

本文介紹一種對紅細胞和白細胞圖像分類任務的主動學習端到端工作流程。
通過細胞圖像的標簽對模型性能的影響,為數據設置優先級和權重。 許多機器學習任務的主要障礙之一是缺乏標記數據。而標記數據可能會耗費很長的時間,并且很昂貴,因此很多時候嘗試使用機器學習方法來解決問題是不合理的。 為了解決這個問題,機器學習領域出現了一個叫做主動學習的領域。主動學習是機器學習中的一種方法,它提供了一個框架,根據模型已經看到的標記數據對未標記的數據樣本進行優先排序。 細胞成像的分割和分類等技術是一個快速發展的領域研究。就像在其他機器學習領域一樣,數據的標注是非常昂貴的,并且對于數據標注的質量要求也非常的高。針對這一問題,本篇文章介紹一種對紅細胞和白細胞圖像分類任務的主動學習端到端工作流程。 我們的目標是將生物學和主動學習的結合,并幫助其他人使用主動學習方法解決生物學領域中類似的和更復雜的任務。 本篇文主要由三個部分組成:
- 細胞圖像預處理——在這里將介紹如何預處理未分割的血細胞圖像。
- 使用CellProfiler提取細胞特征——展示如何從生物細胞照片圖像中提取形態學特征,以用作機器學習模型的特征。
- 使用主動學習——展示一個模擬使用主動學習和不使用主動學習的對比實驗。
細胞圖像預處理
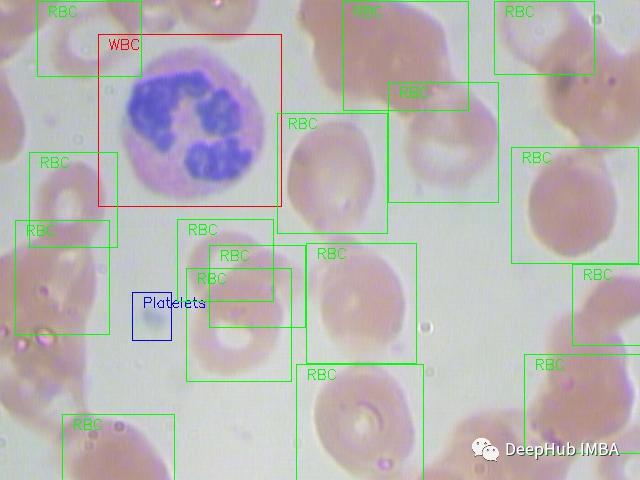
我們將使用在MIT許可的血細胞圖像數據集(GitHub和Kaggle)。每張圖片都根據紅細胞(RBC)和白細胞(WBC)分類進行標記。對于這4種白細胞(嗜酸性粒細胞、淋巴細胞、單核細胞和中性粒細胞)還有附加的標簽,但在本文的研究中沒有使用這些標簽。 下面是一個來自數據集的全尺寸原始圖像的例子:
 ?創建樣本DF
原始數據集包含一個export.py腳本,它將XML注釋解析為一個CSV表,其中包含每個細胞的文件名、細胞類型標簽和邊界框。
原始腳本沒有包含cell_id列,但我們要對單個細胞進行分類,所以我們稍微修改了代碼,添加了該列并添加了一列包括image_id和cell_id的filename列:
?創建樣本DF
原始數據集包含一個export.py腳本,它將XML注釋解析為一個CSV表,其中包含每個細胞的文件名、細胞類型標簽和邊界框。
原始腳本沒有包含cell_id列,但我們要對單個細胞進行分類,所以我們稍微修改了代碼,添加了該列并添加了一列包括image_id和cell_id的filename列:
裁剪 為了能夠處理數據,第一步是根據邊界框坐標裁剪全尺寸圖像。這就產生了很多大小不一的細胞圖像:import os, sys, randomimport xml.etree.ElementTree as ETfrom glob import globimport pandas as pdfrom shutil import copyfileannotations = glob('BCCD_Dataset/BCCD/Annotations/*.xml')df = []for file in annotations:#filename = file.split('/')[-1].split('.')[0] + '.jpg'#filename = str(cnt) + '.jpg'filename = file.split('\')[-1]filename =filename.split('.')[0] + '.jpg'row = []parsedXML = ET.parse(file)cell_id = 0for node in parsedXML.getroot().iter('object'):blood_cells = node.find('name').textxmin = int(node.find('bndbox/xmin').text)xmax = int(node.find('bndbox/xmax').text)ymin = int(node.find('bndbox/ymin').text)ymax = int(node.find('bndbox/ymax').text)row = [filename, cell_id, blood_cells, xmin, xmax, ymin, ymax]df.append(row)cell_id += 1data = pd.DataFrame(df, columns=['filename', 'cell_id', 'cell_type', 'xmin', 'xmax', 'ymin', 'ymax'])data['image_id'] = data['filename'].apply(lambda x: int(x[-7:-4]))data[['filename', 'image_id', 'cell_id', 'cell_type', 'xmin', 'xmax', 'ymin', 'ymax']].to_csv('bccd.csv', index=False)


 ?裁剪的代碼如下:
?裁剪的代碼如下:
以上就是我們所做的所有預處理操作。現在,我們繼續使用CellProfiler提取特征。import osimport pandas as pdfrom PIL import Imagedef crop_cell(row):"""crop_cell(row)given a pd.Series row of the dataframe, load row['filename'] with PIL,crop it to the box row['xmin'], row['xmax'], row['ymin'], row['ymax']save the cropped image,return cropped filename"""input_dir = 'BCCDJPEGImages'output_dir = 'BCCDcropped'# open imageim = Image.open(f"{input_dir}{row['filename']}")# size of the image in pixelswidth, height = im.size# setting the points for cropped imageleft = row['xmin']bottom = row['ymax']right = row['xmax']top = row['ymin']# cropped imageim1 = im.crop((left, top, right, bottom))cropped_fname = f"BloodImage_{row['image_id']:03d}_{row['cell_id']:02d}.jpg"# shows the image in image viewer# im1.show()# save imagetry:im1.save(f"{output_dir}{cropped_fname}")except:return 'error while saving image'return cropped_fnameif __name__ == "__main__":# load labels csv into Pandas DataFramefilepath = "BCCDdataset2-masterlabels.csv"df = pd.read_csv(filepath)# iterate through cells, crop each cell, and save cropped cell to filedataset_df['cell_filename'] = dataset_df.apply(crop_cell, axis=1)
使用CellProfiler提取細胞特征
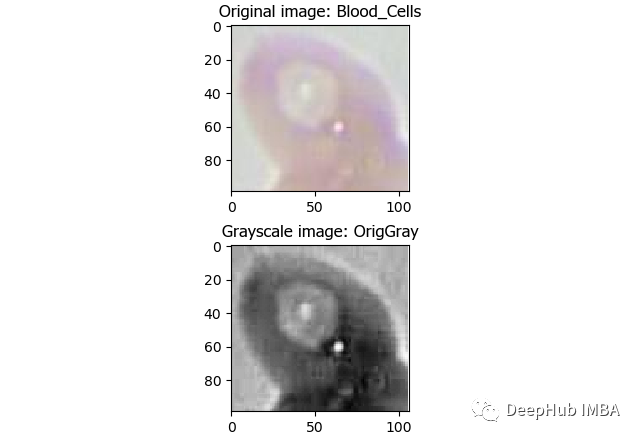
CellProfiler是一個免費的開源圖像分析軟件,可以從大規模細胞圖像中自動定量測量。CellProfiler還包含一個GUI界面,允許我們可視化的操作。 首先下載CellProfiler,如果CellProfiler無法打開,則可能需要安裝Visual C ++發布包,具體安裝方式參考官網。 打開軟件就可以加載圖像了, 如果想構建管道可以在CellProfiler官網找到其提供的可用的功能列表。大多數功能分為三個主要組:圖像處理,目標的處理和測量。常用的功能如下: 圖像處理 - 轉為灰度圖:
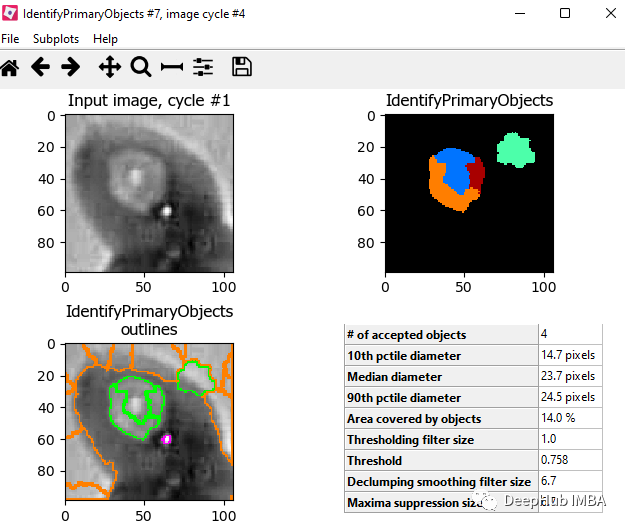
 ?目標對象處理 - 識別主要對象
?目標對象處理 - 識別主要對象
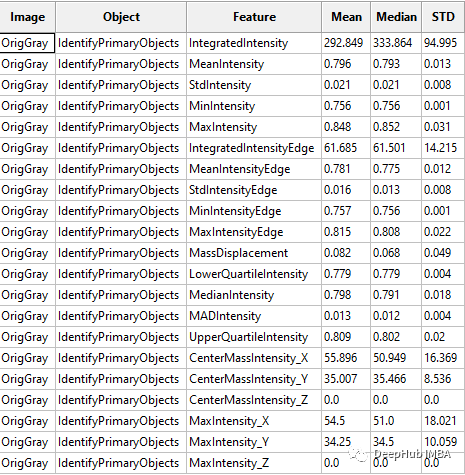
 ?測量 - 測量對象強度
?測量 - 測量對象強度
 ?CellProfiler可以將輸出為CSV文件或者保存指定數據庫中。這里我們將輸出保存為CSV文件,然后將其加載到Python進行進一步處理。
說明:CellProfiler還可以將你處理圖像的流程保存并進行分享。
?CellProfiler可以將輸出為CSV文件或者保存指定數據庫中。這里我們將輸出保存為CSV文件,然后將其加載到Python進行進一步處理。
說明:CellProfiler還可以將你處理圖像的流程保存并進行分享。主動學習
我們現在已經有了訓練需要的搜有數據,現在可以開始試驗使用主動學習策略是否可以通過更少的數據標記獲得更高的準確性。我們的假設是:使用主動學習可以通過大量減少在細胞分類任務上訓練機器學習模型所需的標記數據量來節省寶貴的時間和精力。 主動學習框架 在深入研究實驗之前,我們希望對modAL進行快速介紹:modAL是Python的活躍學習框架。它提供了Sklearn API,因此可以非常容易地將其集成到代碼中。該框架可以輕松地使用不同的主動學習策略。他們的文檔也很清晰,所以建議從它開始你的一個主動學習項目。 主動學習與隨機學習 為了驗證假設,我們將進行一項實驗,將添加新標簽數據的隨機子抽樣策略與主動學習策略進行比較。開始用一些相同的標記樣本訓練2個Logistic回歸估計器。然后將在一個模型中使用隨機策略,在第二個模型中使用主動學習策略。 我們首先為實驗準備數據,加載由Cell Profiler創建的特征。這里過濾了無色血細胞的血小板,只保留紅和白細胞(將問題簡化,并減少數據量) 。所以現在我們正在嘗試解決二進制分類問題 - RBC與WBC。使用Sklearn Label的label encoder進行編碼,并拆分數據集進行訓練和測試。
下一步就是創建模型:# imports for the whole experimentimport numpy as npfrom matplotlib import pyplot as pltfrom modAL import ActiveLearnerimport pandas as pdfrom modAL.uncertainty import uncertainty_samplingfrom sklearn import preprocessingfrom sklearn.metrics import , average_precision_scorefrom sklearn.linear_model import LogisticRegression# upload the cell profiler features for each celldata = pd.read_csv('Zaretski_Image_All.csv')# filter plateletsdata = data[data['cell_type'] != 'Platelets']# define the labeltarget = 'cell_type'label_encoder = preprocessing.LabelEncoder()y = label_encoder.fit_transform(data[target])# take the learning features onlyX = data.iloc[:, 5:]# create training and testing setsX_train, X_test, y_train, y_test = train_test_split(X.to_numpy(), y, test_size=0.33, random_state=42)
dummy_learner是使用隨機策略的模型,而active_learner是使用主動學習策略的模型。為了實例化一個主動學習模型,我們使用modAL包中的ActiveLearner對象。在“estimator”字段中,可以插入任何sklearnAPI兼容的模型。在query_strategy '字段中可以選擇特定的主動學習策略。這里使用“uncertainty_sampling()”。這方面更多的信息請查看modAL文檔。 將訓練數據分成兩組。第一個是訓練數據,我們知道它的標簽,會用它來訓練模型。第二個是驗證數據,雖然標簽也是已知的但是我們假裝不知道它的標簽,并通過模型預測的標簽和實際標簽進行比較來評估模型的性能。然后我們將訓練的數據樣本數設置成5。dummy_learner = LogisticRegression()active_learner = ActiveLearner(estimator=LogisticRegression(),query_strategy=uncertainty_sampling())
我們訓練298個epoch,在每個epoch中,將訓練這倆個模型和選擇下一個樣本,并根據每個模型的策略選擇是否將樣本加入到我們的“基礎”數據中,并在每個epoch中測試其準確性。因為分類是不平衡的,所以使用平均精度評分來衡量模型的性能。 在隨機策略中選擇下一個樣本,只需將下一個樣本添加到虛擬數據集的“新”組中,這是因為數據集已經是打亂的的,因此不需要再進行這個操作。對于主動學習,將使用名為“query”的ActiveLearner方法,該方法獲取“新”組的未標記數據,并返回他建議添加到訓練“基礎”組的樣本索引。被選擇的樣本都將從組中刪除,因此樣本只能被選擇一次。# the training size that we will start withbase_size = 5# the 'base' data that will be the training set for our modelX_train_base_dummy = X_train[:base_size]X_train_base_active = X_train[:base_size]y_train_base_dummy = y_train[:base_size]y_train_base_active = y_train[:base_size]# the 'new' data that will simulate unlabeled data that we pick a sample from and label itX_train_new_dummy = X_train[base_size:]X_train_new_active = X_train[base_size:]y_train_new_dummy = y_train[base_size:]y_train_new_active = y_train[base_size:]
結果如下:# arrays to accumulate the scores of each simulation along the epochsdummy_scores = []active_scores = []# number of desired epochsrange_epoch = 298# running the experimentfor i in range(range_epoch):# train the models on the 'base' datasetactive_learner.fit(X_train_base_active, y_train_base_active)dummy_learner.fit(X_train_base_dummy, y_train_base_dummy)# evaluate the modelsdummy_pred = dummy_learner.predict(X_test)active_pred = active_learner.predict(X_test)# accumulate the scoresdummy_scores.append(average_precision_score(dummy_pred, y_test))active_scores.append(average_precision_score(active_pred, y_test))# pick the next sample in the random strategy and randomly# add it to the 'base' dataset of the dummy learner and remove it from the 'new' datasetX_train_base_dummy = np.append(X_train_base_dummy, [X_train_new_dummy[0, :]], axis=0)y_train_base_dummy = np.concatenate([y_train_base_dummy, np.array([y_train_new_dummy[0]])], axis=0)X_train_new_dummy = X_train_new_dummy[1:]y_train_new_dummy = y_train_new_dummy[1:]# pick next sample in the active strategyquery_idx, query_sample = active_learner.query(X_train_new_active)# add the index to the 'base' dataset of the active learner and remove it from the 'new' datasetX_train_base_active = np.append(X_train_base_active, X_train_new_active[query_idx], axis=0)y_train_base_active = np.concatenate([y_train_base_active, y_train_new_active[query_idx]], axis=0)X_train_new_active = np.concatenate([X_train_new_active[:query_idx[0]], X_train_new_active[query_idx[0] + 1:]], axis=0)y_train_new_active = np.concatenate([y_train_new_active[:query_idx[0]], y_train_new_active[query_idx[0] + 1:]], axis=0)
plt.plot(list(range(range_epoch)), active_scores, label='Active Learning')plt.plot(list(range(range_epoch)), dummy_scores, label='Dummy')plt.xlabel('number of added samples')plt.ylabel('average precision score')plt.legend(loc='lower right')plt.savefig("models robustness vs dummy.png", bbox_inches='tight')plt.show()
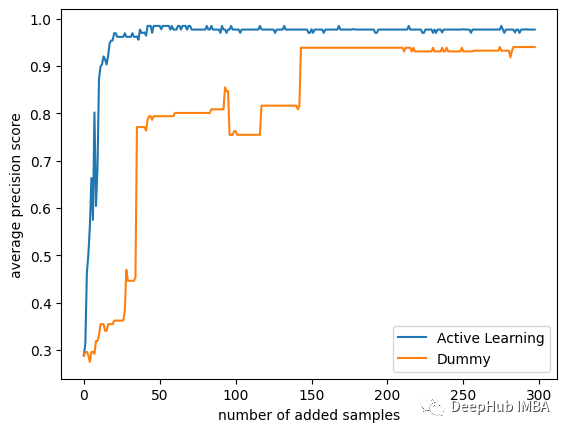 ?策略之間的差異還是很大的,可以看到主動學習只使用25個樣本就可以達到平均精度0.9得分!而使用隨機的策略則需要175個樣本才能達到相同的精度!
此外主動學習策略的模型的分數接近0.99,而隨機模型的分數在0.95左右停止了!如果我們使用所有數據,那么它們最終分數是相同的,但是我們的研究目的是在少量標注數據的前提下訓練,所以只使用了數據集中的300個隨機樣本。
?策略之間的差異還是很大的,可以看到主動學習只使用25個樣本就可以達到平均精度0.9得分!而使用隨機的策略則需要175個樣本才能達到相同的精度!
此外主動學習策略的模型的分數接近0.99,而隨機模型的分數在0.95左右停止了!如果我們使用所有數據,那么它們最終分數是相同的,但是我們的研究目的是在少量標注數據的前提下訓練,所以只使用了數據集中的300個隨機樣本。
總結
本文展示了將主動學習用于細胞成像任務的好處。主動學習是機器學習中的一組方法,可根據其標簽對模型性能的影響來優先考慮未標記的數據示例的解決方案。由于標記數據是一項涉及許多資源(金錢和時間)的任務,因此判斷那些標記那些樣本可以最大程度地提高模型的性能是非常必要的。 細胞成像為生物學,醫學和藥理學領域做出了巨大貢獻。以前分析細胞圖像需要有價值的專業人力資本,但是像主動學習這種技術的出現為醫學領域這種需要大量人力標注數據集的領域提供了一個非常好的解決方案。 本文引用:
-
GitHub — Shenggan/BCCD_Dataset: BCCD (Blood Cell Count and Detection) Dataset is a small-scale dataset for blood cells detection.
-
Blood Cell Images | Kaggle
-
Active Learning in Machine Learning | by Ana Solaguren-Beascoa, PhD | Towards Data Science
-
Carpenter, A. E., Jones, T. R., Lamprecht, M. R., Clarke, C., Kang, I. H., Friman, O., … & Sabatini, D. M. (2006).
-
CellProfiler: image analysis software for identifying and quantifying cell phenotypes. Genome biology, 7(10), 1–11.
-
Stirling, D. R., Swain-Bowden, M. J., Lucas, A. M., Carpenter, A. E., Cimini, B. A., & Goodman, A. (2021).
審核編輯 :李倩
-
圖像分類
+關注
關注
0文章
96瀏覽量
12123 -
機器學習
+關注
關注
66文章
8498瀏覽量
134265 -
預處理
+關注
關注
0文章
33瀏覽量
10625
原文標題:?細胞圖像數據的主動學習
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
一文帶你厘清自動駕駛端到端架構差異
太赫茲細胞能量儀主控芯片方案單片機開發控制板布局規劃
NX CAD軟件:數字化工作流程解決方案(CAD工作流程)

Aigtek高電壓放大器微流控細胞篩選測試
應用于活細胞成像的一次性細胞培養芯片

安泰功率放大器+溶血換能器在生物醫療領域中的具體應用

主動學習在圖像分類技術中的應用:當前狀態與未來展望

活細胞的“聚光燈”——前沿活細胞成像的案例分享


ATG-2000系列功率信號源在介電電泳細胞分選測試中的應用







 工商網監
工商網監

評論