") PFN模型整體結(jié)構(gòu)和分區(qū)過濾編碼器內(nèi)部結(jié)構(gòu)
PFN模型整體結(jié)構(gòu)和分區(qū)過濾編碼器內(nèi)部結(jié)構(gòu)
01 前情提要
關(guān)系抽取目前的算法大概可以分為以下幾種:
先抽實(shí)體,再判關(guān)系,比如陳丹琦大神的《A Frustratingly Easy Approach for Joint Entity and Relation Extraction 》
●Joint Entity and Realtion Extraction:
聯(lián)合模型,目前我看過的有這么幾種方式:
■將聯(lián)合任務(wù)看做是一個填表問題,比如:table sequence,TPlinker
■將聯(lián)合任務(wù)看做是一個序列標(biāo)注問題,比如:ETL Span,PRGC
■將聯(lián)合任務(wù)看做是一個seq2seq問題,比如:SPN4RE
這篇論文:Parition Filter Network(PFN,分區(qū)過濾網(wǎng)絡(luò))是一個聯(lián)合模型,他們把問題定義為一個填表問題。
他們在總結(jié)之前論文的encoding層的時候,把之前的論文的encoding層分成了兩類:
●sequential encoding:串行,先生成一個task的特征(一般都是NER),再生成另一個task的feature(一般就是關(guān)系抽取),而后面這個task的特征,是不會影響到前面那個task的特征的。
●parallel encoding:并行,兩個task的特征是并行生成的,互不影響,只在input層面共享信息。
他們認(rèn)為task間的信息沒有得到很好的交互,(但其實(shí)Table sequence還是有交互的),其實(shí)現(xiàn)在很多算法里都在講交互,比如NLU里面的SF-ID/Bi-Model。同時,之前也有論文(比如Table sequence和陳丹琦那篇論文)發(fā)現(xiàn)了關(guān)系預(yù)測和實(shí)體抽取有可能有些特征是不共享的(Table sequence為了解決這個問題,直接用了倆encoder,陳丹琦大佬那一篇直接是pipeline方法,本身就是倆模型)。而這篇論文想在一個Encoder中完成兩個task的特征抽取,所以他們提出了一個分區(qū)和過濾的思路,找出“只與NER相關(guān)的特征”“只與關(guān)系預(yù)測相關(guān)的特征”和“與NER和關(guān)系預(yù)測都相關(guān)的特征”。
這里插一句,他們這篇論文效果是不錯的,同時也得出了一個結(jié)論,這里提前貼一下,雖然之前有些模型論證關(guān)系抽取的特征部分是對NER有害的,但他們發(fā)現(xiàn)關(guān)系Signal對NER是有益的(或者說是部分有益的,因?yàn)樗麄冏隽朔謪^(qū))。
廢話不多說了,下面介紹模型: 02 問題定義 給定一個文本,也就是一個輸入序列:,其中表示下標(biāo)是i的單詞,L是句子的長度,目的是找到: ●找到所有的實(shí)體:,用token pairs的方式(填表),其中分別是這個實(shí)體的頭和尾字,e是實(shí)體類型 ●找到所有的關(guān)系:,依然是token pairs的方式(填表),其中分別是subject的首字和object的首字,r是關(guān)系類型。 03 模型——PFN
模型主要包含兩個部分:分區(qū)過濾編碼器(Paritition Filter Encoder, PFE) 和 兩個Task Unit (NER Unit 和 RE Unit),如下圖(圖中其實(shí)還有一個Global Feature,這個按照論文中的解釋可以算在Encoder里面)
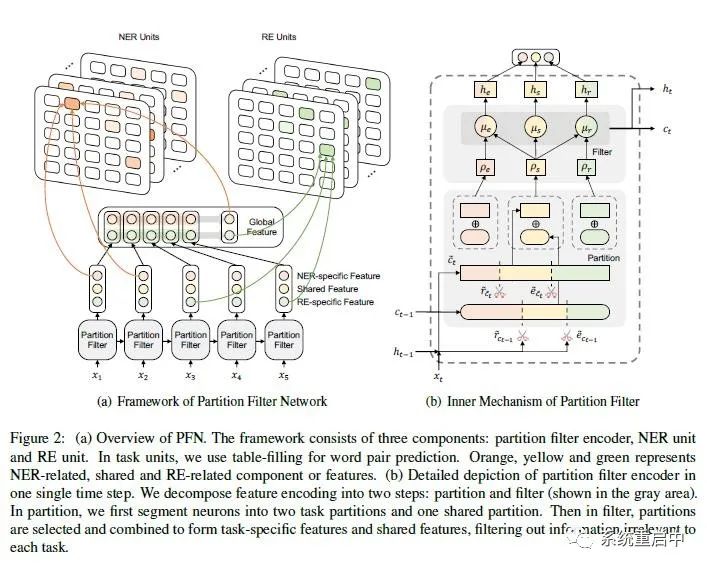
模型整體結(jié)構(gòu)和分區(qū)過濾編碼器內(nèi)部結(jié)構(gòu) >>> 3.1分區(qū)過濾編碼器(PFE)
PFE是一個循環(huán)特征編碼器,類似于LSTM。在每一個time step,PFE都會把特征拆分成為三個分區(qū):entity partition/ relation partition/ shared partition,其中entity partition是僅與實(shí)體抽取相關(guān)的分區(qū),relation partition是僅與relation相關(guān)的分區(qū),shared partition是與兩個任務(wù)都相關(guān)的分區(qū)。然后通過合并分區(qū), 就會過濾走與特定task無關(guān)的特征(比如合并entity partition和shared partition,就可以過濾掉特征中僅與relation相關(guān)的特征)。
上面的流程會被拆分成兩個部分:
●分區(qū)(Partition) :拆分成三個分區(qū)
●過濾(Filter):合并分區(qū)
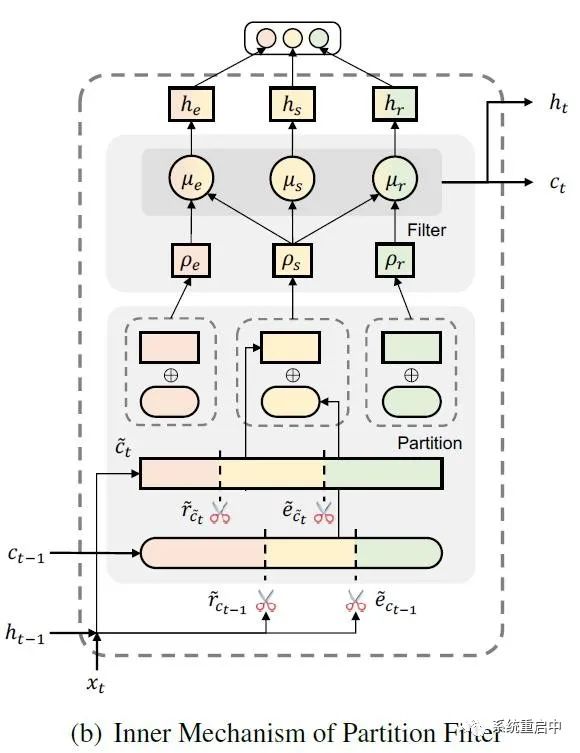
分區(qū)過濾編碼器
3.1.1 分區(qū)操作
如上圖所示,PFN中類似LSTM,也定義了cell state(這個是歷史信息)和 hidden state ,此外還定義了candidate cell state(就是候選分區(qū)的信息),relation gate,entity gate。 每個時間步t,分區(qū)操作流程如下: 首先計算candidate cell state:
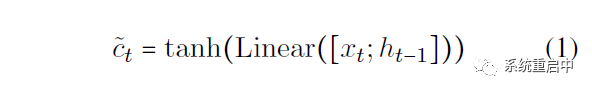
然后計算relation gate和entity gate:
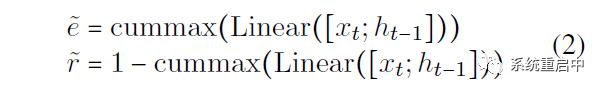
其中, 雖然這里只列了兩個式子,但實(shí)際看上面的圖就知道,這里的要生成兩層分區(qū),我叫他們“候選分區(qū)層”(負(fù)責(zé)對candidate cell state進(jìn)行分區(qū))和“歷史分區(qū)層”(負(fù)責(zé)對 t-1 時間步的cell state進(jìn)行分區(qū)),每層對應(yīng)兩個gate,我叫他們“候選relation gate”“候選entity gate”以及“歷史relation gate”“歷史entity gate”。
然后再在每層利用剛剛計算到的兩個gate,生成三個分區(qū)(兩層就是6個分區(qū)):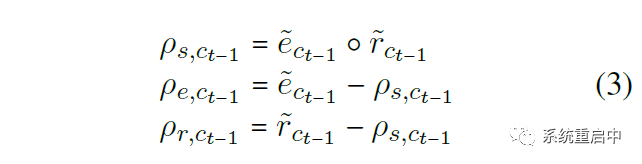
圖中為t-1時間步的歷史分區(qū),用t-1時間步的歷史gate生成,t時間步的候選分區(qū)一個道理 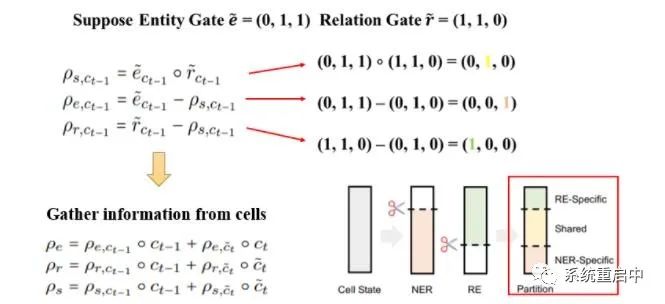 這張圖可以解釋一下上面這個分區(qū),圖片來自官方代碼的git
這張圖可以解釋一下上面這個分區(qū),圖片來自官方代碼的git
最后根據(jù) t-1 時間步的 歷史gate 和 歷史信息cell state,和 t 時間步的 候選gate 和 候選信息candidate cell state,生成 t 時間步的三個分區(qū)的information:
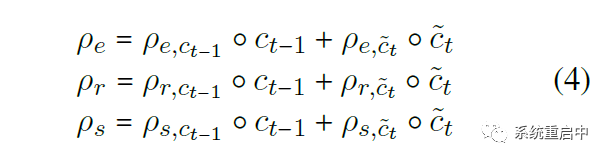
這部分看代碼可能更清晰:
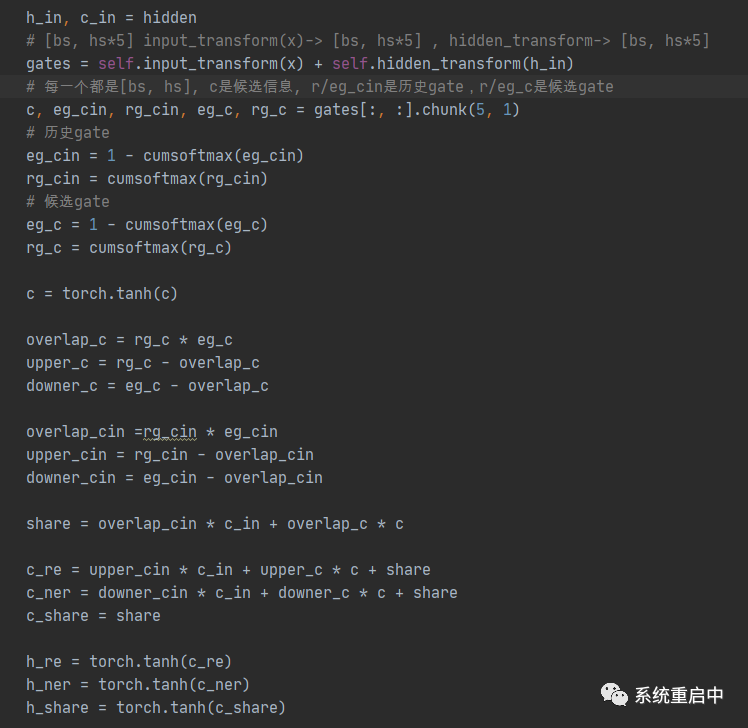 ? 到這里,如果類比LSTM的話,cell state 和 hidden state 怎么更新,我們還不知道,同時得到三個分區(qū)信息按理說是互不重疊的。所以接下來我們讓他們交互,同時看如果更新那兩個state。 ? ? ? ? ? ? 這里有一些問題,就是為什么有要用cummax操作,這是個什么玩意?? ? 這里主要是因?yàn)檫@篇論文在這里的gate設(shè)計上面參考了Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks中的設(shè)計。 ? 這里我參考這篇論文簡單說一下我的理解,需要對信息進(jìn)行排序,切分,所以正好用一個二值gate??來描述,我們來計算這個gate。 ? 假設(shè)我們用一個??表示g中某個位置出現(xiàn)第一個1的概率,看起來像是幾何分布,但并不是,因?yàn)椴皇遣囼?yàn),所以算起來比較麻煩。 ? 我們計算gate g中第k個位置是1的概率,就可以用累計分布函數(shù):???。這樣的話,我們就可以表示二值gate g每個位置為1的概率了,而因?yàn)槎礸ate g每個位置都是離散的,也不好用,所以就用概率來代替它,可以作為它的期望。 ? 然后用這個概率去定義兩個gate,一個單調(diào)增的cummax,一個單調(diào)減的cummax,防止沖突。 ?
? 到這里,如果類比LSTM的話,cell state 和 hidden state 怎么更新,我們還不知道,同時得到三個分區(qū)信息按理說是互不重疊的。所以接下來我們讓他們交互,同時看如果更新那兩個state。 ? ? ? ? ? ? 這里有一些問題,就是為什么有要用cummax操作,這是個什么玩意?? ? 這里主要是因?yàn)檫@篇論文在這里的gate設(shè)計上面參考了Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks中的設(shè)計。 ? 這里我參考這篇論文簡單說一下我的理解,需要對信息進(jìn)行排序,切分,所以正好用一個二值gate??來描述,我們來計算這個gate。 ? 假設(shè)我們用一個??表示g中某個位置出現(xiàn)第一個1的概率,看起來像是幾何分布,但并不是,因?yàn)椴皇遣囼?yàn),所以算起來比較麻煩。 ? 我們計算gate g中第k個位置是1的概率,就可以用累計分布函數(shù):???。這樣的話,我們就可以表示二值gate g每個位置為1的概率了,而因?yàn)槎礸ate g每個位置都是離散的,也不好用,所以就用概率來代替它,可以作為它的期望。 ? 然后用這個概率去定義兩個gate,一個單調(diào)增的cummax,一個單調(diào)減的cummax,防止沖突。 ?
3.1.2 過濾操作
首先,根據(jù)上一步生成的三個分區(qū)的信息,交互得到生成三個memory,以達(dá)到過濾的效果:實(shí)體相關(guān)/關(guān)系相關(guān)/shared
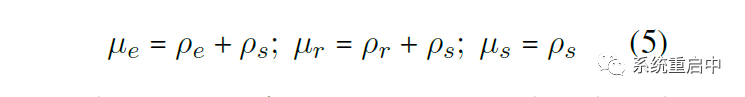
這里就達(dá)到了過濾的效果,實(shí)體部分過濾掉了僅與relation相關(guān)的,relation部分過濾掉了僅與實(shí)體相關(guān)的,shared部分包含了task間的信息,可以認(rèn)為是平衡兩個task 然后,三個memory分別過tanh得到相應(yīng)的三個hidden state,直接從當(dāng)前時間步的cell中輸出,當(dāng)做是 NER-specific Feature/ Relation-specific Feature/ Shared Feature,用于下一階段的運(yùn)算
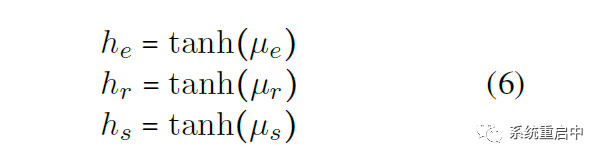
最后,更新cell state 和 hidden state,三個memory拼接在一起過線性映射得到 t 時間步的 cell state,t 時間步的 cell state 過 tanh 得到 t 時間步的 hidden state
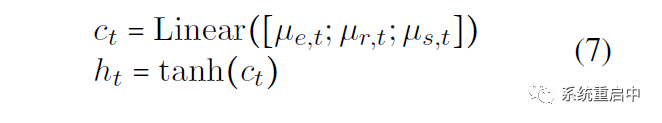
到這里,一個PFE 的 cell 就講完了。
>>> 3.2 Global Representation
上面的 PFE Cell 其實(shí)是一個單向編碼器,但一般嘛,大家都用雙向的編碼器,哪怕你用個BILSTM呢,也是雙向的呀,本文為了代替雙向編碼器中的后向編碼器,就提出了這個Global Representation。
具體來說就是獲得兩個task-specific全局的表征:分別用每個時間步的 entity-specific feature 和 relation-specific feature 拼接 shared feature,過線性映射和tanh,然后做個maxpooling over time,就獲得了兩個task-specific feature:
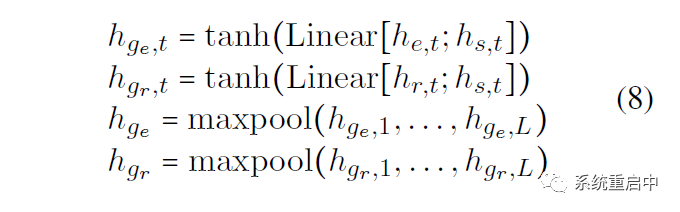
>>> 3.3Task Unit
Task Unit 包含兩個Unit:entity Unit 和 Relation Unit,分別是兩個填表任務(wù)
● Entity Unit
如果句子輸入長度是L,那么表格的長度是L*L,表格中的(i, j)位置表示以第i個位置開始和第j個位置結(jié)束的span的Entity-Sepcific 表征,這個表征的為拼接:第i個位置和第j個的entity-specific feature,以及entity-specific global representation,過Linear以及ELU激活函數(shù)
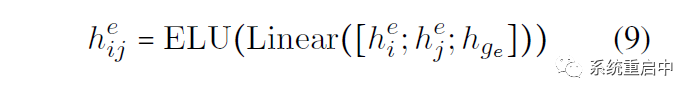
接下來就是輸出層:就是一個線性映射,映射到entity type數(shù)目的維數(shù)上,然后每維做sigmoid,判斷是不是其代表的entity type(之所以采用這種多標(biāo)簽分類的方式,是為了解決overlapping問題)
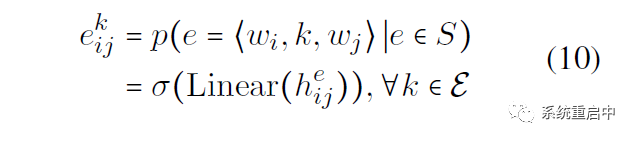
● Relation Unit
如果一個句子長度是L,那么表格長度是L*L,表格中的 (i, j) 位置標(biāo)示以第i個位置為首字的span,和以第j個位置為首字的span的 關(guān)系表征,這個表征的和Entity Unit差不多,拼接:第i個位置和第j個的relation-specific feature,以及relation-specific global representation,過Linear以及ELU激活函數(shù)
然后一樣做多標(biāo)簽分類
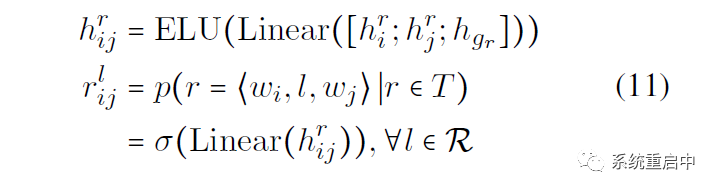
>>> 3.4 訓(xùn)練和推斷
●損失函數(shù):兩個BCE

●推斷的時候有兩個超參數(shù)閾值:實(shí)體閾值和關(guān)系閾值,都設(shè)置為0.5
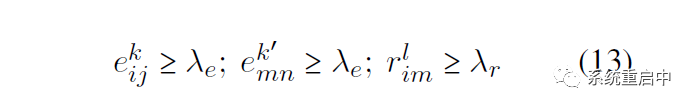
04 實(shí)驗(yàn) >>> 4.1 主要結(jié)果
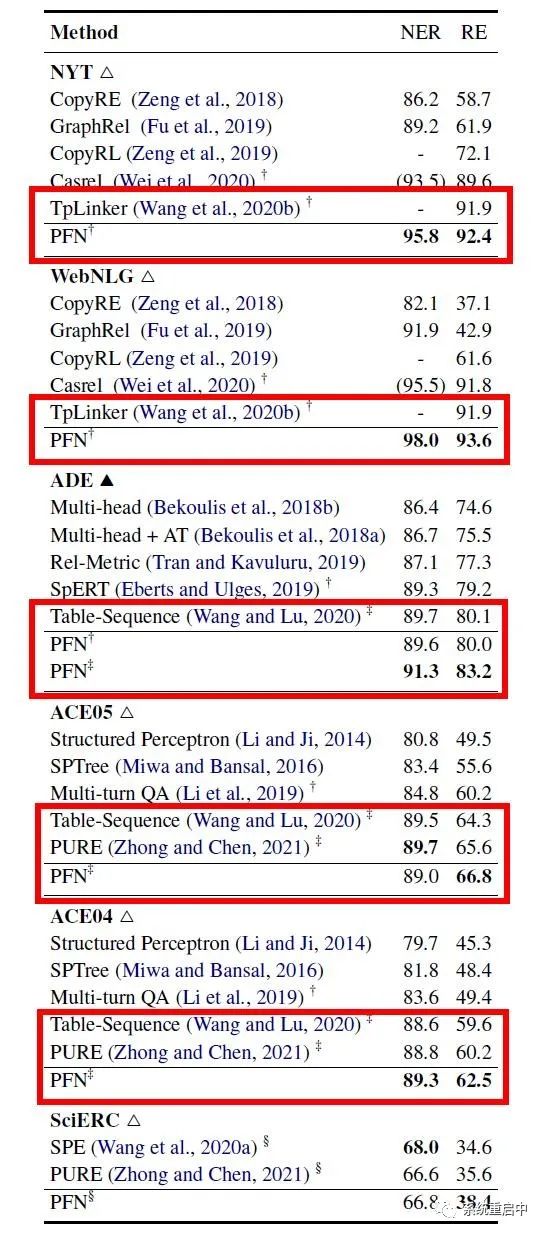

可以看到,在使用同樣的預(yù)訓(xùn)練模型的情況下,效果是要比TPLiner和Table Sequence要好的(Table Sequence是有一些交互的喲),同時這篇論文在WebNLG上的結(jié)果也比同時EMNLP2021論文的PRGC要好一點(diǎn)點(diǎn)(PFN-93.6, PRGC-93.0, TPLinker-91.9) >>> 4.2 消融實(shí)驗(yàn)
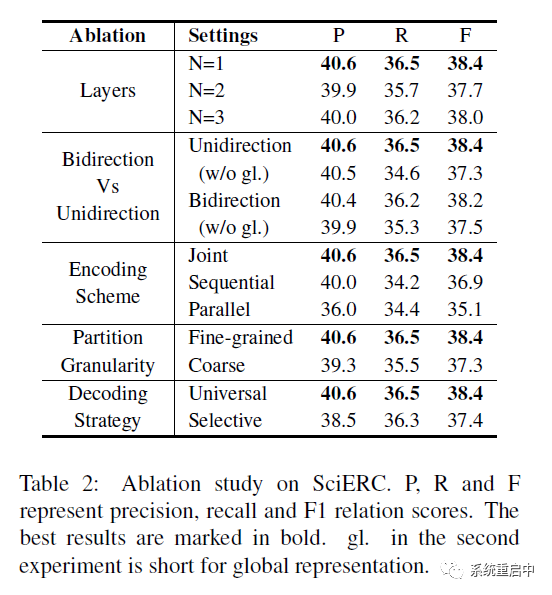
他們的消融實(shí)驗(yàn)主要進(jìn)行了如下幾個:
●編碼器的層數(shù)實(shí)驗(yàn):1層效果就很好 ●雙向編碼器Vs單向編碼器:主要是為了證明他們的Global Representation的作用,結(jié)果發(fā)現(xiàn)效果真不戳,在他們的這一套里面,全局表征完全可以代替后向編碼器,甚至效果更好 ■前向+G>雙向+G>雙向>單向 ●編碼器的結(jié)果:他們換成了兩個LSTM,發(fā)現(xiàn)他們的效果好 ■對于并行模式:entity 和 relation 分別過一個LSTM,只在input級別共享 ■對于串行模式:先過第一個LSTM,hidden state 用于entity預(yù)測,同時 hidden state會被送到第二層LSTM中去,結(jié)果用于預(yù)測relation ●分區(qū)粒度:這個我覺得實(shí)驗(yàn)設(shè)置一定是他們的好,沒必要單拎出來講 ●解碼策略:兩種,一種是relation只考慮entity prediction 結(jié)果的(解碼時級聯(lián),relation不考慮所有單詞,僅考慮candidate set),一種是他們這種兩張表都填的(relation考慮所有單詞) ■他們發(fā)現(xiàn)后者效果更好,原因可能有二:a. 前一種有誤差傳遞;b. 第二種表中的負(fù)例多,有點(diǎn)對比學(xué)習(xí)的意思,因此學(xué)到的正例的表征更牛逼。
>>> 4.3 關(guān)系抽取的signal對NER的影響
之所以做這個實(shí)驗(yàn),是因?yàn)橹坝姓撐恼J(rèn)為關(guān)系抽取的特征對NER在Joint模型中是有害的,因?yàn)閮烧咝枰奶卣鞑煌K麄冎皇遣糠滞膺@個觀點(diǎn),也就是說,關(guān)系抽取的特征部分是對NER有害的,但也有一部分對NER有益的,他們這篇論文其實(shí)就是識別出來哪部分有益,哪部分有害,并對有益部分加以利用。
4.3.1 關(guān)系內(nèi)和關(guān)系外的實(shí)體抽取的差別
在主要實(shí)驗(yàn)中,ACE05里面他們的NER效果拉垮了,他們認(rèn)為是關(guān)系外的實(shí)體很多,統(tǒng)計了一下有64%的實(shí)體都是關(guān)系外實(shí)體。
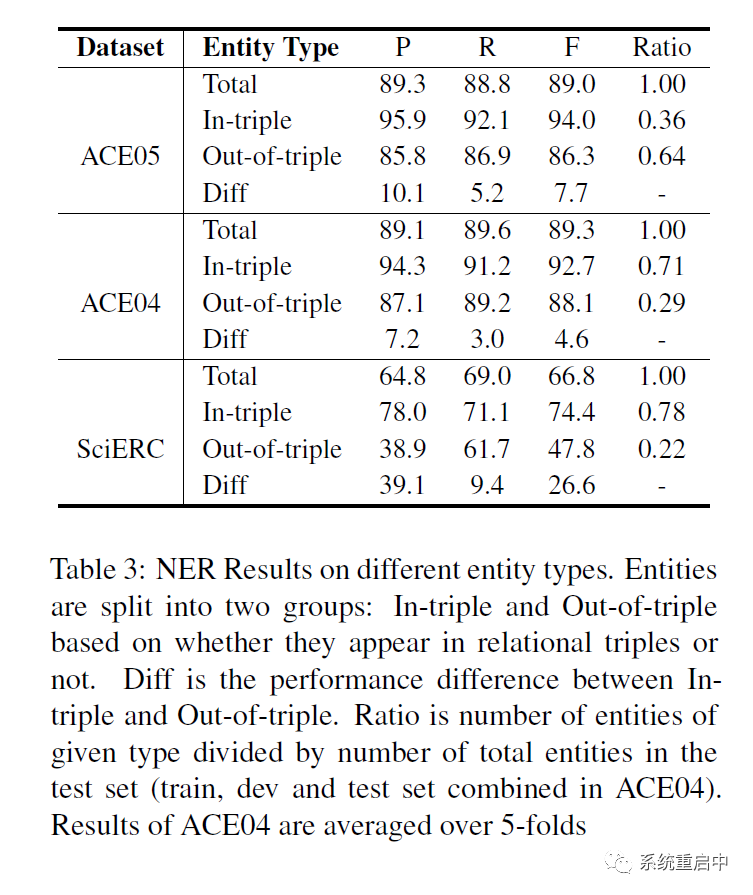
他們做了三個數(shù)據(jù)集上面的,關(guān)系內(nèi)的實(shí)體識別效果F1都要好于關(guān)系外的。(SciERC中g(shù)ap超大,因?yàn)镾ciERC中的實(shí)體專業(yè)程度更強(qiáng),也更長,有關(guān)系效果更好),此外,precision的gap尤其大,證明失去了relation信息的,模型在entity上就會過擬合。
同時看到:關(guān)系外實(shí)體的占比 與 NER的效果是負(fù)相關(guān)的。這有可能是因?yàn)閖oint model的一個缺點(diǎn):考慮到關(guān)系內(nèi)和關(guān)系外的實(shí)體的推斷邏輯是不一樣的(一個有relation影響,一個沒有),那么joint model有可能對關(guān)系外的NER的效果是有害的。
但我這里弱弱的問一句,這是不是說對于類外實(shí)體,如果gate可以做的更好,就可以效果依然棒呢,其他兩個比它好的論文里面(Table Sequence也是交互的啊,PURE我還沒看,回頭看看)。
4.3.2 NER魯棒性分析
他們與純NER算法做對比,進(jìn)行了魯棒性的分析,發(fā)現(xiàn)他們的NER的魯棒性還是不錯的,可能的原因就是relation signals對實(shí)體進(jìn)行了約束,從而讓魯棒性更強(qiáng)。
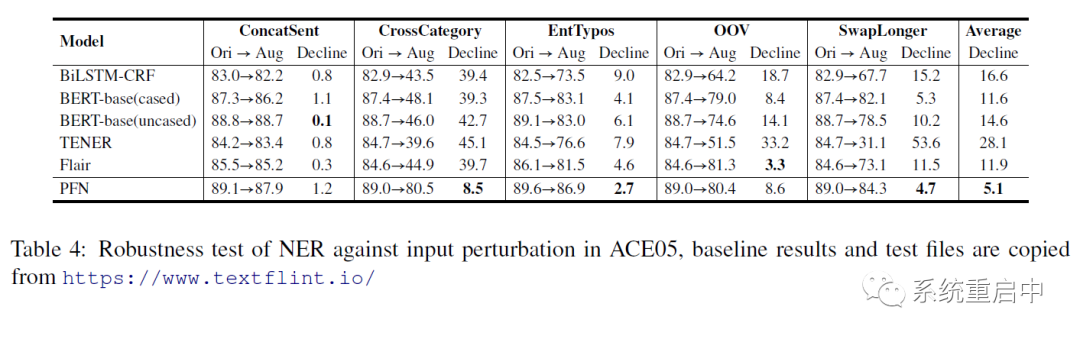
所以通過上面兩部分,他們認(rèn)為關(guān)系信息對NER效果是有幫助的。此外,提一嘴,他們反駁了陳丹琦大佬論文《A Frustratingly Easy Approach for Joint Entity and Relation Extraction》關(guān)于關(guān)系信息對NER的幫助比較小的結(jié)論,認(rèn)為那篇論文是在ACE2005上面做的實(shí)驗(yàn),類外實(shí)體太多了,所以效果不明顯。
-
編碼器
+關(guān)注
關(guān)注
45文章
3651瀏覽量
134773 -
模型
+關(guān)注
關(guān)注
1文章
3268瀏覽量
48926 -
代碼
+關(guān)注
關(guān)注
30文章
4803瀏覽量
68754
原文標(biāo)題:復(fù)旦提出PFN: 關(guān)系抽取SOTA之分區(qū)過濾網(wǎng)絡(luò)
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
芯片封裝內(nèi)部結(jié)構(gòu)
[轉(zhuǎn)帖]光耦內(nèi)部結(jié)構(gòu)原理
變頻器內(nèi)部結(jié)構(gòu)_變頻器內(nèi)部結(jié)構(gòu)圖
光電編碼器原理結(jié)構(gòu)圖
基于雙編碼器網(wǎng)絡(luò)結(jié)構(gòu)的CGAtten-GRU模型

AN-562:過濾ADV719x視頻編碼器內(nèi)部濾波器規(guī)范

基于結(jié)構(gòu)感知的雙編碼器解碼器模型
MOSFET和IGBT內(nèi)部結(jié)構(gòu)與應(yīng)用
磁性編碼器結(jié)構(gòu)及原理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論