 關于YOLOU中模型的測試
關于YOLOU中模型的測試
這里推薦一個YOLO系列的算法實現庫YOLOU,此處的“U”意為“United”的意思,主要是為了學習而搭建的YOLO學習庫,也借此向前輩們致敬,希望不被罵太慘;
整個算法完全是以YOLOv5的框架進行,主要包括的目標檢測算法有:YOLOv3、YOLOv4、YOLOv5、YOLOv5-Lite、YOLOv6、YOLOv7、YOLOX以及YOLOX-Lite。
同時為了方便算法的部署落地,這里所有的模型均可導出ONNX并直接進行TensorRT等推理框架的部署,后續也會持續更新。
01
模型精度對比
 ? 服務端模型 這里主要是對于YOLO系列經典化模型的訓練對比,主要是對于YOLOv5、YOLOv6、YOLOv7以及YOLOX的對比,部分模型還在訓練之中,后續所有預訓練權重均會放出,同時對應的ONNX文件也會給出,方便大家部署應用落地。 注意,這里關于YOLOX也沒完全復現官方的結果,后續有時間還會繼續調參測試,盡可能追上YOLOX官方的結果。 下表是關于YOLOU中模型的測試,也包括TensorRT的速度測試,硬件是基于3090顯卡進行的測試,主要是針對FP32和FP16進行的測試,后續的TensorRT代碼也會開源。目前還在整理之中。
? 服務端模型 這里主要是對于YOLO系列經典化模型的訓練對比,主要是對于YOLOv5、YOLOv6、YOLOv7以及YOLOX的對比,部分模型還在訓練之中,后續所有預訓練權重均會放出,同時對應的ONNX文件也會給出,方便大家部署應用落地。 注意,這里關于YOLOX也沒完全復現官方的結果,后續有時間還會繼續調參測試,盡可能追上YOLOX官方的結果。 下表是關于YOLOU中模型的測試,也包括TensorRT的速度測試,硬件是基于3090顯卡進行的測試,主要是針對FP32和FP16進行的測試,后續的TensorRT代碼也會開源。目前還在整理之中。 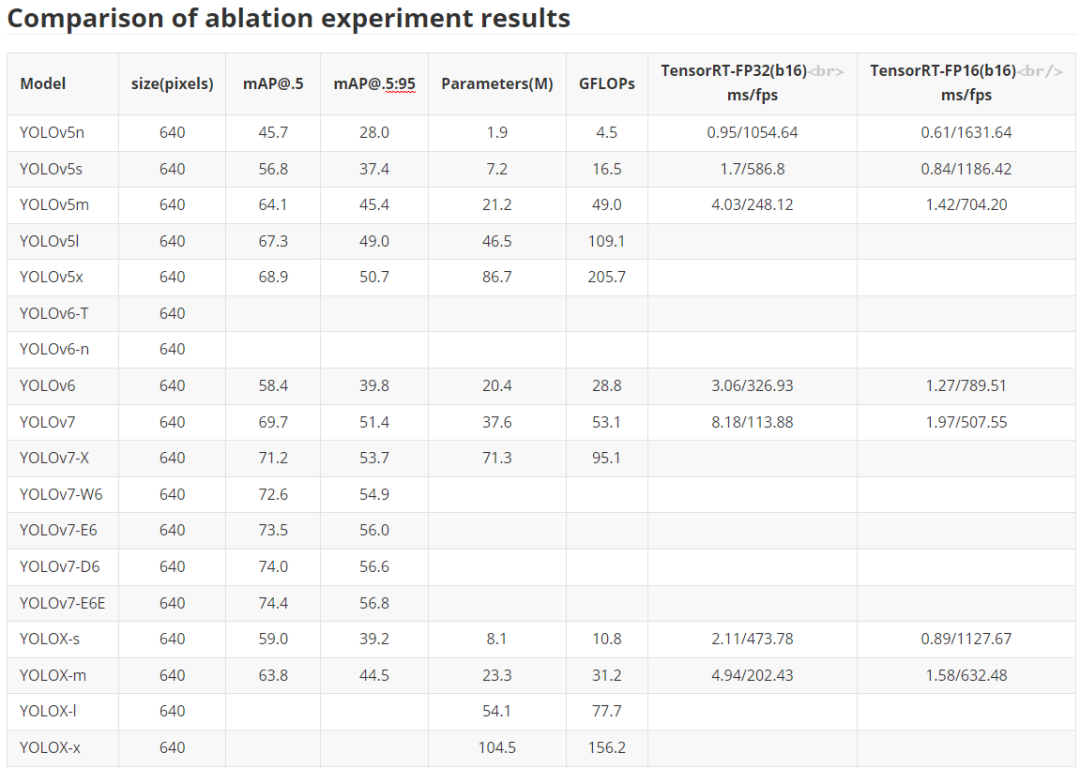 輕量化模型 為了大家在手機端或者其他諸如樹莓派、瑞芯微、AID以及全志等芯片的部署,YOLOU也對YOLOv5和YOLOX進行了輕量化設計。 下面主要是對于邊緣端使用的模型進行對比,主要是借鑒之前小編參與的YOLOv5-Lite的倉庫,這里也對YOLOX-Lite進行了輕量化遷移,總體結果如下表所示,YOLOX-Lite基本上可以超越YOLOv5-Lite的精度和結果。
輕量化模型 為了大家在手機端或者其他諸如樹莓派、瑞芯微、AID以及全志等芯片的部署,YOLOU也對YOLOv5和YOLOX進行了輕量化設計。 下面主要是對于邊緣端使用的模型進行對比,主要是借鑒之前小編參與的YOLOv5-Lite的倉庫,這里也對YOLOX-Lite進行了輕量化遷移,總體結果如下表所示,YOLOX-Lite基本上可以超越YOLOv5-Lite的精度和結果。 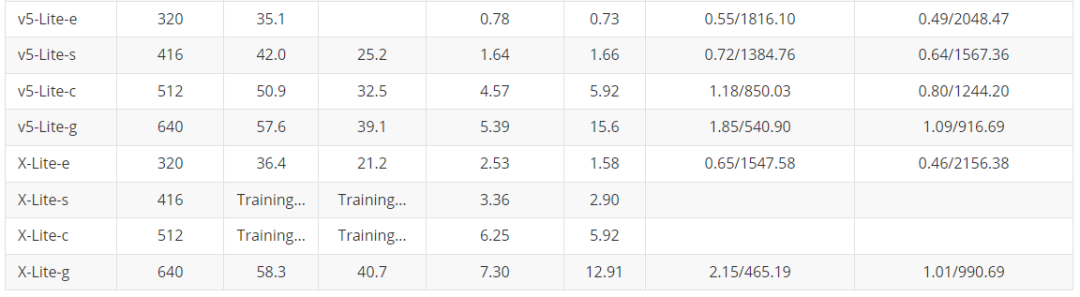
02
如何使用YOLOU?
? 安裝 這里由于使用的是YOLOv5的框架進行的搭建,因此安裝形式也及其的簡單,具體如下:
gitclonehttps://github.com/jizhishutong/YOLOU cdYOLOU pipinstall-rrequirements.txt數據集 這里依舊使用YOLO格式的數據集形式,文件夾形式如下:
train:../coco/images/train2017/ val:../coco/images/val2017/具體的標注文件和圖像list如下所示:
├──images#xx.jpgexample │├──train2017 ││├──000001.jpg ││├──000002.jpg ││└──000003.jpg │└──val2017 │├──100001.jpg │├──100002.jpg │└──100003.jpg └──labels#xx.txtexample ├──train2017 │├──000001.txt │├──000002.txt │└──000003.txt └──val2017 ├──100001.txt ├──100002.txt └──100003.txt參數配置 YOLOU為了方便切換不同模型之間的訓練,這里僅僅需要配置一個mode即可切換不同的模型之間的檢測和訓練,具體意義如下:
 注意:這里的mode主要是對于Loss計算的選擇,對于YOLOv3、YOLOv4、YOLOv5、YOLOR以及YOLOv5-Lite直接設置mode=yolo即可,對于YOLOX以及YOLOX-Lite則設置mode=yolox,對于YOLOv6和YOLOv7則分別設置mode=yolov6和mode=yolov7; 注意由于YOLOv7使用了Aux分支,因此在設置YOLOv7時有一個額外的參數需要配置,即use_aux=True。 具體訓練指令如下:
注意:這里的mode主要是對于Loss計算的選擇,對于YOLOv3、YOLOv4、YOLOv5、YOLOR以及YOLOv5-Lite直接設置mode=yolo即可,對于YOLOX以及YOLOX-Lite則設置mode=yolox,對于YOLOv6和YOLOv7則分別設置mode=yolov6和mode=yolov7; 注意由于YOLOv7使用了Aux分支,因此在設置YOLOv7時有一個額外的參數需要配置,即use_aux=True。 具體訓練指令如下:
pythontrain.py--modeyolov6--datacoco.yaml--cfgyolov6.yaml--weightsyolov6.pt--batch-size32檢測指令如下:
pythondetect.py--source0#webcam file.jpg#image file.mp4#video path/#directory path/*.jpg#glob 'https://youtu.be/NUsoVlDFqZg'#YouTube 'rtsp://example.com/media.mp4'#RTSP,RTMP,HTTPstream
-
硬件
+關注
關注
11文章
3312瀏覽量
66200 -
模型
+關注
關注
1文章
3226瀏覽量
48807 -
代碼
+關注
關注
30文章
4779瀏覽量
68521
原文標題:匯集YOLO系列所有算法,YOLOU算法實現庫來啦
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于模型的動態測試工具TPT
關于multisim中仿真模型的建立
動態模型在軟件系統測試過程中的應用研究
一種新的軟件測試模型—軟件層次化模型
關于模型測試與持續集成相結合的可行性分析
輻射測試中Antenna與EUT的測試距離換算

Simulink集成模型測試太慢怎么辦?






 工商網監
工商網監
評論