


本文旨在幫大家快速了解文本語義相似度領域的研究脈絡和進展,其中包含了本人總結的文本語義相似度任務的處理步驟,文本相似度模型發(fā)展歷程,相關數(shù)據(jù)集,以及重要論文分享。
文本相似度任務處理步驟
通過該領域的大量論文閱讀,我認為處理文本相似度任務時可以分為一下三個步驟:
預處理:如數(shù)據(jù)清洗等。此步驟旨在對文本做一些規(guī)范化操作,篩選有用特征,去除噪音。
文本表示:當數(shù)據(jù)被預處理完成后,就可以送入模型了。在文本相似度任務中,需要有一個模塊用于對文本的向量化表示,從而為下一步相似度比較做準備。這個部分一般會選用一些 backbone 模型,如 LSTM,BERT 等。
學習范式的選擇:這個步驟也是文本相似度任務中最重要的模塊,同時也是區(qū)別于 NLP 領域其他任務的一個模塊。其主要原因在于相似度是一個比較的過程,因此我們可以選用各種各樣的比較的方式來達成目標。可供選擇的學習方式有:孿生網絡模型,交互網絡模型,對比學習模型等。
文本相似度模型發(fā)展歷程
從傳統(tǒng)的無監(jiān)督相似度方法,到孿生模型,交互式模型,BERT,以及基于BERT的一些改進工作,如下圖:
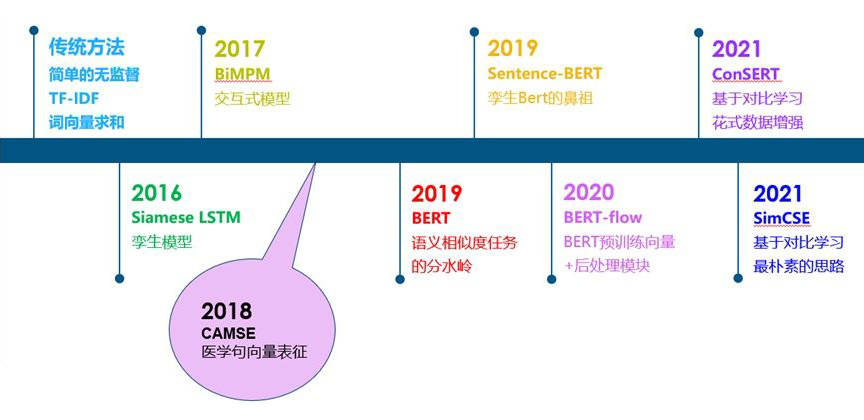
總體來說,在 BERT 出現(xiàn)之前,文本相似度任務可以說是一個百花齊放的過程。大家通過各種方式來做相似度比較的都有。從 BERT 出現(xiàn)之后,由于 BERT 出色的性能,之后的工作主要是基于 BERT 的改進。在這個階段,大家所采用的數(shù)據(jù)集,評價指標等也逐漸進行了統(tǒng)一。
數(shù)據(jù)集
在 BERT 以后,大家在文本相似度任務上逐漸統(tǒng)一了數(shù)據(jù)集的選擇,分別為 STS12,STS13,STS14,STS15,STS16,STS-B,SICK-R 七個數(shù)據(jù)集。STS12-16 分別為 SemEval 比賽 2012~2016 年的數(shù)據(jù)集。此外,STS-B 和 SICK-R 也是 SemEval 比賽數(shù)據(jù)集。在這些數(shù)據(jù)集中,每一個文本對都有一個 0~5 分的人工打標相似度分數(shù)(也稱為 gold label),代表這個文本對的相似程度。
評價指標
首先,對于每一個文本對,采用余弦相似度對其打分。打分完成后,采用所有余弦相似度分數(shù)和所有 gold label 計算 Spearman Correlation。
其中,Pearson Correlation 與 Spearman Correlation 都是用來計算兩個分布之間相關程度的指標。Pearson Correlation 計算的是兩個變量是否線性相關,而 Spearman Correlation 關注的是兩個序列的單調性是否一致。并且論文《Task-Oriented Intrinsic Evaluation of Semantic Textual Similarity》證明,采用 Spearman Correlation 更適合評判語義相似度任務。Pearson Correlation 與 Spearman Correlation 的公式如下:
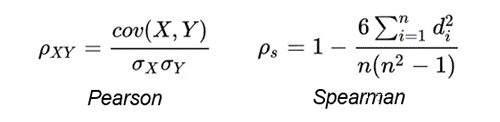
論文分享
Siamese Recurrent Architectures for Learning Sentence Similarity, AAAI 2016
https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/download/12195/12023
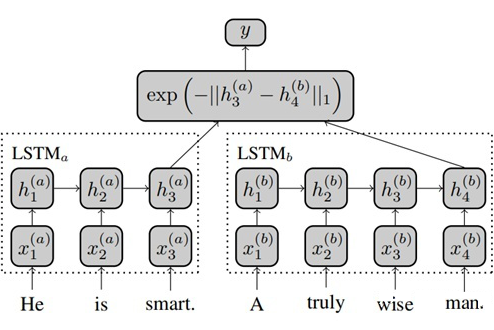
Siamese LSTM 是一個經典的孿生網絡模型,它將需要對比的兩句話分別通過不同的 LSTM 進行編碼,并采用兩個 LSTM 最后一個時間步的輸出來計算曼哈頓距離,并通過 MSE loss 進行反向傳導。
Bilateral Multi-Perspective Matching for Natural Language Sentences, IJCAI 2017
https://arxiv.org/abs/1702.03814
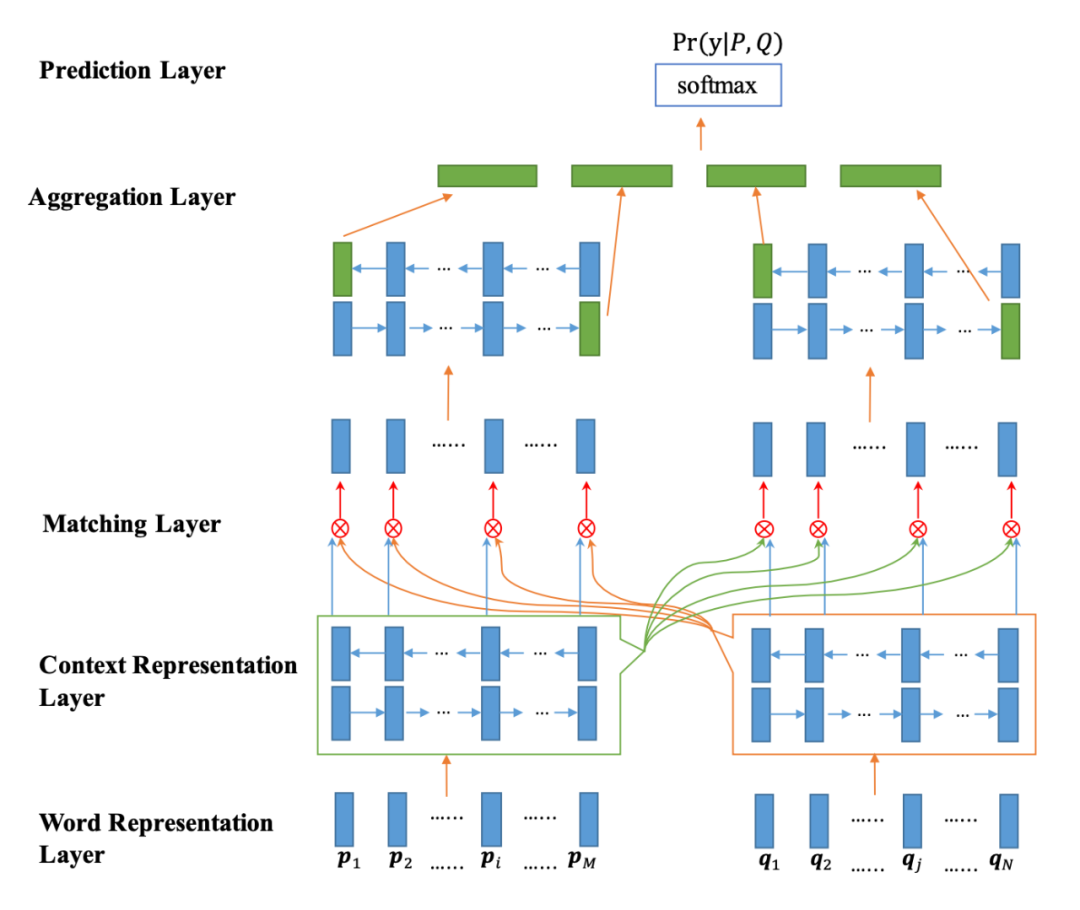
BiMPM 是一個經典的交互式模型,它將兩句話用不同的 Bi-LSTM 模型分別編碼,并通過注意力的方式使得當前句子的每一個詞都和另一個句子中的每一個詞建立交互關系(左右句子是對稱的過程),從而學習到更深層次的匹配知識。在交互之后,再通過 Bi-LSTM 模型分別編碼,并最終輸出。
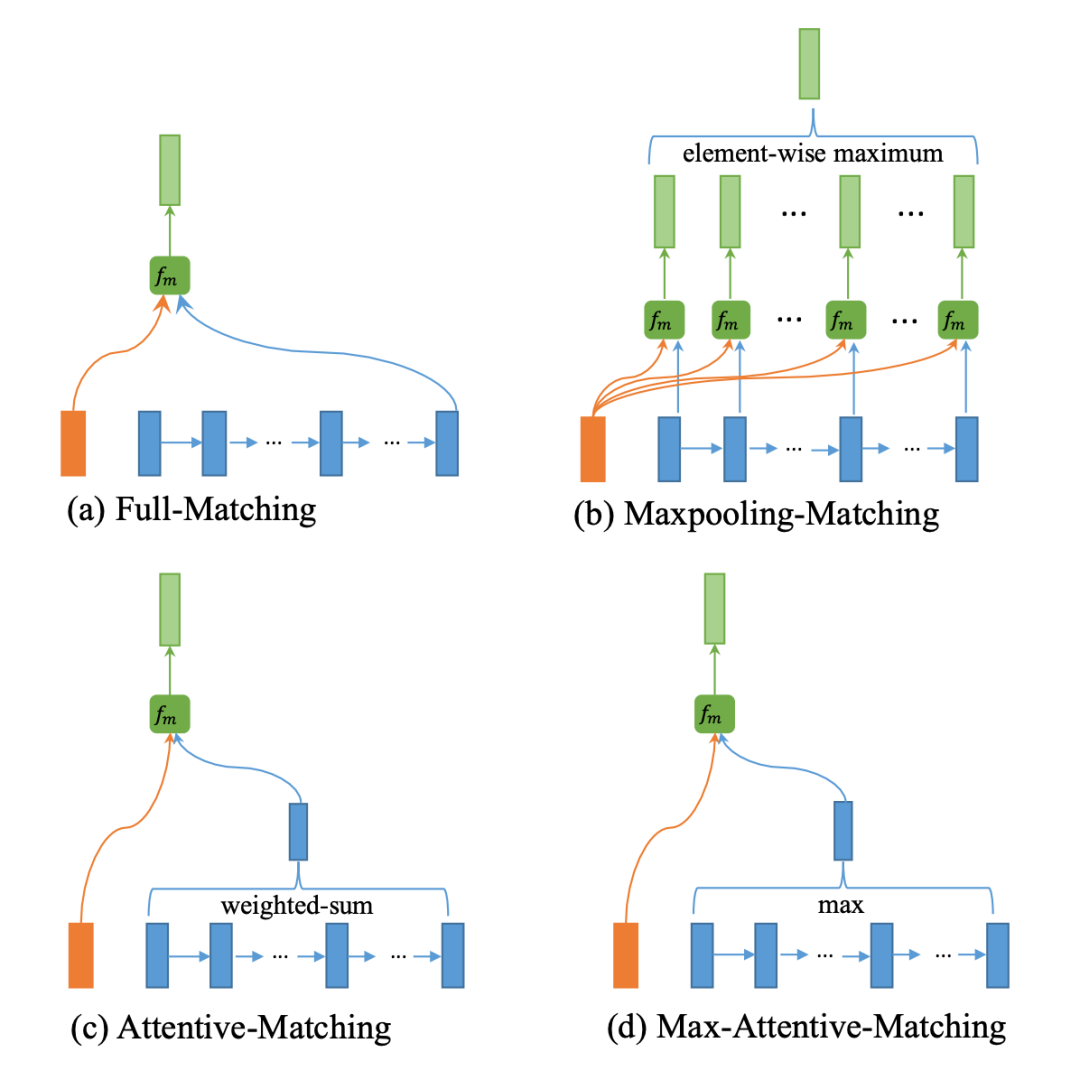
對于交互的過程,作者設計了四種交互方式,分別為:
句子 A 中每個詞與句子 B 的最后一個詞進行交互
句子 A 中每個詞與句子 B 的每個詞進行交互,并求 element-wise maximum
通過句子 A 中的詞篩選句子 B 中的每一個詞,并將句子 B 的詞向量加權求和,最終于 A 詞對比
與 c 幾乎一致,只不過將加權求和操作變成 element-wise maximum
具體的交互形式是由加權的余弦相似度方式完成。
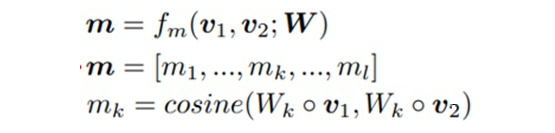
其中,Wk 是參數(shù)矩陣,可以理解為 attention 的 query 或者 key,v1 和 v2 分別是要進行交互的兩個詞,這樣計算 l 次余弦相似度,就會得到 m 向量(一個 l 維向量)。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
https://arxiv.org/abs/1810.04805
BERT 可以認為是語義相似度任務的分水嶺。BERT 論文中對 STS-B 數(shù)據(jù)集進行有監(jiān)督訓練,最終達到了 85.8 的 Spearman Correlation 值。這個分數(shù)相較于后續(xù)絕大部分的改進工作都要高,但 BERT 的缺點也很明顯。對于語義相似度任務來說:
在有監(jiān)督范式下,BERT 需要將兩個句子合并成一個句子再對其編碼,如果需要求很多文本兩兩之間的相似度,BERT 則需要將其排列組合后送入模型,這極大的增加了模型的計算量。
在無監(jiān)督范式下,BERT 句向量中攜帶的語義相似度信息較少。從下圖可以看出,無論是采用 CLS 向量還是詞向量平均的方式,都還比不過通過 GloVe 訓練的詞向量求平均的方式要效果好。

基于以上痛點,涌現(xiàn)出一批基于 BERT 改進的優(yōu)秀工作。
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, EMNLP 2019
https://arxiv.org/abs/1908.10084
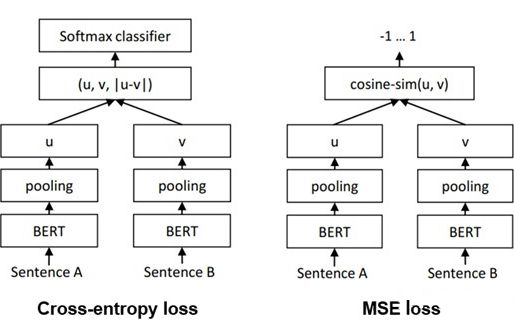
Sentence-BERT 是一篇采用孿生 BERT 架構的工作。Sentence-BERT 作者指出,如果想用 BERT 求出 10000 個句子之間兩兩的相似度,排列組合的方式在 V100 GPU 上測試需要花費 65 小時;而如果先求出 10000 個句子,再計算余弦相似度矩陣,則只需要花費 5 秒左右。因此,作者提出了通過孿生網絡架構訓練 BERT 句向量的方式。
Sentence-BERT 一共采用了三種 loss,也就是三種不同的方式訓練孿生 BERT 架構,分別為 Cross-entropy loss,MSE loss 以及 Triple loss,模型圖如下:
On the Sentence Embeddings from Pre-trained Language Models, EMNLP 2020
https://arxiv.org/abs/2011.05864
BERT-flow 是一篇通過對 BERT 句向量做后處理的工作。作者認為,直接用 BERT 句向量來做相似度計算效果較差的原因并不是 BERT 句向量中不包含語義相似度信息,而是其中包含的相似度信息在余弦相似度等簡單的指標下無法很好的體現(xiàn)出來。
首先,作者認為,無論是 Language Modelling 還是 Masked Language Modelling,其實都是在最大化給定的上下文與目標詞的共現(xiàn)概率,也就是 Ct 和 Xt 的貢獻概率。Language Modelling 與 Masked Language Modelling 的目標函數(shù)如下:
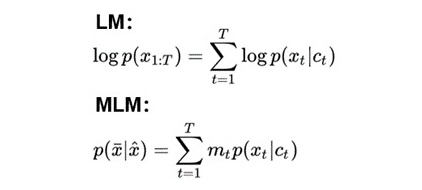
因此,如果兩句話預測出的 Xt 一致,那么兩句話的 Ct 向量很有可能也是相似的!考慮如下兩句話:
今天中午吃什么?
今天晚上吃什么?
通過這兩句話訓練出的語言模型都通過上下文預測出了“吃“這個字,那說明這兩句話的句向量也很可能是相似的,具有相似的語義信息。
其次,作者通過觀察發(fā)現(xiàn),BERT 的句向量空間是各向異性的,且高頻詞距離原點較近,低頻詞距離較遠,且分布稀疏。因此 BERT 句向量無法體現(xiàn)出其中包含的相似度信息。
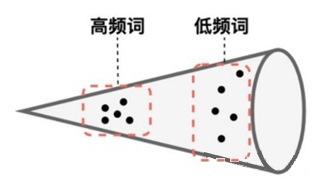
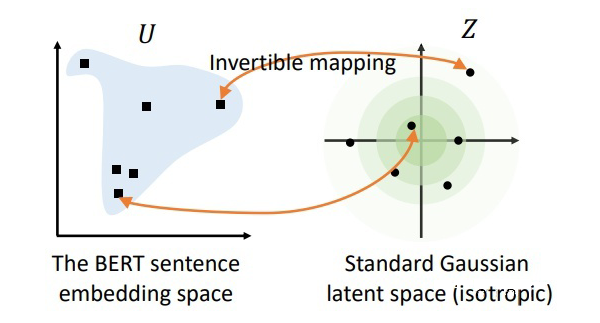
因此,作者認為可以通過一個基于流的生成模型來對 BERT 句向量空間進行映射。具體來說,作者希望訓練出一個標準的高斯分布,使得該分布中的點可以與 BERT 句向量中的點一一映射。由于該方法采用的映射方式是可逆的,因此就可以通過給定的 BERT 句向量去映射回標準高斯空間,然后再去做相似度計算。由于標準高斯空間是各向同性的,因此能夠將句向量中的語義相似度信息更好的展現(xiàn)出來。
SimCSE: Simple Contrastive Learning of Sentence Embeddings, EMNLP 2021
https://arxiv.org/abs/2104.08821
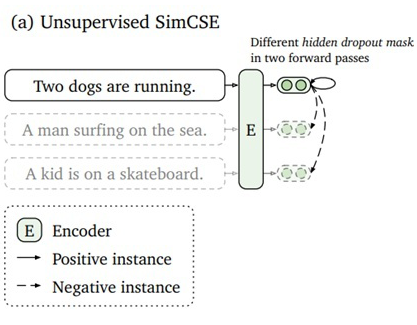
SimCSE 是一篇基于對比學習的語義相似度模型。首先,對比學習相較于文本對之間的匹配,可以在拉近正例的同時,同時將其與更多負例之間的距離拉遠,從而訓練出一個更加均勻的超球體向量空間。作為一類無監(jiān)督算法,對比學習中最重要的創(chuàng)新點之一是如何構造正樣本對,去學習到類別內部的一些本質特征。
SimCSE 采用的是一個極其樸素,性能卻又出奇的好的方法,那就是將一句話在訓練的時候送入模型兩次,利用模型自身的 dropout 來生成兩個不同的 sentence embedding 作為正例進行對比。模型圖如下:
ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer, ACL 2021
https://arxiv.org/abs/2105.11741
ConSERT 同樣也是一篇基于對比學習的文本相似度工作。ConSERT 是采用多種數(shù)據(jù)增強的方式來構造正例的。其中包括對抗攻擊,打亂文本中的詞順序,Cutoff以及 Dropout。這里需要注意的是,雖然 ConSERT 與 SimCSE 都采用了 Dropout,但 ConSERT 的數(shù)據(jù)增強操作只停留在 embedding layer,而 SimCSE 則是采用了 BERT 所有層中的 Dropout。此外,作者實驗證明,在這四種數(shù)據(jù)增強方式中,Token Shuffling 和 Token Cutoff 是最有效的。
Exploiting Sentence Embedding for Medical Question Answering, AAAI 2018
https://arxiv.org/abs/1811.06156
注:由于本人工作中涉及的業(yè)務主要為智慧醫(yī)療,因此會有傾向的關注醫(yī)療人工智能領域的方法和模型。
MACSE 是一篇針對醫(yī)學文本的句向量表征工作,雖然其主要關注的是 QA 任務,但他的句向量表征方式在文本相似度任務中同樣適用。
醫(yī)學文本區(qū)別于通用文本的一大特征就是包含復雜的多尺度信息,如下:
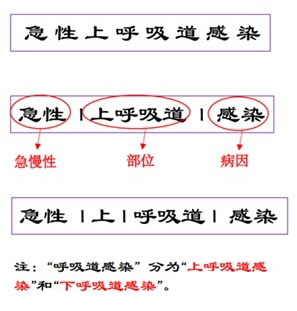
因此,我們就需要一個能夠關注到醫(yī)學文本多尺度信息的模型。
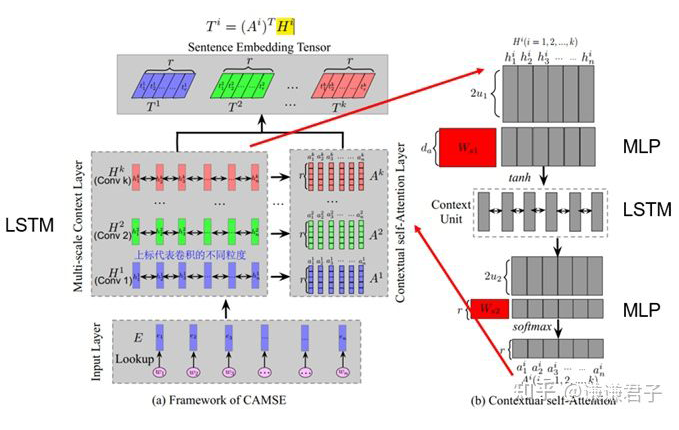
在本文中,通過多尺度的卷積操作,就可以有效的提取到文本中的多尺度信息,并且通過注意力機制對多尺度信息進行加權,從而有效的關注到特定文本中在特定尺度上存在的重要信息。
實驗結果匯總
以下為眾多基于 BERT 改進的模型在標準數(shù)據(jù)集上測試的結果,出自 SimCSE 論文:
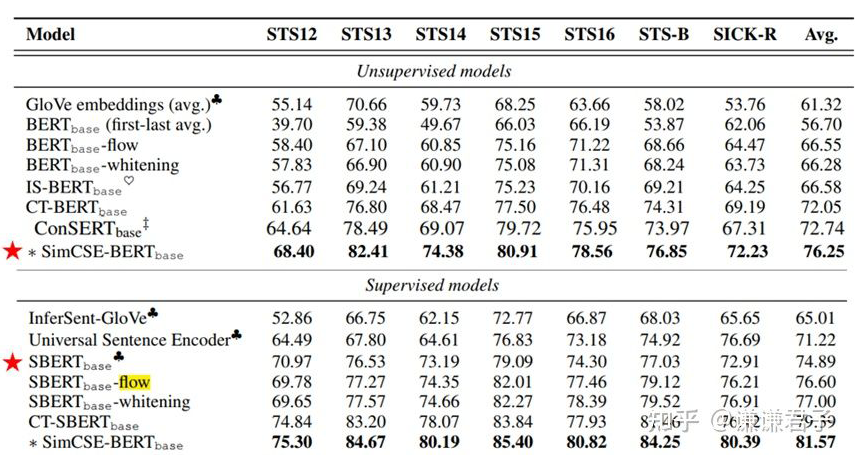
可以看到,BERT-flow 相較于原生 BERT 提升了將近 10 個點,而基于對比學習的工作又要比基于后處理的工作的效果好很多。此外需要注意的是,在這里 Sentence-BERT 被歸為了有監(jiān)督模型中。這是因為 Sentence-BERT 雖然沒有用到 STS 標簽,但訓練時用的是 NLI 數(shù)據(jù)集,也用到了 NLI 中人工打標的標簽,因此 SimCSE 作者將 Sentence-BERT 歸為了有監(jiān)督模型中。
好了,以上就是文本語義相似度領域的研究脈絡和進展,希望能對大家有所幫助。當然 2022 年也有不少優(yōu)秀的工作出現(xiàn),不過這一部分就留到以后吧!
審核編輯 :李倩
-
模型
+關注
關注
1文章
3524瀏覽量
50478 -
語義
+關注
關注
0文章
21瀏覽量
8743 -
文本
+關注
關注
0文章
119瀏覽量
17459
原文標題:一文詳解文本語義相似度的研究脈絡和最新進展
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
百度在AI領域的最新進展
蘭州大學:研究團隊在溫度傳感用發(fā)光材料領域取得新進展
《AI Agent 應用與項目實戰(zhàn)》閱讀心得3——RAG架構與部署本地知識庫
愛立信在電信領域取得重大進展
【「基于大模型的RAG應用開發(fā)與優(yōu)化」閱讀體驗】+Embedding技術解讀
SparseViT:以非語義為中心、參數(shù)高效的稀疏化視覺Transformer

利用VLM和MLLMs實現(xiàn)SLAM語義增強

EBSD技術在磁性材料研究中的應用進展
AI大模型的最新研究進展
北京大學研究團隊在新型激光領域取得重要進展
紫光展銳分析5G廣播技術的發(fā)展脈絡

中國科學院大學:實現(xiàn)可再生高靈敏度生物傳感器新進展





 工商網監(jiān)
工商網監(jiān)

評論