 支持Chiplet的底層封裝技術
支持Chiplet的底層封裝技術
Chiplet 概述 過去幾十年來,半導體行業一直按照摩爾定律的規律發展,憑借著芯片制造工藝的迭代,使得每18個月芯片性能提升一倍。但是當工藝演進到5nm,3nm節點,提升晶體管密度越來越難,同時由于集成度過高,功耗密度越來越大,供電和散熱也面臨著巨大的挑戰。Chiplet(芯粒)技術是SoC集成發展到當今時代,摩爾定律逐漸放緩情況下,持續提高集成度和芯片算力的重要途徑。工業界近期已經有多個基于Chiplet的產品面市,Intel甚至發布了集成47顆芯片的Ponte Vecchio系列,Chiplet技術已經是芯片廠商比較依賴的技術手段了。 相比傳統Monolithic芯片技術,Chiplet技術背景下,可以將大型單片芯片劃分為多個相同或者不同的小芯片,這些小芯片可以使用相同或者不同的工藝節點制造,再通過跨芯片互聯和封裝技術進行封裝級別集成,降低成本的同時獲得更高的集成度。通常來說,由于光刻掩膜版的尺寸限定在33mm * 26mm,單個芯片的面積一般不超過800mm^2,通過多個芯片的片間集成,可以在封裝層面突破單芯片上限,進一步提高集成度。而且從工藝制造良率的Bose-Einstein模型:
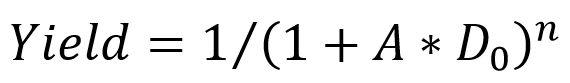
其中A代表芯片面積,D0代表缺陷密度,n代表掩膜版層數相關系數。單芯片的面積越大,良率越低,對應制造成本也越高。同時,在當前主流芯片架構中,信號處理部分通常為數字邏輯,隨著工藝演進相同功能情況下面積也會進一步縮小,但是各類接口部分通常為模擬電路,隨著工藝演進相同功能情況下面積幾乎不會縮小,因此合理地將不用功能有效劃分到不同工藝節點的芯片上,可以更高效利用現有制造工藝,有效降低成本。 Chiplet技術帶來上述高集成度和低成本等優勢的同時,也面臨著諸多技術挑戰,總體來說可以概括為:物理上如何拼接多個芯片;設計上如何將大芯片劃分為多個小芯片;以及如何標準化接口協議做到不同芯片產品標準化拼接。具體來說可以分為幾個不同的方面:
超高速、超高密度和超低延時的封裝技術,用來解決Chiplet之間遠低于單芯片內部的布線密度、高速可靠的信號傳輸帶寬和超低延時的信號交互。目前主流的封裝技術包括但不限于MCM、CoWoS、EMIB等。
基于Chiplet的架構設計,一方面考慮不同Chiplets之間如何進行功能劃分和架構定義,另一方面考慮多個Chiplets如何進行有效互聯和擴展,實現高效靈活可擴展的架構,避免多Chiplets之間出現信號死鎖、流量擁塞等功能和性能問題。
標準化的多Chiplets之間交互的通信互聯協議,用于指導和約束不同芯片的接口設計和標準化對接。目前由Intel、AMD、ARM、ASE、Google、 Meta、Microsoft、Qualcomm、Samsung和TSMC共同開發和制定的UCIe(UniversalChiplet Interconnect Express)已經發布第一版標準。
由于篇幅限制,本文基于上述三個方面,簡單介紹下當前業界主流實現方式,探討不同解決方法的優缺點和設計考量,后續會附上各個部分的詳細介紹。
支持Chiplet的底層封裝技術 封裝技術目前主要由TSMC、ASE、Intel等公司來主導,包含從2D MCM到2.5D CoWoS、EMIB和3D HybridBonding。本文主要介紹目前工業界主流的2D和2.5D封裝技術和其優缺點。
1. MCM(Multi-Chip Module)

Multi-chipModule
MCM一般是指通過Substrate(封裝基板)走線將多個芯片互聯的技術。通常來說走線的距離和范圍可以在10mm~25mm,線距線寬大約10mm量級,單條走線帶寬大約10Gbit/s量級。由于MCM可以通過基板直接連接各個芯片,通常封裝的成本會相對較低,但是由于走線的線距線寬比較大,封裝密度相對較低,接口速率相對較低,延時相對較大。
2. CoWoS(Chip-on-Wafer-on-Substrate)
CoWoS是TSMC主導的,基于interposer(中間介質層)實現的2.5D封裝技術,其中interposer采用成熟制程的芯片制造工藝,可以提供相比MCM更高密度和更大速率的接口。目前TSMC主流的CoWoS技術包括: CoWoS-S:基礎CoWoS技術,可以支持超高集成密度,提供不超過兩倍掩膜版尺寸的interposer層,通常用于集成HBM等高速高帶寬內存芯片。
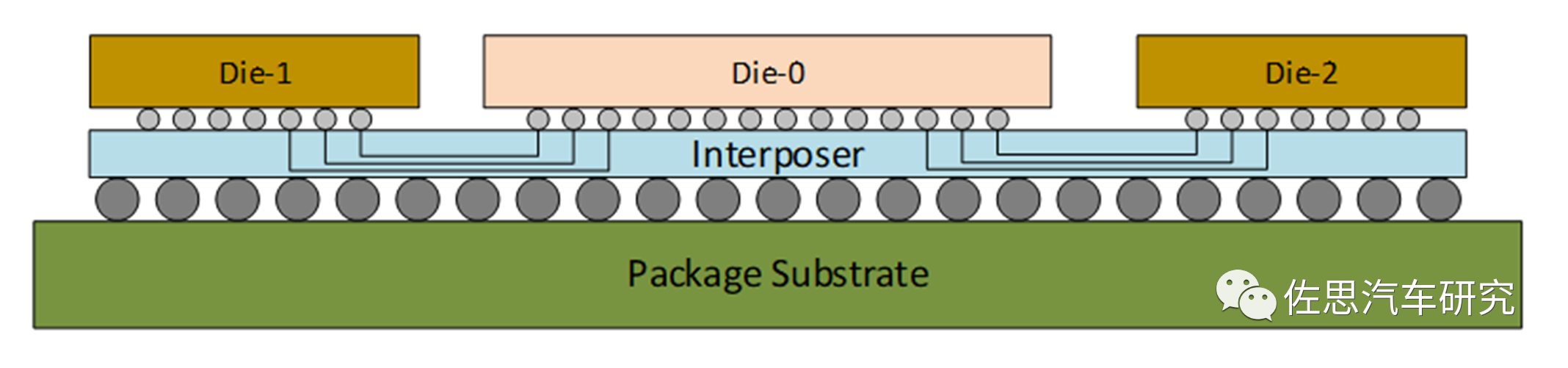
CoWoS
CoWoS-R:基于前述CoWoS-S技術,引入InFO技術中的RDL(RedistributionLayer),RDL 中介層由聚合物和銅跡線組成,具有相對機械柔韌性,而這種靈活性增強了封裝連接的可靠性,并允許新封裝可以擴大其尺寸以滿足更復雜的功能需求,從而有效支持多個Chiplets之間進行高速可靠互聯。
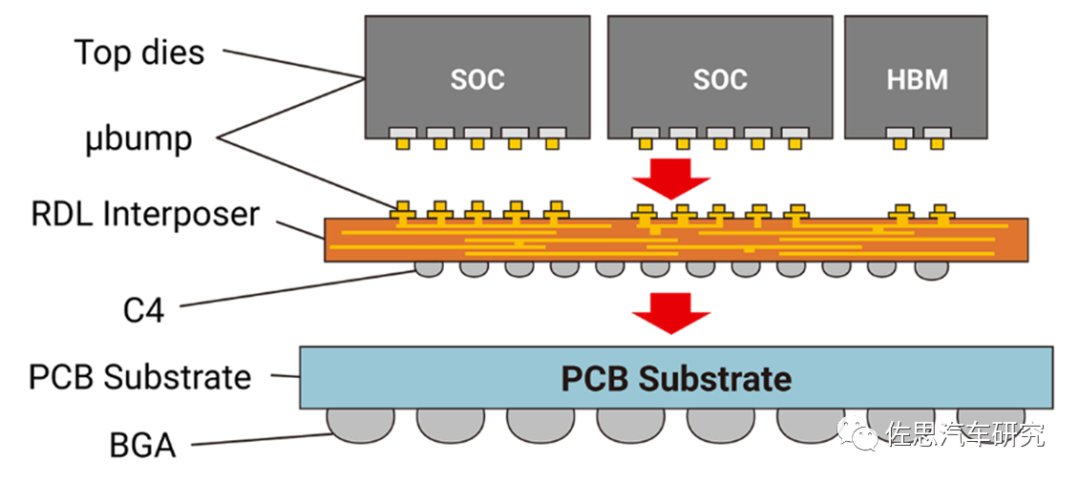
CoWoS-R
CoWoS-L:在上述CoWoS-S和InFO技術的基礎上,引入LSI(LocalSilicon Interconnect)技術,LSI 芯片在每個產品中可以具有多種連接架構(例如 SoC 到 SoC、SoC 到小芯片、SoC 到 HBM 等),也可以重復用于多個產品,提供更靈活和可復用的多芯片互聯架構。
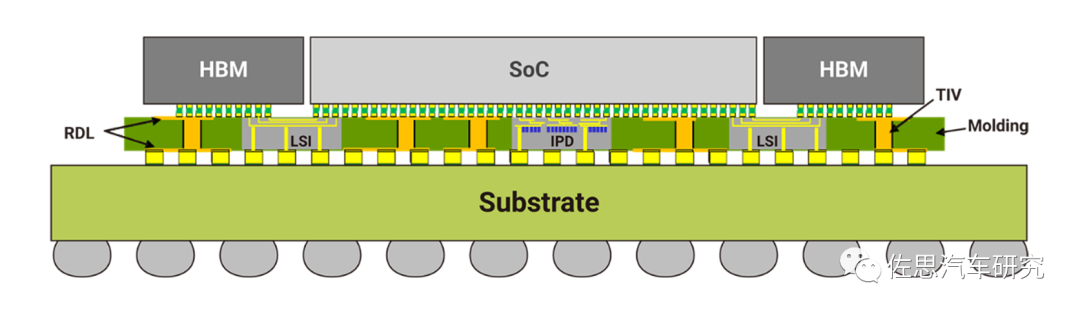
CoWoS-L
相比于MCM,CoWoS技術可以提供更高的互聯帶寬和更低的互聯延時,從而獲得更高的性能。同時,受限于interposer的尺寸(通常為2倍掩膜版最大尺寸),可以提供的封裝密度上限相對比較有限,并且由于interposer的引入,需要付出額外的制造成本和更高的技術復雜度,以及隨之而來的整體良率的降低。
3. EMIB(Embedded Multi-die Interconnect Bridge)

EMIB
EMIB是Intel主導的2.5D封裝技術,使用多個嵌入式包含多個路由層的橋接芯片,同時內嵌至封裝基板,達到高效和高密度的封裝。由于不再使用interposer作為中間介質,可以去掉原有連接至interposer所需要的TSVs,以及由于interposer尺寸所帶來的封裝尺寸的限制,可以獲得更好的靈活性和更高的集成度。 總體而言,相比于前述介紹的MCM、CoWoS和InFO/LSI技術,EMIB技術要更為優雅和經濟高效,獲得更高的集成度和制造良率。但是EMIB需要封裝工藝配合橋接芯片,技術門檻和復雜度較高。
Chiplet架構挑戰和洞察 基于Chiplet的架構設計,首先要考慮不同Chiplets之間如何進行功能劃分和架構定義,目前主流的設計思路大致可以分為兩類:
第一類
基于功能劃分到多個Chiplets,單個Chiplet不包含完整功能集合,通過不同Chiplets組合封裝實現不同類型的產品,典型代表為Huawei Lego架構(Kunpeng & Ascend)、AMD Zen2/3架構。
Huawei Lego架構:采用computedie(compute + memory interface)和I/O die組合的形式進行不同Chiplets功能拆解。在compute die(CPU/AI)設計時采用先進的工藝,獲得頂級的算力和能效,在I/O die設計時采用成熟工藝,在面積與先進工藝差別不大的情況下獲得成本收益。并且不同的Chiplets的數量和組合形式都可以靈活搭配,從而組合出多種不同規格的云端高性能處理器產品。
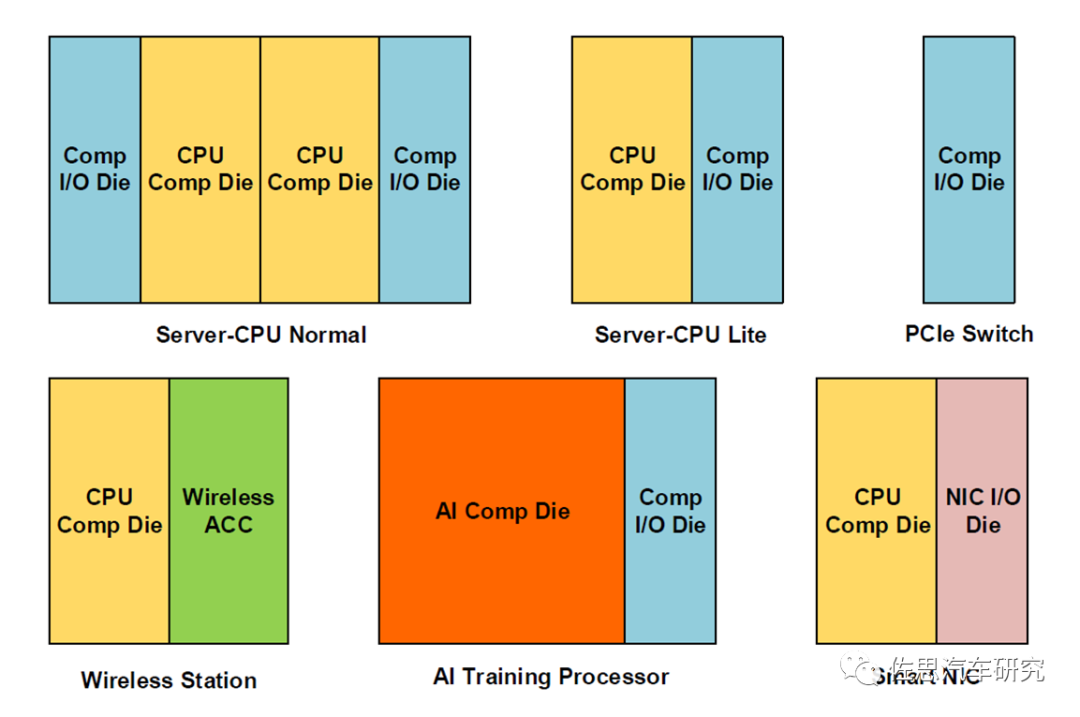
HuaweiLego
AMD Zen3架構:采用CCD(compute)和CIOD(memoryinterface + I/O)組合的形式進行不同Chiplets功能拆解。在CCD設計時采用最先進的工藝,獲得頂級的算力和能效,在CIOD設計時采用成熟工藝,在面積與先進工藝差別不大的情況下獲得成本收益。并且CCD本身按照兩個4C8T cluster組合的形式設計,可以適應AMD從Desktop到Server的架構需求,根據場景選擇CCD數量和設計對應的CIOD即可,靈活度非常高。
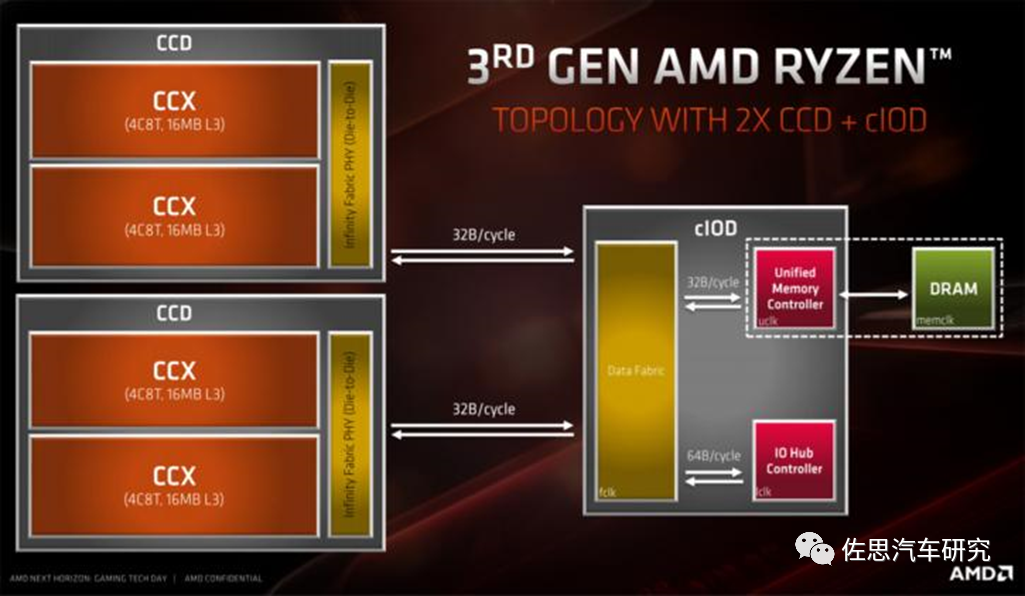
AMD Zen3
第二類
單個Chiplet包含較為獨立完整的功能集合,通過多個Chiplets級聯獲得性能的線性增長,典型代表為Apple M1 Ultra、Intel Sapphire rapids系列。
Apple M1 Ultra:通過Apple自研的封裝技術UltraFusion來堆疊兩顆M1 Max芯片,使得兩顆芯片之間擁有超過2.5TB/s帶寬且極低延時的互聯能力。基于這個互聯的延時帶寬能力,可以使得M1 Ultra直接獲得兩倍M1 Max的算力,同時在軟件層面依然可以將M1 Ultra當做一個完整芯片對待,而不會增加額外的軟件修改和調試的負擔。

AppleM1 Ultra
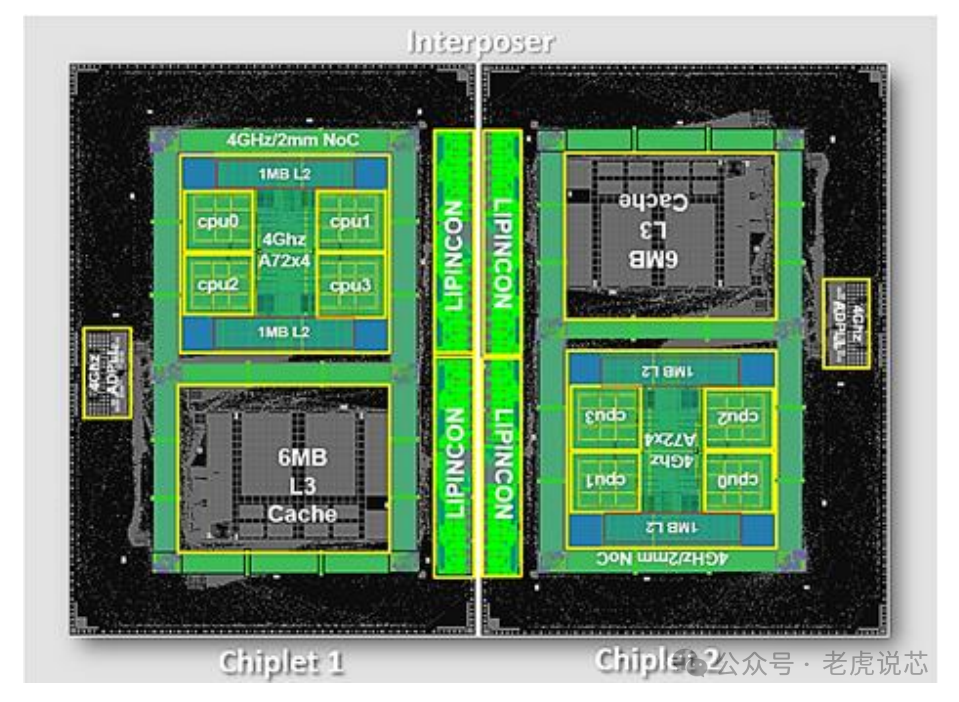
Intel Sapphire Rapids:通過兩組鏡像對稱的相同架構的building blocks,組合4個Chiplets,獲得4倍的性能和互聯帶寬。每個基本模塊包含計算部分(CHA & LLC & Coresmesh, Accelerators)、memory interface部分(controller, Ch0/1)、I/O部分(UPI,PCIe)。通過將上述高性能組件組成基本的building block,再通過EMIB技術進行Chiplet互聯,可以獲得線性性能提升和成本收益。
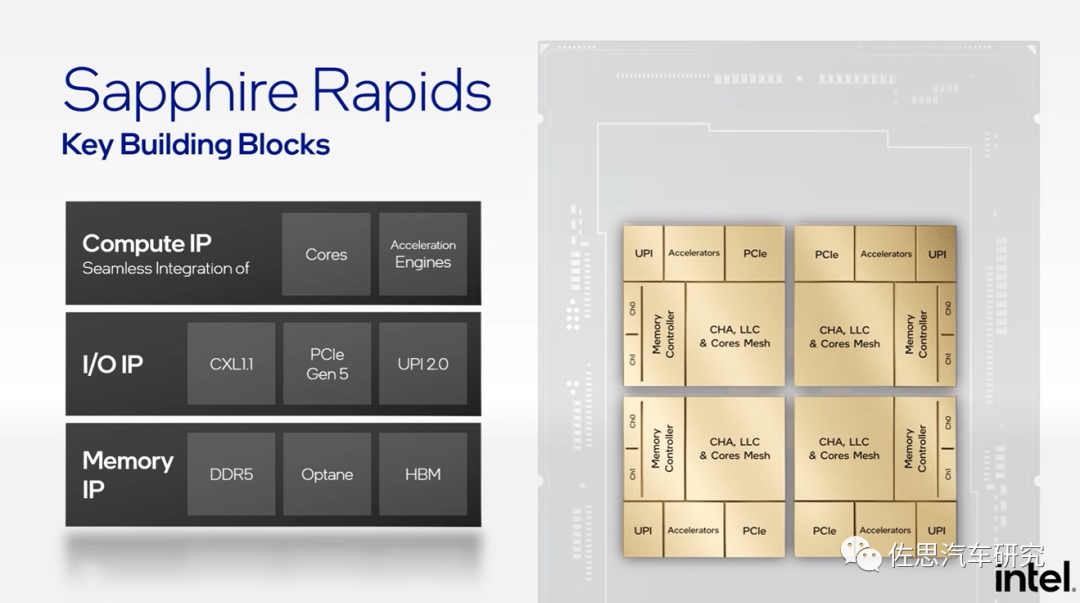
IntelSapphire Rapids
基于Chiplet的架構設計,同時要考慮多個Chiplets如何進行有效互聯和擴展,實現高效靈活可擴展的架構,避免多Chiplets之間出現信號死鎖、流量擁塞等功能和性能問題。由于芯片內部互聯通常為可靠連接假設下的并行數據傳輸,而芯片之間的互聯通常為不可靠連接假設下的串行數據傳輸,根據芯片片上和片間互聯架構的組合和流量收斂情況,目前主流的設計思路和應用場景大致分為兩大類:
第一類
片上片間相同架構,流量全打平或基本打平。典型代表如Cerebras,采用從tile到singledie到wafer scale engine完全相同的互聯架構。另一個典型代表是Tesla DoJo,采用InFO-SoW的封裝和芯片四邊全部放置I/O接口的方式實現片內每個方向10TBps帶寬,跨片每邊4TBps,SoW集成后單邊帶寬9TBps。
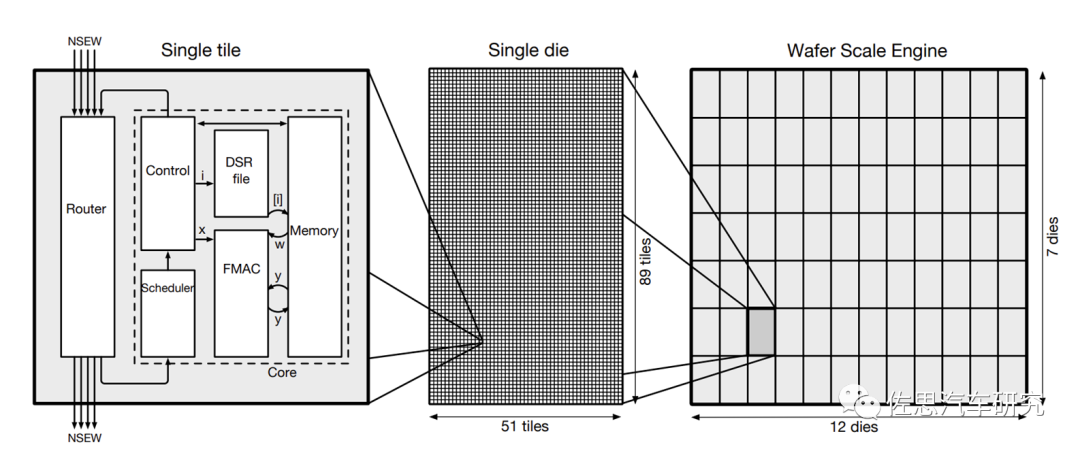
CS-1Wafer Scale Engine
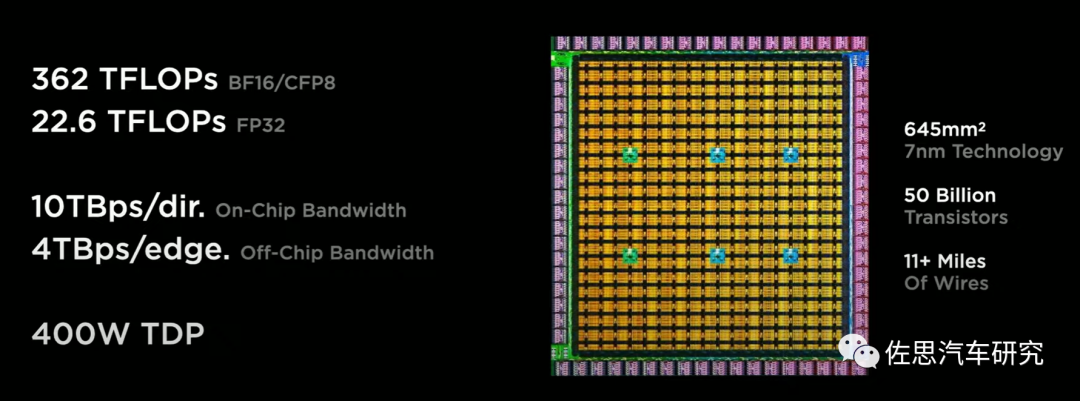
DoJoD1 Chip
第二類
片上片間架構相似,片間流量按照一定比例收斂。典型代表一個是前述的Huawei Bufferless Multi-Ring架構,片上流量會收斂到分布式的各個跨片接口;另一個典型代表是前述的Apple M1 Ultra,片上流量收斂到UltraFusion集中交換部分。
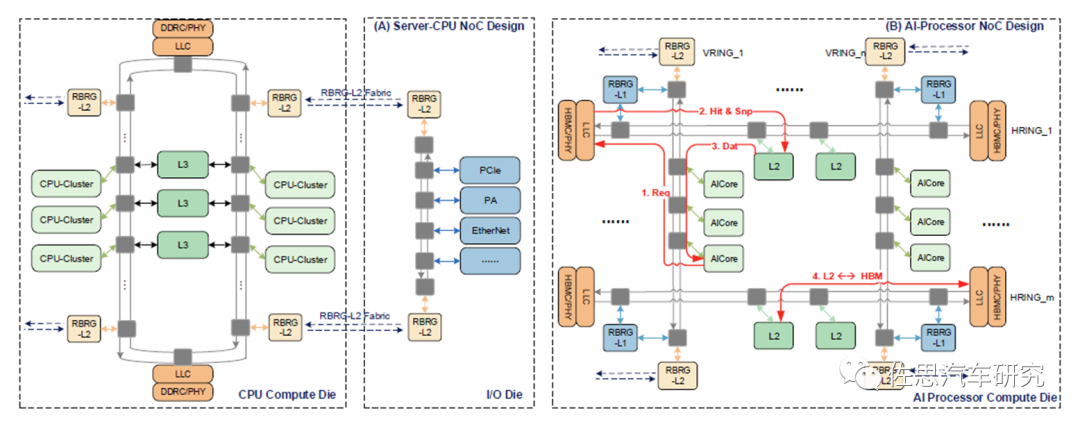
BufferlessMulti-Ring
從計算負載的角度,當單個計算任務計算密度較高,超出單芯片算力范圍的時候,需要多個芯片協同來完成,此時跨片數據交互也需要提供和片上數量級相當的帶寬和延時,才能更有效利用算力,提高計算效率。典型的任務類型是AI的訓練任務,前述Cerebras和DoJo的互聯架構對這類場景有較強優勢。當計算任務數量龐大,單個任務負載較小,跨片流量通常是要遠小于片上流量的,此時采用流量收斂策略更為合適。 從互聯架構的實現方式和實現策略角度,通常根據網絡的拓撲、路由策略、防死鎖機制等又可進一步細分,本文由于篇幅限制不再詳細介紹。
Chiplet協議介紹 工業界大約從2016年開始就在逐步嘗試基于Chiplet的芯片設計,經過長時間的摸索,已經在封裝工藝、架構設計上有了深厚的積累和長足的進步,在這樣的背景和契機之下,由Intel、AMD、ARM、ASE、Google、 Meta、Microsoft、Qualcomm、Samsung和TSMC共同開發和制定的UCIe 1.0在2022年3月正式推出。 UCIe標準的初衷和目標,是建立一套Chiplet技術相關的設計和制造等各個環節的參考標準,從而使得不同設計和制造廠商的芯片可以無縫集成,從而打造封裝層級的完整靈活的芯片開發生態系統。基于Chiplet技術和UCIe標準,可以實現超過單個掩膜版尺寸的芯片面積,獲得更大尺寸、更高集成度的高性能芯片。同時基于標準的UCIe,可以使能各類不同工藝和不同大小的芯片和IP在封裝層面進行集成,有效降低開發成本,同時減少開發周期。

Figure.Initial motivation of UCIe
UCIe主要規定的規格和標準包含以下幾個層面(具體內容本文不再贅述):
協議層:定義了高層級通信協議標準,初始版本采用成熟的PCIe加CXL協議。
中間層:定義了Chiplets之間的適配標準,包括Link狀態管理,參數對齊,信號的選擇校驗,以及可能的重傳機制。
物理層:定義了電氣信號連接的標準、物理鏈路設計標準,包括電氣信號定義,時鐘定義,Link和Sideband訓練。
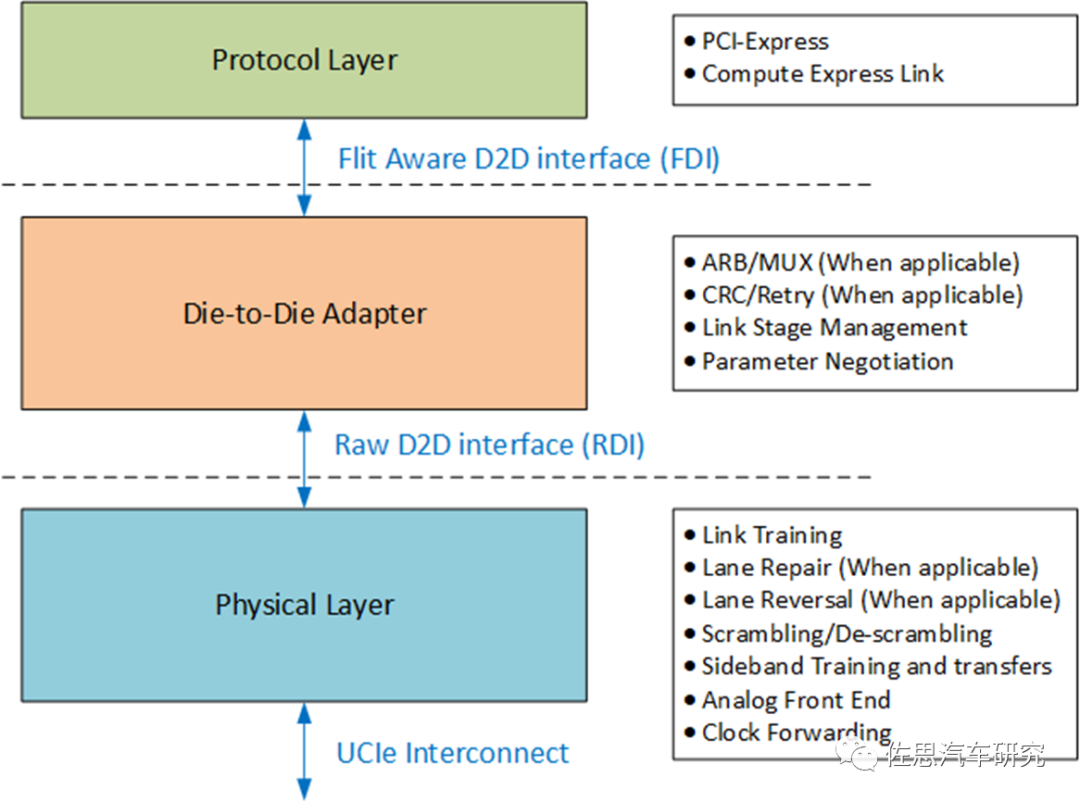
Figure.Layering with UCIe
總結 綜上所述,經過數年的發展,Chiplet技術已經逐漸走向成熟和商用,成為芯片廠商比較依賴的技術手段,也被認為是未來芯片行業發展的重要方向。目前在底層封裝層面,已經有TSMC、Intel等廠商提供CoWOS、EMIB等先進封裝,可以提供超高速、超高密度和超低延時的Chiplet互聯;在標準協議層面,也有眾多大廠領銜發布的UCIe 1.0版本,提供了跨片接口設計的指導和約束。而在架構設計層面,如何基于Chiplet設計高性能、高效率、靈活可擴展的互聯架構,如何基于實現和商業視角進行芯片間的功能劃分仍然是Chiplet技術中最大的挑戰。
Reference:
https://3dfabric.tsmc.com/english/dedicatedFoundry/technology/3DFabric.htm
https://ase.aseglobal.com/public/en/technology/focos.html
https://www.intel.com/content/www/us/en/silicon-innovations/6-pillars/emib.html
S. Naffziger, K. Lepak, M. Paraschou, and M. Subramony, “2.2 amd chiplet architecture for high-performance server and desktop products,” in 2020 IEEE International Solid-State Circuits Conference-(ISSCC). IEEE, 2020, pp. 44–45
A. Biswas, “Sapphire rapids,” in 2021 IEEE Hot Chips 33 Symposium (HCS). IEEE Computer Society, 2021, pp. 1–22.
T. Wang, F. Feng, S. Xiang, Q. Li and J. Xia, "Application Defined On-chip Networks for Heterogeneous Chiplets: An Implementation Perspective," 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2022, pp. 1198-1210, doi: 10.1109/HPCA53966.2022.00091.
https://www.apple.com/tn/newsroom/2022/03/apple-unveils-m1-ultra-the-worlds-most-powerful-chip-for-a-personal-computer/
Rocki, Kamil, et al. "Fast stencil-code computation on a wafer-scale processor." SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020.
https://www.youtube.com/watch?v=j0z4FweCy4M
Parasar, Mayank, et al. "Swap: Synchronized weaving of adjacent packets for network deadlock resolution." Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture. 2019.
Yin, Jieming, et al. "Modular routing design for chiplet-based systems." 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2018.
https://www.uciexpress.org/specification
Xia, Jing, et al. "Kunpeng 920: The first 7-nm chiplet-based 64-Core ARM SoC for cloud services." IEEE Micro 41.5 (2021): 67-75.
https://www.anandtech.com/Gallery/Album/8123#3
審核編輯 :李倩
-
半導體
+關注
關注
334文章
27290瀏覽量
218099 -
摩爾定律
+關注
關注
4文章
634瀏覽量
79002 -
封裝技術
+關注
關注
12文章
548瀏覽量
67981 -
chiplet
+關注
關注
6文章
431瀏覽量
12585
原文標題:Chiplet:大算力的翅膀
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Chiplet在先進封裝中的重要性
先進封裝技術-7扇出型板級封裝(FOPLP)
先進封裝技術- 6扇出型晶圓級封裝(FOWLP)

Chiplet技術有哪些優勢
最新Chiplet互聯案例解析 UCIe 2.0最新標準解讀

IMEC組建汽車Chiplet聯盟

Primemas選擇Achronix eFPGA技術用于Chiplet平臺
Rapidus與IBM合作研發小芯片封裝技術
高端性能封裝技術的某些特點與挑戰
易卜半導體創新推出Chiplet封裝技術,彌補國內技術空白,助力高算力芯片發展
什么是Chiplet技術?
Chiplet技術對英特爾和臺積電有哪些影響呢?

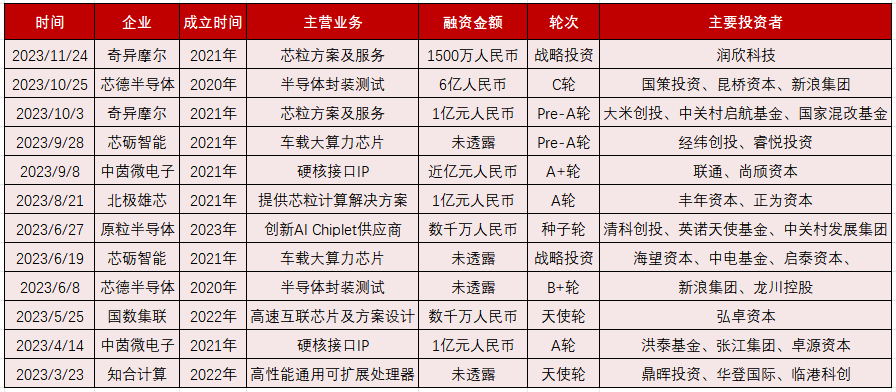
2023年Chiplet發展進入新階段,半導體封測、IP企業多次融資





 工商網監
工商網監
評論