") iNeRF對RGB圖像進行類別級別的物體姿態(tài)估計
iNeRF對RGB圖像進行類別級別的物體姿態(tài)估計
作者:Lin Yen-Chen, Pete Florence, Jonathan T. Barron, Alberto Rodriguez, Phillip Isola, Tsung-Yi Lin
摘要
我們提出了iNeRF,一個通過 “反轉 ”神經輻射場(NeRF)來進行無網格姿勢估計的框架。NeRFs已經被證明對合成真實世界場景或物體的逼真的新視圖非常有效。在這項工作中,我們研究了是否可以通過NeRF來應用無網格、純RGB的6DoF姿態(tài)估計的分析合成法:給定一個圖像,找到攝像機相對于三維物體或場景的平移和旋轉。我們的方法假定在訓練或測試期間沒有物體網格模型可用。從最初的姿勢估計開始,我們使用梯度下降法來最小化從NeRF渲染的像素和觀察到的圖像中的像素之間的殘差。在我們的實驗中,我們首先研究:1)如何在iNeRF的姿勢精化過程中對射線進行取樣以收集信息梯度;2)不同批次的射線如何影響合成數據集上的iNeRF。然后我們表明,對于來自LLFF數據集的復雜的真實世界場景,iNeRF可以通過估計新的圖像的相機姿態(tài)和使用這些圖像作為NeRF的額外訓練數據來改善NeRF。最后,我們展示了iNeRF可以通過反轉從單一視圖推斷出的NeRF模型,對RGB圖像進行類別級別的物體姿態(tài)估計,包括訓練期間未見的物體實例。
主要貢獻
總而言之,我們的主要貢獻如下。
(i) 我們表明,iNeRF可以使用NeRF模型來估計具有復雜幾何形狀的場景和物體的6DoF姿態(tài),而不需要使用3D網格模型或深度感應--只使用RGB圖像作為輸入。
(ii) 我們對射線采樣和梯度優(yōu)化的批量大小進行了深入研究,以確定iNeRF的穩(wěn)健性和局限性。
(iii) 我們表明,iNeRF可以通過預測更多圖像的相機姿態(tài)來改善NeRF,這些圖像可以被添加到NeRF的訓練集中。
(iv) 我們展示了對未見過的物體的類別級姿勢估計結果,包括一個真實世界的演示。
主要方法
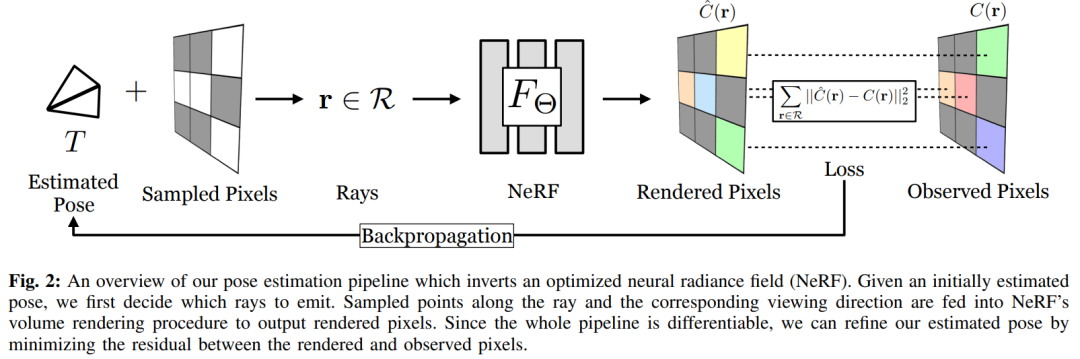
我們現(xiàn)在提出了iNeRF,一個通過 “反轉 ”訓練過的NeRF來執(zhí)行6DoF姿態(tài)估計的框架。讓我們假設一個場景或物體的NeRF的參數化Θ已經被恢復,并且相機的本征是已知的,但是圖像觀測I的相機位姿T還沒有確定。與NeRF不同的是,NeRF使用一組給定的相機位姿和圖像觀測值來優(yōu)化Θ,而我們要解決的是在給定權重Θ和圖像I的情況下恢復相機姿勢T的逆問題。
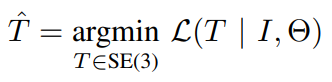
為了解決這個優(yōu)化問題,我們利用NeRF的能力,在NeRF模型的坐標框架中采取一些估計的相機姿勢T∈SE(3),并渲染相應的圖像觀察。然后,我們可以使用與NeRF相同的光度損失函數L,但我們不是通過反向傳播來更新MLP的權重Θ,而是更新姿勢T以最小化L。雖然倒置NeRF來進行姿勢估計的概念可以簡明扼要地說明,但這樣的問題是否可以實際解決到一個有用的程度并不明顯。損失函數L在SE(3)的6DoF空間上是非凸的,而且全圖像的NeRF渲染在計算上很昂貴,特別是在優(yōu)化程序的循環(huán)中使用。
1.基于梯度的SE(3)優(yōu)化
將Θ定義為經過訓練的固定的NeRF的參數,先驗Ti是當前優(yōu)化步驟i的估計相機姿勢,I是觀察到的圖像,L(Ti | I, Θ)是用于訓練NeRF中的精細模型的損失。我們采用基于梯度的優(yōu)化來解決上面方程中定義的先驗T。為了確保在基于梯度的優(yōu)化過程中,估計的姿勢先驗Ti繼續(xù)位于SE(3)流形上,我們用指數坐標為先驗Ti設置參數。給定一個從相機幀到模型幀的初始姿勢估計值先驗T0∈SE(3),我們將先驗Ti表示為:
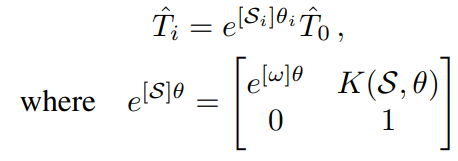
我們通過MLP對損失函數進行迭代,得到梯度?SθL(e [S]θT0 |I, Θ),用于更新估計的相對變換。我們使用Adam優(yōu)化器,其學習率為指數衰減。對于每個觀察到的圖像,我們將Sθ初始化到0附近,其中每個元素都是從零均值正態(tài)分布N(0,σ=10-6)中隨機抽取的。在實踐中,用e[S]θ T0進行參數化,如果利用T0e[S]θ會導致旋轉中心在初始估計的中心,而不是在攝像機幀的中心。這就減輕了優(yōu)化過程中旋轉和平移之間的耦合。
2.光線采樣
這里討論了三種采樣方法
隨機采樣:一個直觀的策略是在圖像平面上隨機抽取M個像素點{p i x , piy}M i=0,并計算其對應的射線。事實上,NeRF本身在優(yōu)化Θ時就使用了這種策略(假設不使用圖像批處理)。我們發(fā)現(xiàn),當射線的批處理量b較小時,這種隨機采樣策略的性能是無效的。大多數隨機采樣的像素對應于圖像中平坦的、無紋理的區(qū)域,這些區(qū)域在姿勢方面提供的信息很少(這與著名的光圈問題一致)。
興趣特征點采樣:我們提出了興趣點抽樣來指導iNeRF的優(yōu)化,我們首先采用興趣點檢測器來定位觀察圖像中的一組候選像素位置。然后,我們從檢測到的興趣點中抽出M個點,如果檢測到的興趣點不夠多,就回落到隨機抽樣。雖然這種策略使優(yōu)化收斂得更快,因為引入了較少的隨機性,但我們發(fā)現(xiàn)它很容易出現(xiàn)局部最小值,因為它只考慮觀察圖像上的興趣點,而不是來自觀察圖像和渲染圖像的興趣點。然而,獲得渲染圖像中的興趣點需要O(HW n)個前向MLP通道,因此在優(yōu)化中使用的成本過高。
興趣特征區(qū)域采樣:為了防止只從興趣點取樣造成的局部最小值,我們建議使用 “興趣區(qū)域 ”取樣,這是一種放寬興趣點取樣的策略,從以興趣點為中心的擴張掩模中取樣。在興趣點檢測器對興趣點進行定位后,我們應用5×5的形態(tài)學擴張進行I次迭代以擴大采樣區(qū)域。在實踐中,我們發(fā)現(xiàn)當射線的批量大小較小時,這樣做可以加快優(yōu)化速度。請注意,如果I被設置為一個大數字,興趣區(qū)域采樣就會退回到隨機采樣。
3.用iNeRF自我監(jiān)督學習NeRF
除了使用iNeRF對訓練好的NeRF進行姿態(tài)估計外,我們還探索使用估計的姿態(tài)來反饋到訓練NeRF表示中。具體來說,我們首先根據一組已知相機姿勢的訓練RGB圖像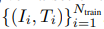 來訓練NeRF,產生NeRF參數Θtrain。然后,我們使用iNeRF來接收額外的未知姿勢的觀察圖像{Ii}。Ntest i=1,并求解估計姿勢先驗Ti。Ntest i=1。鑒于這些估計的姿勢,我們可以使用自我監(jiān)督的姿勢標簽,將
來訓練NeRF,產生NeRF參數Θtrain。然后,我們使用iNeRF來接收額外的未知姿勢的觀察圖像{Ii}。Ntest i=1,并求解估計姿勢先驗Ti。Ntest i=1。鑒于這些估計的姿勢,我們可以使用自我監(jiān)督的姿勢標簽,將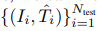 加入訓練集。這個過程允許NeRF在半監(jiān)督的情況下被訓練。
加入訓練集。這個過程允許NeRF在半監(jiān)督的情況下被訓練。
主要結果


審核編輯:郭婷
-
攝像機
+關注
關注
3文章
1596瀏覽量
60016 -
輻射
+關注
關注
1文章
598瀏覽量
36335
原文標題:iNeRF:用于姿態(tài)估計的反向神經輻射場(IROS 2021)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
基于PoseDiffusion相機姿態(tài)估計方法

源碼交流=圖像處理 識別圓形物體
光照變化情況下的靜態(tài)頭部姿態(tài)估計
不同類別的電池是如何回收的?
基于RGB-D圖像物體識別方法
基于深度學習的二維人體姿態(tài)估計方法

基于深度學習的二維人體姿態(tài)估計算法

基于視點與姿態(tài)估計的視頻監(jiān)控行人再識別
基于OnePose的無CAD模型的物體姿態(tài)估計
一種基于去遮擋和移除的3D交互手姿態(tài)估計框架
無需實例或類級別3D模型的對新穎物體的6D姿態(tài)追蹤
基于飛控的姿態(tài)估計算法作用及原理
從單張圖像中揭示全局幾何信息:實現(xiàn)高效視覺定位的新途徑






 工商網監(jiān)
工商網監(jiān)
評論