 三篇基于遷移學習的論元關系提取
三篇基于遷移學習的論元關系提取
引言
隨著越來越多的機器學習應用場景的出現,而現有表現比較好的監督學習需要大量的標注數據,標注數據是一項枯燥無味且花費巨大的任務,所以遷移學習受到越來越多的關注。本次論文分享介紹了三篇基于遷移學習的論元關系提取。
數據概覽
基于遷移學習和主動學習的論元關系提取(Efficient Argument Structure Extraction with Transfer Learning and Active Learning)
論文地址:https://arxiv.org/pdf/2204.00707
該篇文章針對提取論元關系提出了基于Transformer的上下文感知論元關系預測模型,該模型在五個不同的領域中顯著優于依賴特征或僅編碼有限上下文的模型。為了解決數據標注的困難,作者通過遷移學習利用現有的注釋好的數據來提高新目標域中的模型性能,以及通過主動學習來識別少量樣本進行注釋。
一個用于集成論辯挖掘任務的大規模數據集(IAM: A Comprehensive and Large-Scale Dataset for Integrated Argument Mining Tasks)
論文地址:https://arxiv.org/pdf/2203.12257
該篇文章為了使論辯中繁瑣的過程自動化,提出了一個大規模數據集IAM,該數據集可用于一系列論辯挖掘任務,包括主張提取、立場分類、證據提取等。之后進一步提出了與論辯準備過程相關的兩個新的論辯挖掘任務:(1)基于立場分類的主張提取,(2)主張-證據對提取。對每個集成任務分別采用流水線方法和端到端方法進行試驗。
社會討論中的無監督知識遷移有助于論辯挖掘嗎?(Can Unsupervised Knowledge Transfer from Social Discussions Help Argument Mining?)
論文地址:https://arxiv.org/pdf/2203.12881
雖然基于Transformer的預訓練語言模型可以在許多NLP任務中取得最好的結果,但是標注數據的缺乏和論證高度依賴領域的本質限制了此類模型的性能。文章提出了一種遷移學習的策略來解決,利用CMV做為數據集,微調選擇性掩碼語言模型,并且提出了基于prompt的策略來預測論元間的關系。
論文細節

論文動機
識別論元結構在論辯挖掘領域里是一項非常重要的任務。從正式文本,例如法律文件、科學文獻到線上帖子,識別論元結構在識別各個領域的中心論點和推理過程方面發揮著重要作用。對于給定一個命題,該文章需要在給定文本窗口中從其他命題中預測與該命題之間的關系(支持或者反對)。但是一個巨大的挑戰是需要捕捉命題之間的長期依賴關系。下圖展示了識別論元關系的一個例子,該例子為同行評審和在線評論中的論點摘錄。右邊表示論元結構被標記為命題之間的支持關系。盡管文本之間的主題或詞匯存在差異,但我們看到兩篇文本都具有相似結構的長期依賴關系,表明識別論元之間的關系可能會跨度很大,因此需要理解更長的上下文。

由于現有的方法需要高質量的標注數據、為了解決長期依賴從而人工設計的自定義特征以及模型訓練,導致時間復雜度非常高。因此文章的主要目標是設計一個方便研究者在新領域的文本中更快更精確地提取出論元關系模型。文章首先提出了一種上下文感知的論元關系預測模型,該模型可以通過微調Transformer獲得。對于給定的命題,模型對該命題的更多相鄰的命題進行編碼,不僅僅是編碼緊挨的命題。此外,由于標注論元結構即使是對于有經驗的標注人員來說依然很困難,所以文章第二個目標是通過少量的數據來有效的訓練模型。文章提出了兩種互補的方法:(1)遷移學習可以調整在不同域中現有注釋數據上訓練的模型,或利用未標記的域內數據來進行更好的表示學習。(2)主動學習基于樣本獲取策略選擇新域中的樣本,以優化訓練性能。
論元關系預測模型
任務定義
將一篇文本切分為多個命題來預測命題到命題是否存在支持或反對關系,其中目標命題稱為“頭部”,命題稱為“尾部”,為了方便起見,文章給出了“頭部”的先驗知識。
上下文感知模型
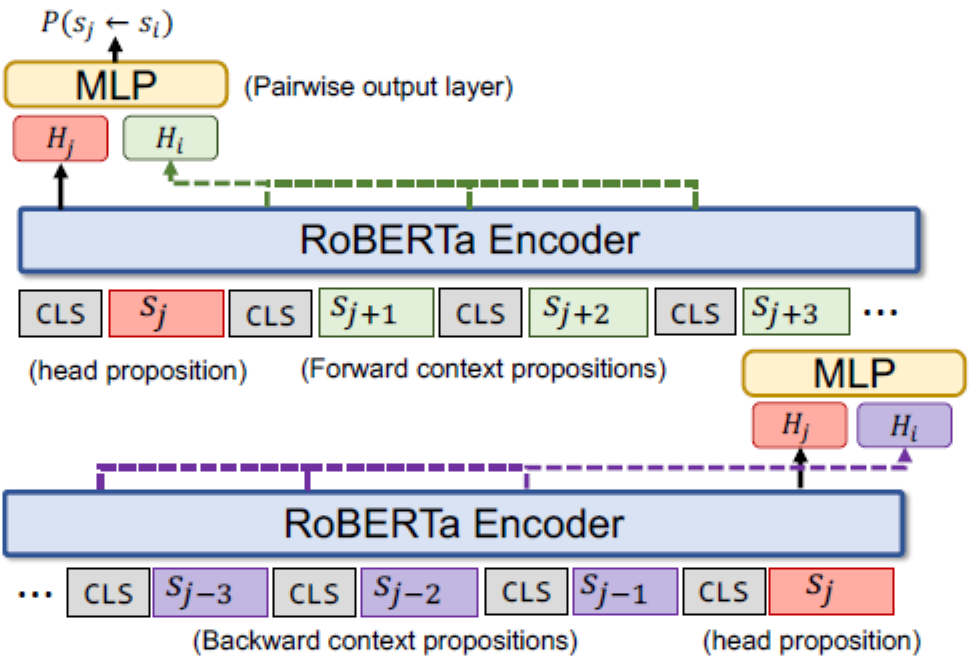
下圖表示了該模型,模型是建立在RoBERTa之上,RoBERTa包含多層,每一層都使用雙向多頭自注意力機制。對于每一個”頭部“命題,文章編碼了在它之前的個命題(紫色表示)以及它之后的個命題(綠色表示),命題之間通過[CLS]分開。表示的最后一層狀態,每一個和分別與拼接后傳給配對輸出層,從而預測命題到命題的概率。
預測概率公式為:
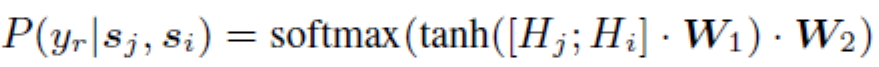
其中表示三類:支持、反對和無關。和表示訓練參數。
主動學習策略
文章考慮了一個基于池主動學習策略,訓練集的標簽最初是不可用的,并且進行次學習過程。在第次迭代中,利用給定的數據獲取策略選擇個樣本,將這些數據標注之后添加到數據池構成,模型在上訓練。
與模型無關的數據獲取策略
通過模型獲取的數據可能不適用于接下來的模型,這是主動學習的一個弊端。因此作者設計了與模型無關的數據獲取策略。
NOVEL-VOCAB促使命題使用更多未觀察到的單詞,假設單詞在數據池中出現的頻率為,則對于未標注的樣本的得分為:
其中是樣本中單詞的頻率。有著最高得分的樣本會被選中來標注。
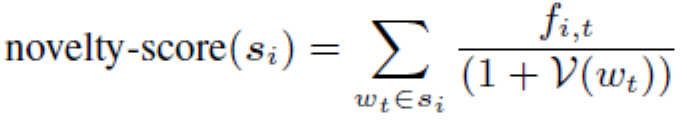
DISC-MARKER旨在通過匹配以下18個論述標記來選擇更多的關系鏈接。

數據集及相關領域
Domain 1: Peer Reviews
AMPERE包含了400篇ICLR 2018年的文章評審,每一個命題被標注為evaluation、request、fact、reference和quote。文章在AMPERE的基礎之上將命題之間的關系標注為支持或者反對,新的數據集命名為**AMPERE++**。最終結果為400篇評審包含3636對關系,其中300篇做為訓練集,20篇做為驗證集,80篇做為測試集。并且文章另外收集了42K篇評審用在自監督學習中來提高表示學習。
Domain 2: Essays
命題被標注為premise、claim和major claim,支持與反對關系只能存在于premise到premise或者claim,并且命題之間不能跨段落。其中282篇文章做為訓練集,20篇文章做為驗證集,80篇文章做為測試集,同樣作者另外收集了26K篇文章用來自監督表示學習。
Domain 3: Biomedical Paper Abstracts
AbstRCT語料庫包含700篇論文摘要,主要主題是疾病的隨機對照試驗。其中350篇摘要做為訓練集,50篇做為驗證集,300篇做為測試集。作者另外收集了133K篇未標注的摘要用做自監督學習。
Domain 4: Legal Documents
ECHR包含了42篇關于歐洲人權法院的法律文件,其中27篇做為訓練集,7篇做為驗證集,8篇做為測試集。
Domain 5: Online User Comments
Cornell eRulemaking Corpus來自于線上論壇,其中501篇做為訓練集,80篇做為驗證集,150篇做為測試集。
實驗結果
監督學習結果
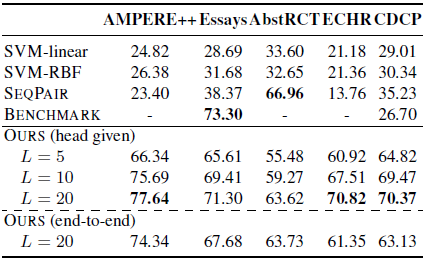
下表表明了除了Essays和AbstRCT,上下文感知模型均優于基線模型,在這兩個數據集上特征豐富的SVM性能要優于上下文感知模型。AbstRCT有著更高的正樣本率,表明上下文感知模型在對抗不平衡的訓練數據上面要更加魯棒。
遷移學習結果
上一節中的結果顯示了不同域之間的巨大性能差異。帶有少量標記樣本的域,例如AbstRCT和CDCP,會導致更差的性能。此外,注釋某些領域的論元結構更加復雜。我們假設理解論元關系的基本推理能力可以跨域共享,因此作者研究了遷移學習,它利用具有相似任務標簽(transductive)或相同目標域的未標記數據(inductive)做為現有數據。具體來說,作者在所有傳輸對上進行了全面的遷移學習實驗,其中模型首先在源域上訓練并在目標域上進行微調。
Transductive TL下表的上半部分顯示,從 AMPERE++ 遷移而來的模型中有四分之三的模型實現了更好的性能。但是,當從其他四個數據集進行傳輸時,性能偶爾會下降。這可能是由于不同的語言風格和論元結構、源域大小或由于過度依賴論述標記而導致模型無法學習良好的表示。總體而言,AMPERE++ 始終有利于論元結構理解不同領域,展示了其在未來研究中的潛力。
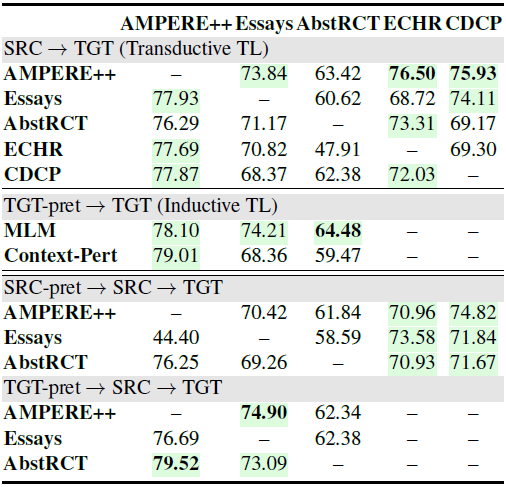
Inductive TL作者考慮了歸納式的遷移學習并且設置了兩個任務:
(1)掩碼模型預測(MLM):隨機選擇15%的輸入數據做為預測;
(2)上下文感知的句子擾動(Context-Pert):它將每個文檔打包成一個由[CLS]分割的句子序列,其中20%被來自其他文檔的隨機句子替換,另外20%在同一個文檔中打亂, 其余不變。
預訓練目標是預測每個句子的擾動類型。結果在上表的中間部分,其中MLM對所有三個領域都有好處。Context-Pert進一步提高了AMPERE++的性能,但降低了其他兩個域的性能。
Combining Inductive and Transductive TL此外,作者證明了添加自監督學習做為Transductive遷移學習的額外預訓練步驟可以進一步提高性能。從上表的下半部分來看,預訓練模型比標準的Transductive遷移學習得到了一致的改進。值得注意的是,使用目標域進行預訓練會比使用源域數據產生更好的結果。這意味著更好的目標域語言表示學習比更強大的源域模型更有效。
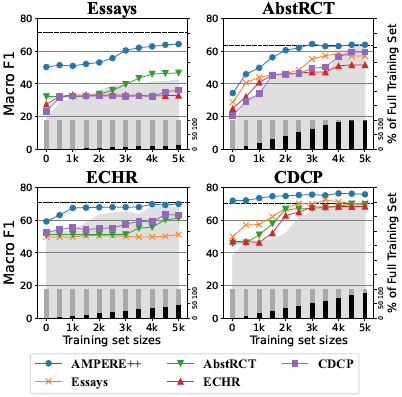
Effectiveness of TL in Low-Resource Setting為了定量地證明遷移學習如何使低資源目標域有效,我們控制訓練數據的大小并對每個域進行Transductive遷移學習。下圖描繪了訓練數據從0到5,000變化的趨勢,增量為500。在所有數據集中,AMPERE++作為源域產生了最好的遷移學習結果:使用不到一半的目標訓練集。一般來說,當使用較少的訓練數據時,遷移學習會帶來更多的改進。
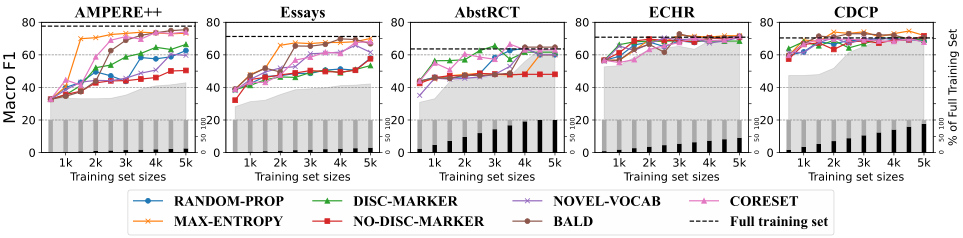
主動學習結果
下圖展示了所有策略的F1得分,從圖中可以看出,標注數據越多,性能越好。MAX-ENTROPY,BALD和CORESET三種基于模型的方法獲得更好的性能,不依賴模型的方法也產生了相對較好的結果。對于AMPERE++和AbstRCT,DISC-MARKER被證實是一個很好的啟發式選擇。在論文領域中,由于論述標記大量使用,所以它的得分相對較低,不使用論述標記會導致性能下降。值得注意的是,在不依賴任何訓練模型的情況下,特定于任務的數據獲取策略可以有效地標記論元關系。


論文動機
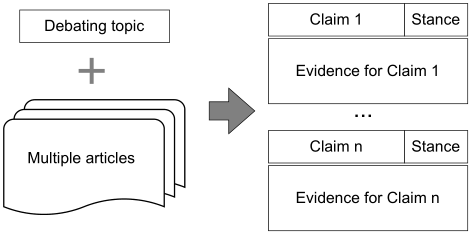
傳統的論辯通常需要人工準備過程,包括閱讀大量文章,選擇主張,確定主張的立場,為主張尋找證據等。論辯挖掘做為論辯系統中的核心,近年來受到了廣泛關注。一些論辯挖掘任務和數據集被用來自動化實現AI論辯,文章的目標是實現論辯論準備過程的自動化,如圖所示。具體來說,提供論辯主題和幾篇相關的文章,從這些主張中提取它們的立場,以及支持這些主張的證據。
然而現有的工作沒有能夠完成這一系列的任務(主張提取、立場分類、證據提取),因此文章提出了IAM數據集來解決這個難題。為了更好地協調這些任務,文章提出了兩個新的集成任務:基于立場分類的主張提取(CESC)和主張-證據對提取(CEPE)。這兩個任務不對現有的任務進行處理,而是將相關的主要任務整合在一起,這樣在準備辯論的過程中更實際、更有效。CESC任務可以分為兩個子任務:主張檢測任務和立場分類任務。直觀上,我們在CESC任務上進行實驗,采用流水線方法將兩個子任務結合起來。由于這兩個子任務是相輔相成的,所以我們也采用了端到端的多標簽分類模型(支持、反對、無關系)。CEPE任務由主張檢測任務和證據檢測任務組成。與注釋過程類似,利用多任務模型同時提取主張和證據及其配對關系。
IAM數據集
數據收集
作者從線上論壇廣泛的收集了123個論辯主題,對于每個主題,收集了大約10篇來自英文維基百科的文章,總共收集了1010篇文章,共69,666個句子。
數據標注
標注過程分為兩個階段:
對給定話題檢測主張;
對給定主張檢測證據。
下表表示了一個例子,主題是”人工智能會取代人類嗎?“以及標注好的主張。主張被標記為“C_index”,證據被標記為“E_index”。對于立場,“+1”代表支持該主題的當前主張,而“-1”代表反對該主題的主張。一個證據可以支持多個主張,同樣一主張也可以由多個證據來支持。

數據集分析
該數據集包含123個話題,可以應用于各個子任務。下表展示了數據集的統計信息,句子的長度平均21個單詞,數據集還計算了每個”主張-證據“句子對之間共享的詞匯的平均百分比為20.14%;而語料庫中任意兩個句子之間的比例僅為8.73%。這說明提取“主張-證據”對是一項合理的任務,因為“主張-證據”的詞匯共享比例高于其他句子對。

任務
現存的子任務
主張提取:給定一個特定的論辯主題和相關文章,自動從文章中提取主張。因為主張是關鍵的論元,所以主張提取任務是基礎性任務。
立場分類:給定一個主題和為其提取的一組主張,確定每個主張是支持該主題還是反對該主題。
證據提取:給定一個具體的主題、相關的主張和可能相關的文章,需要該模型自動確定這些文檔中的證據。
集成的任務
主張提取-立場分類(CESC):由于主張有著明確的立場,因此立場明確的句子很有可能成為主張。立場識別可能有利于主張提取,因此將任務一與任務二合并,即給定一個特定的主題和相關的文章,從文章中提取主張,也確定主張對該主題的立場。
主張-證據對提取(CEPE):文章假設主張提取和證據提取之間相輔相成,所以結合任務一和任務三,即給定一個特定的主題和相關的文章,從文章中提取主張-證據對。
方法
句子配對分類
將句子對連接起來,并輸入到預訓練模型中,以獲得“[CLS]”標記的隱藏狀態。之后,一個線性分類器將預測兩個句子之間的關系。任務一到任務三都可以表示為一個二分類任務,交叉熵做為損失函數。
由于任務一和任務三的數據標簽是不平衡的,主張和證據的總數要遠小于句子總數,因此可以利用負采樣來解決。在這兩個任務訓練過程中,對于每一個主張或者證據,隨機選取一定數量的非主張或非證據句子做為負樣本,這些負樣本連同所有的主張和證據共同構成了每個任務的新的訓練數據集。
多標簽模型用于CESC
文章將主題和句子配對輸入到預訓練模型中,輸出標簽為支持、反對和無關。由于無關的數量要遠大于支持和反對的數量,因此采用負采樣來保證更加平衡的訓練過程。
多任務模型用于CEPE
首先將主題和文章中各個句子連接起來做為主張候選集,文章中的句子序列做為證據候選集。將主張提取和證據提取定義為序列標注問題,主張候選集和證據候選集輸入到預訓練模型中得到嵌入表示。為了預測兩句話是否構成主張-證據對,文章采用填表的方法,將主張候選集的每個句子與證據候選集的每個句子配對,形成一個表,所有三個特征(即主張候選集、證據候選集、表格)都通過注意力引導的多交叉編碼層相互更新。最后,兩個序列特征用于預測其序列標簽,表格特征用于每個主張和證據之間的配對預測。與流水線方法相比,該多任務模型具有更強的子任務協調能力,因為兩個子任務之間的共享信息是通過多交叉編碼器顯式學習的。
實驗結果
現有任務的主要結果
1.主張提取:下表展示了任務一的性能,RoBERTa-base性能略優于BERT-base-cased。
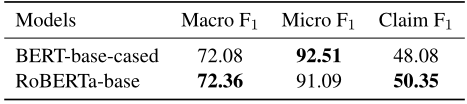
2.立場分類:下表說明兩種類型的主張F1得分相近,并且RoBERTa-base性能優于BERT-base-cased。
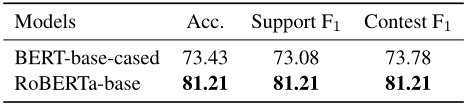
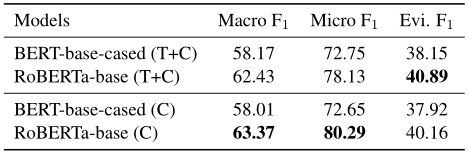
3.證據提取:下表顯示了任務3上的性能。同樣,RoBERTa模型比BERT模型性能更好。對于這個任務,作者實驗了兩種設置:(1)給定主題和主張(T+C),(2)僅給定主張(C),從候選句子中識別證據。對于(T+C)設置,只需將主題和主張連接為一個句子,并與證據候選集配對,以預測它是否是特定主題下給定主張的證據。對比這兩種設置的結果,添加主題的句子作為輸入并沒有進一步顯著提高性能,這說明主張與證據的關系更密切,而主題并不是證據提取的決定性因素。
集成任務的主要結果
CESC任務:下表顯示了CESC任務的兩種方法的結果。對于兩種方法,在訓練過程中為每個正樣本(主張)隨機選取5個負樣本。流水線模型獨立訓練兩個子任務,然后將它們連接到一起,以預測一個句子是否為主張以及句子的立場。雖然它在每個子任務上都取得了最好的性能,但總體性能不如多標簽模型。結果表明,識別主張的立場有利于主張提取任務,這種多標簽模型有利于集成CESC任務。

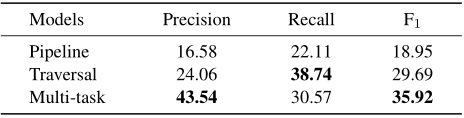
CEPE任務:下表顯示了不同方法之間的總體性能比較。除了前面提到的流水線和多任務模型,文章還添加了另一個基線模型,命名為“遍歷”。在該模型中,所有可能的“主題+主張候選句”和“證據候選句”被連接起來,并輸入到句子對分類模型中。遍歷模型和多任務模型在F1總分上都優于流水線模型,這意味著同時處理這兩個子任務的重要性。多任務模型的性能優于遍歷模型,說明多任務體系結構具有較強的子任務協調能力。


論文動機
線上論辯文本:用戶在網上來回發布的帖子引發的討論,反映了大規模的意見互動。下圖表示了兩個用戶連續發帖中的論元標注,紅色代表主張,藍色代表前提。

標注數據的缺乏:之前的研究試圖以半監督的方式利用大量的未標記數據,然而這種方法要求論元被定義在句子級別,因此在預測過程中會添加額外的跨度。BERT雖然可以解決特定任務上的數據稀缺問題,但是BERT學習到的語言表示依然限制了此類模型的表達能力。
因此,作者提出了基于Transformer的遷移學習方法。作者從CMV社區中使用大量未標記數據做為論辯知識來源,基于Transformer的預訓練模型使用掩碼語言模型(MLM)在數據集上微調,不像之前隨機掩碼單詞來預測,作者掩碼幾個帖子中特定的標記來進行預測,將這種方法命名為選擇性掩碼語言模型(sMLM)。為了充分利用基于sMLM語言模型訓練,作者提出了基于prompt的方法來預測論元之間的關系。
選擇性語言模型(sMLM)
CMV的結構
討論論壇方便用戶可以發帖子以及在下面進行評論,其他用戶可以回復原帖或者評論。最終可以形成類似于以原帖為根節點的樹形結構,從根節點到葉子節點的路徑可以被視為兩個或多個用戶獨立的對話路徑,將該路徑稱為“線程”。
sMLM微調
作者選擇特定的詞來掩碼,而不是隨機選擇。作者選擇多個標記,表明意見、因果關系、反駁、事實陳述、假設、總結和一些額外的詞,這些詞根據上下文的不同有多種用途。下圖表示sMLM需要預訓練語言模型來根據上下文預測紅色單詞。
由于CMV線程將對話分為評論/帖子級別以及線程級別。作者試圖探索在不同的論辯挖掘任務中文本大小的影響。為此作者使用提出的sMLM對BERT進行微調,并在線程機制中訓練Longformer模型,Longformer使用稀疏的全局的注意力機制,即少量單詞關注全部單詞來獲得長期依賴。

論元識別
在選擇性微調之后,作者要在線程中識別論元類型。由于在單詞級別上進行的檢測,所以使用標準的BIO標注模式,即.
論元關系識別
作者提出基于prompt的方法來預測論元之間的關系。如下圖所示,試圖對USER-1和USER-2提出的主張之間的關系進行分類,分別用紅色和綠色突出顯示;通過追加提示模板,線程被轉換為提示輸入。語言模型將提示標記序列轉換為固定維度的向量,掩碼標記位置對應的向量用于關系分類。

實驗結果
數據集
作者使用CMV做為數據集,其中99%的數據做為訓練集,1%的數據用來檢驗sMLM模型的準確率。數據集包括3051條原帖以及293,297條評論,共有34,911個用戶,120,031個線程。
論元識別
下表展示了論元識別的結果。首先,從現有性能最好的基于LSTM的方法(精度為0.54)轉移到BERT時(精度為0.62),可以看到字符級標記精度得分的巨大差異。這種差異是意料之中的,因為像BERT這樣的預訓練語言模型在CMV這樣的小型數據集中提供了先機。盡管字符級標記的精度提高了,但是精確論元匹配的微平均F1得分在使用RoBERTa之前并沒有增加太多。使用sMLM微調進行訓練的Longformer在論元識別的F1總得分方面明顯優于其他模型。然而,與評論級上下文(RoBERTa)相比,選擇性語言模型的影響在線程級上下文(即Longformer)的情況下更為突出。
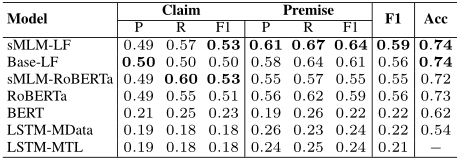
論元關系識別
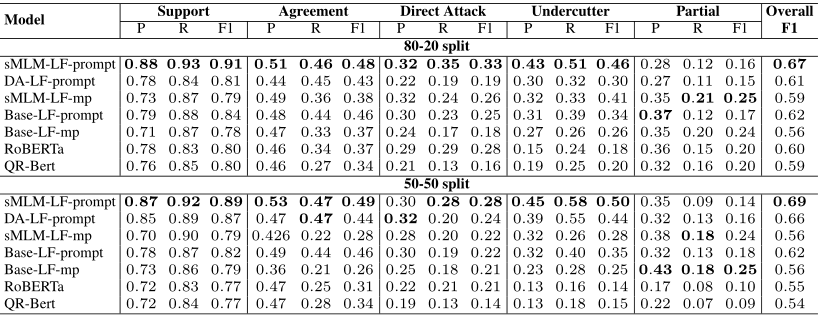
下表給出了CMV數據集上論元關系識別的結果。考慮傳統的平均池化方法,在這種方法中,我們觀察到sMLM預先訓練的Longformer在訓練集為80%和測試集為20%的情況下提高了3個點,而在訓練集和測試集各為50%的情況下保持相似的性能。此外,無論使用Longformer還是sMLM,基于prompt的方法始終優于平均池化方法。
審核編輯 :李倩
-
機器學習
+關注
關注
66文章
8459瀏覽量
133371 -
數據集
+關注
關注
4文章
1212瀏覽量
24964 -
遷移學習
+關注
關注
0文章
74瀏覽量
5611
原文標題:ACL2022 | 基于遷移學習的論元關系提取
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論