


前言 隨著eBPF推出,由于具有高性能、高擴(kuò)展、安全性等優(yōu)勢(shì),目前已經(jīng)在網(wǎng)絡(luò)、安全、可觀察等領(lǐng)域廣泛應(yīng)用,同時(shí)也誕生了許多優(yōu)秀的開源項(xiàng)目,如Cilium、Pixie等,而iLogtail作為阿里內(nèi)外千萬(wàn)實(shí)例可觀測(cè)數(shù)據(jù)的采集器,eBPF 網(wǎng)絡(luò)可觀測(cè)特性也預(yù)計(jì)會(huì)在未來(lái)8月發(fā)布。下文主要基于eBPF觀測(cè)HTTP 1、HTTP 1.1以及HTTP2的角度介紹eBPF的針對(duì)可觀測(cè)場(chǎng)景的應(yīng)用,同時(shí)回顧HTTP 協(xié)議自身的發(fā)展。
eBPF基本介紹 eBPF 是近幾年 Linux Networkworking 方面比較火的技術(shù)之一,目前在安全、網(wǎng)絡(luò)以及可觀察性方面應(yīng)用廣泛,比如CNCF 項(xiàng)目Cilium 完全是基于eBPF 技術(shù)實(shí)現(xiàn),解決了傳統(tǒng)Kube-proxy在大集群規(guī)模下iptables 性能急劇下降的問(wèn)題。從基本功能上來(lái)說(shuō)eBPF 提供了一種兼具性能與靈活性來(lái)自定義交互內(nèi)核態(tài)與用戶態(tài)的新方式,具體表現(xiàn)為eBPF 提供了友好的api,使得可以通過(guò)依賴libbpf、bcc等SDK,將自定義業(yè)務(wù)邏輯安全的嵌入內(nèi)核態(tài)執(zhí)行,同時(shí)通過(guò)BPF Map 機(jī)制(不需要多次拷貝)直接在內(nèi)核態(tài)與用戶態(tài)傳遞所需數(shù)據(jù)。 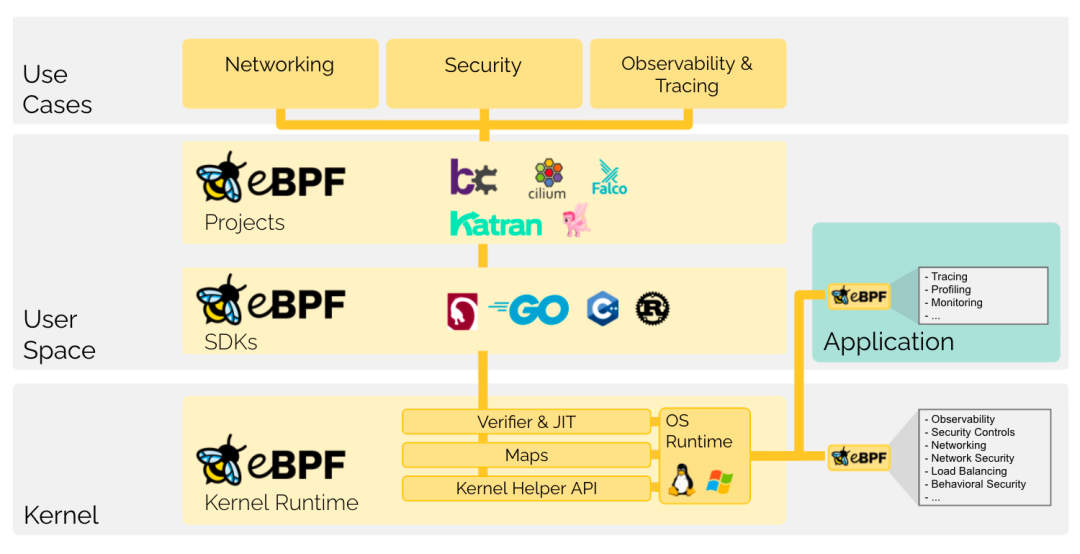 當(dāng)聚焦在可觀測(cè)性方面,我們可以將eBPF 類比為Javaagent進(jìn)行介紹。Javaagent的基本功能是程序啟動(dòng)時(shí)對(duì)于已存在的字節(jié)碼進(jìn)行代理字節(jié)碼織入,從而在無(wú)需業(yè)務(wù)修改代碼的情況下,自動(dòng)為用戶程序加入hook點(diǎn),比如在某函數(shù)進(jìn)入和返回時(shí)添加hook點(diǎn)可以計(jì)算此函數(shù)的耗時(shí)。而eBPF 類似,提供了一系列內(nèi)核態(tài)執(zhí)行的切入點(diǎn)函數(shù),無(wú)需修改代碼,即可觀測(cè)應(yīng)用的內(nèi)部狀態(tài),以下為常用于可觀測(cè)性的切入點(diǎn)類型:
當(dāng)聚焦在可觀測(cè)性方面,我們可以將eBPF 類比為Javaagent進(jìn)行介紹。Javaagent的基本功能是程序啟動(dòng)時(shí)對(duì)于已存在的字節(jié)碼進(jìn)行代理字節(jié)碼織入,從而在無(wú)需業(yè)務(wù)修改代碼的情況下,自動(dòng)為用戶程序加入hook點(diǎn),比如在某函數(shù)進(jìn)入和返回時(shí)添加hook點(diǎn)可以計(jì)算此函數(shù)的耗時(shí)。而eBPF 類似,提供了一系列內(nèi)核態(tài)執(zhí)行的切入點(diǎn)函數(shù),無(wú)需修改代碼,即可觀測(cè)應(yīng)用的內(nèi)部狀態(tài),以下為常用于可觀測(cè)性的切入點(diǎn)類型:
kprobe:動(dòng)態(tài)附加到內(nèi)核調(diào)用點(diǎn)函數(shù),比如在內(nèi)核exec系統(tǒng)調(diào)用前檢查參數(shù),可以BPF 程序設(shè)置 SEC("kprobe/sys_exec")頭部進(jìn)行切入。
tracepoints:內(nèi)核已經(jīng)提供好的一些切入點(diǎn),可以理解為靜態(tài)的kprobe,比如syscall 的connect函數(shù)。
uprobe:與krobe對(duì)應(yīng),動(dòng)態(tài)附加到用戶態(tài)調(diào)用函數(shù)的切入點(diǎn)稱為uprobe,相比如kprobe 內(nèi)核函數(shù)的穩(wěn)定性,uprobe 的函數(shù)由開發(fā)者定義,當(dāng)開發(fā)者修改函數(shù)簽名時(shí),uprobe BPF 程序同樣需要修改函數(shù)切入點(diǎn)簽名。
perf_events:將BPF 代碼附加到Perf事件上,可以依據(jù)此進(jìn)行性能分析。
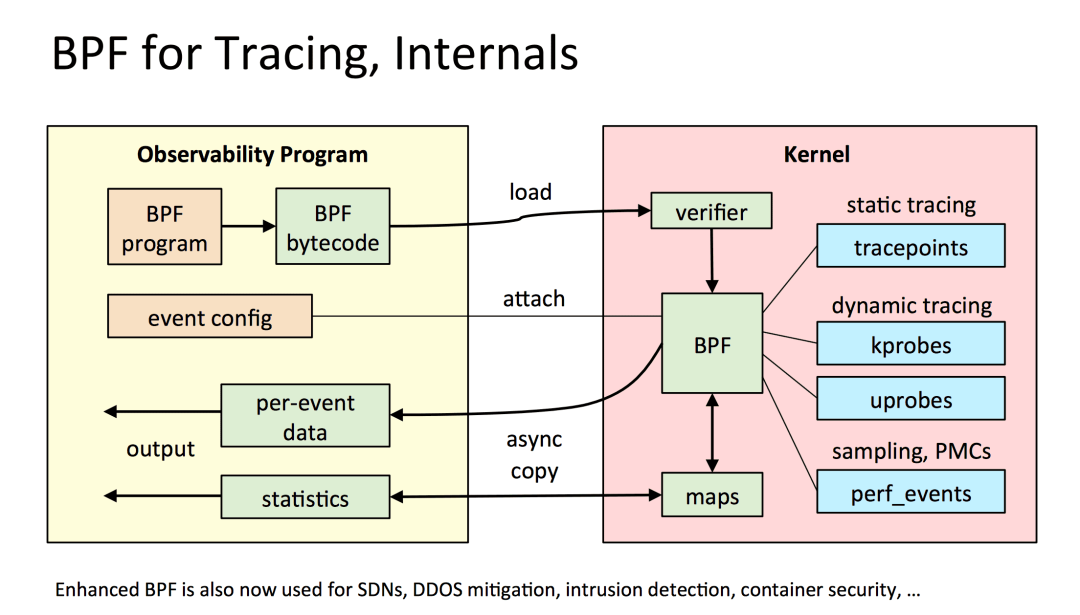
TCP與eBPF 由于本文觀測(cè)協(xié)議HTTP 1、HTTP1.1以及HTTP2 都是基于TCP 模型,所以先回顧一下 TCP 建立連接的過(guò)程。首先Client 端通過(guò)3次握手建立通信,從TCP協(xié)議上來(lái)說(shuō),連接代表著狀態(tài)信息,比如包含seq、ack、窗口/buffer等,而tcp握手就是協(xié)商出來(lái)這些初始值;而從操作系統(tǒng)的角度來(lái)說(shuō),建立連接后,TCP 創(chuàng)建了INET域的 socket,同時(shí)也占用了FD 資源。對(duì)于四次揮手,從TCP協(xié)議上來(lái)說(shuō),可以理解為釋放終止信號(hào),釋放所維持的狀態(tài);而從操作系統(tǒng)的角度來(lái)說(shuō),四次揮手后也意味著Socket FD 資源的回收。 而對(duì)于應(yīng)用層的角度來(lái)說(shuō),還有一個(gè)常用的概念,這就是長(zhǎng)連接,但長(zhǎng)連接對(duì)于TCP傳輸層來(lái)說(shuō),只是使用方式的區(qū)別:
應(yīng)用層短連接:三次握手+單次傳輸數(shù)據(jù)+四次揮手,代表協(xié)議HTTP 1
應(yīng)用層長(zhǎng)連接:三次握手+多次傳輸數(shù)據(jù)+四次揮手,代表協(xié)議 HTTP 1.1、HTTP2
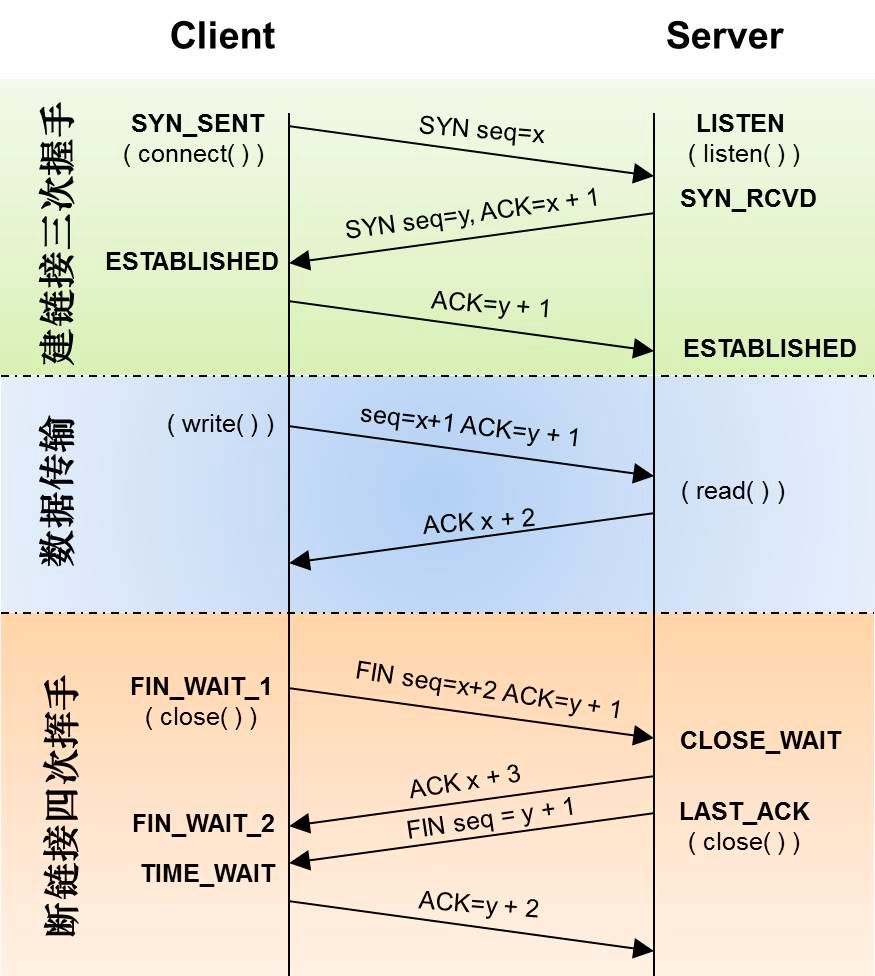
 參考下圖TCP 建立連接過(guò)程內(nèi)核函數(shù)的調(diào)用,對(duì)于eBPF 程序可以很容易的定義好tracepoints/kprobe 切入點(diǎn)。例如建立連接過(guò)程可以切入 accept 以及connect 函數(shù),釋放鏈接過(guò)程可以切入close過(guò)程,而傳輸數(shù)據(jù)可以切入read 或write函數(shù)。
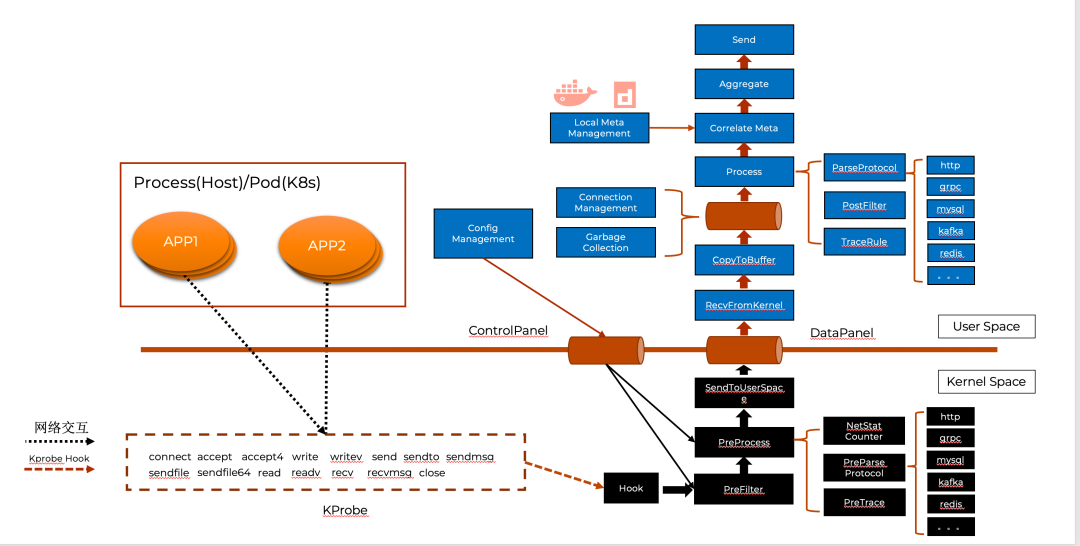
參考下圖TCP 建立連接過(guò)程內(nèi)核函數(shù)的調(diào)用,對(duì)于eBPF 程序可以很容易的定義好tracepoints/kprobe 切入點(diǎn)。例如建立連接過(guò)程可以切入 accept 以及connect 函數(shù),釋放鏈接過(guò)程可以切入close過(guò)程,而傳輸數(shù)據(jù)可以切入read 或write函數(shù)。 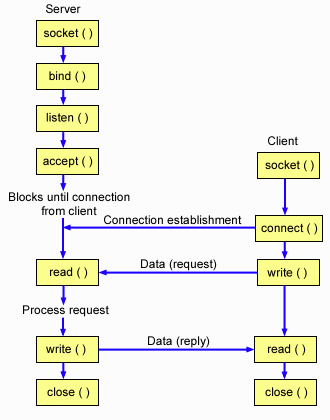 基于TCP 大多數(shù)切入點(diǎn)已經(jīng)被靜態(tài)化為tracepoints,因此BPF 程序定義如下切入點(diǎn)來(lái)覆蓋上述提到的TCP 核心函數(shù)(sys_enter 代表進(jìn)入時(shí)切入,sys_exit 代表返回時(shí)切入)。 SEC("tracepoint/syscalls/sys_enter_connect") SEC("tracepoint/syscalls/sys_exit_connect") SEC("tracepoint/syscalls/sys_enter_accept") SEC("tracepoint/syscalls/sys_exit_accept") SEC("tracepoint/syscalls/sys_enter_accept4") SEC("tracepoint/syscalls/sys_exit_accept4") SEC("tracepoint/syscalls/sys_enter_close") SEC("tracepoint/syscalls/sys_exit_close") SEC("tracepoint/syscalls/sys_enter_write") SEC("tracepoint/syscalls/sys_exit_write") SEC("tracepoint/syscalls/sys_enter_read") SEC("tracepoint/syscalls/sys_exit_read") SEC("tracepoint/syscalls/sys_enter_sendmsg") SEC("tracepoint/syscalls/sys_exit_sendmsg") SEC("tracepoint/syscalls/sys_enter_recvmsg") SEC("tracepoint/syscalls/sys_exit_recvmsg") .... 結(jié)合上述概念,我們以iLogtail的eBPF 工作模型為例,介紹一個(gè)可觀測(cè)領(lǐng)域的eBPF 程序是如何真正工作的。更多詳細(xì)內(nèi)容可以參考此分享:?基于eBPF的應(yīng)用可觀測(cè)技術(shù)實(shí)踐。如下圖所示,iLogtaileBPF 程序的工作空間分為Kernel Space與User Space。 Kernel Space 主要負(fù)責(zé)數(shù)據(jù)的抓取與預(yù)處理:
基于TCP 大多數(shù)切入點(diǎn)已經(jīng)被靜態(tài)化為tracepoints,因此BPF 程序定義如下切入點(diǎn)來(lái)覆蓋上述提到的TCP 核心函數(shù)(sys_enter 代表進(jìn)入時(shí)切入,sys_exit 代表返回時(shí)切入)。 SEC("tracepoint/syscalls/sys_enter_connect") SEC("tracepoint/syscalls/sys_exit_connect") SEC("tracepoint/syscalls/sys_enter_accept") SEC("tracepoint/syscalls/sys_exit_accept") SEC("tracepoint/syscalls/sys_enter_accept4") SEC("tracepoint/syscalls/sys_exit_accept4") SEC("tracepoint/syscalls/sys_enter_close") SEC("tracepoint/syscalls/sys_exit_close") SEC("tracepoint/syscalls/sys_enter_write") SEC("tracepoint/syscalls/sys_exit_write") SEC("tracepoint/syscalls/sys_enter_read") SEC("tracepoint/syscalls/sys_exit_read") SEC("tracepoint/syscalls/sys_enter_sendmsg") SEC("tracepoint/syscalls/sys_exit_sendmsg") SEC("tracepoint/syscalls/sys_enter_recvmsg") SEC("tracepoint/syscalls/sys_exit_recvmsg") .... 結(jié)合上述概念,我們以iLogtail的eBPF 工作模型為例,介紹一個(gè)可觀測(cè)領(lǐng)域的eBPF 程序是如何真正工作的。更多詳細(xì)內(nèi)容可以參考此分享:?基于eBPF的應(yīng)用可觀測(cè)技術(shù)實(shí)踐。如下圖所示,iLogtaileBPF 程序的工作空間分為Kernel Space與User Space。 Kernel Space 主要負(fù)責(zé)數(shù)據(jù)的抓取與預(yù)處理:
抓取:Hook模塊會(huì)依據(jù)KProbe定義攔截網(wǎng)絡(luò)數(shù)據(jù),虛線中為具體的KProbe 攔截的內(nèi)核函數(shù)(使用上述描述的SEC進(jìn)行定義),如connect、accept 以及write 等。
預(yù)處理:預(yù)處理模塊會(huì)根據(jù)用戶態(tài)配置進(jìn)行數(shù)據(jù)的攔截丟棄以及數(shù)據(jù)協(xié)議的推斷,只有符合需求的數(shù)據(jù)才會(huì)傳遞給SendToUserSpace模塊,而其他數(shù)據(jù)將會(huì)被丟棄。其后SendToUserSpace 模塊通過(guò)eBPF Map 將過(guò)濾后的數(shù)據(jù)由內(nèi)核態(tài)數(shù)據(jù)傳輸?shù)接脩魬B(tài)。
User Space 的模塊主要負(fù)責(zé)數(shù)據(jù)分析、聚合以及管理:
分析:Process 模塊會(huì)不斷處理eBPF Map中存儲(chǔ)的網(wǎng)絡(luò)數(shù)據(jù),首先由于Kernel 已經(jīng)推斷協(xié)議類型,Process 模塊將根據(jù)此類型進(jìn)行細(xì)粒度的協(xié)議分析,如分析MySQL 協(xié)議的SQL、分析HTTP 協(xié)議的狀態(tài)碼等。其次由于 Kernel 所傳遞的連接元數(shù)據(jù)信息只有Pid 與FD 等進(jìn)程粒度元信息,而對(duì)于Kubernetes 可觀測(cè)場(chǎng)景來(lái)說(shuō),Pod、Container 等資源定義更有意義,所以Correlate Meta 模塊會(huì)為Process 處理后的數(shù)據(jù)綁定容器相關(guān)的元數(shù)據(jù)信息。
聚合:當(dāng)綁定元數(shù)據(jù)信息后,Aggreate 模塊會(huì)對(duì)數(shù)據(jù)進(jìn)行聚合操作以避免重復(fù)數(shù)據(jù)傳輸,比如聚合周期內(nèi)某SQL 調(diào)用1000次,Aggreate 模塊會(huì)將最終數(shù)據(jù)抽象為 XSQL:1000 的形式進(jìn)行上傳。
管理:整個(gè)eBPF 程序交互著大量著進(jìn)程與連接數(shù)據(jù),因此eBPF 程序中對(duì)象的生命周期需要與機(jī)器實(shí)際狀態(tài)相符,當(dāng)進(jìn)程或鏈接釋放,相應(yīng)的對(duì)象也需要釋放,這也正對(duì)應(yīng)著Connection Management 與Garbage Collection 的職責(zé)。
eBPF 數(shù)據(jù)解析 HTTP 1 、HTTP1.1以及HTTP2 數(shù)據(jù)協(xié)議都是基于TCP的,參考上文,一定有以下函數(shù)調(diào)用:
connect 函數(shù):函數(shù)簽名為int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen), 從函數(shù)簽名入?yún)⒖梢垣@取使用的socket 的fd,以及對(duì)端地址等信息。
accept 函數(shù):函數(shù)簽名為int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen), 從函數(shù)簽名入?yún)⑼瑯涌梢垣@取使用的socket 的fd,以及對(duì)端地址等信息。
sendmsg函數(shù):函數(shù)簽名為ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags),從函數(shù)簽名可以看出,基于此函數(shù)可以拿到發(fā)送的數(shù)據(jù)包,以及使用的socket 的fd信息,但無(wú)法直接基于入?yún)⒅獣詫?duì)端地址。
recvmsg函數(shù):函數(shù)簽名為ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags),從函數(shù)簽名可以看出,基于此函數(shù)我們拿到接收的數(shù)據(jù)包,以及使用的socket 的fd信息,但無(wú)法直接基于入?yún)⒅獣詫?duì)端地址。
close 函數(shù):函數(shù)簽名為int close(int fd),從函數(shù)簽名可以看出,基于此函數(shù)可以拿到即將關(guān)閉的fd信息。
HTTP 1 / HTTP 1.1 短連接模式
HTTP 于1996年推出,HTTP 1 在用戶層是短連接模型,也就意味著每一次發(fā)送數(shù)據(jù),都會(huì)伴隨著connect、accept以及close 函數(shù)的調(diào)用,這就以為這eBPF程序可以很容易的尋找到connect 的起始點(diǎn),將傳輸數(shù)據(jù)與地址進(jìn)行綁定,進(jìn)而構(gòu)建服務(wù)的上下游調(diào)用關(guān)系。 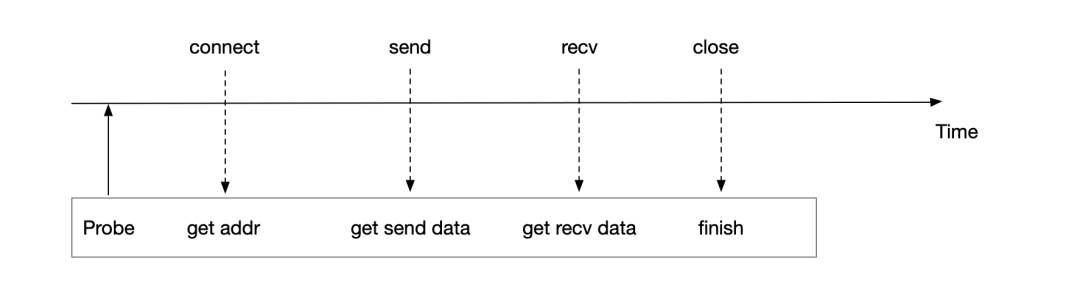 可以看出HTTP 1 或者HTTP1.1 短連接模式是對(duì)于eBPF 是非常友好的協(xié)議,因?yàn)榭梢暂p松的關(guān)聯(lián)地址信息與數(shù)據(jù)信息,但回到HTTP 1/HTTP1.1 短連接模式 本身來(lái)說(shuō),‘友好的代價(jià)’不僅意味著帶來(lái)每次TCP 連接與釋放連接的消耗,如果兩次傳輸數(shù)據(jù)的HTTP Header 頭相同,Header 頭也存在冗余傳輸問(wèn)題,比如下列數(shù)據(jù)的頭Host、Accept 等字段。
可以看出HTTP 1 或者HTTP1.1 短連接模式是對(duì)于eBPF 是非常友好的協(xié)議,因?yàn)榭梢暂p松的關(guān)聯(lián)地址信息與數(shù)據(jù)信息,但回到HTTP 1/HTTP1.1 短連接模式 本身來(lái)說(shuō),‘友好的代價(jià)’不僅意味著帶來(lái)每次TCP 連接與釋放連接的消耗,如果兩次傳輸數(shù)據(jù)的HTTP Header 頭相同,Header 頭也存在冗余傳輸問(wèn)題,比如下列數(shù)據(jù)的頭Host、Accept 等字段。 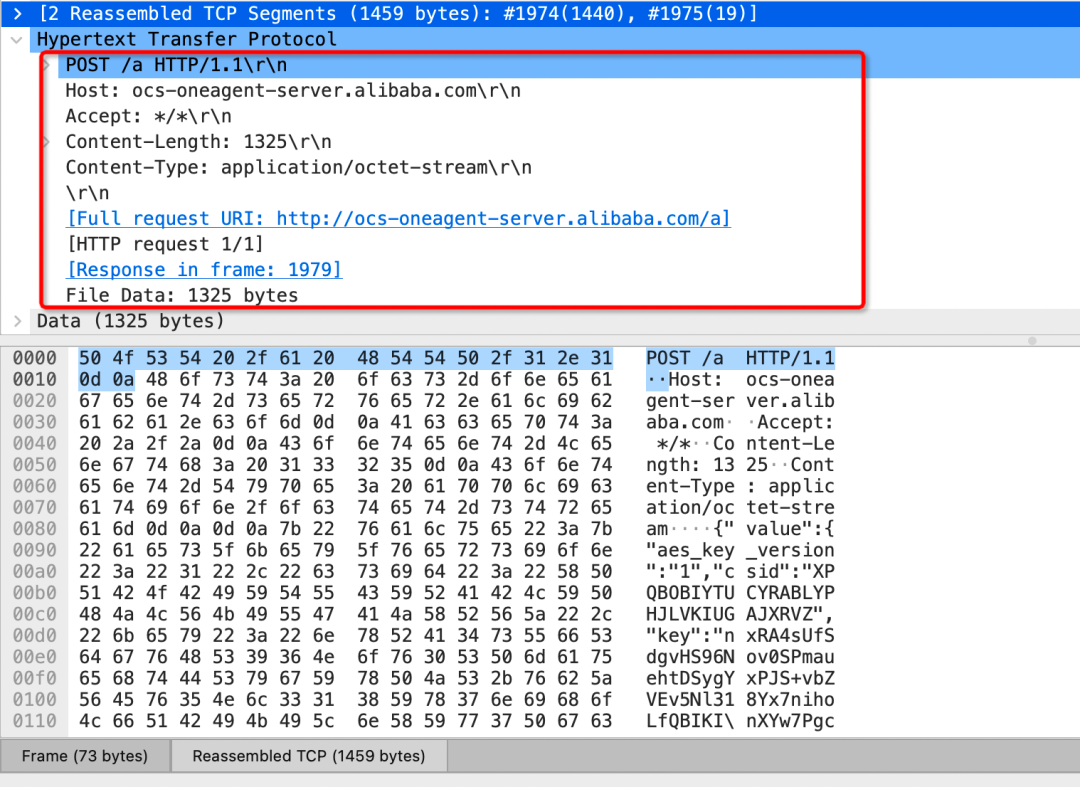
HTTP 1.1 長(zhǎng)連接
HTTP 1.1 于HTTP 1.0 發(fā)布的一年后發(fā)布(1997年),提供了緩存處理、帶寬優(yōu)化、錯(cuò)誤通知管理、host頭處理以及長(zhǎng)連接等特性。而長(zhǎng)連接的引入也部分解決了上述HTTP1中每次發(fā)送數(shù)據(jù)都需要經(jīng)過(guò)三次握手以及四次揮手的過(guò)程,提升了數(shù)據(jù)的發(fā)送效率。但對(duì)于使用eBPF 觀察HTTP數(shù)據(jù)來(lái)說(shuō),也帶來(lái)了新的問(wèn)題,上文提到建立地址與數(shù)據(jù)的綁定依賴于在connect 時(shí)進(jìn)行probe,通過(guò)connect 參數(shù)拿到數(shù)據(jù)地址,從而與后續(xù)的數(shù)據(jù)包綁定。但回到長(zhǎng)連接情況,假如connect 于1小時(shí)之前建立,而此時(shí)才啟動(dòng)eBPF程序,所以我們只能探測(cè)到數(shù)據(jù)包函數(shù)的調(diào)用,如send或recv函數(shù)。此時(shí)應(yīng)該如何建立地址與數(shù)據(jù)的關(guān)系呢? 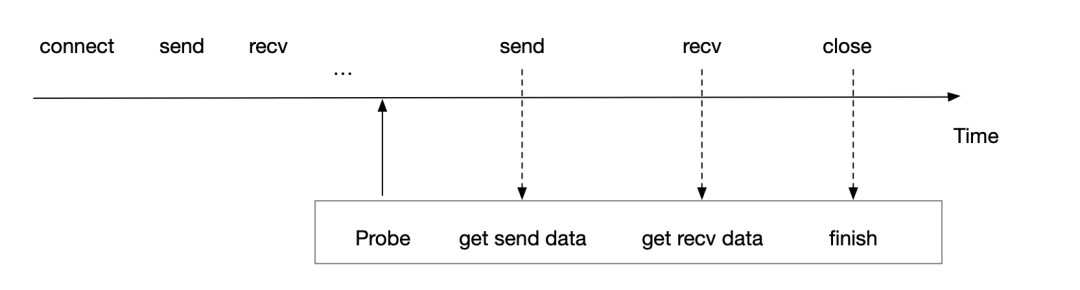 首先可以回到探測(cè)函數(shù)的定義,可以發(fā)現(xiàn)此時(shí)雖然沒(méi)有明確的地址信息,但是可以知道此TCP 報(bào)文使用的Socket 與FD 信息。因此可以使用 netlink 獲取此Socket 的元信息,進(jìn)行對(duì)長(zhǎng)連接補(bǔ)充對(duì)端地址,進(jìn)而在HTTP 1.1 長(zhǎng)連接協(xié)議構(gòu)建服務(wù)拓?fù)渑c分析數(shù)據(jù)明細(xì)。 ssize_t?sendmsg(int?sockfd,?const?struct?msghdr?*msg,?int?flags) ssize_t?recvmsg(int?sockfd,?struct?msghdr?*msg,?int?flags)
首先可以回到探測(cè)函數(shù)的定義,可以發(fā)現(xiàn)此時(shí)雖然沒(méi)有明確的地址信息,但是可以知道此TCP 報(bào)文使用的Socket 與FD 信息。因此可以使用 netlink 獲取此Socket 的元信息,進(jìn)行對(duì)長(zhǎng)連接補(bǔ)充對(duì)端地址,進(jìn)而在HTTP 1.1 長(zhǎng)連接協(xié)議構(gòu)建服務(wù)拓?fù)渑c分析數(shù)據(jù)明細(xì)。 ssize_t?sendmsg(int?sockfd,?const?struct?msghdr?*msg,?int?flags) ssize_t?recvmsg(int?sockfd,?struct?msghdr?*msg,?int?flags) 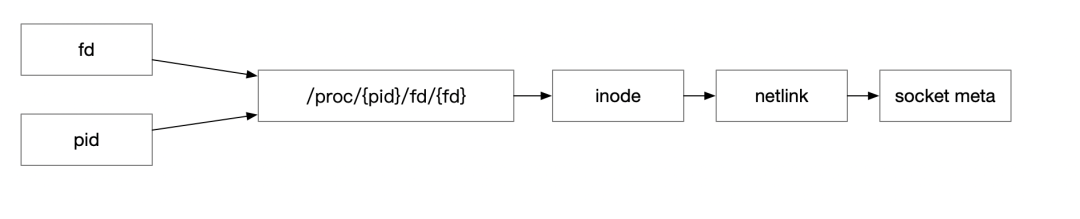
HTTP 2
在HTTP 1.1 發(fā)布后,由于冗余傳輸以及傳輸模型串行等問(wèn)題,RPC 框架基本上都是進(jìn)行了私有化協(xié)議定義,如Dubbo 等。而在2015年,HTTP2 的發(fā)布打破了以往對(duì)HTTP 協(xié)議的很多詬病,除解決在上述我們提到的Header 頭冗余傳輸問(wèn)題,還解決TCP連接數(shù)限制、傳輸效率、隊(duì)頭擁塞等問(wèn)題,而 gRPC正式基于HTTP2 構(gòu)建了高性能RPC 框架,也讓HTTP 1 時(shí)代層出不窮的通信協(xié)議,也逐漸走向了歸一時(shí)代,比如Dubbo3 全面兼容gRPC/HTTP2 協(xié)議。
特性
以下內(nèi)容首先介紹一些HTTP2 與eBPF 可觀察性相關(guān)的關(guān)鍵特性。
多路復(fù)用
HTTP 1 是一種同步、獨(dú)占的協(xié)議,客戶端發(fā)送消息,等待服務(wù)端響應(yīng)后,才進(jìn)行新的信息發(fā)送,這種模式浪費(fèi)了TCP 全雙工模式的特性。因此HTTP2 允許在單個(gè)連接上執(zhí)行多個(gè)請(qǐng)求,每個(gè)請(qǐng)求相應(yīng)使用不同的流,通過(guò)二進(jìn)制分幀層,為每個(gè)幀分配一個(gè)專屬的stream 標(biāo)識(shí)符,而當(dāng)接收方收到信息時(shí),接收方可以將幀重組為完整消息,提升了數(shù)據(jù)的吞吐。此外可以看到由于Stream 的引入,Header 與Data 也進(jìn)行了分離設(shè)計(jì),每次傳輸數(shù)據(jù)Heaer 幀發(fā)送后為此后Data幀的統(tǒng)一頭部,進(jìn)一步提示了傳輸效率。 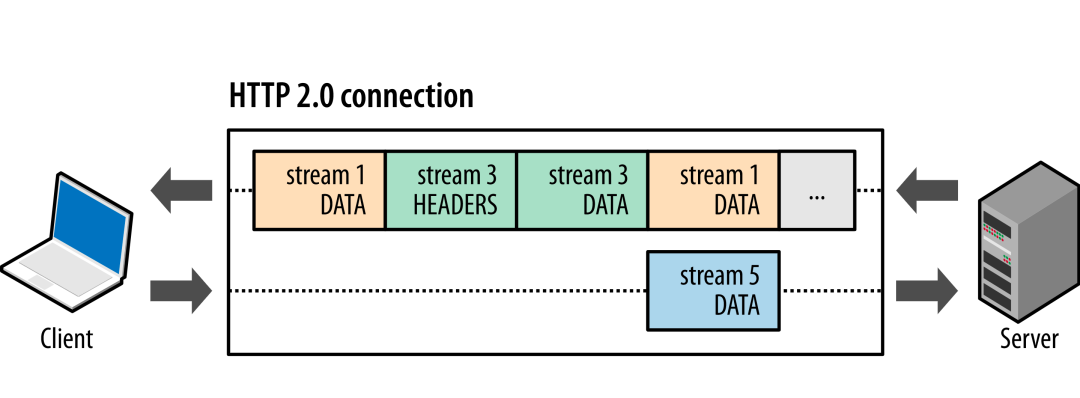
首部壓縮
HTTP 首部用于發(fā)送與請(qǐng)求和響應(yīng)相關(guān)的額外信息,HTTP2引入首部壓縮概念,使用與正文壓縮不同的技術(shù),支持跨請(qǐng)求壓縮首部,可以避免正文壓縮使用算法的安全問(wèn)題。HTTP2采用了基于查詢表和Huffman編碼的壓縮方式,使用由預(yù)先定義的靜態(tài)表和會(huì)話過(guò)程中創(chuàng)建的動(dòng)態(tài)表,沒(méi)有引用索引表的首部可以使用ASCII編碼或者Huffman編碼傳輸。 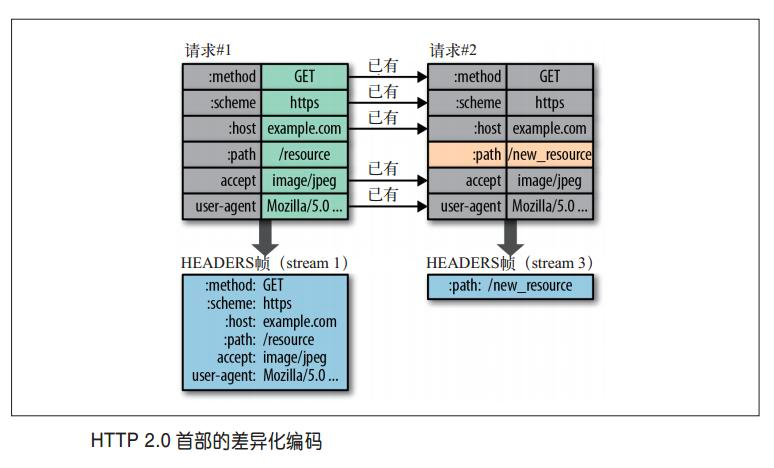 但隨著性能的提升,也意味著越來(lái)越多的數(shù)據(jù)避免傳輸,這也同時(shí)意味著對(duì)eBPF 程序可感知的數(shù)據(jù)會(huì)更少,因此HTTP2協(xié)議的可觀察性也帶來(lái)了新的問(wèn)題,以下我們使用gRPC不同模式以及Wireshark 分析HTTP2協(xié)議對(duì)eBPF 程序可觀測(cè)性的挑戰(zhàn)。
但隨著性能的提升,也意味著越來(lái)越多的數(shù)據(jù)避免傳輸,這也同時(shí)意味著對(duì)eBPF 程序可感知的數(shù)據(jù)會(huì)更少,因此HTTP2協(xié)議的可觀察性也帶來(lái)了新的問(wèn)題,以下我們使用gRPC不同模式以及Wireshark 分析HTTP2協(xié)議對(duì)eBPF 程序可觀測(cè)性的挑戰(zhàn)。
GRPC
Simple RPC
Simple RPC 是GRPC 最簡(jiǎn)單的通信模式,請(qǐng)求和響應(yīng)都是一條二進(jìn)制消息,如果保持連接可以類比為HTTP 1.1 的長(zhǎng)連接模式,每次發(fā)送收到響應(yīng),之后再繼續(xù)發(fā)送數(shù)據(jù)。 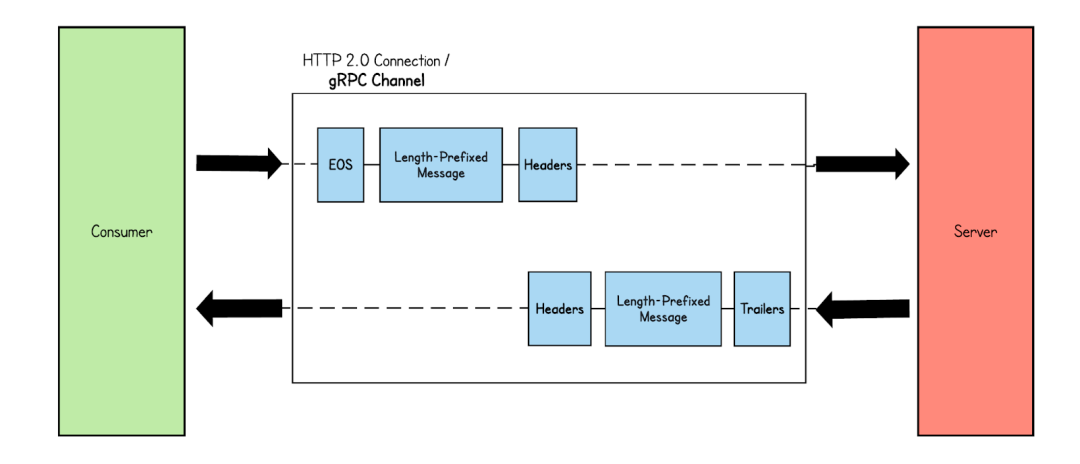 但與HTTP 1 不同的是首部壓縮的引入,如果維持長(zhǎng)連接狀態(tài),后續(xù)發(fā)的數(shù)據(jù)包Header 信息將只存儲(chǔ)索引值,而不是原始值,我們可以看到下圖為Wirshark 抓取的數(shù)據(jù)包,首次發(fā)送是包含完整Header幀數(shù)據(jù),而后續(xù)Heders 幀長(zhǎng)度降低為15,減少了大量重復(fù)數(shù)據(jù)的傳輸。
但與HTTP 1 不同的是首部壓縮的引入,如果維持長(zhǎng)連接狀態(tài),后續(xù)發(fā)的數(shù)據(jù)包Header 信息將只存儲(chǔ)索引值,而不是原始值,我們可以看到下圖為Wirshark 抓取的數(shù)據(jù)包,首次發(fā)送是包含完整Header幀數(shù)據(jù),而后續(xù)Heders 幀長(zhǎng)度降低為15,減少了大量重復(fù)數(shù)據(jù)的傳輸。 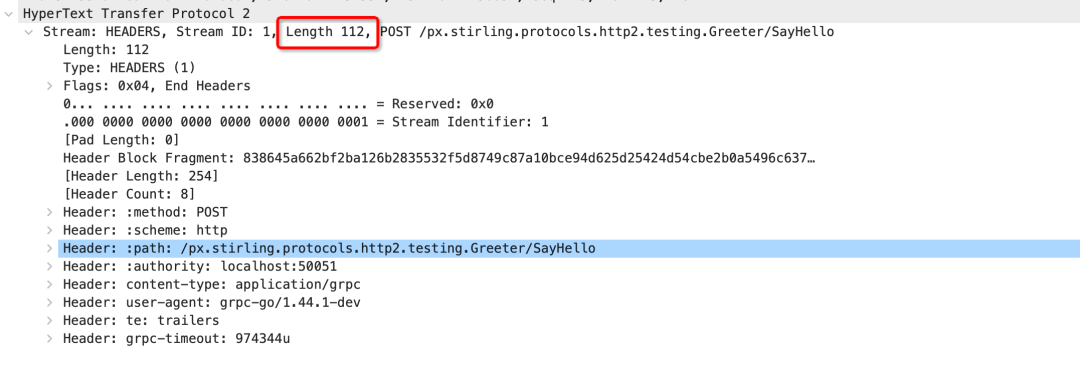
Stream 模式
Stream 模式是gRPC 常用的模式,包含Server-side streaming RPC,Client-side streaming RPC,Bidirectional streaming RPC,從傳輸編碼上來(lái)說(shuō)與Simple RPC 模式?jīng)]有不同,都分為Header 幀、Data幀等。但不同的在于Data 幀的數(shù)量,Simple RPC 一次發(fā)送或響應(yīng)只包含一個(gè)Data幀 模式,而Stream 模式可以包含多個(gè)。 1、Server-side streaming RPC:與Simple RPC 模式不同,在Server-side streaming RPC 中,當(dāng)從客戶端接收到請(qǐng)求時(shí),服務(wù)器會(huì)發(fā)回一系列響應(yīng)。此響應(yīng)消息序列在客戶端發(fā)起的同一 HTTP 流中發(fā)送。如下圖所示,服務(wù)器收到來(lái)自客戶端的消息,并以幀消息的形式發(fā)送多個(gè)響應(yīng)消息。最后,服務(wù)器通過(guò)發(fā)送帶有呼叫狀態(tài)詳細(xì)信息的尾隨元數(shù)據(jù)來(lái)結(jié)束流。 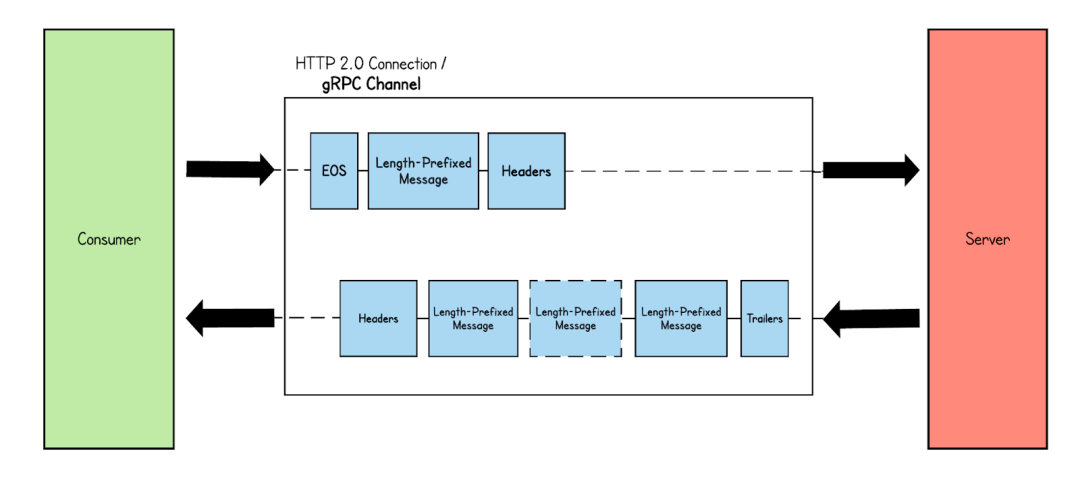 2、Client-side streaming RPC:?在客戶端流式 RPC 模式中,客戶端向服務(wù)器發(fā)送多條消息,而服務(wù)器只返回一條消息。
2、Client-side streaming RPC:?在客戶端流式 RPC 模式中,客戶端向服務(wù)器發(fā)送多條消息,而服務(wù)器只返回一條消息。 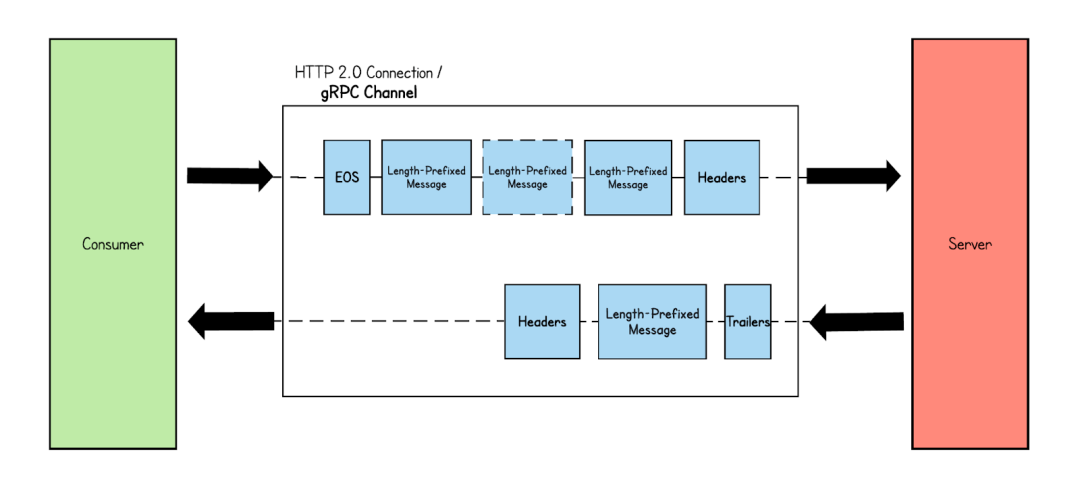 3、Bidirectional streaming RPC:客戶端和服務(wù)器都向?qū)Ψ桨l(fā)送消息流。客戶端通過(guò)發(fā)送標(biāo)頭幀來(lái)設(shè)置 HTTP 流。建立連接后,客戶端和服務(wù)器都可以同時(shí)發(fā)送消息,而無(wú)需等待對(duì)方完成。
3、Bidirectional streaming RPC:客戶端和服務(wù)器都向?qū)Ψ桨l(fā)送消息流。客戶端通過(guò)發(fā)送標(biāo)頭幀來(lái)設(shè)置 HTTP 流。建立連接后,客戶端和服務(wù)器都可以同時(shí)發(fā)送消息,而無(wú)需等待對(duì)方完成。 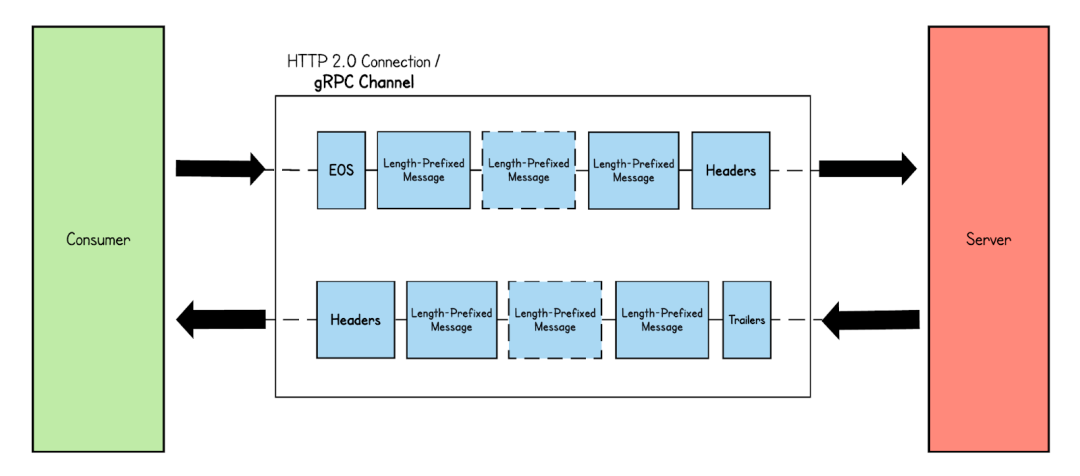
tracepoint/kprobe的挑戰(zhàn)
從上述wirshark 報(bào)文以及協(xié)議模式可以看出,歷史針對(duì)HTTP1時(shí)代使用的tracepoint/kprobe 會(huì)存在以下挑戰(zhàn):
Stream 模式: 比如在Server-side stream 下,假如tracepoint/kprobe 探測(cè)的點(diǎn)為Data幀,因Data 幀因?yàn)闊o(wú)法關(guān)聯(lián)Header 幀,都將變成無(wú)效Data 幀,但對(duì)于gRPC 使用場(chǎng)景來(lái)說(shuō)還好,一般RPC 發(fā)送數(shù)據(jù)和接受數(shù)據(jù)都很快,所以很快就會(huì)有新的Header 幀收到,但這時(shí)會(huì)遇到更大的挑戰(zhàn),長(zhǎng)連接下的首部壓縮。
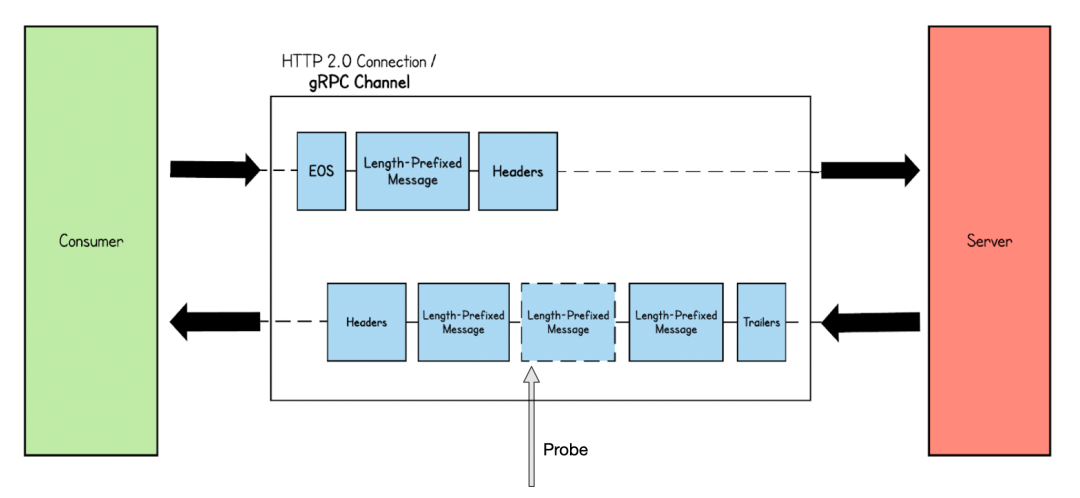
長(zhǎng)連接+首部壓縮:當(dāng)HTTP2 保持長(zhǎng)連接,connect 后的第一個(gè)Stream 傳輸?shù)腍eader 會(huì)為完整數(shù)據(jù),而后續(xù)Header幀如與前置Header幀存在相同Header 字段,則數(shù)據(jù)傳輸?shù)臑榈刂沸畔ⅲ嬲臄?shù)據(jù)信息會(huì)交給Server 或Client 端的應(yīng)用層SDK 進(jìn)行維護(hù),而如下圖eBPF tracepoints/kprobe 在stream 1 的尾部幀才進(jìn)行probe,對(duì)于后續(xù)的Header2 幀大概率不會(huì)存在完整的Header 元數(shù)據(jù),如下圖Wireshark 截圖,包含了很多Header 信息的Header 長(zhǎng)度僅僅為15,可以看出eBPF tracepoints/kprobe 對(duì)于這種情況很難處理。
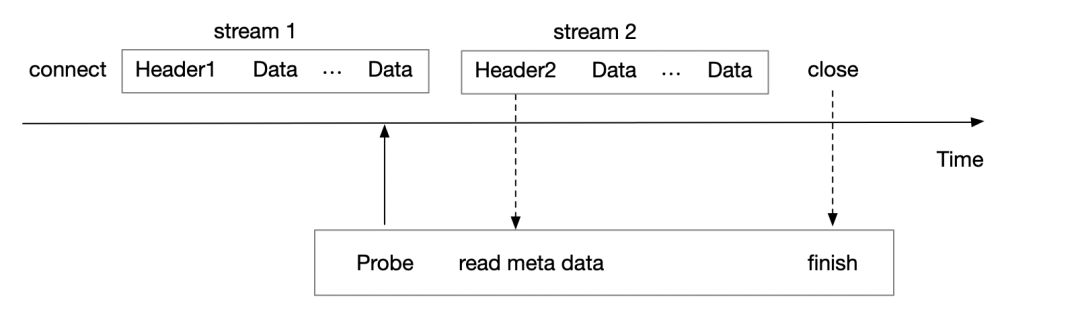 從上文可知,HTTP2 可以歸屬于有狀態(tài)的協(xié)議,而Tracepoint/Kprobe 對(duì)有狀態(tài)的協(xié)議數(shù)據(jù)很難處理完善,某些場(chǎng)景下只能做到退化處理,以下為使用Tracepoint/Kprobe 處理的基本流程。
從上文可知,HTTP2 可以歸屬于有狀態(tài)的協(xié)議,而Tracepoint/Kprobe 對(duì)有狀態(tài)的協(xié)議數(shù)據(jù)很難處理完善,某些場(chǎng)景下只能做到退化處理,以下為使用Tracepoint/Kprobe 處理的基本流程。 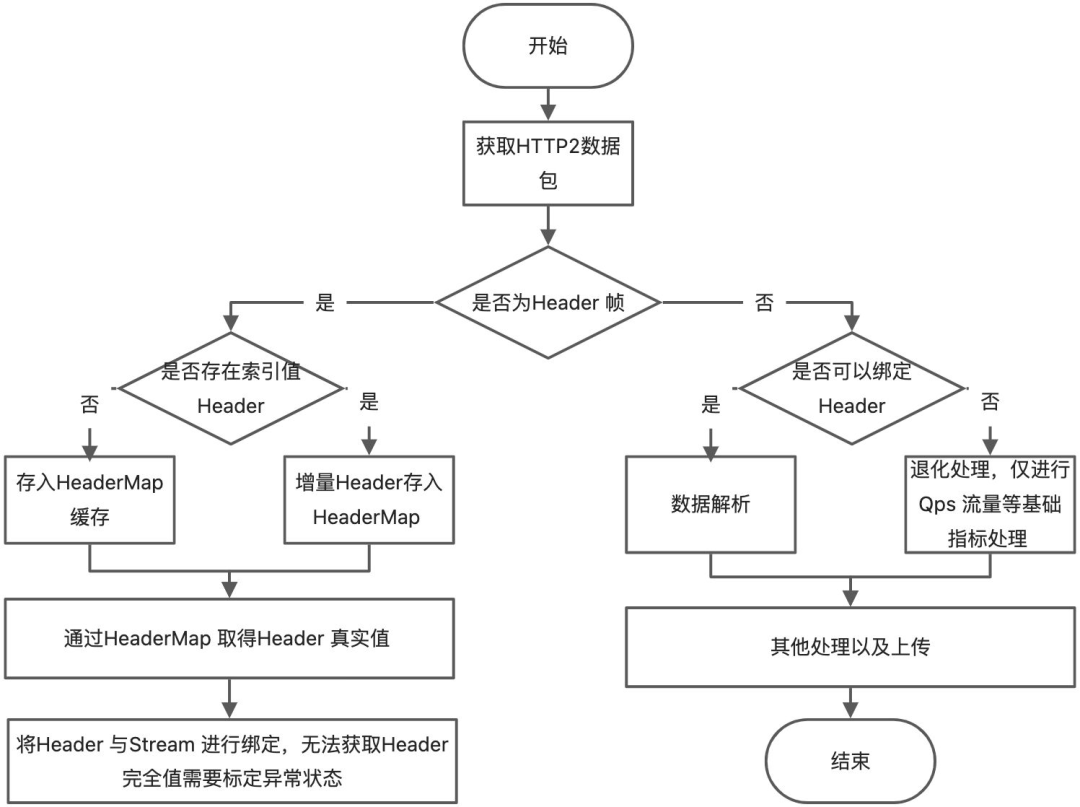
Uprobe 可行嗎?
從上述tracepoint/kprobe 的挑戰(zhàn)可以看到,HTTP 2 是一種很難被觀測(cè)的協(xié)議,在HTTP2 的協(xié)議規(guī)范上,為減少Header 的傳輸,client 端以及server 端都需要維護(hù)Header 的數(shù)據(jù),下圖是grpc 實(shí)現(xiàn)的HTTP2 客戶端維護(hù)Header 元信息的截圖,所以在應(yīng)用層可以做到拿到完整Header數(shù)據(jù),也就繞過(guò)來(lái)首部壓縮問(wèn)題,而針對(duì)應(yīng)用層協(xié)議,eBPF 提供的探測(cè)手段是Uprobe(用戶態(tài)),而Pixie 項(xiàng)目也正是基于Uprobe 實(shí)踐了gRPC HTTP2 流量的探測(cè),詳細(xì)內(nèi)容可以參考此文章[1]。 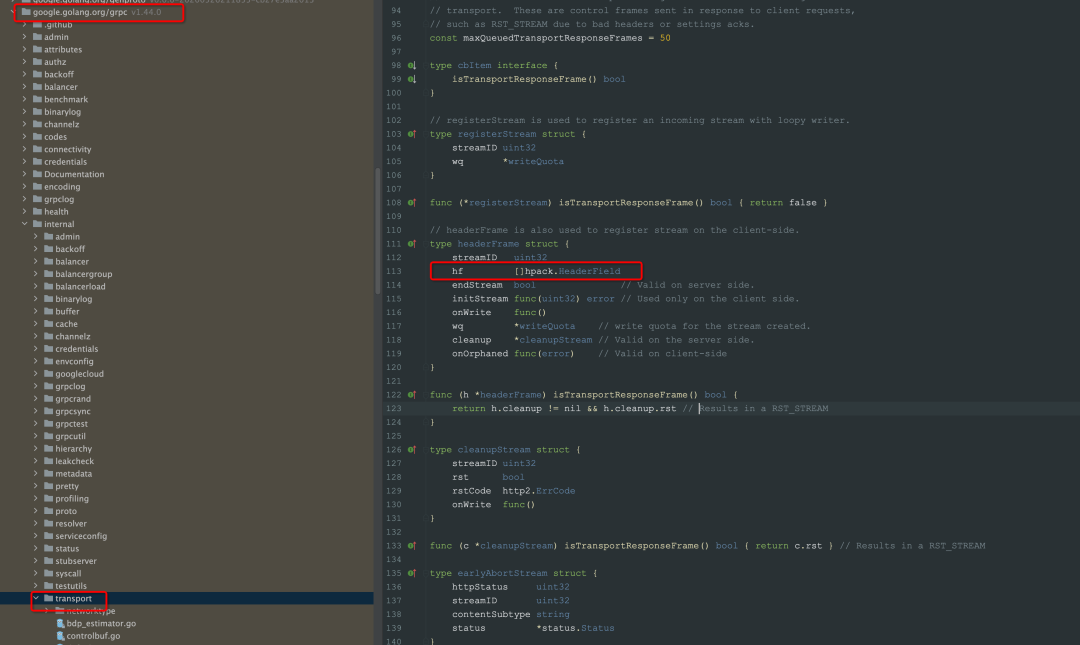 下圖展示了使用Uprobe 觀測(cè)Go gRPC 流量的基本流程,如其中writeHeader 的函數(shù)定義為 func (l *loopyWriter) writeHeader(streamID uint32, endStream bool, hf []hpack.HeaderField, onWrite func()), 可以看到明確的Header 文本。
下圖展示了使用Uprobe 觀測(cè)Go gRPC 流量的基本流程,如其中writeHeader 的函數(shù)定義為 func (l *loopyWriter) writeHeader(streamID uint32, endStream bool, hf []hpack.HeaderField, onWrite func()), 可以看到明確的Header 文本。 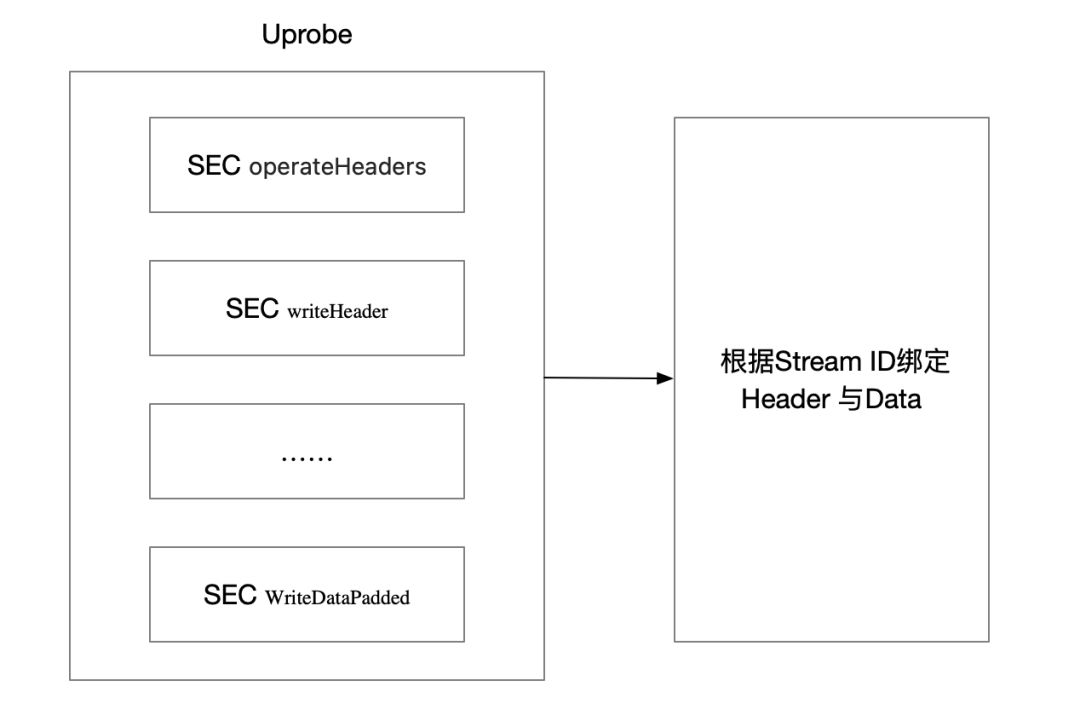
Kprobe 與Uprobe 對(duì)比
從上文可以看出Uprobe 實(shí)現(xiàn)簡(jiǎn)單,且不存在數(shù)據(jù)退化的問(wèn)題,但Uprobe 真的完美嗎?
兼容性:上述方案僅僅是基于Golang gRPC 的 特定方法進(jìn)行探測(cè),也就意味著上述僅能覆蓋Golang gRPC 流量的觀察,對(duì)于Golang 其他HTTP2 庫(kù)無(wú)法支持。
多語(yǔ)言性:Uprobe 只能基于方法簽名進(jìn)行探測(cè),更適用于C/GO 這種純編譯型語(yǔ)言,而對(duì)于Java 這種JVM 語(yǔ)言,因?yàn)檫\(yùn)行時(shí)動(dòng)態(tài)生成符號(hào)表,雖然可以依靠一些javaagent 將java 程序用于Uprobe,但是相對(duì)于純編譯型語(yǔ)言,用戶使用成本或改造成本還是會(huì)更高一些。
穩(wěn)定性:Uprobe 相對(duì)于tracepoint/kprobe 來(lái)說(shuō)是不穩(wěn)定的,假如探測(cè)的函數(shù)函數(shù)簽名有改變,這就意味著Uprobe 程序?qū)o(wú)法工作,因?yàn)楹瘮?shù)注冊(cè)表的改變將使得Uprobe 無(wú)法找到切入點(diǎn)。
綜合下來(lái)2種方案對(duì)比如下,可以看到2種方案對(duì)于HTTP2(有狀態(tài))的觀測(cè)都存在部分取舍:
| 方式 | 穩(wěn)定性 | 多語(yǔ)言性 | 兼容性 | 易于實(shí)現(xiàn) | 數(shù)據(jù)完整性 |
| Kprobe/tracepoint | 強(qiáng) | 強(qiáng) | 強(qiáng) | 復(fù)雜 | 存在數(shù)據(jù)退化 |
| Uprobe | 弱 | 弱 | 弱 | 簡(jiǎn)單 | 完整 |
總結(jié) 上述我們回顧了HTTP1到HTTP2 時(shí)代的協(xié)議變遷,也看到HTTP2 提升傳輸效率做的種種努力,而正是HTTP2的巨大效率提升,也讓gRPC選擇了直接基于HTTP2 協(xié)議構(gòu)建,而也是這種選擇,讓gRPC 成為了RPC 百家爭(zhēng)鳴后是隱形事實(shí)協(xié)議。但我們也看到了協(xié)議的進(jìn)步意味著更少的數(shù)據(jù)交互,也讓數(shù)據(jù)可觀察變得更加困難,比如HTTP2 使用eBPF目前尚無(wú)完美的解決方法,或使用Kprobe 觀察,選擇的多語(yǔ)言性、流量拓?fù)浞治觥⒌菰S了失去流量細(xì)節(jié)的風(fēng)險(xiǎn);或使用Uprobe 觀察,選擇了數(shù)據(jù)的細(xì)節(jié),拓?fù)洌菰S了多語(yǔ)言的兼容性問(wèn)題。 iLogtail致力于打造覆蓋Trace、Metrics 以及Logging 的可觀測(cè)性的統(tǒng)一Agent,而eBPF 作為目前可觀測(cè)領(lǐng)域的熱門采集技術(shù),提供了無(wú)侵入、安全、高效觀測(cè)流量的能力,預(yù)計(jì)8月份,我們將在iLogtail Cpp正式開源后發(fā)布此部分功能,歡迎大家關(guān)注和互相交流。
-
網(wǎng)絡(luò)
+關(guān)注
關(guān)注
14文章
7860瀏覽量
91237 -
HTTP
+關(guān)注
關(guān)注
0文章
526瀏覽量
33733 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4386瀏覽量
65246
原文標(biāo)題:一文詳解用eBPF觀測(cè)HTTP
文章出處:【微信號(hào):LinuxDev,微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
關(guān)于 eBPF 安全可觀測(cè)性,你需要知道的那些事兒
openEuler 倡議建立 eBPF 軟件發(fā)布標(biāo)準(zhǔn)
基于拓?fù)浞指畹木W(wǎng)絡(luò)可觀測(cè)性分析方法
eBPF安全可觀測(cè)性的前景展望
六大頂級(jí)、開源的數(shù)據(jù)可觀測(cè)性工具
Linux內(nèi)核觀測(cè)技術(shù)eBPF中文入門指南
eBPF,何以稱得上是革命性的內(nèi)核技術(shù)?

華為云應(yīng)用運(yùn)維管理平臺(tái)獲評(píng)中國(guó)信通院可觀測(cè)性評(píng)估先進(jìn)級(jí)
使用APM無(wú)法實(shí)現(xiàn)真正可觀測(cè)性的原因
什么是多云? 為什么我們需要多云可觀測(cè)性 (Observability)?
如何構(gòu)建APISIX基于DeepFlow的統(tǒng)一可觀測(cè)性能力呢?
華為云發(fā)布全棧可觀測(cè)平臺(tái) AOM,以 AI 賦能應(yīng)用運(yùn)維可觀測(cè)

【質(zhì)量視角】可觀測(cè)性背景下的質(zhì)量保障思路
eBPF技術(shù)實(shí)踐之virtio-net網(wǎng)卡隊(duì)列可觀測(cè)
DeepSeek賦能Vixtel飛思達(dá)CloudFox可觀測(cè)性平臺(tái),打破可觀測(cè)性工程的實(shí)施壁壘





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論