 改進企業IT欺詐預防
改進企業IT欺詐預防
任何商業或行業,從零售、醫療保健到金融服務,都會受到欺詐的影響。欺詐的成本可能是驚人的。欺詐損失每 1 美元 減輕金融公司約 4 美元的成本 。 2018 年至 2023 年間,在線賣家將 網上支付欺詐損失 1300 億美元 。
通過使用 AI 和大數據分析,企業可以實時有效地防止欺詐企圖。
這篇文章討論了需要考慮的基礎設施因素,例如性能、硬件和用于實施欺詐預防策略的人工智能軟件的類型。
交易前和交易后欺詐檢測
在討論欺詐檢測之前,讓我們先明確預防和檢測之間的區別。欺詐預防描述了管理和消除欺詐的總體努力。欺詐檢測只是識別欺詐活動的能力。
欺詐檢測有兩種方法,這兩種方法都是綜合欺詐預防戰略所必需的。
Pre-transaction detection: 在交易完成之前檢測并阻止試圖欺詐的交易。當在事務之前檢測到異常數據或行為時,事務被阻止。
Post-transaction detection: 根據數據分析或交易后輸入,在交易完成后識別欺詐交易。然后是損害緩解。
理想的方法是在未遂欺詐發生之前檢測并阻止其發生。當交易后發現欺詐時,唯一的辦法是評估損害,通知相關方,并努力從欺詐損害中恢復。
盡管欺詐永遠無法完全消除,但在制定欺詐風險管理計劃時,交易前和交易后的欺詐工作都很重要。
開發有效反欺詐解決方案的最佳企業 IT 實踐
如果欺詐預防像速溶早餐麥片一樣簡單,你只需加熱水攪拌即可。有效預防欺詐只需要一個標準服務器和軟件。對的不完全是這樣。
防欺詐軟件顯然至關重要,但僅選擇任何硬件和軟件組合并不能確保成功。盡管欺詐預防“解決方案”在企業中廣泛存在,但欺詐仍在不斷增加,在這一過程中造成了財務損失。
企業 IT 必須確保多個基礎架構元素到位:
人工智能驅動軟件:由于傳統的靜態智能不如人工智能的動態智能有效,因此存在人工智能驅動的欺詐解決方案的趨勢。為了防止復雜的欺詐企圖,軟件必須學習。因此,人工智能必須處于核心地位。
加速性能 :實時人工智能驅動的欺詐檢測需要盡可能高的性能。延遲會影響客戶體驗。通過性能,可以實時評估更多欺詐因素,從而實現更準確的欺詐檢測。
可用性和規模 :需要一個高可用的擴展架構來支持 24-7 天的數據接收和預防。
如果沒有這三個組成部分,效率會降低,這可能會給企業和客戶帶來更大的欺詐損失。
人工智能驅動的軟件
人工智能驅動的軟件已經在企業中普及。通過人工智能訓練的欺詐預防模型,可以基于模型訓練迭代評估和調整檢測真實欺詐的準確性。培訓后,預防解決方案作為推斷應用程序運行,以評估和阻止潛在的欺詐交易。然后,來自應用程序的數據反饋到模型,以進行重新訓練,提高準確性和效率。然后使用連續重新訓練的模型更新生產應用程序等。
隨著 機器學習 ( ML )和 深度學習( DL )越來越多地應用于不斷增長的數據集,隨著原始數據準備用于訓練,在數據預處理和特征工程中, Apache Spark 已變得流行。它還用作分析工作負載的數據執行引擎。 GPU 以加速深度學習和人工智能工作負載的方式并行和加速數據處理查詢。 RAPIDS 通常用于 GPU 加速基礎架構中的 accelerate Spark 以及 ML / DL 框架。
此外,像 NVIDIA Morpheus 這樣的人工智能框架可以在無監督的情況下運行,以標記異常活動并增強欺詐預防工作。基于人工智能的欺詐預防是動態的,可以自動適應威脅。
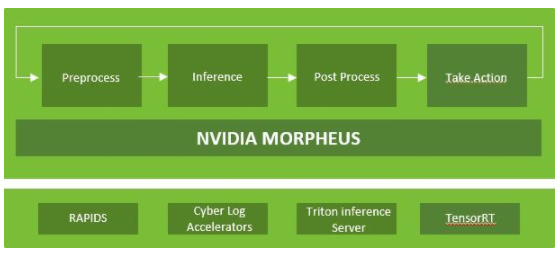
圖 1 NVIDIA Morpheus 驅動框架示例
加速性能
是的,需要速度,尤其是交易前欺詐檢測。
交易前檢測
如果沒有硬件加速,由于欺詐預防軟件分析每筆交易,執行交易的客戶可能會因無法接受的延遲而感到不便。處理速度慢會影響客戶滿意度,商家實現的收入更少。標準 CPU 足以預防遺留欺詐,但已不再適用。
由企業級 GPU 支持的基于人工智能的現代解決方案在速度和準確性上可以更有效。高性能 GPU 加速可以在給定的時間范圍內評估更多的風險因素。或者,可以在更短的時間內評估相同數量的風險因素。
交易后檢測
交易后欺詐檢測不受實時約束。盡管如此, GPU 加速可以帶來好處。更快的處理能力允許在給定的時間段內評估更多的數據。
與交易前結果一樣,交易后結果可用于更新前后處理模型,以改善未來結果(推斷)。
其他性能注意事項
IT 部門可能僅僅根據事務速度錯誤地評估服務器性能要求。然而,初始模型訓練和基于來自推理應用程序的輸入反饋數據的重新訓練也需要高性能。
如果沒有 GPU 加速,初始訓練可能需要數小時或數天,再訓練的時間可能長得令人無法接受。結果時間不僅僅是 GPU 時鐘頻率。一些 GPU 未被認證為企業級,并且缺乏大量 GPU 內存或足夠數量的內核來提供快速訓練結果。
是的,大型欺詐預防模型的培訓可以在云中以性能和規模執行。不幸的是,經過多次訓練迭代后,云處理周期可能會很昂貴。
幸運的是,可以使用代表性數據子集或較低分辨率精度參數,在企業 GPU 加速的工作站上以迭代方式經濟高效地在本地執行模型訓練。這使得在數據科學工作站或支持 GPU 的服務器的資本支出之后,初步模型培訓的成本基本上是免費的。
經過初步培訓后,可以在大型數據集上以更高的效率在云端或企業服務器或服務器集群中執行全面培訓。
可用性和規模
欺詐者從不睡覺,因此企業欺詐預防也無法休息。事務應用程序不間斷運行,因此防欺詐軟件也必須這樣做。企業 IT 基礎設施必須為預防解決方案提供彈性和可用性。正如我所指出的,性能很重要,但當它不總是可用時,它否定了任何性能優勢。
正如我之前所討論的,欺詐和相關損害每年都在增加。預防解決方案必須無縫擴展以適應這種情況。
可用性和可擴展性要求不能局限于服務器。例如,網絡可能滿足所需吞吐量和延遲的規范,但事實是突發網絡流量可能會導致足夠的網絡擁塞,從而導致欺詐檢測被跳過、無法接受的延遲或超時。因此,在構建高級反欺詐解決方案時,不能忽視網絡的魯棒性和冗余性。
為欺詐解決方案構建 AI 友好的基礎設施
隨著時間的推移,您的人工智能驅動的解決方案能否獲得成功所需的性能、可用性和規模?假設基于人工智能的防欺詐軟件正確,它還必須確保正確的基礎設施。正如我前面所討論的,這意味著隨著防欺詐數據和工作負載的增加,基礎設施可以加速性能、不間斷運行,以及無縫擴展基礎設施投資的靈活性。
提供支持欺詐預防和人工智能驅動的企業解決方案的企業級 IT 基礎設施也是一項挑戰。正確的產品組合解決了企業欺詐預防的性能、可用性和擴展需求,同時支持其他人工智能框架和工具。從用于模型開發的移動和桌面工作站,到用于數據中心推理和大規模培訓的服務器和軟件。
關于作者
André Franklin 是 NVIDIA 數據科學營銷團隊的一員,專注于 NVIDIA 支持的工作站和服務器的基礎設施解決方案。他在多個企業解決方案方面擁有豐富的經驗,包括 NetApp 、 Hewlett-Packard enterprise 和具有預測分析功能的靈活存儲陣列。安德烈居住在加利福尼亞州北部,以駕駛無線電控制的模型飛機、滑冰和拍攝大自然遠足而聞名。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4984瀏覽量
103017 -
服務器
+關注
關注
12文章
9139瀏覽量
85377 -
人工智能
+關注
關注
1791文章
47234瀏覽量
238351
發布評論請先 登錄
相關推薦
潤和軟件出席中華預防醫學會環境衛生分會2024年學術會議
TPM在工業機器人故障預防中的五大策略
變壓器預防性試驗項目及意義
ADVANCE.AI:頭號公敵!合成身份偽造盛行,金融科技企業如何應對挑戰
NVIDIA加速計算和 AI助力數字銀行揭穿金融欺詐騙局
紅色警戒!深度偽造欺詐蔓延全球,ADVANCE.AI助力出海企業反欺詐新升級
蘋果聲明App Store成功阻止70億美元欺詐交易
淺談電氣火災的分析和預防








 工商網監
工商網監
評論