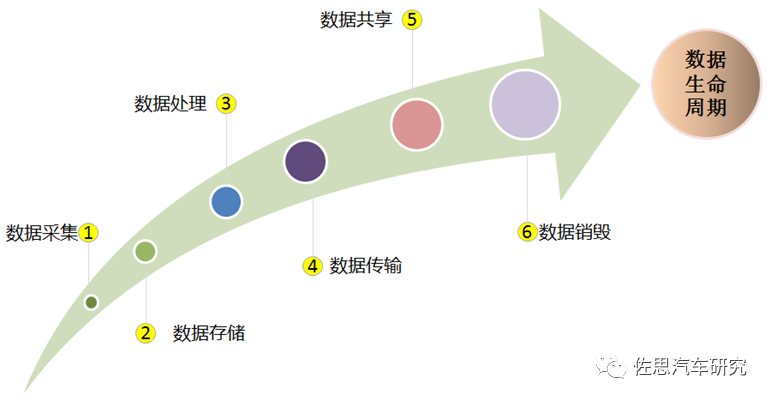
根據網信辦2021年8月頒布的《汽車數據安全管理若干規定(試行)》對汽車數據收集、分析、存儲、傳輸、查詢、應用、刪除等全流程做了詳細的規定。在開展汽車數據處理過程中堅持“車內處理”、“默認不收集”、“精度范圍適用”、“脫敏處理”等數據處理原則,減少對汽車數據的無序收集和違規濫用。在自動駕駛技術開發過程中,數據收集及處理等首先要合法合規。
數據采集/清洗
從汽車攝像頭、毫米波雷達、激光雷達及超聲波雷達收集來的大量非結構化數據(圖像、視頻、語音)可能是原始的和混亂的。為使數據有意義,需對其進行清理、結構化與整理。首先將來自多個來源的數據導入適當的存儲庫,標準化數據格式,并根據相關規則進行聚合。而后檢查損壞、重復或丟失的數據點,并丟棄可能影響數據集整體質量的不需要的數據。最后,用標簽對在不同條件下捕獲的視頻進行分類,例如白天、夜晚、晴天、下雨等。此步驟提供了對將用于訓練、驗證的清洗后的結構化數據。
數據標注
對數據采集后經過清洗的結構化數據需要進行標注。標注是將編碼值分配給原始數據的過程。編碼值包括但不限于分配類標簽、繪制邊界框和標記對象邊界。需要高質量的標注來教授監督學習模型對象是什么以及測量訓練模型的性能。
在自動駕駛領域,數據標注處理的場景通常包括換道超車、通過路口、無紅綠燈控制的無保護左轉、右轉,以及一些復雜的長尾場景諸如闖紅燈車輛、橫穿馬路的行人、路邊違章停靠的車輛等。
常用的標注工具包括圖片通用拉框、車道線標注、駕駛員面部標注、3D點云標注、2D/3D融合標注、全景語義分割等。由于大數據的發展和大型數據集數量的增加,數據標注工具的使用不斷迅速擴大。
數據傳輸
如今,數據采集的頻率已進入毫秒級別,需要的是數千個信號維度(如總線信號、傳感器內部狀態、軟件埋點、用戶行為及環境感知數據等)的高精度數據,同時避免數據丟失、亂序、跳變及延時,并在高精度高質量前提下,極大壓縮傳輸/存儲成本。車聯網數據的上下行鏈路比較長(從車端MCU、DCU、網關、4G/5G到云端)需要保證各鏈路節點的數據傳輸質量。
針對數據傳輸的新變化,部分企業已能提供高效的數據采集及車云一體傳輸方案,例如智協慧同EXCEEDDATA靈活數采平臺方案,在車端邊緣計算環境基于實時數據,實現了10毫秒級實時運算,用于觸發靈活數據采集上傳功能,上傳的數據已經經過計算和篩選,顯著降低上傳的數據量。此外對車端原始信號進行100-300倍無損壓縮和存儲,云端管理平臺保存無損高壓縮比的車端高質量信號, 支持數采算法的下發、多種采集模式的觸發、采集數據實時上傳到業務桌面的一鍵式下載,按車輛、按事件、按時間段等多重靈活篩選,隨用隨解,存算分離,實現了車云同構的數據采集-計算-上傳-加工的閉環;2021年,國內首個搭載智協慧同EXCEEDDATA解決方案的量產車型已落地(高合HiPhiX)。
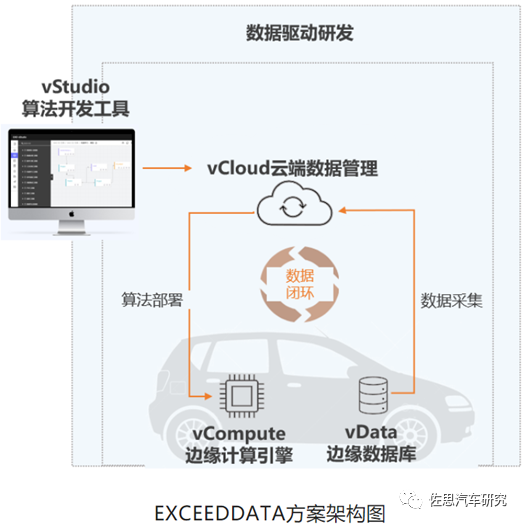
來源:智協慧同
數據存儲
為更清晰感知周圍環境,自動駕駛汽車增配更多傳感器,并生成大量數據。一些高等級自動駕駛系統甚至配置40多個各類傳感器,對車輛周邊360°環境準確感知。自動駕駛系統的研發需經過數據采集、數據匯聚、清洗標記、模型訓練、模擬仿真、大數據分析等多個環節,期間涉及對海量數據的匯聚存儲,不同環節不同系統之間的數據流轉,以及模型訓練時對海量數據的讀寫。數據面臨存儲瓶頸的新挑戰。
為此,眾多云服務提供商在這方面的技術和能力成為了幫助車企制勝的關鍵。比如亞馬遜云科技AWS以自動駕駛數據湖為中心,助力車企構建起端到端的自動駕駛數據閉環。借助Amazon Simple Storage Service (Amazon S3,云上對象存儲服務)構建自動駕駛數據湖,實現數據采集、數據管理和分析、數據標注、模型和算法開發、仿真驗證、地圖開發以及DevOps和MLOps,車企能更加容易地實現自動駕駛全流程的開發、測試和應用。
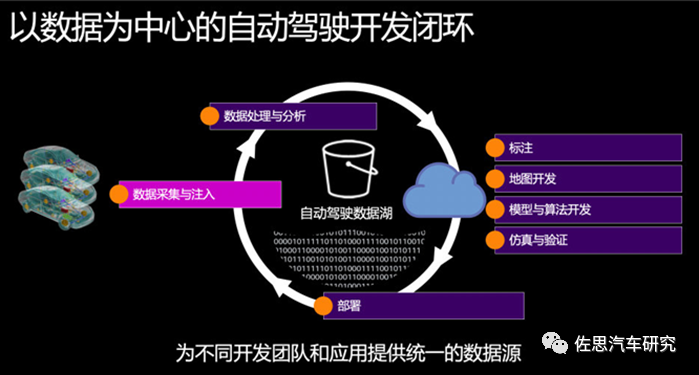
來源:AWS 在國內的科技巨頭中,以百度數據閉環解決方案為例,其數據存儲提供路側及車輛多源數據信息的數據檢索服務,用于業務平臺的海量數據查找,具備多維度檢索(車輛信息、里程數、自動駕駛時長等)、數據生產到銷毀的整個生命周期的管理、支持全景數據視圖、數據溯源和數據開放共享等優勢。
百度自動駕駛數據閉環解決方案架構
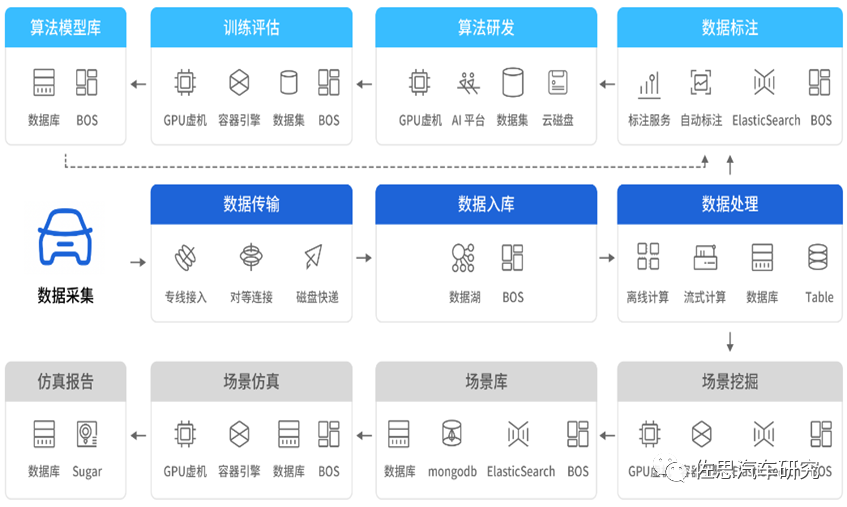
來源:百度
二、自動駕駛高效開發需構建數據閉環系統
自動駕駛發展從技術驅動轉向了數據驅動,但是數據驅動的商業模式面臨諸多困難。
海量數據處理難:高等級自動駕駛測試車每天采集的數據量是TB級別的,開發團隊需要PB級的存儲空間,但這些數據中,可用于訓練的價值數據約只占不到5%。且對車載攝像頭、激光雷達、高精定位等傳感器采集的數據還有嚴格的安全合規要求,無疑對海量數據的接入、存儲、脫敏、處理等帶來了極大的挑戰。
數據標注成本高:數據標注占據了大量的人力和時間成本。隨自動駕駛高階能力的發展,場景復雜度持續提升,會出現更多的難例場景。而提升車輛感知模型的精度,則對訓練數據集的規模和質量提出了更高要求。傳統人工標注在效率和成本方面,已難以滿足模型訓練對海量數據集的需求。
仿真測試效率低:虛擬仿真是加速自動駕駛算法訓練的有效手段,但仿真場景構建難、還原度低,尤其是一些復雜、危險場景,很難構建。加之并行仿真能力不足,仿真測試的效率低,算法的迭代周期過長。
高精地圖覆蓋少:高精地圖主要還是靠自采集、自制圖,僅滿足試驗階段指定道路的場景。后續要走向商用,擴展到全國各大城市的城區街道,在覆蓋、動態更新,以及成本和效率方面都面臨著非常突出的挑戰。
為了解決各種困難和問題,自動駕駛高效開發需構建高效的數據閉環系統。
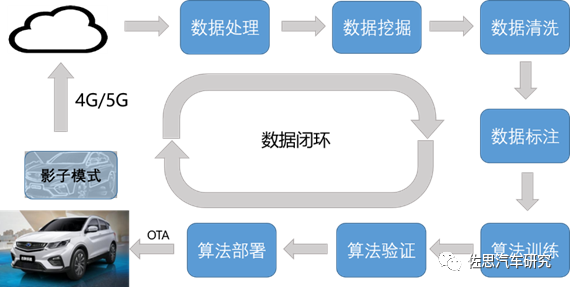
來源:福瑞泰克
就自動駕駛數據閉環而言,在自動駕駛落地過程中需要不斷解決Corner Cases,為此必須擁有足夠多的數據樣本以及便捷的車端驗證方式。影子模式就是解決Corner Cases的最佳解決方案之一。
影子模式由特斯拉2019年4月提出并應用到車端,進行相關決策的對比和觸發數據上傳。利用售出車輛上的自動駕駛軟件持續記錄傳感器探測的數據,在適當時間選擇性回傳用于機器學習、改進原來的自動駕駛算法。

Dojo超級計算機能利用海量視頻數據,做無人監管標注和訓練。
2021年特斯拉全球交付93.62萬輛汽車,其中中國工廠交付了48.41萬輛。2022年上半年交付56萬輛。特斯拉利用量產優勢,通過影子模式不斷優化算法。利用影子模式,通過百萬已售車輛做測試車輛,對周圍感知以及特殊路況進行捕捉,不斷強化對于不確定性事件的預測和規避、學習能力。因為有百萬量級的已售車輛支撐,覆蓋的Corner Cases及極端工況就會更全面,靈活觸發式采集的高質量數據能迭代出更優質的算法,而算法迭代的卓越度又決定著軟件的價值。從軟件升級訂閱服務來講,數據閉環的爆發力才剛剛嶄露頭角。
三、數據閉環成為自動駕駛迭代升級的核心
自動駕駛系統不斷迭代的前提是算法的持續優化,而算法的卓越度又取決于數據閉環系統的效能,數據在自動駕駛開發每個場景的高效能流轉至關重要,數據智能化將成為加速自動駕駛量產的關鍵。
2021年12月,毫末智行正式發布了國內首個自動駕駛數據智能體系MANA雪湖,從感知、認知、標注、仿真、計算五大能力方面加速自動駕駛技術的演進。未來三年毫末輔助駕駛系統可搭載超100萬臺乘用車。毫末智行依靠其全自研的自動駕駛系統,在數據的積累、處理、應用上取得了顯著優勢。海量數據帶來技術迭代優勢。降本增效優勢明顯。
再比如,Momenta實現了領先的全流程數據驅動的技術能力,包括感知、融合、預測和規控等算法模塊都可以通過數據驅動的方式高效的迭代與更新。其閉環自動化(Closed Loop Automation)是一整套讓數據流推動數據驅動的算法自動迭代的工具鏈。CLA能自動篩選出海量黃金數據,驅動算法的自動迭代,讓自動駕駛飛輪越轉越快。
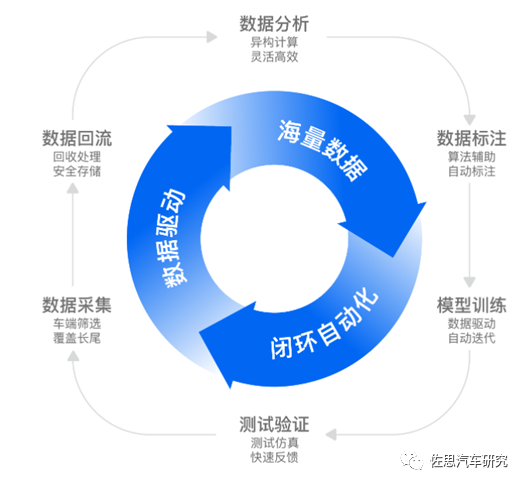
來源:Momenta
軟件定義汽車背景下,數據、算法和算力是自動駕駛開發的三駕馬車。車企研發周期縮短、功能迭代加速,未來能夠持續地低成本、高效率、高效能收集數據,并通過真實數據迭代算法,最終形成數據閉環及商業閉環是自動駕駛企業可持續發展的關鍵所在。
審核編輯 :李倩
-
傳感器
+關注
關注
2551文章
51174瀏覽量
754271 -
自動駕駛
+關注
關注
784文章
13839瀏覽量
166551 -
智能網聯汽車
+關注
關注
9文章
1074瀏覽量
31091
原文標題:數據閉環研究:自動駕駛發展從技術驅動轉向數據驅動
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
2024年中國將邁入L3自動駕駛時代,特斯拉是華為/小鵬最大敵手?
中汽中心出席2024年中國電池ID成果發布會
自動駕駛域控研究:One board/One Chip方案將對汽車供應鏈產生深遠影響

東軟成功入圍《2024中國數據中臺市場研究報告》領先廠商行列
FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
佐思汽研發布《2024年北京車展新四化趨勢分析報告》



佐思汽研發布《2024年端到端自動駕駛研究報告》







 工商網監
工商網監
評論