 使用加速WEKA加速機器學習模型
使用加速WEKA加速機器學習模型
近年來,建筑業和采用機器學習( ML )工具。使用 GPU 加速計算日益密集的模型已成為一個突出的趨勢。
為了增加用戶訪問,加速 WEKA 項目通過集成開源 RAPIDS 庫,為在知名的 WEKA 算法中使用 GPU 提供了一個可訪問的入口點。
在這篇文章中,我們將向您介紹加速 WEKA ,并學習如何使用 WEKA 軟件利用圖形用戶界面( GUI )的 GPU 加速算法。這種 Java 開源替代方案適合于從不同環境或包中尋找各種 ML 算法的初學者。
什么是加速 WEKA ?
加速 WEKA 將WEKA軟件(一種著名的開源 Java 軟件)與利用 GPU 縮短 ML 算法執行時間的新技術相結合。針對沒有系統配置和編碼專業知識的用戶,它有兩個好處:易于安裝和指導 ML 任務的配置和執行的 GUI 。
加速 WEKA 是一個可用于 WEKA 的軟件包集合,它可以擴展以支持新的工具和算法。
什么是急流?
RAPIDS是一組開源 Python 庫,供用戶在 NVIDIA GPU 上開發和部署數據科學工作負載。流行的庫包括用于 GPU 加速數據幀處理的 cuDF 和用于 GPU 加速機器學習算法的 cuML 。 RAPIDS API 盡可能符合 CPU 對應項,例如 pandas 和scikit-learn。
%1 : %2 加速的 WEKA 架構
加速 WEKA 的構建塊是WekaDeeplearning4j和wekaRAPIDS(受wekaPython啟發)等包。 WekaDeeplearning4j ( WDL4J )已經支持 GPU 處理,但在庫和環境配置方面有非常特殊的需求。 WDL4J 為 Deeplearning4j 庫提供了 WEKA 包裝。
對于 Python 用戶, weka Python 最初通過創建服務器并通過套接字與之通信來提供 Python 集成。有了它,用戶可以在 WEKA 工作臺內執行 scikit learn ML 算法(甚至XGBoost)。此外, weka RAPIDS 通過在 wekaPython 中使用相同的技術提供與 RAPIDS cuML 庫的集成。
總之,這兩個包在用戶友好的 WEKA 工作臺內提供了增強的功能和性能。加速 WEKA 通過改進 JVM 和 Python 解釋器之間的通信,在性能方面更進一步。它通過使用 Apache Arrow 和 GPU 內存共享等替代方法來實現這兩種語言之間的高效數據傳輸。
加速 WEKA 還提供了與 RAPIDS cuML 庫的集成,該庫實現了在 NVIDIA GPU 上加速的機器學習算法。一些 cuML 算法甚至可以支持多 GPU 解。
支持的算法
加速 WEKA 目前支持的算法有:
線性回歸
物流回歸
山脊
套索
彈性網
MBSGD 分類器
多項式 nb
伯努林
高斯 B
隨機森林分類器
隨機森林采伐
靜止無功補償器
SVR 公司
LinearSVC
Kneighbors 回歸器
Kneighbors 分類器
多 GPU 模式下加速 WEKA 支持的算法有:
Kneighbors 回歸器
Kneighbors 分類器
線性回歸
山脊
套索
彈性網
多項式 nb
光盤
使用加速 WEKA GUI
在加速 WEKA 設計階段,一個主要目標是使其易于使用。以下步驟概述了如何在系統上進行設置,并提供了一個簡單的示例。
有關更多信息和全面入門,請參閱文檔。加速 WEKA 的唯一先決條件是在系統中安裝Conda。
加速 WEKA 的安裝可通過提供包和環境管理的系統 Conda 獲得。這種能力意味著一個簡單的命令可以安裝項目的所有依賴項。例如,在 Linux 機器上,在終端中發出以下命令以安裝加速 WEKA 和所有依賴項。
conda create-n accelweka-c rapidsai-c NVIDIA -c conda forge-c waikato weka
Conda 創建環境后,使用以下命令將其激活:
激活時
這個終端實例剛剛加載了加速 WEKA 的所有依賴項。使用以下命令啟動 WEKA GUI 選擇器:
韋卡
圖 1 顯示了 WEKA GUI 選擇器窗口。從那里,單擊 Explorer 按鈕訪問 Accelerated WEKA 的功能。
圖 1 。 WEKA GUI 選擇器窗口。這是啟動 WEKA 時出現的第一個窗口
在 WEKA Explorer 窗口(圖 2 )中,單擊 Open file 按鈕以選擇數據集文件。 WEKA 使用 ARFF 文件,但可以從 CSV 中讀取。根據屬性的類型,從 CSV 轉換可能非常簡單,或者需要用戶進行一些配置。
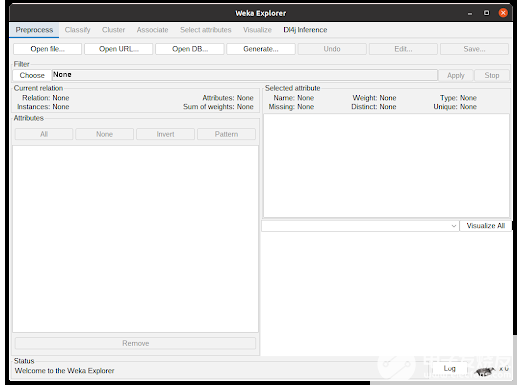
圖 2 :在 WEKA Explorer 窗口中,用戶可以導入數據集,檢查有關屬性的統計信息,并在預處理時對數據集應用過濾器
加載了數據集的 WEKA Explorer 窗口如圖 3 所示。假設不想預處理數據,單擊“分類”選項卡將向用戶顯示分類選項。
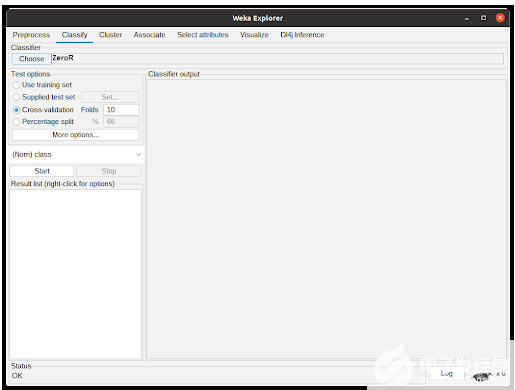
圖 3 。加載數據集的 WEKA Explorer 窗口。加載數據集(從 ARFF 文件或 CSV 文件)后,屬性名稱顯示在左側。有關選定屬性的信息顯示在右上角。在右下角可以看到一個圖表,其中包含根據所選屬性的類分布
分類選項卡如圖 4 所示。單擊“選擇”按鈕將顯示已實現的分類器。由于數據集的特性,有些可能被禁用。要使用加速 WEKA ,用戶必須選擇急流。積云分類器。之后,單擊粗體 CuMLClassifier 將使用戶轉到分類器的選項窗口。
圖 4 。在 WEKA 分類選項卡中,用戶可以配置分類算法和測試選項,這些選項將在使用之前選擇的數據集的實驗中使用
圖 5 顯示了 CuMLClassifier 的選項窗口。使用字段 RAPIDS 學習器,用戶可以在軟件包支持的分類器中選擇所需的分類器。現場學習者參數用于修改 cuML 參數,其詳細信息可在cuML documentation中找到。
其他選項用于用戶微調屬性轉換,配置要使用的 Python 環境,并確定算法應操作的小數位數。為了學習本教程,請選擇隨機林分類器,并將所有內容保留為默認配置。單擊“確定”將關閉窗口并返回到上一個選項卡。
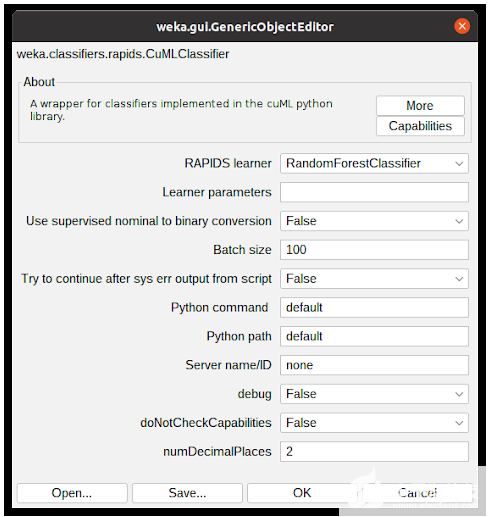
圖 5 。通過 WEKA 分類器配置窗口,用戶可以配置所選分類器的參數。在這種情況下,它顯示了新集成的 CuMLClassifier 選項和所選的 RandomForestClassifier 學習器
根據上一步配置分類器后,參數將顯示在選擇按鈕旁邊的文本字段中。單擊開始后, WEKA 將開始使用數據集執行所選分類器。
圖 6 顯示了分類器的作用。分類器輸出顯示有關實驗的調試和一般信息,例如參數、分類器、數據集和測試選項。狀態顯示執行的當前狀態,底部的 Weka 鳥在實驗運行時從一側動畫并翻轉到另一側。
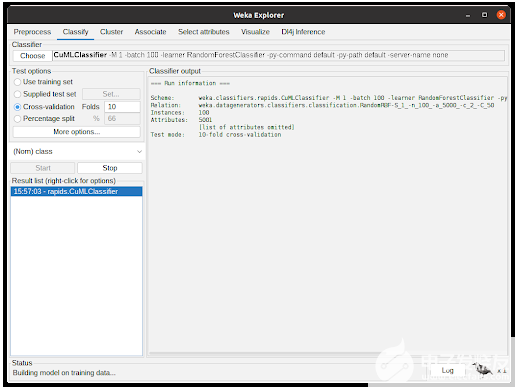
圖 6 。 WEKA 分類選項卡,所選分類算法正在進行中
算法完成任務后,將輸出執行摘要,其中包含有關預測性能和所用時間的信息。在圖 7 中,輸出顯示了使用從 cuML 到 CuMLClassifier 的 RandomForestClassifier 進行 10 倍交叉驗證的結果。
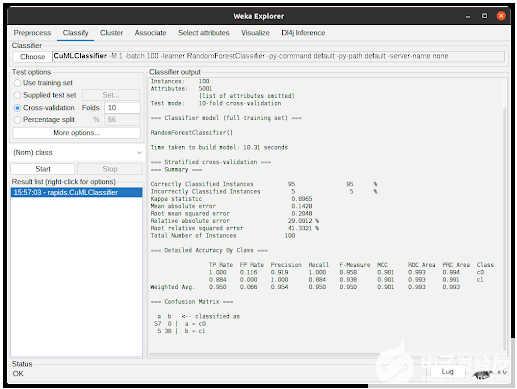
圖 7 。實驗完成后的 WEKA 分類選項卡
基準測試加速 WEKA
我們評估了加速 WEKA 的性能,比較了算法在 CPU 上的執行時間和使用加速 WEKA 的執行時間。實驗中使用的硬件是 i7-6700K 、 GTX 1080Ti 和具有四個 A100 GPU 的 DGX 站。除非另有說明,否則基準測試使用單個 GPU 。
我們使用具有不同特征的數據集作為基準。其中一些是合成的,用于更好地控制屬性和實例,如 RDG 和 RBF 生成器。 RDG 生成器基于決策列表構建實例。默認配置有 10 個屬性, 2 個類,最小規則大小為 1 ,最大規則大小為 10 。我們將最小值和最大值分別更改為 5 和 20 。使用該生成器,我們創建了具有 1 、 2 、 5 和 1000 萬個實例的數據集,以及具有 20 個屬性的 500 萬個實例。
RBF 生成器為每個類創建一組隨機中心,然后通過獲取屬性值中心的隨機偏移來生成實例。屬性的數量用后綴 a _ uu 表示(例如, a5k 表示 5000 個屬性),實例的數量用后綴 n _ u 表示(例如, n10k 表示 10000 個實例)。
最后,我們使用了HIGGS 數據集,其中包含有關原子加速器運動學特性的數據。希格斯數據集的前 500 萬個實例用于創建希格斯粒子。
顯示了 weka RAPIDS 積分的結果,其中我們直接比較了基線 CPU 執行和加速 weka 執行。 WDL4J 的結果如表 5 所示。
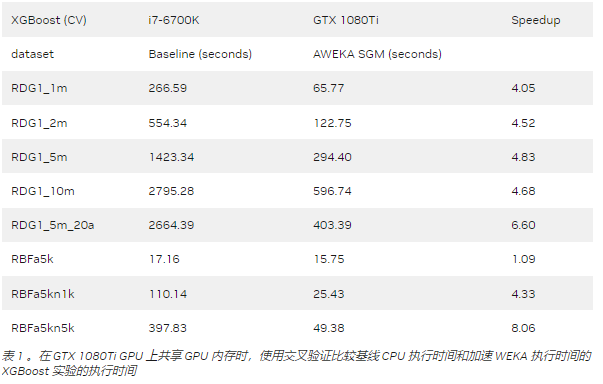
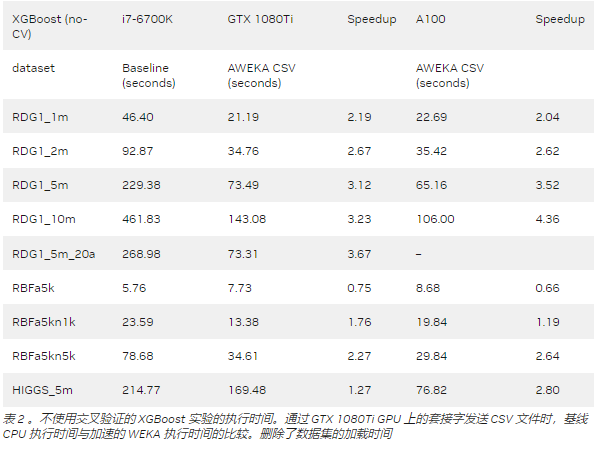
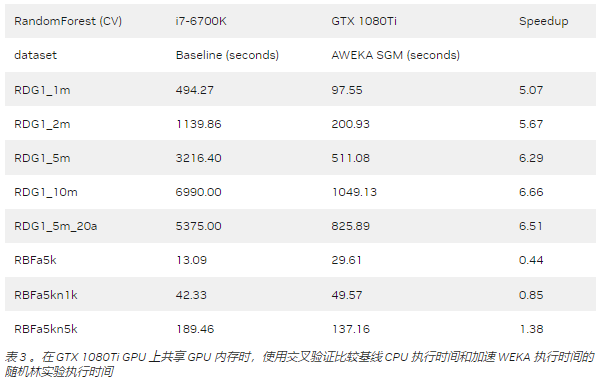
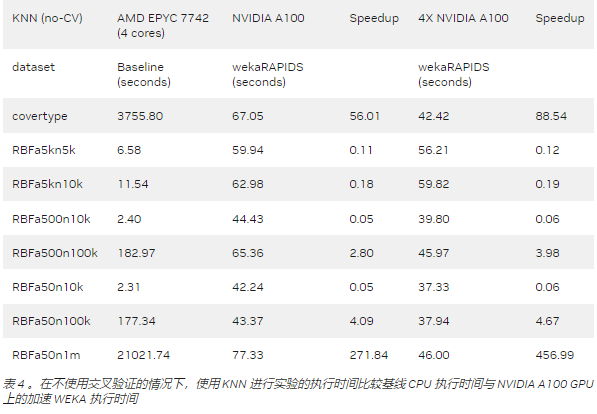
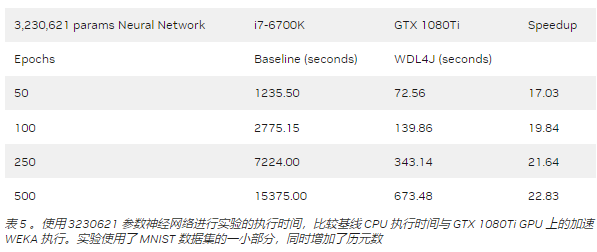
該基準測試表明,加速 WEKA 為具有較大數據集的計算密集型任務提供了最大的好處。像 RBFa5k 和 RBFa5kn1k 這樣的小數據集(分別擁有 100 個和 1000 個實例)呈現出糟糕的加速,這是因為數據集太小,無法使將內容移動到 GPU 內存的開銷值得。
這種行為在 A100 (表 4 )實驗中很明顯,其中架構更為復雜。使用它的好處開始在 100000 個實例或更大的數據集上發揮作用。例如,具有 100000 個實例的 RBF 數據集顯示了約 3 倍和 4 倍的加速,這仍然不太明顯,但顯示出了改進。更大的數據集,如 covertype 數據集(約 700000 個實例)或 RBFa50n1m 數據集( 100 萬個實例),分別顯示了 56X 和 271X 的加速。請注意,對于深度學習任務,即使使用 GTX 1080Ti ,加速也可以達到 20 倍以上。
關鍵要點(與行動要求掛鉤)
加速 WEKA 將幫助您使用激流為 WEKA 增壓。加速 WEKA 有助于 RAPIDS 的高效算法實現,并具有易于使用的 GUI 。使用 Conda 環境簡化了安裝過程,從一開始就可以直接使用加速 WEKA 。
如果您使用 AcceleratedWEKA ,請在社交媒體上使用標簽“ AcceleratedWEKA ”。此外,請參閱 文檔 以獲取在學術工作中引用加速 WEKA 的正確出版物,并了解有關該項目的更多詳細信息。
加速 WEKA
WEKA 在 GPL 開源許可證 下免費提供,因此加速了 WEKA 。事實上, Accelerated WEKA 是通過 Conda 提供的,用于自動安裝環境所需的工具,對源代碼的添加將發布到 WEKA 的主包中。
關于作者
Albert Bifet 是特議會聯盟特馬哈拉艾研究所所長。他是一位計算機科學家,主要興趣領域是數據流及其應用的人工智能/機器學習。他是 MOA 機器學習軟件的核心開發者,擁有 150 多篇關于機器學習方法及其應用的出版物。
Guilherme Weigert Cassales 自 2021 以來一直是人工智能研究所的博士后研究員,同年他在圣卡洛斯聯邦大學( UFSCar )獲得了計算機科學博士學位。他的研究興趣包括數據流的機器學習、分布式系統和高性能計算。
自 2021 以來,Justin Liu 一直是人工智能研究所的研究程序員。他在該行業有十多年的軟件開發經驗。他的興趣包括機器學習、大規模數據處理和 ML 操作。
審核編輯:郭婷
-
cpu
+關注
關注
68文章
10873瀏覽量
212107 -
加速器
+關注
關注
2文章
801瀏覽量
37926 -
gpu
+關注
關注
28文章
4747瀏覽量
129020 -
機器學習
+關注
關注
66文章
8423瀏覽量
132752
發布評論請先 登錄
相關推薦
PyTorch GPU 加速訓練模型方法
GPU加速計算平臺是什么
NVIDIA 加速人形機器人發展

LLM大模型推理加速的關鍵技術
如何加速大語言模型推理

NVIDIA在加速識因智能AI大模型落地應用方面的重要作用介紹
NVIDIA Isaac機器人平臺升級,加速AI機器人技術革新
家居智能化,推動AI加速器的發展







 工商網監
工商網監
評論