


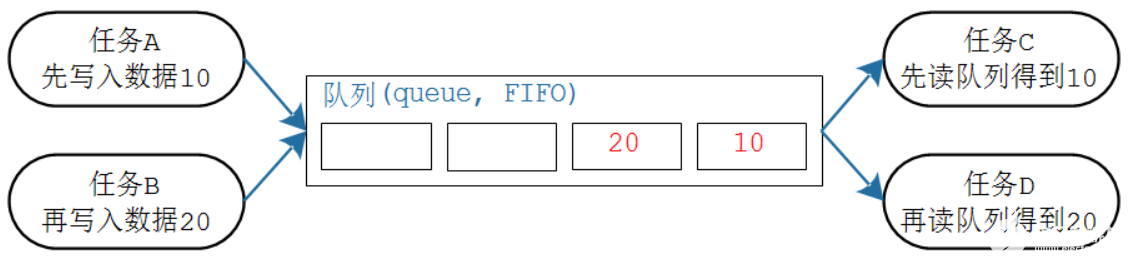
隊列-Queue
FIFO(先入先出)隊列Queue,LIFO(后入先出)隊列LifoQueue,和優先級隊列PriorityQueue。
常用方法:
Queue.qsize() 返回隊列的大小
Queue.empty() 如果隊列為空,返回True,反之False
Queue.full() 如果隊列滿了,返回True,反之False,Queue.full 與 maxsize 大小對應
Queue.get(item) 獲取隊列
Queue.get_nowait() 相當于Queue.get(False),非阻塞方法
Queue.put(item) 寫入隊列
Queue.task_done() 在完成一項工作之后,Queue.task_done()函數向任務已經完成的隊列發送一個信號。每個get()調用得到一個任務,接下來task_done()調用告訴隊列該任務已經處理完畢。
Queue.join() 實際上意味著等到隊列為空,再執行別的操作
Queue隊列方法主要用于我們的進程間的通信。
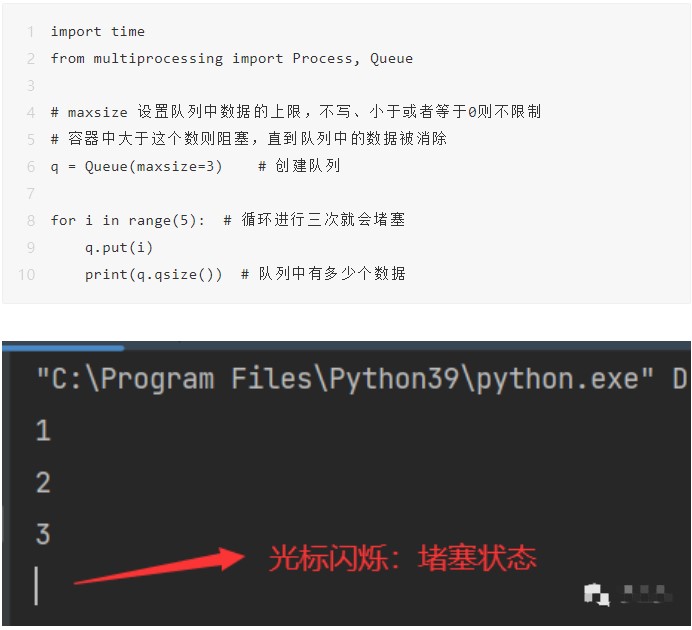

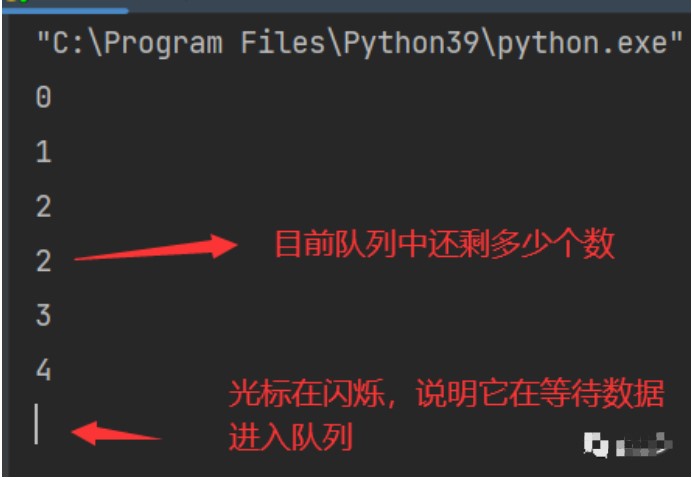
進程中的通信一個最主要的用途就是用于日后的爬蟲,當我們需要爬取5000個網頁的時候,我們需要從瀏覽器首頁獲取所有的靜態資源(檢查網頁代碼),然后再通過內容提取來提取出其中的URL(全局資源定位符),比如:www.baidu.com,這就和生產者消費者模型很相似。
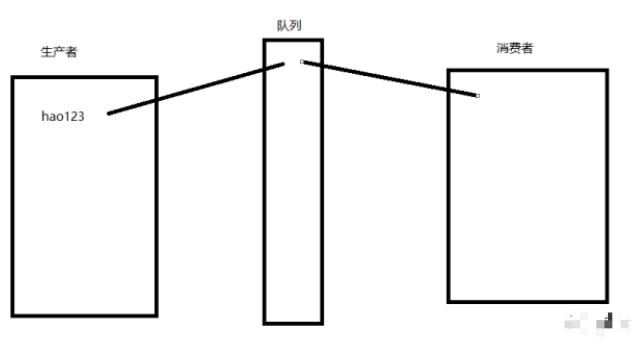
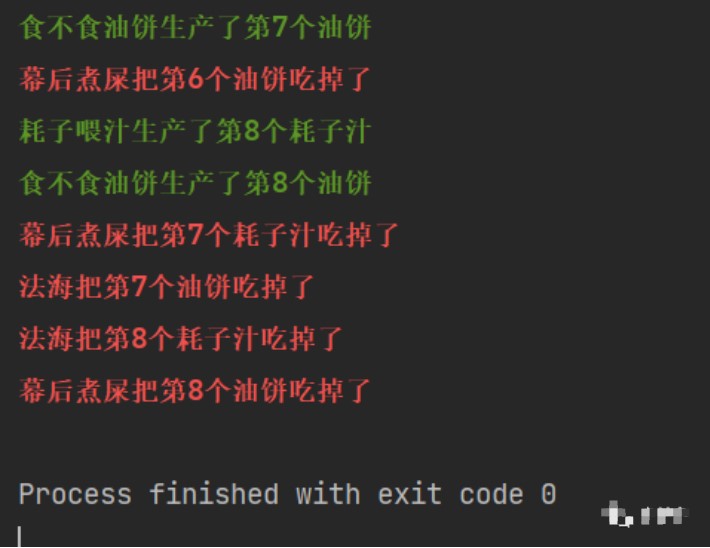
我們來簡單實現"生產者消費者模型":


進程池-Pool
一、什么是進程池?
在程序實際處理問題過程中,忙時會有成千上萬的任務需要被執行,閑時可能只有零星任務。那么在成千上萬個任務需要被執行的時候,我們就需要去創建成千上萬個進程么?首先,創建進程需要消耗時間,銷毀進程也需要消耗時間。第二即便開啟了成千上萬的進程,操作系統也不能讓他們同時執行,這樣反而會影響程序的效率。因此我們不能無限制的根據任務開啟或者結束進程。那么我們要怎么做呢?
進程池就是先定義一個池子,在里面放上固定數量的進程,有需求來了,就拿一個池中的進程來處理任務,等到處理完畢,進程并不關閉,而是將進程再放回進程池中繼續等待任務。如果有很多任務需要執行,池中的進程數量不夠,任務就要等待之前的進程執行任務完畢歸來,拿到空閑進程才能繼續執行。也就是說,池中進程的數量是固定的,那么同一時間最多有固定數量的進程在運行。這樣不會增加操作系統的調度難度,還節省了開閉進程的時間,也一定程度上能夠實現并發效果。
二、程序類型
我們的程序有兩種:計算密集型、IO密集型
計算密集型:充分利用CPU,多線程可以充分利用多核(適合開啟多進程,但不適合開啟很多)
IO密集型:大部分的時間都在阻塞隊列,而不是在運行狀態(根本不適合開啟多進程)

信號量和多進程的處理方式的差異在于,每n個信號量是同步的,也就是說,如果只設置了4個信號量,4個用戶先搶占了CPU,那剩余的496個任務量需要等待前面4個用戶完成了(100%)之后才能夠繼續進行。而多進程是異步的,但是由于計算機的CPU有限,采用時間片輪轉法進行分配工作,所有的進程都有機會同時開始任務,但一段(細微)時間后,時間片就會分配給其他進程,這樣宏觀上看起來它是同時進行的,但其中涉及到了非常多的計算機的進程調度,但是信號量和多進程的處理時間需要視情況而定。
進程池在面對這種(做500件衣服)計算密集型的程序時具有非常高的效率,使用進程池不涉及進程調度,也就不浪費時間,屬于流水線式24h晝夜不息工作模式,做完一件衣服立馬就會接手第二件、第三件......這種方式充分地利用了CPU,不會在創建進程、進程調度、銷毀進程中浪費時間。



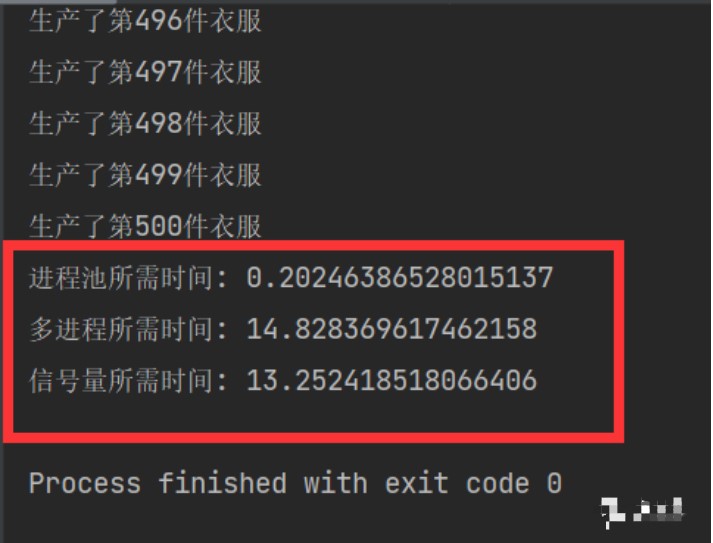
從結果來看,我們可以發現,進程池的速度與多進程和信號量比起來那是相當的哇塞。所以該用哪種方法不用多說了吧。
審核編輯:劉清
-
cpu
+關注
關注
68文章
11090瀏覽量
217345 -
fifo
+關注
關注
3文章
402瀏覽量
44853 -
URL
+關注
關注
0文章
141瀏覽量
15877 -
進程
+關注
關注
0文章
207瀏覽量
14298
發布評論請先 登錄
韋東山freeRTOS系列教程之隊列(queue)(5)
Linux下進程通訊消息隊列
RAW queue 篇
Queue隊列的作用是什么
消息隊列Queue相關資料推薦
網絡中常用的隊列管理方法比較
Java多線程總結之Queue
ThreadX(九)------消息隊列Queue

STM32G0開發筆記:使用FreeRTOS系統的隊列Queue
用隊列實現棧的兩種方法
OpenHarmony語言基礎類庫【@ohos.util.Queue (線性容器Queue)】





 工商網監
工商網監

評論