") 計算機視覺圖像技術:視覺圖像搜索綜述
計算機視覺圖像技術:視覺圖像搜索綜述
美麗是平凡的,平凡得讓你感覺不到她的存在;美麗是平淡的,平淡得只剩下溫馨的回憶;美麗又是平靜的,平靜得只有你費盡心思才能激起她的漣漪。
這些年計算機視覺識別和搜索這個領域非常熱鬧,后期出現(xiàn)了很多的創(chuàng)業(yè)公司,大公司也在這方面也花了很多力氣在做。做視覺搜索,其實是深度學習(或人工智能)領域最重要的研究課題之一,在現(xiàn)實生活中有著非常廣泛的應用。
通常,視覺搜索包含了兩步任務:首先,待搜索物體的檢測與定位;其次,從庫(知識圖譜、圖片庫、信息庫等)中搜索該物體,或查詢相關聯(lián)的場景。比如從簡單的以圖搜圖、車牌識別,到人臉識別、植物或寵物的識別,人體或車輛的跟蹤,無人機、無人汽車的自動駕駛,智能機器人等領域,都離不開計算機視覺搜索技術,這也是此次谷歌開源基于 TensorFlow 的物體檢測代碼的意義所在。
谷歌此次開源版本中已經(jīng)實現(xiàn)的 Faster R-CNN、R-FCN、SSD 檢測算法之外,還有不少其他檢測算法,如除 SSD 外,另一款端到端的檢測算法:YOLO(You Only Look Once),精度可能略遜于 Faster R-CNN(非絕對,不同的數(shù)據(jù)、網(wǎng)絡設計會導致差異),但檢測速度較快。后續(xù)的 YOLO 9000(YOLO 升級版),論文提到能夠檢測識別超過 9000 類的物體,而且檢測更加快速、準確。

計算機能夠比以往更快更精準的識別圖片,但它們需要大量數(shù)據(jù)。所以ImageNet 和 Pascal VOC 經(jīng)過多年積累建立了包含幾百萬張圖片的龐大且免費的數(shù)據(jù)集,用描述圖片內容的關鍵詞為圖片做好了標簽,包括貓、山、披薩和體育活動等。這些開源數(shù)據(jù)集是使用機器學習進行圖像識別的基礎。
ImageNet 每年一度的圖像識別挑戰(zhàn)賽眾所周知,ImageNet 由斯坦福大學和普林斯頓大學的計算機科學家在2009年發(fā)起,當時有 80,000 張打好標簽的圖片,到今天這個數(shù)據(jù)已經(jīng)增加到 140 萬張,這些數(shù)據(jù)可以隨時被用來進行機器訓練。
Pascal VOC 由英國的幾所大學支持,他們的圖片數(shù)量較少,但每張圖片有著更加豐富的釋文。這提升了機器學習的準確度和應用范圍,加快了整個過程,因為它可以省略掉一些繁重的子任務。
如今,谷歌、Facebook 等科技巨頭、創(chuàng)業(yè)公司、高校等都在使用這些開源圖片集來喂養(yǎng)他們的機器學習,但科技巨頭還享受另外一項優(yōu)勢,谷歌和 Facebook 可以從 Google Photos 社交網(wǎng)絡上獲取數(shù)百萬張用戶已經(jīng)標記好的圖片。你之前有沒有考慮過,為何谷歌和 Facebook 會讓你免費上傳如此多圖片?原因就在于這些圖片可以將他們的深度學習網(wǎng)絡訓練的更加準確。
一、舉例說明:
亞馬遜出品的Firefly當時引起了很大的轟動雖然這個產(chǎn)品也很難說是不是成功但是當時確實是很大膽的一個舉動。
百度也有圖像搜索和圖像識別微軟也有。
Google很早也有了Google Goggles這個產(chǎn)品雖然技術跟現(xiàn)在有很大的差別。
Pinterest在去年也有這樣的功能問世就是在它自己的分享照片上可以去搜相似的照片或者是相似的產(chǎn)品。
阿里巴巴的一個圖片搜索——拍立淘強調的是用自己手機去拍照片去搜索網(wǎng)上相同或者相似的商品。
二、如果想構建一個圖像搜索引擎,那如何對圖像進行搜索呢?
一種方式是依賴于與圖像相關聯(lián)的標簽、關鍵字和文字描述,這種稱為標簽搜索,或者叫以文搜圖。
另一種方式是通過量化圖像并提取一組數(shù)字來表示圖像的顏色、紋理或者形狀,然后通過對比圖像之間相似度來搜索圖像,這種成為范例搜索,或者叫以圖搜圖。
最后一種是結合前面兩種方式,既依賴與圖像相關的文字信息,也同時量化圖像本身,稱為混合搜索。
圖像搜索引擎有3種類型:標簽搜索、范例搜索和混合搜索
標簽搜索
在谷歌或百度輸入關鍵字并點擊搜索按鈕,這是我們熟悉的文本搜索方式,而圖像的標簽搜索與文本搜索很相似。圖像的標簽搜索引擎很少關注圖像本身,而依賴于文字線索。這些線索可以有各種來源,但主要方法是:
手動注釋:在這種情況下,管理員或者用戶提供圖像內容的標簽和關鍵字;
上下文提示:通常,上下文提示僅適用于網(wǎng)頁。與手動注釋我們必須人工提取標簽不同,上下文提示會自動檢查圖像周圍的文字內容或圖片標簽。這種方法的缺點是我們要假設圖像的內容與網(wǎng)頁上的文本有關。這可能適用于諸如百度百科這樣的網(wǎng)站,其頁面上的圖像與文章的內容高度相關;
范例搜索:
這些類型的圖像搜索引擎嘗試量化圖像本身,稱為基于內容的圖像檢索(CBIR)系統(tǒng)。一個簡單的例子是通過圖像中像素強度的平均值,標準偏差和偏度來表征圖像的顏色。(如果只是構建一個簡單的圖像搜索引擎,在許多情況下,這種方法實際效果很好)
對于給定的圖像數(shù)據(jù)集,將數(shù)據(jù)集中的所有圖像都計算出特征值,并將其存儲在磁盤上。當我們量化圖像時,我們描述圖像并提取圖像特征。這些圖像特征是圖像的抽象,并用于表征圖像內容,從圖像集合中提取特征的過程稱為索引。
假定現(xiàn)在我們從數(shù)據(jù)集中的每一個圖像中都提取出了特征,如何進行搜索呢?第一步是為我們的系統(tǒng)提供一個查詢圖像,這是我們在數(shù)據(jù)集中尋找的一個范例。查詢圖像以與索引圖像完全相同的方式提取特征。然后我們使用距離函數(shù)(如歐式距離)將我們的查詢特征與索引數(shù)據(jù)集中的特征進行比對。然后根據(jù)相似性(歐幾里德距離越小意味著越相似)的結果進行排序并顯示出來。
混合方式:
假如我們正在為Twitter建立一個圖像搜索引擎。Twitter允許在推文中使用圖片。同時,Twitter也允許你給自己的推文提供標簽。我們可以使用推文標簽來建立圖像的標簽搜索,然后分析和量化圖像本身特征,建立范例搜索。這樣做的方式就是構建一個混合圖像搜索引擎,其中包括文本關鍵字以及從圖像中提取的特征。
最好的例子就是谷歌的圖像搜索。谷歌的圖像搜索是實際通過分析圖像本身特征來進行搜索,但是谷歌首先是一個文本搜索引擎,因此它也允許你通過標簽進行搜索。
三、文本搜索又可以細分為三種
第一種用人來對文本做標記
最早期上個世紀七八十年代時是很小的圖片集 是通過人來添加圖像的文本標簽然后通過文本來搜索就夠了。之后就發(fā)展到了2004年前后的社交媒體時代那個時候像Flicker上圖片的Tag雖然也是人加的但是通過草根人群加的量就變得非常地大。通過這個也能做比較不錯的圖片搜索。再往后的標注就不是人給自己的圖片加標簽了而是通過設計一些標注的平臺——比較有名的是Google收購的Image Labeler——以游戲的方式對圖片進行標注。這些標注當然可以用來做圖像的搜索這就是通過人工加文本標注的方式進行圖像的搜索。
第二種通過網(wǎng)頁的文本對圖片進行索引
目前的互聯(lián)網(wǎng)通用圖片搜索引擎基本上都是基于這一套技術。通過網(wǎng)頁的文本來對圖片進行索引當然這里面也涉及到很多的細節(jié)包括怎樣從網(wǎng)頁上提取有效的文字以及2008年之后也有很多圖像分析的內容引進到基于網(wǎng)頁的圖片搜索里來。也就是說雖然圖像是網(wǎng)頁中的圖片但是也會對其進行內容分析——不管是打標簽還是特征抽取等——來改進文本搜索存在的一些缺陷提升搜索的精準性。
第三種自動標注
大量的學術論文是這個方向上的一種叫concept detection或者叫tagging。規(guī)模上小到幾十個、幾百個大到上千個、上萬個的標簽。
四、這一類嚴格來講又可細分為幾類:
Predefined categories。比如預先定好只分一千類然后就去訓練一個分類器把這個圖片標好。不限定標簽的范圍或者說標簽的范圍非常大然后去學習圖片和標簽的一個共同的描述方式從而可以實現(xiàn)近似于free text的文本標注。
Implicit tagging即隱式的自動標注。搜索引擎在運行的過程中用戶在搜索時會點擊搜索結果這個時候搜索的詞和搜索的結果就通過被點擊這個動作建立起了一個關聯(lián)這種方式也可以認為是一種標注。雖然它有一些噪聲但是實際上也是非常有效的并且也可以用一些方法降低其噪聲甚至在相似圖像之間傳遞標簽從而擴大標簽的覆蓋率。這種標注對基于網(wǎng)頁的圖像搜索引擎對搜索質量的提升起到了非常關鍵的作用。
五、圖像搜索——從火熱到?jīng)]落再到興起
最早在二十世紀九十年代時那個時候叫做CBIR(Content-Based Image Retrieval)即基于內容的圖像檢索。但是那時基本上只能在幾千、幾萬幅圖上進行檢索而且檢索的效果很難保證。當時有一個一直流行到現(xiàn)在的詞叫做“語義鴻溝”這也是當時我們經(jīng)常用來質疑基于圖像的搜索或CBIR到底靠不靠譜。
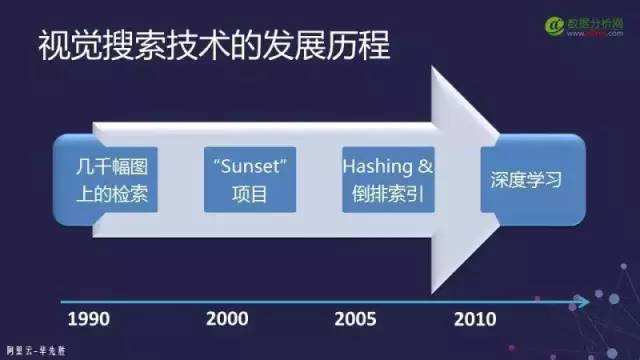
圖像搜索的沒落直到2008年左右才有所起色當時出現(xiàn)了一家叫TinEye的公司提供這樣一種網(wǎng)絡服務你提交一個圖片后它可以幫你找互聯(lián)網(wǎng)上跟此圖非常相似的圖片。當你的圖像再往大到千萬、億級甚至到十億、千億級別的時候就沒有辦法了。所以此時就要把圖片進行索引,索引在文本搜索里面是通過倒排的方法來做這個是非常容易實現(xiàn)的。但是圖像不一樣圖像的描述是它的特征而這個特征是一個向量。
那如何用高維的特征去建索引的方法:
Partition tree是用各種各樣tree的方法把數(shù)據(jù)進行分割、分塊使得查找起來比較方便。
Hashing關于圖像搜索的Paper基本上都是在做Hashing。
Neighborhood Graph用鄰接圖的方法來建索引的方法。
Invert Index把所有的圖像特征轉化成視覺詞然后用倒排的方法來做。
這幾個方法之間基本上都是可以互相轉化的當然轉化時有時是有信息損失的。如果做大規(guī)模的、數(shù)據(jù)量非常大的圖像搜索我個人認為用倒排的方法來做比較合適。
深度學習用在圖片搜索當中:
深度學習出來之后可以讓我們去按照自己所想要達到的目標去學習一個神經(jīng)網(wǎng)絡通過這個神經(jīng)網(wǎng)絡去抽取圖像的特征。實際上搜索跟識別是密不可分的尤其是在做大規(guī)模圖像搜索時識別、檢測必不可少。識別有時也是要通過搜索來完成的,例如如果你類別非常多的時候往往要通過搜索的方法來實現(xiàn)而不是通過模型的方法來做識別。所以搜索和識別在大數(shù)據(jù)時代的界限變得越來越模糊了它們之間互相需要互相利用。
六、為什么使用OpenCV+Python實現(xiàn)圖像搜索引擎呢?
首先,OpenCV是一個開源的計算機視覺處理庫,在計算機視覺、圖像處理和模式識別中有廣泛的應用。接口安全易用,而且跨平臺做的相當不錯,是一個不可多得的計算機圖像及視覺處理庫。
其次,Python的語法更加易用,貼近自然語言,極為靈活。雖然計算效率并不高,但快速開發(fā)上它遠勝于C++或其他語言,引入pysco能夠優(yōu)化python代碼中的循環(huán),一定程度上縮小與C/C++在計算上的差距。而且圖像處理中需要大量的矩陣計算,引入numpy做矩陣運算能夠降低編程的冗雜度,更多地把精力放在匹配的邏輯上,而非計算的細枝末節(jié)。
圖片搜索引擎算法及框架設計:
基本步驟
采用顏色空間特征提取器和構圖空間特征提取器提取圖像特征。
圖像索引表構建驅動程序生成待搜索圖像庫的圖像特征索引表。
圖像搜索引擎驅動程序執(zhí)行搜索命令,生成原圖圖像特征并傳入圖片搜索匹配器。
圖片搜索匹配內核執(zhí)行搜索匹配任務。返回前l(fā)imit個最佳匹配圖像。
所需模塊
numpy。科學計算和矩陣運算利器。
cv2。OpenCV的python模塊接入。
re。正則化模塊。解析csv中的圖像構圖特征和色彩特征集。
csv。高效地讀入csv文件。
glob。正則獲取文件夾中文件路徑。
argparse。設置命令行參數(shù)。
封裝類及驅動程序
顏色空間特征提取器ColorDescriptor。
類成員bins。記錄HSV色彩空間生成的色相、飽和度及明度分布直方圖的最佳bins分配。bins分配過多則可能導致程序效率低下,匹配難度和匹配要求過分苛嚴;bins分配過少則會導致匹配精度不足,不能表證圖像特征。
成員函數(shù)getHistogram(self, image, mask, isCenter)。生成圖像的色彩特征分布直方圖。image為待處理圖像,mask為圖像處理區(qū)域的掩模,isCenter判斷是否為圖像中心,從而有效地對色彩特征向量做加權處理。權重weight取5.0。采用OpenCV的calcHist()方法獲得直方圖,normalize()方法歸一化。
成員函數(shù)describe(self, image)。將圖像從BGR色彩空間轉為HSV色彩空間(此處應注意OpenCV讀入圖像的色彩空間為BGR而非RGB)。生成左上、右上、左下、右下、中心部分的掩模。中心部分掩模的形狀為橢圓形。這樣能夠有效區(qū)分中心部分和邊緣部分,從而在getHistogram()方法中對不同部位的色彩特征做加權處理。
構圖空間特征提取器StructureDescriptor。
類成員dimension。將所有圖片歸一化(降低采樣)為dimension所規(guī)定的尺寸。由此才能夠用于統(tǒng)一的匹配和構圖空間特征的生成。
成員函數(shù)describe(self, image)。將圖像從BGR色彩空間轉為HSV色彩空間(此處應注意OpenCV讀入圖像的色彩空間為BGR而非RGB)。返回HSV色彩空間的矩陣,等待在搜索引擎核心中的下一步處理。
圖片搜索匹配內核Searcher。
類成員colorIndexPath和structureIndexPath。記錄色彩空間特征索引表路徑和結構特征索引表路徑。
成員函數(shù)solveColorDistance(self, features, queryFeatures, eps = 1e-5)。求features和queryFeatures特征向量的二范數(shù)。eps是為了避免除零錯誤。
成員函數(shù)solveStructureDistance(self, structures, queryStructures, eps = 1e-5)。同樣是求特征向量的二范數(shù)。eps是為了避免除零錯誤。需作統(tǒng)一化處理,color和structure特征向量距離相對比例適中,不可過分偏頗。
成員函數(shù)searchByColor(self, queryFeatures)。使用csv模塊的reader方法讀入索引表數(shù)據(jù)。采用re的split方法解析數(shù)據(jù)格式。用字典searchResults存儲query圖像與庫中圖像的距離,鍵為圖庫內圖像名imageName,值為距離distance。
成員函數(shù)transformRawQuery(self, rawQueryStructures)。將未處理的query圖像矩陣轉為用于匹配的特征向量形式。
成員函數(shù)searchByStructure(self, rawQueryStructures)。類似4。
成員函數(shù)search(self, queryFeatures, rawQueryStructures, limit = 3)。將searchByColor方法和searchByStructure的結果匯總,獲得總匹配分值,分值越低代表綜合距離越小,匹配程度越高。返回前l(fā)imit個最佳匹配圖像。
圖像索引表構建驅動index.py。
引入color_descriptor和structure_descriptor。用于解析圖片庫圖像,獲得色彩空間特征向量和構圖空間特征向量。
用argparse設置命令行參數(shù)。參數(shù)包括圖片庫路徑、色彩空間特征索引表路徑、構圖空間特征索引表路徑。
用glob獲得圖片庫路徑。
生成索引表文本并寫入csv文件。
可采用如下命令行形式啟動驅動程序。
dataset為圖片庫路徑。color_index.csv為色彩空間特征索引表路徑。structure_index.csv為構圖空間特征索引表路徑。
圖像搜索引擎驅動searchEngine.py。
引入color_descriptor和structure_descriptor。用于解析待匹配(搜索)的圖像,獲得色彩空間特征向量和構圖空間特征向量。
用argparse設置命令行參數(shù)。參數(shù)包括圖片庫路徑、色彩空間特征索引表路徑、構圖空間特征索引表路徑、待搜索圖片路徑。
生成索引表文本并寫入csv文件。
可采用如下命令行形式啟動驅動程序。
dataset為圖片庫路徑。color_index.csv為色彩空間特征索引表路徑。structure_index.csv為構圖空間特征索引表路徑,query/pyramid.jpg為待搜索圖片路徑。

七、圖像搜索系統(tǒng)的四個基本要求
在索引建立的過程首先我們要到互聯(lián)網(wǎng)上去找到這些圖發(fā)現(xiàn)它以后還要選擇它。因為互聯(lián)網(wǎng)上的圖很多不可能把所有的圖都放在索引里面去,這時候就涉及到應該把什么圖放進去才能滿足用戶的搜索需求。這個要求是說選擇出來的圖片應該能滿足當前時間點上大部分人搜索的需求就可以了,這實際上會轉換成為一個機器學習的問題來解決。
選擇好后就要進行理解和索引要知道這個圖片里有什么內容。如果基于網(wǎng)頁就要從網(wǎng)頁上抽信息,如果是完全基于圖像就要抽取圖像的特征進行理解并建索引。建立索引以后再把這些索引推到搜索服務的機器上去,比如一個互聯(lián)網(wǎng)圖片搜索引擎這個時候可能要幾千臺機器才能hold住這個圖片庫的索引。
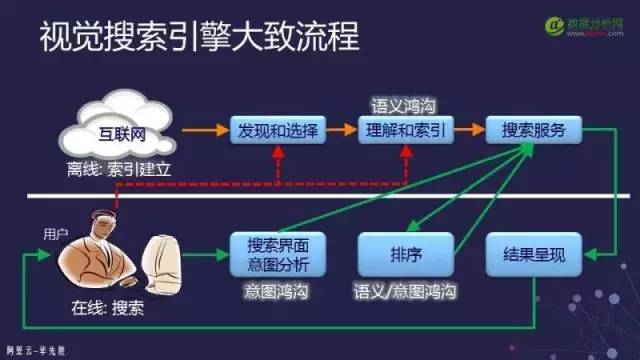
視覺搜索關鍵要求:
第一個是相關性:這是一個最基本的要求。當給了一幅圖像進去出來的東西要跟給出的圖像要是相關的。如何定義“相關”一般對于圖片搜索而言基本上是認為“跟它一樣”或者是“相像”。例如產(chǎn)品同款產(chǎn)品不管顏色是否一樣但它是相同的東西這就叫做相關性。相關性一般來說是做搜索的人最關心的一個問題;
第二個是覆蓋率:這就跟產(chǎn)品非常相關。不是我只能搜衣服不能搜其他的商品或者我只能搜商品又不能搜別的東西。否則用戶的體驗就很不好,甚至是在電商的搜索引擎里面如果用戶輸入了一個非商品我們該怎么反饋給用戶這都是涉及到覆蓋率的問題。
第三個是伸縮性:①是否能夠高效快速地處理大量的商品和商品的變化即是否能夠非常快速地將大量商品放到索引里面去而且索引能夠很方便地更新,也就是對于商品建造索引過程而言的一個伸縮性。②能否響應大量用戶的搜索請求,即當有大量的用戶同時訪問搜索服務時要能夠快速地響應所有的請求。
第四是用戶體驗:比較偏交互式用戶界面設計方面;
八、商品圖片搜索相關關鍵技術
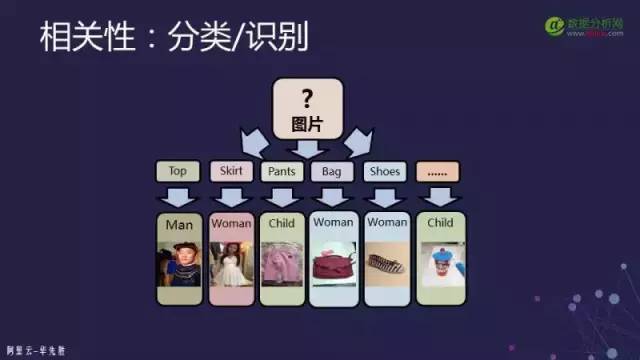
首先要知道一個圖片的大致類型。例如如果是一個商品需要知道它到底是上衣——是男士的上衣還是女士的上衣還是鞋子等。這樣來避免搜索出的結果完全不靠譜,這個我們一般把它叫做分類或識別。
主體的檢測:主體的檢測方法在計算機視覺領域也有很多快速的方法基本上是先要找Proposal Window然后對其進行分類。這個場景通常要求速度非常快一個搜索請求進來后所有的操作——包括上述分類、主體檢測以及后面的一些步驟到最終的返回結果——都是要在幾百毫秒之內返回給用戶的。因此我們的Proposal Window就不能那么多,否則計算量就相當?shù)拇螅赃@就會涉及到后續(xù)Proposal Window的refinement這樣一個步驟。
圖像特征來描述:基本方法還是是利用深度學習這個工具,force神經(jīng)網(wǎng)絡收斂到一個地方使得特征輸出能夠反映出這個商品的特性例如些種類、風格、圖案、顏色等。
覆蓋率分為三個角度來講:
索引的覆蓋率。這是我們一般提到覆蓋率時所指的含義。簡單說就是索引里多少貨商品當然是越多越好種類越全越好這個比較容易理解。
特征的覆蓋率。特征的覆蓋率是指商品的描述能夠覆蓋各個種類不是只能做鞋子或只能做服裝而不能做別的東西甚至非商品是不是能做。為了描述的精準、描述能力的優(yōu)化實際上不同的類型一般用不同的特征來描述。
搜索的覆蓋率。這個覆蓋率是電商場景下所獨有的,因為電商只有商品圖像的索引沒有別的索引;那么用戶如果輸入的不是電商產(chǎn)品的圖片該怎么辦?比如用戶在街上看到一條很可愛的狗并拍照后在平臺上搜索該怎么處理呢?這個時候我們可以把狗識別出來然后返回給用戶一些狗相關的產(chǎn)品這是一種解決方案。如果是風景、食品的話也可以對風景進行識別對食品里面的熱量進行識別然后把這些信息返回給用戶。
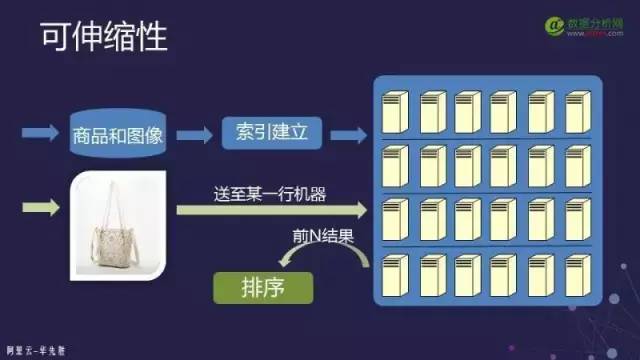
伸縮性的實現(xiàn)方式主要有兩種:
第一種是通過系統(tǒng)的方法,也就是通過大量的機器來實現(xiàn)。索引技術有了系統(tǒng)的方法來實現(xiàn)因此對索引的要求其實沒有那么高,有很多方法都可以完全滿足搜索系統(tǒng)的構建需求。正如講搜索引擎架構時所述索引會分到很多機器上去,那么只要做到每一臺機器上的數(shù)據(jù)搜索效率足夠高的話那么這個系統(tǒng)就可以完成大規(guī)模的搜索任務。
第二種是通過算法,對于算法而言就集中在一臺機器上怎么樣做到高效。
九、圖像識別技術:
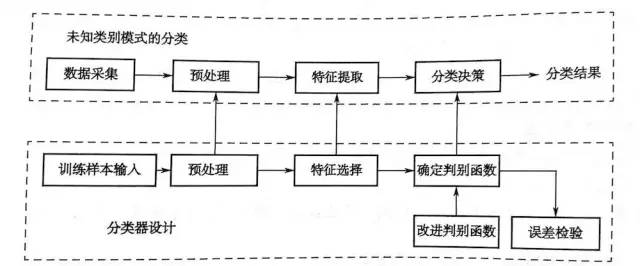
圖像識別技術是數(shù)字圖像處理和模式識別技術相結合的產(chǎn)物。數(shù)字圖象處理是利用計算機或其他數(shù)字設備對圖像信息進行各種加工和處理,以滿足目標識別需求的基礎行為。模式識別研究如何用機器來實現(xiàn)人對事物的學習、識別和判斷能力,因而是以滿足目標識別的判斷行為。
為了模擬人類圖像識別活動,人們提出了不同的圖像識別模型。例如,模版匹配模型。這種模型認為,識別圖像中的某個物體,必須在過去的經(jīng)驗中有有這個圖像對對物體的記憶模式,又叫模板,當前的刺激如果能與大腦中的模板相匹配,這個物體就被識別了。
圖像識別的基本過程是抽取代表未知樣本模式的本質表達形式(如各種特征)和預先存儲在機器中的標準模式表達形式的集合(稱為字典)逐一匹配,用一定的準則進行判別,在機器存儲的標準模式表達形式的集合中,找到最接近輸入樣本子模式的表達形式,該表達模式對應的類別就是識別結果。因此,圖像識別技術是一種從大量信息和數(shù)據(jù)出發(fā),在已有經(jīng)驗和認識的基礎上,利用計算機和數(shù)學推理的方法自動完成圖像中物體的識別和評價的過程。
圖像識別過程包括圖像采集(特征分析)、圖像預處理、特征提取、模式匹配4個環(huán)節(jié)。
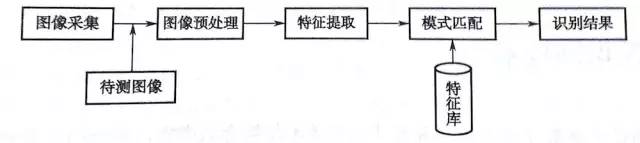
首先,通過高清攝像機、掃描儀或其他圖像采集儀器采集圖像的原始信息。傳統(tǒng)的全局特征表示方法,如顏色、形狀、紋理等特征,簡單直觀,但易受光照、裁剪、旋轉、噪聲等因素的影響,目前基本只作為輔助手段。
圖像預處理的作用可以總結為:采用某種手段將圖像信息歸一化,以便于后續(xù)處理工作。圖像特征提取部分的作用是提取出最能表征一個物體的特征信息,并將其轉變成特征向量或矩陣的形式。模式匹配是指系統(tǒng)用待測圖像的特征與特征庫中的信息進行比對,通過選擇合適的分類器達到識別的目的。

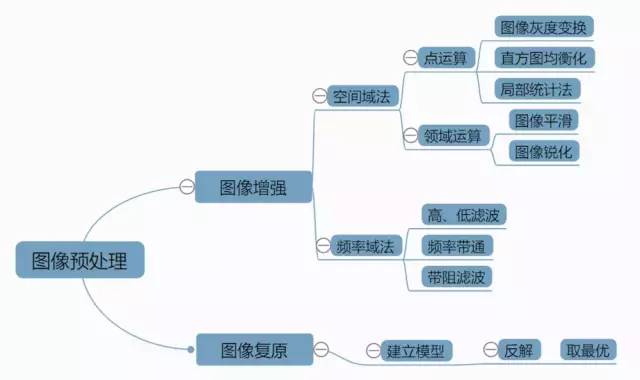
1.圖像預處理
圖像預處理技術就是對圖像進行正式處理前所做的一系列操作。圖像預處理技術分為兩大方面,即圖像增強和圖像復原技術。圖像增強技術在圖像預處理中占有較大的比重,是圖像預處理所必需的步驟,它與圖像復原技術的不同之處在于圖像復原是以恢復圖像原來的本質為目的的。
一般來說,圖像增強技術有兩種方法:空間域和頻率域法。空間域法則主要是直接在空間域內對圖像進行運算處理,分為兩個方面:點運算和領域運算(局部運算)。其中,點運算包括圖像灰度變換、直方圖均衡化和局部統(tǒng)計法等幾種方法;
領域運算包括圖像平滑和圖像銳化等幾個方面。頻率域法則只在圖像的某種變換域里對圖像的變換值進行運算,如我們對圖像進行傅立葉變換,然后在變換域里對圖像的頻譜進行某種計算,最后把計算后的圖像逆變換到空間域。頻率域法通常分為高、低通濾波、頻率帶通和帶阻濾波等。圖像復原技術就是利用圖像的先驗知識來改變一副被退化的圖像的過程。圖像復原技術需要我們建立圖像模型,然后逆向反解這個退化過程,最后獲得退化前的最優(yōu)圖像。
2.變換域處理
圖像變換域處理是以空間頻率(波數(shù))為自變量描述圖像的特征的,可以將一幅圖像元值在空間上的變化分解為具有不同振幅、空間頻率和相位的簡振函數(shù)的線性疊加,圖像中各種空間頻率成分和分布稱為空間頻譜。這種對圖像的空間頻率特征進行分解、處理和分析稱為空間頻率域處理或波數(shù)域處理。在眾多的圖像變換技術中,常用的有離散余弦變換、沃什爾變換、傅立葉變換、Gabor變換和小波變換等。
(1)離散余弦變換DCT變換矩陣的基向量由于近似于托伯利茲向量,常常被認為是對語言和圖像信號進行變換的最佳變換,雖然在壓縮效率上略遜于具有最好壓縮能力的K-L變換,但其可做到的高效處理型是K-L變換無法比擬的,并成為H.261、JPEG和MPEG等國際標準的主要環(huán)節(jié)。被廣泛應用于圖像編碼方面。
(2)沃什爾變換是一種正交變換,能將相鄰取樣點的相關性消除掉,使信號能量集中在變換矩陣的左上角,其它部分出現(xiàn)很多零值;或在誤差允許范圍內,允許省略掉小值,這樣可以達到數(shù)據(jù)壓縮的目的。沃什爾變換在圖像傳輸、雷達、通信和生物醫(yī)學等領域曾得到廣泛應用。
(3)傅立葉變換是一種常用的正交變換,其最主要的數(shù)學理論基礎就是傅立葉級數(shù),由著名數(shù)學家Fourier在1822年提出,其主要思想是將周期函數(shù)展開成正弦級數(shù)。傅立葉變換的提出奠定了圖像的理論基礎,其通過在時空域和頻率域來回切換圖像,對圖像的信息特征進行提取和分析,簡化了計算工作量,被喻為描述圖像信息的第二種語言,廣泛應用于圖像變換、圖像編碼與壓縮、圖像分割和圖像重建中。
(4)Gabor變換屬于加窗傅立葉變換,是短時Fourier變換中當窗函數(shù)取為高斯函數(shù)時的一種特殊情況。由于傅立葉變換存在一定的局限性,所以Gabor1946年提出了加窗傅立葉變換。加窗傅立葉變換方法的一個典型就是低通濾波器。Gabor 函數(shù)可以在頻域不同尺度和不同方向上提取相關特征。
(5)小波變換受到傅立葉變換的啟發(fā),Morlet于1984年提出了小波分析的概念。1986年著名數(shù)學家Meyer和Mallat合作構建了圖像小波函數(shù)的統(tǒng)一方法——多尺度分析。目前在圖像去噪應用方面,小波變換理論取得非常好的效果。
頻率域去噪主要是由于有的圖像在空間域處理的效果并不理想,因此想到轉換到頻率域進行處理,即用一組正交的函數(shù)系去逼近要處理的目標函數(shù),從而進一步得到相應級數(shù)的系數(shù)。頻率域處理主要用于與圖像空間頻率有關的處理中,如圖像恢復、圖像重建、輻射變換、邊緣增強、圖像平滑、噪聲壓制、頻譜分析和紋理分析等處理和分析中。
3.特征提取
特征提取計算機所視覺和圖像處理中的一個概念,它指的是使用計算機提取圖像信息,決定每個圖像的點是否屬于一個圖像特征。特征提取的結果是把圖像上的點分為不同的子集,這些子集往往屬于孤立的點、連續(xù)曲線或者連續(xù)的區(qū)域。
(1)特征選擇
原始數(shù)量的特征很大,或者說原始樣本處于一個高維空間中,從一組特征挑選出一些最有效的特征以達到降低特征空間維數(shù)的目的,這個過程就叫做特征選擇。也就是說,將對類別可分離性無貢獻或者貢獻不大的特征簡單地忽略掉。特征選擇是圖像識別中的一個關鍵問題。
(2)特征變換
通過映射或變換的方法可以將高維空間中的特征描述用低維空間的特征來描述,這個過程就叫做特征變換。通過特征變換獲得的特征是原始特征集的某種組合,新的特征中包含了原有全體特征的信息。主成份分析法是最常用的特征變換方法。
特征的選擇與提取是非常重要的,特征選擇是模式識別中的一個關鍵問題。由于在很多實際問題中常常不容易找到那些最重要的特征,或受條件限制不能對它們進行測量,這就使特征選擇與提取的任務復雜化而成為構造模式識別系統(tǒng)中最困難的任務之一。
特征選擇與提取的基本任務是如何從許多特征中找出那些最有效的特征。解決特征選擇與特征提取問題,最核心的內容就是如何對現(xiàn)有特征進行評估,以及如何通過現(xiàn)有特征產(chǎn)生更好的特征。常見的圖像特征提取與描述方法如顏色特征、紋理特征和幾何形狀特征提取與描述方法。
特征提取算法:
斑點特征檢測,代表性算法有:LOG(高斯拉普拉斯算子檢測)、DOH(利用圖像點的二階微分Hessian矩陣及其行列式);
角點特征檢測,代表性算法有:Harris角點檢測、Shi-Tomasi角點檢測、FAST角點檢測 等;
SIFT(尺度不變特征轉化)特征檢測,是具有劃時代意義的特征檢測算法。由于其具有非常不錯的仿射不變性,旋轉不變性,對于光線、噪點、視角變化等的容忍度也較高,在圖像搜索匹配領域應用非常廣泛,后續(xù)也出現(xiàn)了很多基于 SIFT 的改良算法。
SURF(加速魯棒特征)特征檢測,是 SIFT 的高效變種,簡化了 SIFT 特征提取的算法,運算效率更高,基本可實現(xiàn)實時處理。
ORB 特征檢測,主要在 FAST 特征點檢測算法與 BRIEF 特征描述方法的基礎上,做了一些優(yōu)化和改進,是 SIFT、SURF(兩者都受專利保護)之外一個很好的選擇。
KAZE/AKAZE(KAZE的加速版)特征檢測,比 SIFT 有著更優(yōu)異的性能和更穩(wěn)定的表現(xiàn),是繼 SIFT 之后一個較大的突破,也是目前我在系統(tǒng)中優(yōu)先采用的圖像特征提取算法。
另外,還有基于 BRISK/SBRISK(二進制魯棒尺度不變關鍵點)、FREAK(快速視網(wǎng)膜關鍵點)等算法的特征提取檢測
4.模式識別
根據(jù)有無標準樣本,模式識別可分為監(jiān)督學習和非監(jiān)督學習。模式識別分類或描述通常是基于已經(jīng)得到分類或描述的模式集合而進行的,人們稱這個模式集合為訓練集,由此產(chǎn)生的學習策略稱為監(jiān)督學習。學習也可以是非監(jiān)督學習,在此意義下產(chǎn)生的系統(tǒng)不需要提供模式類的先驗知識,而是基于模式的統(tǒng)計規(guī)律或模式的相似性學習判斷模式的類別。
(1)數(shù)據(jù)采集
數(shù)據(jù)采集是指利用各種傳感器把被研究對象的各種信息轉換為計算機可以接收的數(shù)值或符號(串)集合。習慣上稱這種數(shù)值或符號(串)所組成的空間為模式空間。這一步的關鍵是傳感器的選取。
一般獲取的數(shù)據(jù)類型如下:
物理參量和邏輯值:體溫、化驗數(shù)據(jù)、參量正常與否的描述。
一維波形:腦電圖、心電圖、季節(jié)振動波形、語音信號等。
二維圖像:文字、指紋、地圖、照片等。
(2)預處理
為了從這些數(shù)字或符號(串)中抽取出對識別有效的信息,必須進行預處理,目的是為了消除輸入數(shù)據(jù)或信息中的噪聲,排除不相干的信號,只留下與被研究對象的性質和采用的識別方法密切相關的特征(如表征物體的形狀、周長、面積等)。
舉例來說,在進行指紋識別時,指紋掃描設備每次輸出的指紋圖像會隨著圖像的對比度、亮度或背景等的不同而不同,有時可能還會產(chǎn)生變形,而人們感興趣的僅僅是圖像中的指紋線、指紋分叉點和端點等,而不需要指紋的其他部分和背景。因此,需要采用合理的濾波算法,如基于塊方圖的方向濾波和二值濾波等,過濾掉指紋圖像中這些不必要的部分。
(3)特征提取
對原始數(shù)據(jù)進行交換,從許多特征中尋找出最有效的特征,得到最能反應分類本質的特征,將維數(shù)較高的測量空間(原始數(shù)據(jù)組成的空間)轉變?yōu)榫S數(shù)較低的特征空間(分類識別賴以進行的空間),以降低后續(xù)處理過程的難度。人類很容易獲取的特征,對于機器來說就很難獲取了,這就是模式識別中的特征選擇與提取的問題。特征選擇與提取是模式識別的一個關鍵問題。
一般情況下,候選特征種類越多,得到的結果應該越好。但是,由此可能會引發(fā)維數(shù)災害,即特征維數(shù)過高,計算機難以求解。如何確定合適的特征空間是設計模式識別系統(tǒng)一個十分重要的問題。
對特征空間進行優(yōu)化有兩種基本方法:
第一種是特征選擇,如果所選用的特征空間能使同類物體分布具有緊致性,為分類器設計成功提供良好的基礎;反之,如果不同類別的樣品在該特征空間中混雜在一起,再好的設計方法也無法提高分類器的準確性;
另一種是特征的組合優(yōu)化,通過一種映射變換改造原特征空間,構造一個新的精簡的特征空間。
(4)分類決策
基于模式特征空間,就可以進行模式識別的最后一部分:分類決策。該階段最后輸出的可能是對象所屬的類型,也可能是模型數(shù)椐庫中與對象最相似的模式編號。己知若干個樣品的類別及特征,例如,手寫阿拉伯數(shù)字的判別是具有10類的分類問題,機器首先要知道每個手寫數(shù)字的形狀特征,對同一個數(shù)字,不同的人有不同的寫法,甚至同一個人對同一個數(shù)字也行多種寫法,就必須讓機器知道它屬于哪一類。因此,對分類問題需要建立樣品庫。根椐這些樣品庫建立判別分類函數(shù),這—過程是由機器來實現(xiàn)的,稱為學習過程。然后對一個未知的新對象分析它的特征,決定它屬于哪一類,這是一種監(jiān)督分類的方法。
具體步驟是建立特征空間中的訓練集,已知訓練集里每個點的所屬類別,從這些條件出發(fā),尋求某種判別函數(shù)或判別準則,設計判決函數(shù)模型,然后根據(jù)訓練集中的樣品確定模型中的參數(shù),便可將這模型用于判別,利用判別函數(shù)或判別準則去判別每個未知類別的點應該屬于哪一個類。在模式識別學科中,.一般把這個過程稱為訓練與學習的過程。
分類的規(guī)則是依據(jù)訓練樣品提供信息確定的。分類器設計在訓練過程中完成,利用一批訓練樣品,包括各種類別的樣品,由這些樣品大致勾畫出各類事物在特征空間分布的規(guī)律性,為確定使用什么樣的數(shù)學公式及這些公式中的參數(shù)提供了信息。
一般來說,決定使用什么類型的分類函數(shù)是人決定的。分類器參數(shù)的選擇或者在學習過程中得到的結果取決于設計者選擇什么樣的準則函數(shù)。不同準則函數(shù)的最優(yōu)解對應不同的學習結果,得到性能不同的分類器。數(shù)學式子中的參數(shù)則往往通過學習來確定,在學習過程中,如果發(fā)現(xiàn)當前采用的分類函數(shù)會造成分類錯誤,那么利用錯誤提供應如何糾正的信息,就可以使分類函數(shù)朝正確的方向前進,這就形成了一種迭代的過程。如果分類函數(shù)及其參數(shù)使出錯的情況越來越少,就可以說是逐漸收斂,學習過程就收到了效果,設計也就可以結束。
針對不問的應用目的,模式識別系統(tǒng)4部分的內容有很大的差異,特別楚在數(shù)據(jù)預處理和分類決策這兩部分。為了提高識別結果的可靠性,往往需要加入知識庫(規(guī)則)以對可能產(chǎn)生的錯誤進行修正,或通過引入限制條件大大縮小待識別模式在模型庫中的搜索空間,以減少匹配計算量。

都說
深度學習的興起和大數(shù)據(jù)息息相關,那么是不是數(shù)據(jù)集越大,訓練出的圖像識別算法準確率就越高呢?
過去 10 年,計算機視覺技術取得了很大的成功,其中大部分可以歸功于深度學習模型的應用。此外自 2012 年以來,這類系統(tǒng)的表現(xiàn)能力有了很大的進步,原因包括:
1)復雜度更高的深度模型;
2)計算性能的提升;
3)大規(guī)模標簽數(shù)據(jù)的出現(xiàn)。
每年,我們都能看到計算性能和模型復雜度的提升,從 2012 年 7 層的 AlexNet,發(fā)展到 2015 年 101 層的 ResNet。然而,可用數(shù)據(jù)集的規(guī)模卻沒有成比例地擴大。101 層的 ResNet 在訓練時仍然用著和 AlexNet 一樣的數(shù)據(jù)集:ImageNet 中的 10 萬張圖。過去 5 年間,GPU 計算力和模型復雜度都在持續(xù)增長,但訓練數(shù)據(jù)集的規(guī)模沒有任何變化;
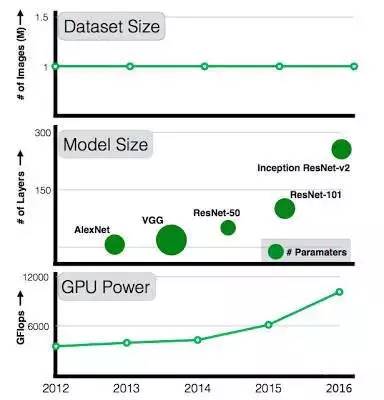
比如2017年探索“大量數(shù)據(jù)”與深度學習之間的關系:
1)使用當前的算法,如果提供越來越多帶噪聲標簽的圖片,視覺表現(xiàn)是否仍然可以得到優(yōu)化;
2)對于標準的視覺任務,例如分類、對象探測,以及圖像分割,數(shù)據(jù)和性能之間的關系是什么;
3)利用大規(guī)模學習技術,開發(fā)能勝任計算機視覺領域各類任務的最先進的模型。
當然,問題的關鍵在于要從何處找到比 ImageNet 大 300 倍的數(shù)據(jù)集。
Google 一直努力構建這樣的數(shù)據(jù)集,以優(yōu)化計算機視覺算法。在 Geoff Hinton、Francois Chollet 等人的努力下,Google 內部構建了一個包含 3 億張圖片的數(shù)據(jù)集,將其中的圖片標記為 18291 個類,并將其命名為 JFT-300M。圖片標記所用的算法混合了復雜的原始網(wǎng)絡信號,以及網(wǎng)頁和用戶反饋之間的關聯(lián)。通過這種方法,這 3 億張圖片獲得了超過 10 億個標簽(一張圖片可以有多個標簽)。在這 10 億個標簽中,約 3.75 億個通過算法被選出,使所選擇圖片的標簽精確度最大化。然而,這些標簽中依然存在噪聲:被選出圖片的標簽約有 20% 是噪聲。
最后訓練得到意料之外的結果:
更好的表征學習(Representation Learning)能帶來幫助。
大規(guī)模數(shù)據(jù)有助于表征學習,從而優(yōu)化我們所研究的所有視覺任務的性能。建立用于預訓練的大規(guī)模數(shù)據(jù)集很重要。這還說明無監(jiān)督表征學習,以及半監(jiān)督表征學習方法有良好的前景。看起來,數(shù)據(jù)規(guī)模繼續(xù)壓制了標簽中存在的噪聲。
隨著訓練數(shù)據(jù)數(shù)量級的增加,任務性能呈線性上升。視覺任務性能和表現(xiàn)學習訓練數(shù)據(jù)量(取對數(shù))之間的關系。即使訓練圖片規(guī)模達到 3 億張,也沒有觀察到性能上升出現(xiàn)停滯。
模型容量非常關鍵,如果希望完整利用 3 億張圖的數(shù)據(jù)集,就需要更大容量(更深)的模型。例如,對于 ResNet-50,COCO 對象探測得分的上升很有限,只有 1.87%,而使用 ResNet-152,這一得分上升達到 3%。此外,構建包含 300M 圖片的數(shù)據(jù)集并不是最終目標。應當探索,憑借更龐大的數(shù)據(jù)集(包含超過 10 億圖片),模型是否還能繼續(xù)優(yōu)化。
十、視覺搜索及圖像識別應用的領域:
1、電子商務結合,搜索同款或相似款的衣物、包包;
2、社交網(wǎng)絡結合,實現(xiàn)更好的圖像理解與互動;
3、自媒體結合,更方便的尋找圖像、視頻的素材;
4、知識產(chǎn)權結合,可以更準確的追溯圖像來源與版權信息;
5、醫(yī)療健康結合,可以更準確的做病理研究;
6、工業(yè)生成結合,實現(xiàn)更可靠的瑕疵物件篩選;
7、網(wǎng)絡安全結合,實現(xiàn)更好的對圖像、視頻內容的自動過濾審核;
8、安保監(jiān)控結合,可以實現(xiàn)更準確的跟蹤定位;
9、智能機器人相結合,可以實現(xiàn)更好的機器人物體識別和場景定位...
圖像搜索結合用戶使用場景,能夠在復雜背景條件下準確地識別和提取圖片中的主體信息,并使用當前人工智能領域較為先進的深度學習技術對獲取到的圖片信息進行語義分析,現(xiàn)在圖像搜索的應用范圍已經(jīng)越來越廣,例如:
1、手機拍照購物:在書店、超市、電器賣場隨手拍攝一個商品,即可查到該商品在網(wǎng)上商城的價格。移動拍照購物搜索,只需通過手機拍攝相應物品的照片就可進行購物搜索,這樣的搜索工具使網(wǎng)絡購物變得更加直觀、便捷。
2、購物網(wǎng)站相似:在具體商品頁面下部,自動列出相似款商品。讓使用者快速搜到相似的圖片,節(jié)省時間,提高效率。
3.目錄銷售:用戶在享受購物目錄翻閱的便捷和愜意過程中,用手機拍下感興趣的圖片,即刻被引導到商家的網(wǎng)站,激活線上行為。為用戶提供了方便的購買途徑。
4.手機導覽增值服務:著重為觀眾提供作品背后的信息體驗,用戶手機拍下感興趣的展品,相關的深度信息立刻在手機中顯示。
5.版權保護:通過圖像識別技術,發(fā)現(xiàn)同源圖片的整體或局部在哪些地方出現(xiàn),包括線上和線下,保護圖片所有者的版權。
十一、未來圖像搜索發(fā)展的趨勢:
圖像搜索和識別技術的未來:數(shù)據(jù)、用戶、模型、系統(tǒng),結合在一起使用;因為絕對不是某一個算法能解決的,也不是僅憑深度學習就可以解決的,更不是說一個搜索系統(tǒng)、識別系統(tǒng)就可以解決的。
審核編輯 :李倩
-
計算機視覺
+關注
關注
8文章
1698瀏覽量
45977 -
視覺圖像
+關注
關注
0文章
7瀏覽量
6877 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:計算機視覺(圖像)技術:視覺圖像搜索綜述
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
計算機視覺中的圖像融合

機器視覺和計算機視覺有什么區(qū)別
計算機視覺的五大技術
計算機視覺的工作原理和應用
計算機視覺和機器視覺區(qū)別在哪
計算機視覺和圖像處理的區(qū)別和聯(lián)系
計算機視覺在人工智能領域有哪些主要應用?
計算機視覺怎么給圖像分類
深度學習在計算機視覺領域的應用
計算機視覺的主要研究方向
計算機視覺與圖像處理、模式識別、機器學習學科之間的關系
工業(yè)視覺與計算機視覺的區(qū)別
計算機視覺:AI如何識別與理解圖像





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論