

MLPerf benchmarks 由工業(yè)界、學(xué)術(shù)界和研究實(shí)驗(yàn)室的人工智能領(lǐng)導(dǎo)者組成的聯(lián)盟開發(fā),旨在提供標(biāo)準(zhǔn)、公平和有用的深度學(xué)習(xí)性能測(cè)量。 MLPerf 訓(xùn)練側(cè)重于測(cè)量時(shí)間,以便為以下任務(wù)訓(xùn)練一系列常用的神經(jīng)網(wǎng)絡(luò):
自然語(yǔ)言處理
推薦系統(tǒng)
生物醫(yī)學(xué)圖像分割
目標(biāo)檢測(cè)
圖像分類
強(qiáng)化學(xué)習(xí)
減少培訓(xùn)時(shí)間對(duì)于加快部署時(shí)間、最小化總體擁有成本和最大化投資回報(bào)至關(guān)重要。
然而,與平臺(tái)性能一樣重要的是它的多功能性。訓(xùn)練每個(gè)模型的能力,以及提供基礎(chǔ)設(shè)施可替代性以運(yùn)行從訓(xùn)練到推理的所有人工智能工作負(fù)載的能力,對(duì)于使組織能夠最大限度地實(shí)現(xiàn)其基礎(chǔ)設(shè)施投資的回報(bào)至關(guān)重要。
NVIDIA platform 具有全堆棧創(chuàng)新和豐富的開發(fā)人員和應(yīng)用程序生態(tài)系統(tǒng),仍然是唯一提交所有八個(gè) MLPerf 訓(xùn)練測(cè)試結(jié)果,以及提交所有 MLPerf 推理和 MLPerf 高性能計(jì)算( HPC )測(cè)試結(jié)果的系統(tǒng)。
在本文中,您將了解 NVIDIA 在整個(gè)堆棧中部署的方法,以在 MLPerf v2.0 中提供更高的性能。
全堆棧改進(jìn)
NVIDIA MLPerf v2.0 提交基于經(jīng)驗(yàn)證的 A100 Tensor Core GPU 、 NVIDIA DGX A100 系統(tǒng) 以及 NVIDIA DGX SuperPOD 參考架構(gòu)。許多合作伙伴還使用 A100 Tensor Core GPU 提交了結(jié)果。
通過整個(gè)堆棧(包括系統(tǒng)軟件、庫(kù)和算法)的持續(xù)創(chuàng)新,與之前使用相同 A100 Tensor Core GPU 提交的文件相比, NVIDIA 再次實(shí)現(xiàn)了性能改進(jìn)。
與 NVIDIA MLPerf v0.7 提交的第一批 A100 Tensor Core GPU 提交相比,結(jié)果表明,每個(gè)芯片的增益高達(dá) 2.1 倍,最大規(guī)模訓(xùn)練的增益為 5.7 倍(表 1 )。
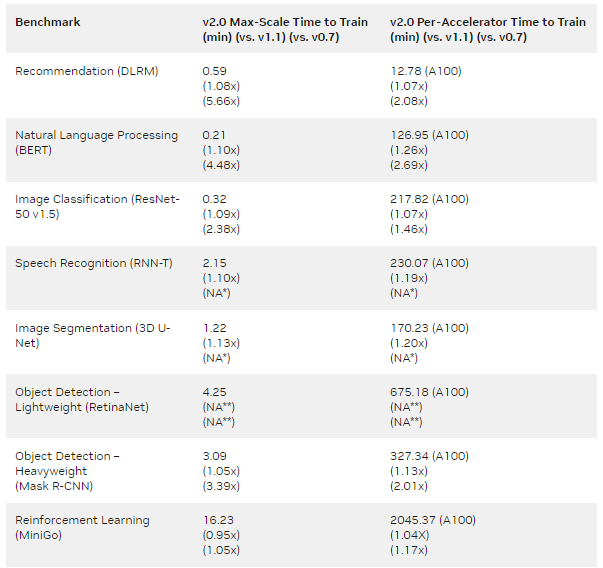
MLPERF v1.1 Submission details :
每加速器: BERT : 1.1-2066 | DLRM:1.1-2064 |掩碼 R-CNN:1.1-2066 | Resnet50 v1.5:1.1-2065 | RNN-T:1.1-2066 | 3D U-Net:1.1-2065 | MiniGo:1.1-2067
最大比例: BERT : 1.1-2083 | DLRM:1.1-2073 | Mask R-CNN:1.1-2076 | Resnet50 v1.5:1.1-2082 | SSD:1.1-2070 | RNN-T:1.1-2080 | 3D U-Net:1.1-2077 | MiniGo:1.1-2081 (*)
MLPERF v2.0 Submission details :
每加速器: BERT : 2.0-2070 | DLRM:2.0-2068 | Mask R-CNN:2.0-2070 | Resnet50 v1.5:2.0-2069 | RetinaNet:2.0-2091 | RNN-T:2.0-2066 | 3D U-Net:2.0-2060 | MiniGo:2.0-2059
最大比例: BERT : 2.0-2106 | DLRM:2.0-2098 | Mask R-CNN:2.0-2099 | Resnet50 v1.5:2.0-2107 | RetinaNet:2.0-2103 | RNN-T:2.0-2104 | 3D U-Net:2.0-2100 | MiniGo:2.0-2105
使用 8xA100 服務(wù)器訓(xùn)練時(shí)間并將其乘以 8 計(jì)算出 A100 的每加速器性能。 3D U-Net 和 RNN-T 不是 MLPerf v0.7 的一部分。(**)RetinaNet 不是 MLPerf v0.7 或 v1.1 的一部分。 MLPerf 名稱和徽標(biāo)是商標(biāo)。
以下各節(jié)重點(diǎn)介紹了為實(shí)現(xiàn)這些改進(jìn)所做的一些工作。
BERT
最新的 NVIDIA BERT 提交利用了以下優(yōu)化:
順序包裝
全連接層和 GELU 層的融合
順序包裝
在前幾輪中,填充批次所需的填充相關(guān)開銷已經(jīng)通過引入未添加優(yōu)化進(jìn)行了優(yōu)化。然而,取消添加會(huì)導(dǎo)致緩沖區(qū)大小動(dòng)態(tài)變化,因?yàn)榱钆瓶倲?shù)不再固定。
當(dāng)我們不必使用 CUDA 圖時(shí),例如當(dāng)使用大批量時(shí),這不是一個(gè)問題。然而,對(duì)于小批量,其中 CUDA 圖用于減少 CPU 開銷,動(dòng)態(tài)大小的緩沖區(qū)需要針對(duì)每個(gè)可能的大小使用許多單獨(dú)的圖。為了有效利用 CUDA 圖,同時(shí)最小化填充開銷, NVIDIA 在這一輪中使用了序列打包的概念。
在來自 Transformers ( BERT )的 MLPerf 雙向編碼器表示中,訓(xùn)練樣本被限制為 512 個(gè)令牌,但其令牌通常少于 512 個(gè)。由于訓(xùn)練序列具有不同的長(zhǎng)度,因此可以在 512 個(gè)令牌樣本中擬合多個(gè)序列。
序列壓縮要求預(yù)先知道訓(xùn)練集序列的長(zhǎng)度分布。序列可以合并到壓縮樣本中,這樣合并的樣本中沒有一個(gè)超過 512 個(gè)令牌的長(zhǎng)度。
NVIDIA 使用了與另一個(gè)提交者 用于 MLPerf v1.1 類似的打包算法。 GPU 具有高度的通用編程能力,因此可以采用來自不同提交方的算法。
為了在實(shí)現(xiàn)復(fù)雜性和性能之間取得良好的平衡,每個(gè)樣本中最多包含三個(gè)序列。這導(dǎo)致每個(gè)訓(xùn)練樣本包含不同數(shù)量的序列,因?yàn)橐慌齻€(gè)樣本可以包含三到九個(gè)序列。
CUDA 圖要求每個(gè)圖的緩沖區(qū)大小隨時(shí)間固定。通過為批次中每個(gè)可能的序列數(shù)創(chuàng)建一個(gè)單獨(dú)的圖來處理不同數(shù)量的總序列。
對(duì)于大規(guī)模訓(xùn)練,我們使用每個(gè)芯片兩個(gè)批次的大小。這轉(zhuǎn)化為五到七個(gè)單獨(dú)的圖,這遠(yuǎn)低于開始提到的未添加優(yōu)化所需的數(shù)量。
總的來說,對(duì)于 4096- GPU 和 1024- GPU 場(chǎng)景,該技術(shù)分別將大規(guī)模運(yùn)行的結(jié)果提高了 10% 和 33% 。
全連接層和 GELU 層的融合
BERT 使用高斯誤差線性單元( GELU )激活函數(shù),該函數(shù)遵循完全連接層。在之前提交的文件中, GELU 激活函數(shù)是作為單個(gè)內(nèi)核實(shí)現(xiàn)的。這種方法需要額外的內(nèi)存事務(wù)來進(jìn)行輸入讀取和輸出寫入。
在這一輪中, NVIDIA 實(shí)現(xiàn)了完全連接層(矩陣乘法操作)與 GELU 激活函數(shù)的融合。這消除了對(duì)大量?jī)?nèi)存讀寫操作的需要,使總吞吐量增加了 2-4% ——每芯片批量越大,收益越大。
通常,將激活數(shù)學(xué)融合到矩陣乘法運(yùn)算的末尾更有效,這意味著將 GELU 激活函數(shù)融合到不同的完全連接層中(圖 1 )。
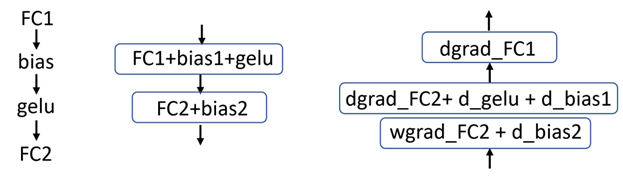
圖 1 左:在 BERT 中的操作模式,中:前向傳遞中的融合圖,右:后向傳遞中的融合圖。每個(gè)框代表一個(gè)內(nèi)核。
深度學(xué)習(xí)推薦模型
最新的 NVIDIA 深度學(xué)習(xí)推薦模型( DLRM )提交再次利用了 NVIDIA Merlin HugeCTR ,一個(gè)用于推薦系統(tǒng)的優(yōu)化開源深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練框架。
內(nèi)核融合
多層感知器( MLP )是 DLRM 的關(guān)鍵構(gòu)建塊。為了減少全局內(nèi)存的訪問次數(shù),元素核和通用矩陣乘法( GEMM )核的融合得到了廣泛應(yīng)用。
這個(gè) NVIDIA cuBLAS 庫(kù) 最近引入了一種新的融合類型: GEMM 和 DReLU (將 ReLU 梯度計(jì)算與反向過程中的矩陣乘法運(yùn)算融合)。 HugeCTR 利用這種新的融合類型來提高 MLP 的性能。
改進(jìn)了計(jì)算和通信的重疊
提高 GPU 利用率對(duì)于提供最高性能非常重要。
在最新提交的文件中, NVIDIA 顯著改善了混合嵌入評(píng)估中計(jì)算和通信的重疊,以提高 GPU 利用率。具體來說,迭代 i 中密集網(wǎng)絡(luò)的執(zhí)行通過流水線與迭代 i + 1 中嵌入的執(zhí)行重疊,增加了 GPU 的利用率。
這種重疊是可能的,因?yàn)樵谠u(píng)估階段沒有迭代之間的依賴關(guān)系。
此外,還優(yōu)化了混合嵌入的前向/后向分層all-to-all操作中的幾個(gè)關(guān)鍵內(nèi)核。
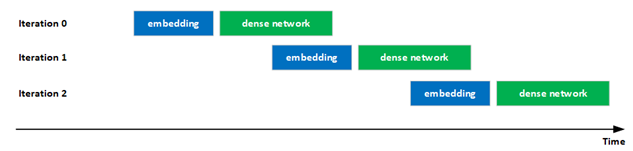
圖 2 :嵌入和密集網(wǎng)絡(luò)的重疊執(zhí)行
ResNet-50
對(duì)于 ResNet-50 ,我們采用了以下優(yōu)化來提高性能:
更好的最大規(guī)模訓(xùn)練配置
更快的 cuDNN 內(nèi)核
更好的最大規(guī)模訓(xùn)練配置
當(dāng)對(duì)模型進(jìn)行大規(guī)模訓(xùn)練時(shí),如果全局批量大小不是數(shù)據(jù)集中訓(xùn)練圖像的整數(shù)倍,則會(huì)在歷元的最后一次迭代中添加額外數(shù)據(jù),以使批量大小在迭代中保持一致。如果全局批大小接近數(shù)據(jù)集的整數(shù)倍,則可以避免浪費(fèi)的計(jì)算。這對(duì)于大規(guī)模訓(xùn)練尤其重要,因?yàn)槿峙肯鄬?duì)較大。
在這一輪 MLPerf 中,我們得出結(jié)論,使用 527 個(gè)節(jié)點(diǎn),全局批量大小為 67456 ,顯著減少了浪費(fèi)的計(jì)算,與 MLPerf v1.1 中 NVIDIA 提交的 ResNet-50 相比,性能提升了 3.5% 。
更快的 cuDNN 內(nèi)核
對(duì)于提交的 ResNet50 , NVIDIA 顯著改進(jìn)了 cuDNN 提取的內(nèi)核。這包括針對(duì)層大小選擇更好的內(nèi)核,以及針對(duì)不同分片大小優(yōu)化內(nèi)核實(shí)現(xiàn)。
從這些優(yōu)化的內(nèi)核采樣中,我們觀察到 MLPerf v1.1 的大規(guī)模配置的吞吐量提高了 4% 以上。
RetinaNet
NVIDIA RetinaNet 提交利用了幾種軟件優(yōu)化,包括:
通道最后存儲(chǔ)格式和自動(dòng)混合精度
使用融合加速
優(yōu)化損耗塊
異步評(píng)分
CUDA 圖
通道最后存儲(chǔ)格式和自動(dòng)混合精度
為了避免內(nèi)存重組并有效提高峰值性能, NVIDIA 使用了 PyTorch 通道最后內(nèi)存格式 ( NHWC 而非 NCHW )和 PyTorch 自動(dòng)混合精度 (AMP)。
使用融合加速
對(duì)于 RetinaNet 提交, NVIDIA took 利用了幾個(gè)融合機(jī)會(huì)。通過 Apex 庫(kù)的 cuDNN 運(yùn)行時(shí)融合用于融合 CONV-bias-ReLU 和 CONV-bias-pattern ,而 PyTorch NVFuser 用于融合元素操作,例如 scale-bias-ReLU 和 scale-bias-add-ReLU 。
cuDNN 運(yùn)行時(shí)融合 Python 接口可以在 Apex repository (從apex.contrib.conv_bias_relu導(dǎo)入 ConvBiasReLU 或 ConvBias )中找到。
優(yōu)化損耗塊
RetinaNet 損耗相關(guān)計(jì)算分為兩個(gè)階段:地面實(shí)況數(shù)據(jù)預(yù)處理和實(shí)際損耗計(jì)算。
由于地面實(shí)況數(shù)據(jù)預(yù)處理不依賴于模型輸出,部分地面實(shí)況數(shù)據(jù)處理通過 custom functions 卸載到 DALI ,使其能夠異步執(zhí)行,提高了系統(tǒng)資源利用率。預(yù)處理的其余部分被重新實(shí)現(xiàn),然后合并到模型圖中以避免抖動(dòng)。
對(duì)于損耗計(jì)算,使用了優(yōu)化的焦損實(shí)現(xiàn),可在 Apex library 中找到。
異步評(píng)分
RetinaNet 提交指南要求在每個(gè)訓(xùn)練期后進(jìn)行評(píng)估(推斷和評(píng)分)。由于 OpenImages 驗(yàn)證數(shù)據(jù)集中有大量圖像和邊界框,以及評(píng)分代碼的順序?qū)崿F(xiàn),評(píng)分時(shí)間開銷很大。
為了減輕評(píng)分開銷,特別是在大規(guī)模執(zhí)行中,實(shí)現(xiàn)了異步評(píng)分,以便下一個(gè)訓(xùn)練歷元掩蓋了前一個(gè)歷元評(píng)分過程。

圖 3 在評(píng)估中執(zhí)行異步 COCO 評(píng)分
CUDA 圖
CUDA 圖 在 NVIDIA RetinaNet 提交中廣泛使用。繪制了整個(gè)模型和地面實(shí)況預(yù)處理的部分,這需要重新實(shí)現(xiàn)它們以適應(yīng) CUDA 圖約束。
該模型的正向和反向過程被圖形捕捉,以及地面實(shí)況預(yù)處理的部分。后者需要代碼自適應(yīng)以適應(yīng) CUDA 圖約束。
有關(guān)更多信息,請(qǐng)參閱 用 CUDA 圖加速 PyTorch 。
掩碼 R-CNN
NVIDIA Mask R-CNN 提交使用了幾種技術(shù)來提高性能:
瓶頸塊優(yōu)化
RPN 頭部融合
評(píng)價(jià)
Top-K
瓶頸塊優(yōu)化
resnet主干構(gòu)建為瓶頸塊堆棧,每個(gè)瓶頸塊由三個(gè)連續(xù)卷積組成。每個(gè)卷積后面跟著一個(gè)批范數(shù)和一個(gè) ReLu 。批范數(shù)模塊有四個(gè)參數(shù),在正向方法中計(jì)算兩個(gè)中間項(xiàng)需要一些數(shù)學(xué)知識(shí)。
由于批量規(guī)范被凍結(jié),參數(shù)永遠(yuǎn)不會(huì)更改,這意味著中間項(xiàng)也不會(huì)更改。為了節(jié)省時(shí)間,這些中間項(xiàng)只計(jì)算了一次。
ReLu 的反向傳播涉及創(chuàng)建和應(yīng)用掩碼。在早期版本的代碼中,該掩碼以半( FP16 )精度存儲(chǔ)。在這一輪中, DReLU 掩碼表示為布爾值,而不是 FP16 ,以減少內(nèi)存事務(wù)。
在反向傳播過程中,為三個(gè)卷積層中的每一層計(jì)算數(shù)據(jù)梯度和權(quán)重梯度。 NVIDIA 根據(jù)經(jīng)驗(yàn)發(fā)現(xiàn),雖然數(shù)據(jù)梯度 GPU 內(nèi)核使用足夠數(shù)量的 CTA 來啟動(dòng),以充分利用 GPU ,但權(quán)重梯度內(nèi)核使用的 CTA 要少得多。
實(shí)現(xiàn)的一個(gè)優(yōu)化是首先啟動(dòng)數(shù)據(jù)梯度核,然后在單獨(dú)的流上啟動(dòng)所有三個(gè)權(quán)重梯度核,以便它們同時(shí)運(yùn)行。這減少了權(quán)重梯度的總計(jì)算時(shí)間。
Apex 中的 瓶頸塊模塊 中的 PyTorch 用戶可以使用這些優(yōu)化。
RPN 頭部融合
如 RetinaNet 一節(jié)所述,實(shí)現(xiàn)了一個(gè)新的 Apex 模塊,該模塊融合了卷積、偏置和 ReLu 。該模塊位于 MaskR CNN 中,用于融合 RPN 頭塊中某些層的正向傳播。
評(píng)價(jià)
平均而言,評(píng)估所需的時(shí)間幾乎與培訓(xùn)所需的時(shí)間相同。評(píng)估在專用節(jié)點(diǎn)上異步完成,但結(jié)果通過阻塞廣播與訓(xùn)練節(jié)點(diǎn)共享。
訓(xùn)練節(jié)點(diǎn)在開始等待評(píng)估廣播之前等待一定數(shù)量的步驟,以最小化任何評(píng)估結(jié)果等待時(shí)間。學(xué)習(xí)率曲線有兩個(gè)拐點(diǎn),模型在通過最后一個(gè)拐點(diǎn)之前收斂的可能性極小。這就是為什么你應(yīng)該等待盡可能長(zhǎng)的時(shí)間來檢查評(píng)估結(jié)果,直到訓(xùn)練通過最后一個(gè)學(xué)習(xí)率曲線拐點(diǎn)。
Top-K
在 PyTorch 的早期版本中, top-k 內(nèi)核啟動(dòng)的 CTA 數(shù)量與每 GPU 批大小成比例。當(dāng)批量大小等于 1 時(shí),這產(chǎn)生了較差的性能,該批量大小通常用于 NVIDIA max scale 運(yùn)行。
在前幾輪中,我們使用兩階段 top-k 方法解決了這個(gè)問題,該方法是用 Python 實(shí)現(xiàn)的,但該解決方案并沒有得到很好的推廣。關(guān)于更普遍解決方案的工作已經(jīng)在進(jìn)行中。
在這一輪中, NVIDIA 與 PyTorch 團(tuán)隊(duì)合作,以確保新的 top-k 實(shí)現(xiàn)在批量為 1 的情況下產(chǎn)生更好的性能,并進(jìn)入 PyTorch 。完成后,以前的兩階段 top-k 實(shí)現(xiàn)被新的 PyTorch 模塊所取代。
3D U-Net
3D U-Net 具有多個(gè)大層,輸入通道數(shù)為 32 。對(duì)于wgrad內(nèi)核,使用默認(rèn)為 64x256x64 的內(nèi)核意味著顯著的塊大小量化損失。
由于在 cuDNN 中引入了新的 32x256x32 wgrad內(nèi)核,從而節(jié)省了分片大小量化損失。這導(dǎo)致 MLPerf v2.0 中單個(gè)節(jié)點(diǎn)的加速比 MLPerf v1.1 高出 5% 以上。
RNN-T
遞歸神經(jīng)網(wǎng)絡(luò)傳感器( RNN-T )的預(yù)處理步驟相對(duì)密集。多虧了 DALI ,大部分預(yù)處理開銷可以通過管道傳輸并隱藏在主訓(xùn)練循環(huán)下。
然而,由于輸入數(shù)據(jù)的大小可能不同,因此需要在初始迭代后重新定位內(nèi)部?jī)?nèi)存緩沖區(qū),從而增加預(yù)熱階段的長(zhǎng)度。
DALI 最近已切換到基于內(nèi)存池的分配器,其中池使用cuMem API 進(jìn)行管理。這顯著減少了分配新緩沖區(qū)的開銷,在訓(xùn)練中產(chǎn)生了更快的預(yù)熱過程。
結(jié)論
多虧了整個(gè)堆棧的優(yōu)化, NVIDIA 平臺(tái)再次能夠使用經(jīng)驗(yàn)證的 NVIDIA A100 Tensor Core GPU 和 NVIDIA DGX A100 平臺(tái)提高 MLPerf Training v2.0 的性能。
NVIDIA 仍然是在 MLPerf 基準(zhǔn)測(cè)試套件中提交結(jié)果的唯一平臺(tái),包括 MLPerf 培訓(xùn)、 MLPerf 推理和 MLPerf HPC 。這展示了整個(gè)平臺(tái)的性能和多功能性,隨著現(xiàn)代人工智能在每個(gè)計(jì)算領(lǐng)域的普及,這一點(diǎn)至關(guān)重要。
除了在 MLPerf 存儲(chǔ)庫(kù)中提供用于 NVIDIA MLPerf 提交的軟件外,還為 NVIDIA GPU 、 在 NGC hub 上可用 制作并優(yōu)化了數(shù)十個(gè)其他模型。
NVIDIA 平臺(tái)也無處不在,為客戶提供了運(yùn)行模型的選擇。 NVIDIA A100 可從所有主要服務(wù)器制造商和云服務(wù)提供商處獲得,允許您在本地、云中、混合環(huán)境或邊緣部署。
關(guān)于作者
Ashraf Eassa 是NVIDIA 加速計(jì)算集團(tuán)內(nèi)部的高級(jí)產(chǎn)品營(yíng)銷經(jīng)理。
Sukru Burc Eryilmaz 是 NVIDIA 計(jì)算機(jī)體系結(jié)構(gòu)的高級(jí)架構(gòu)師,他致力于在單節(jié)點(diǎn)和超級(jí)計(jì)算機(jī)規(guī)模上改進(jìn)神經(jīng)網(wǎng)絡(luò)訓(xùn)練的端到端性能。他從斯坦福大學(xué)獲得博士學(xué)位,并從比爾肯特大學(xué)獲得學(xué)士學(xué)位。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5196瀏覽量
105529 -
gpu
+關(guān)注
關(guān)注
28文章
4889瀏覽量
130464 -
人工智能
+關(guān)注
關(guān)注
1804文章
48503瀏覽量
245277
發(fā)布評(píng)論請(qǐng)先 登錄
hyper-v 配置,Hyper-V配置:性能優(yōu)化與高級(jí)設(shè)置
新品| GPS V2.0,高性能GNSS全球定位模塊

解鎖NVIDIA TensorRT-LLM的卓越性能
ANAPF有源電力濾波器單頁(yè)說明書 V2.0
ANSVG-G-A混合動(dòng)態(tài)濾波補(bǔ)償裝置使用說明書 V2.0
NVIDIA AI助力初創(chuàng)企業(yè)為心理治療師提供AI工具
從TMS320TCI648x DSP的EDMA v2.0遷移到EDMA v3.0

從EDMA v2.0遷移到TMS320DM644X DMSoC的EDMA v3.0
從EDMA v2.0遷移到EDMA v3.0 TMS320C64X DSP
阿童木二代Atom XL數(shù)字模擬對(duì)講手機(jī)用戶手冊(cè)V2.0
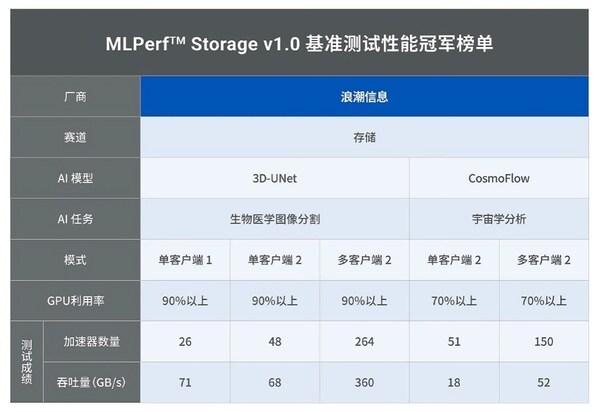
浪潮信息AS13000G7榮獲MLPerf? AI存儲(chǔ)基準(zhǔn)測(cè)試五項(xiàng)性能全球第一
堆棧和內(nèi)存的基本知識(shí)
如何使用Polyspace Code Prover來統(tǒng)計(jì)堆棧
NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業(yè)軟件支持
NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業(yè)軟件支持,實(shí)現(xiàn)邊緣實(shí)時(shí)醫(yī)療、工業(yè)和科學(xué) AI 應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論