
一、簡介
在UIE出來以前,小樣本NER主要針對的是英文數據集,目前主流的小樣本NER方法大多是基于prompt,在英文上效果好的方法,在中文上不一定適用,其主要原因可能是:
中文長實體相對英文較多,英文是按word進行切割,很多實體就是一個詞;邊界相對來說更清晰;
生成方法對于長實體來說更加困難。但是隨著UIE的出現,中文小樣本NER 的效果得到了突破。
二、主流小樣本NER方法
2.1、EntLM
EntLM該方法核心思想:拋棄模板,把NER作為語言模型任務,實體的位置預測為label word,非實體位置預測為原來的詞,該方法速度較快。模型結果圖如圖2-1所示:
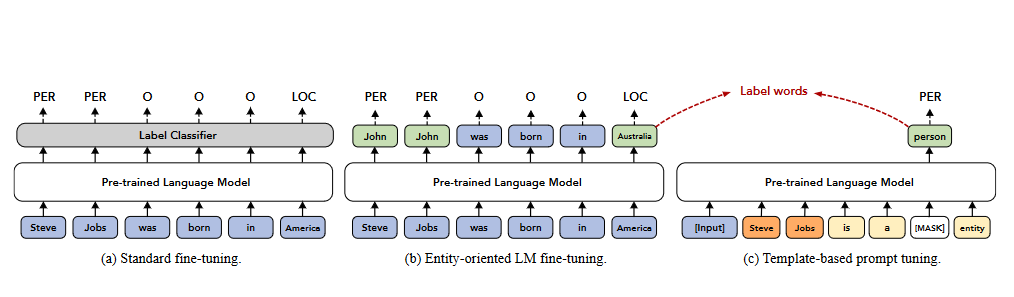 圖2-1 EntLM模型
圖2-1 EntLM模型
論文重點在于如何構造label word:在中文數據上本實驗做法與論文稍有區別,但整體沿用論文思想:下面介紹了基于中文數據的標簽詞構造過程;
采用領域數據構造實體詞典;
基于實體詞典和已有的實體識別模型對中文數據(100 000)進行遠程監督,構造偽標簽數據;
采用預訓練的語言模型對計算LM的輸出,取實體部分概率較高的top3個詞;
根據偽標簽數據和LM的輸出結果,計算詞頻;由于可能出現在很多類中都出現的高頻標簽詞,因此需要去除沖突,該做法沿用論文思想;
使用均值向量作為類別的原型,選擇top6高頻詞的進行求平均得到均值向量;
2.2、TemplateNER
TemplateNER的核心思想就是采用生成模型的方法來解決NER問題,訓練階段通過構造模板,讓模型學習哪些span是實體,哪些span不是實體,模板集合為:$T=[T+,T+ ...T+,T-]$,T+為xx is aentity,T-為 xx is not aentity,訓練時采用目標實體作為正樣本,負樣本采用隨機非實體進行構造,負樣本的個數是正樣本的1.5倍。推理階段,原始論文中是 n-gram 的數量限制在 1 到 8 之間,作為實體候選,但是中文的實體往往過長,所以實驗的時候是將,n-gram的長度限制在15以內,推理階段就是對每個模板進行打分,選擇得分最大的作為最終實體。
這篇論文在應用中的需要注意的主要有二個方面:
模板有差異,對結果影響很大,模板語言越復雜,準確率越低;
隨著實體類型的增加,會導致候選實體量特別多,訓練,推理時間更,尤其在句子較長的時候,可能存在效率問題,在中文數據中,某些實體可能涉及到15個字符(公司名),導致每個句子的候選span增加,線上使用困難,一條樣本推理時間大概42s
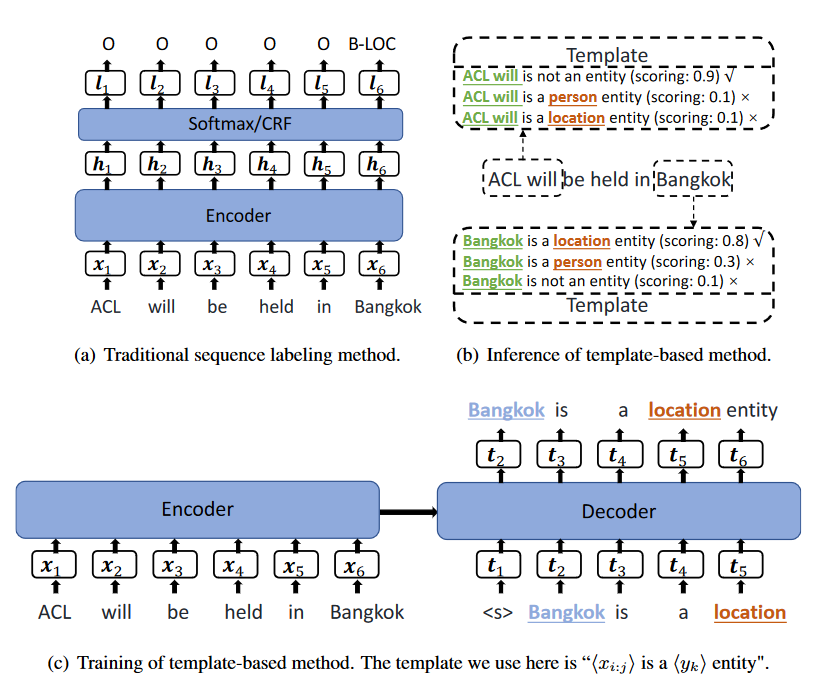 圖2-2 TemplateNER抽取模型
圖2-2 TemplateNER抽取模型
2.3、LightNER
LightNER的核心思想采用生成模型進行實體識別,預訓練模型采用 BART通過 prompt 指導注意力層來重新調整注意力并適應預先訓練的權重, 輸入一個句子,輸出是:實體的序列,每個實體包括:實體 span 在輸入句子中的 start index,end index ,以及實體類型 ,該方法的思想具有一定的通用性,可以用于其他信息抽取任務。
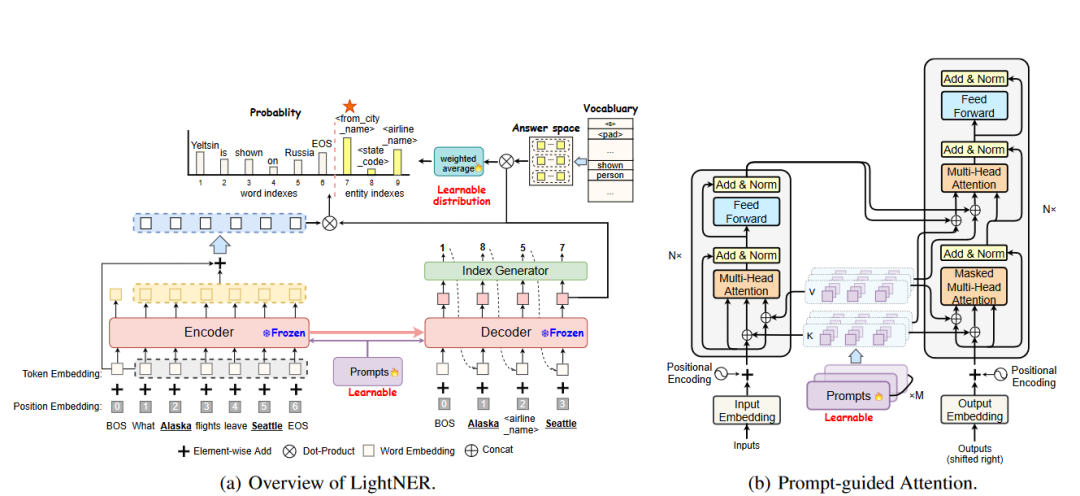 圖2-3 LightNER抽取模型
圖2-3 LightNER抽取模型
2.4、UIE
UIE(通用信息抽取框架)真正的實現其實是存在兩個版本,最初是中科院聯合百度發的ACL2022的一篇論文,Unified Structure Generation for Universal Information Extraction,這個版本采用的是T5模型來進行抽取,采用的是生成模型,后來百度推出的UIE信息抽取框架,采用的是span抽取方式,直接抽取實體的開始位置和結束位置,其方法和原始論文并不相同,但是大方向相同。
輸入形同:UIE采用的是前綴prompt的形式,采用的是Schema+Text的形式作為輸入,文本是NER任務,所以Schema為實體類別,比如:人名、地名等。
采用的訓練形式相同,都是采用預訓練加微調的形式
不同點:
百度UIE是把NER作為抽取任務,分別預測實體開始和結束的位置,要針對schema進行多次解碼,比如人名進行一次抽取,地名要進行一次抽取,以次類推,也就是一條文本要進行n次,n為schema的個數,原始UIE是生成任務,一次可以生成多個schema對應的結果
百度UIE是在ernie基礎上進行預訓練的,原始的UIE是基于T5模型。
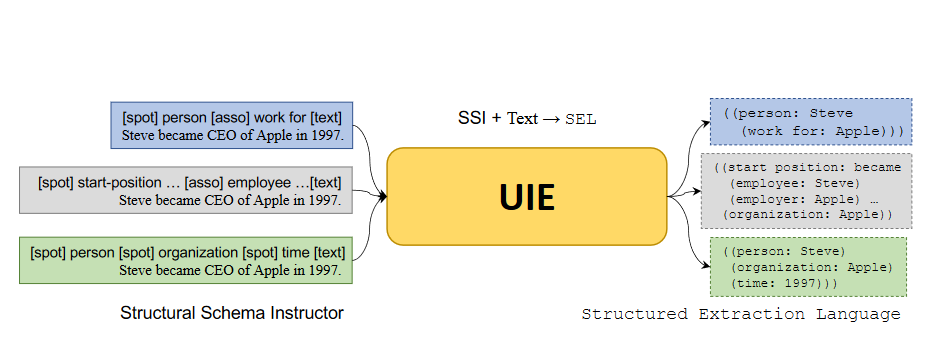 圖2-4 UIE抽取模型
圖2-4 UIE抽取模型
三、實驗結果
該部分主要采用主流小樣本NER模型在中文數據上的實驗效果。
通用數據1測試效果:
| Method | 5-shot | 10-shot | 20-shot | 50-shot |
|---|---|---|---|---|
| BERT-CRF | - | 0.56 | 0.66 | 0.74 |
| LightNER | 0.21 | 0.42 | 0.57 | 0.73 |
| TemplateNER | 0.24 | 0.44 | 0.51 | 0.61 |
| EntLM | 0.46 | 0.54 | 0.56 | - |
從實驗結果來看,其小樣本NER模型在中文上的效果都不是特別理想,沒有達到Bert-CRF的效果,一開始懷疑結果過擬了,重新換了測試集,發現BERT-CRF效果依舊變化不大,就是比其他的小樣本學習方法好。
3.1、UIE實驗結果
UIE部分做的實驗相對較多,首先是消融實驗,明確UIE通用信息抽取的能力是因為預訓練模型的原因,還是因為模型本身的建模方式讓其效果好,其中,BERTUIE,采用BERT作為預訓練語言模型,pytorch實現,抽取方式采用UIE的方式,抽取實體的開始和結束位置。
領域數據1測試結果(實體類型7類):
| 預訓練模型 | 框架 | F1 | Epoch |
|---|---|---|---|
| Ernie3.0 | Paddle | 0.71 | 200 |
| Uie-base | paddle | 0.72 | 100 |
| BERT | pytorch | 0.705 | 30 |
從本部分實驗可以確定的是,預訓練模型其實就是一個錦上添花的作用, UIE的本身建模方式更重要也更有效。
領域數據1測試結果(實體類型7類):
| 5-shot | 10-shot | 20-shot | 50-shot | |
|---|---|---|---|---|
| BERT-CRF | 0.697 | 0.75 | 0.82 | 0.85 |
| 百度UIE | 0.76 | 0.81 | 0.84 | 0.87 |
| BERTUIE | 0.73 | 0.79 | 0.82 | 0.87 |
| T5(放寬后評價) | 0.71 | 0.75 | 0.79 | 0.81 |
領域數據3測試效果(實體類型6類),20-shot實驗結果:
| BERT-CRF | LightNER | EntLM | 百度UIE | BERTUIE | |
|---|---|---|---|---|---|
| F1 | 0.69 | 0.57 | 0.58 | 0.72 | 0.69 |
UIE在小樣本下的效果相較于BERT-CRF之類的抽取模型要好,但是UIE的速度較于BERT-CRF慢很多,大家可以根據需求決定用哪個模型。如果想進一步提高效果,可以針對領域數據做預訓練,本人也做了預訓練,效果確實有提高。
-
百度
+關注
關注
9文章
2311瀏覽量
91333 -
語言模型
+關注
關注
0文章
552瀏覽量
10512 -
數據集
+關注
關注
4文章
1217瀏覽量
25100
原文標題:中文小樣本NER模型方法總結和實戰
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
[討論]提高網站關鍵詞排名的28個SEO小技巧
關鍵詞優化有哪些實用的方法
中文分詞研究難點-詞語切分和語言規范
開發語音產品時設計喚醒詞和命令詞的技巧
量子Fourier變換構造FQT電路
基于強度熵解決中文關鍵詞識別
基于標簽優先的抽取排序方法





 工商網監
工商網監

評論