


自然語言處理(簡稱NLP)被譽為“人工智能皇冠上的明珠”、“實現(xiàn)通用人工智能(AGI)的鑰匙”。
當自然語言處理技術(shù)遇到司法系統(tǒng),會擦出怎樣的火花?
在這里先跟大家分享一個“常識”:
據(jù)我國的法律,給出的量刑大都是一個區(qū)間,而不是具體值,比如判刑3年到5年。
那么究竟是3年、4年還是5年,需要法官對具體問題進行具體分析。
其出發(fā)點是好的,但實際卻讓一些經(jīng)驗欠缺的法官左右為難:判久了對被告不利,判的時間不足對受害者又不夠公平。
不過現(xiàn)在嘛,法官的這個煩惱可以先放放了,因為有一項AI前來“搭把手”。
這個AI背后的主要技術(shù),其實就是自然語言處理,它可以提取出當前案件中的諸多要素,將其和其他類似案件的要素作對比,最終分析得出具體建議值。
NLP技術(shù)在司法領(lǐng)域的應(yīng)用
事實上,除了能夠輔助法官量刑外,現(xiàn)在“NLP+司法”的應(yīng)用已不勝枚舉。
因為司法系統(tǒng)的構(gòu)造可不簡單:它包括公安、檢察院、法院、司法局、律師,當然還有民眾。
對于不同的群體和場景,需要采用不同的方案和技術(shù)。
例如,在庭審場景下,有AI幫忙做筆錄那就省事兒多了,還可以大幅提升庭審效率。
于是“語音識別自動生成庭審筆錄”不就來了嗎?
目前,科大訊飛的語音識別自動生成庭審筆錄已經(jīng)覆蓋了29個省份的法庭,平均使庭審時長縮短了30%,為復(fù)雜庭審縮短時長還達到了50%。
此外,對公安、檢察院、法院比較熟悉的朋友可能知道,很多案件都有厚厚一疊卷宗,手動編目、分類費時費力,現(xiàn)在這種活兒也可以交給AI來處理了,文字OCR技術(shù)在這里大顯身手。
編目完成后,還有重頭戲:閱卷。當然,AI又被派上了用場,它可以輔助辦案人員閱讀卷宗,例如:要素索取、結(jié)果呈現(xiàn)。
然后到了案件中至關(guān)重要的一部分:證據(jù)。
事實上,證詞和線索往往都來自不同的個體,很多時候都會不出現(xiàn)證據(jù)不一致等情況,為此讓人工分析推理,是件非常淘神費力的事情。
而AI現(xiàn)在可以輔助辦案人員校驗證據(jù)了,具體來說,就是AI單個人提供的筆錄等進行校驗,并且對不同人給出的信息進行對比、矛盾審查。
這背后涉及到實體識別、指代消解、語義角色和依存關(guān)系分析等NLP技術(shù)延伸出來的方法。
對于上述提到的卷宗、筆錄等法律文本,AI還能自動發(fā)現(xiàn)文本中的錯別字詞和語法錯誤。
為實現(xiàn)這樣的效果,訊飛采用了BERT中文全詞Mask(BERT-Chinese-wwm)模型,這是一個哈工大和訊飛聯(lián)合發(fā)布的全詞覆蓋中文BERT預(yù)訓練模型。
除此之外,面向普通大眾,訊飛還發(fā)布了法律自動問答AI助手“法小飛”;還有基于案情的律師推薦AI等。
以上,都是科大訊飛副總裁、AI研究院副院長,北京研究院院長王士進分享的訊飛“NLP+司法”案例。
NLP的進展與挑戰(zhàn)
前文展示了“NLP+司法”的應(yīng)用,下面就NLP這項技術(shù)展開談?wù)劇?/p>
在本部分正式開始前,先來看一段有趣的對話吧(據(jù)說這是道外國人中文語言水平考試題):
B:沒什么意思,意思意思。 A:你這樣就沒意思了。 B:哎呀,小意思,小意思。 A:你這人可真有意思。 B:哎呀,其實也沒有別的意思。 A:那我就不好意思了。 B:是我不好意思。
請問這里的“意思”都是什么意思?(Doge)
其實,這里的“意思”二字可以看作一個符號,這個符號背后承載的信息非常豐富。
一詞多義、多詞一義等問題,本質(zhì)上是形式和背后含義之間存在多對多的映射關(guān)系的問題,或者可以理解成在一個廣闊空間內(nèi)進行搜索的問題。
我們認為,怎么處理好這些關(guān)系,是自然語言處理的最核心的困難。
哈爾濱工業(yè)大學教授、人工智能研究院副院長車萬翔如是說道。
但如果沒有任何限制,在一個非常大的空間內(nèi)進行搜索,其復(fù)雜性相當高。這個該怎么解決?
車教授介紹稱,一般是用“知識”進行約束,這里打雙引號的原因是:提到知識,一般會認為是某些規(guī)則、邏輯、符號知識;而這里指的是更廣義的知識。
廣義的知識有多種分類法,這里主要將其分為3種來源。
其一,就是狹義的知識,包括語言、常識(很難從文本中挖到)和世界知識(可以從文本中挖到),世界知識可以拿知識圖譜等來表示。
其三,是數(shù)據(jù),包括有標注的、無標注的數(shù)據(jù)和偽數(shù)據(jù)。當下爆火的預(yù)訓練模型就使用了大量的未標注數(shù)據(jù)。
首先可通過未標注數(shù)據(jù)預(yù)訓練一個模型;接著用語料庫去精調(diào)這個模型,從而使目標模型變得更強大。
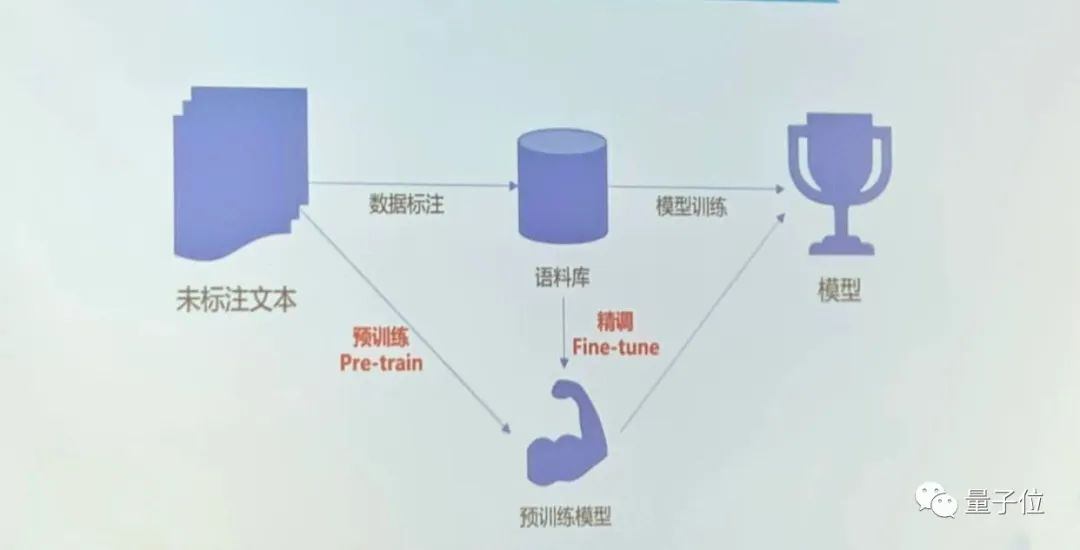
當下普遍認為,對于幾乎所有AI系統(tǒng),如果沒有新的知識、算法或數(shù)據(jù)輸入,這個系統(tǒng)本身很難提高。
當然也有人提出,怎么感覺有例外——比如DeepMind的AI棋手AlphaZero,就是通過自我博弈來學習精進的。
對此,車教授解釋道,這種游戲場景比較特殊,因為它本身是一個封閉的系統(tǒng),能夠下棋的位置畢竟有限,且還有人為制定的勝負標準,所以在條條框框之下,機器自由發(fā)揮的空間并不算特別大。
但像NLP就不一樣了,哪句話說得好,哪句話說得不好,其實沒有一個明確的判定標準,這種情況下,左右博弈就沒有奇效了。
說到這里,現(xiàn)在 NLP用到了知識、算法和數(shù)據(jù),那NLP之后還會朝哪個方向發(fā)展?或者說,NLP下一步還會用到什么?
要回答這個問題,不妨先縱觀一下人工智能自1956年誕生以來的發(fā)展簡史。(你就會發(fā)現(xiàn)一些有意思的規(guī)律)
上世紀50年代至上世紀90年代期間,主要關(guān)注的是小規(guī)模專家知識;從上世紀90年代到2011年前后,更關(guān)注的是算法設(shè)計;從2010年到2017年,迎來了深度學習的熱潮,數(shù)據(jù)的重要性愈發(fā)凸顯。
而自2018年谷歌推出BERT至今,大規(guī)模預(yù)訓練模型成了當下熱詞。
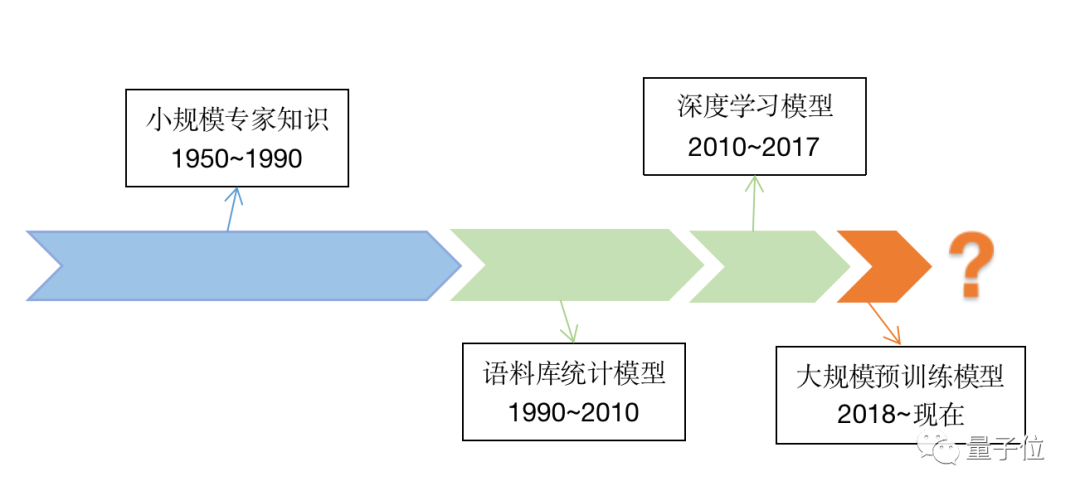
不難發(fā)現(xiàn),此前,后一個階段的時間幾乎是前一階段的一半,所以……(手動狗頭)
說回大規(guī)模預(yù)訓練模型,車教授指出,當前大模型的“同質(zhì)化”趨勢越來越明顯,當然這可不是什么不好的事,我們可以用“通用性”來理解。
無論是 NLP 任務(wù)還是CV任務(wù)等,現(xiàn)在都有一套“萬金油”模型:Transformer,基本可以統(tǒng)一解決很多問題。此外,現(xiàn)在模型的規(guī)模越來越大,而且模型的表現(xiàn)和其規(guī)模確實呈正相關(guān)。所有有觀點認為,隨著模型規(guī)模的增大,還可能會涌現(xiàn)出令人驚訝的AI。正如俗話所說:量變引起質(zhì)變。
車教授表示,模型的“同質(zhì)化”和“規(guī)模化”趨勢是不可逆轉(zhuǎn)的,未來還會繼續(xù)這樣走下去。
至于NLP目前遇到的問題,其實也算是人工智能發(fā)展過程中的問題,比如說易用性、高效性、魯棒性、可解釋性、推理能力等。(篇幅有限,這里就先不展開了)
車教授提出,未來可能除了數(shù)據(jù)外,還會使用更廣泛的“知識”,而這種“知識”的來源可以被概括成“體驗”,體驗來自于人機交互等場景。
NLP相關(guān)問題更多探討
圍繞自然語言處理的機遇和挑戰(zhàn),幾位學界和企業(yè)界的大佬展開了一場主題Panel。
大模型的工業(yè)實用前景
首先,縱觀前沿科技和當今的工業(yè)界不難發(fā)現(xiàn),雖然自2020年GPT-3誕生以來,大模型的參數(shù)已達千億級別;但在工業(yè)實操中,尚未看到超大模型的廣范應(yīng)用。
其中一個重要的原因是,大模型的訓練數(shù)據(jù)和一些工業(yè)領(lǐng)域的真實數(shù)據(jù)差別明顯。
大模型的實用前景到底如何目前十分具有爭議——有樂觀者認為:未來大模型也能成為NLP 的基礎(chǔ)模型;也有消極的觀點表示:這更像各巨頭集合算法算力、大數(shù)據(jù)等優(yōu)勢搞的一個軍備競賽而已。
現(xiàn)場的幾位專家對大模型的實用前景都未持消極態(tài)度,不過他們的具體想法也不盡相同。
學術(shù)界這邊,中國科學院自動化研究所的劉康研究員發(fā)言稱:
大模型確實是個好東西,但與其把大模型看成一種資源,不如把它看成一種技術(shù)規(guī)范、一種工具。
比如,在一些小數(shù)據(jù)場景下,能夠快速把已有的一些知識經(jīng)驗遷移到新的任務(wù)。就像人拿到一個不會用新產(chǎn)品時,通過閱讀產(chǎn)品說明書,然后就很快學會使用該產(chǎn)品了。
清華大學副教授劉知遠的研究方向之一就是大模型。他指出,一方面,在實踐中發(fā)現(xiàn),中文的數(shù)據(jù)質(zhì)量比英文的差太多。
這不僅是規(guī)模問題,數(shù)據(jù)質(zhì)量也不太行。最終效果就是,在實際訓練過程中,對中文素材去完重、去完垃圾后,所剩的數(shù)據(jù)非常有限。
所以,如何為模型訓練收集更多高質(zhì)量的中文數(shù)據(jù),是個重要議題,也是一件任重道遠的事兒。
另一方面,劉知遠教授認為,要提升大模型的實用性,下一代大模型必須具備這樣的特性:
隨著模型的規(guī)模的增長,其計算量要呈現(xiàn)一個亞線性的增長趨勢,否則系統(tǒng)很難承受。就像我們的人腦也學習了很多東西,但在回憶具體某概念時,腦子一般不用把很多知識點都過一遍。
企業(yè)界這邊,京東科技語音語義創(chuàng)新算法負責人、高級總監(jiān)吳友政提到,當下大伙兒熱議的大模型并不一定要參數(shù)量達到千億級才算。
除了“大”之外,Transformer和自監(jiān)督也是大模型的兩個核心概念。更重要的是,Transformer和自監(jiān)督在工業(yè)界已有廣泛應(yīng)用,很多企業(yè)的線上系統(tǒng)雖然沒有千億參數(shù),但參數(shù)量也能達到億級了。
當然,百億、千億級模型的工業(yè)應(yīng)用場景,還需要漫長的探索。
舉個例子,在實際應(yīng)用中,可控性往往也是一個重要指標。雖然像GPT-3這樣的模型在生成開放故事方面表現(xiàn)很好,但怎么基于現(xiàn)有的知識生成更加可控的文本依然值得研究。
對千億大模型的工業(yè)應(yīng)用,科大訊飛研究院執(zhí)行院長劉聰干脆直言道:
對企業(yè)來說,投產(chǎn)比太高。(即性價比太低)
他認同“超大模型可以提高相關(guān)技術(shù)領(lǐng)域天花板”的觀點,就像前面提到的,把它作為一種范式是OK的。
劉聰還補充道,在教育、醫(yī)療、司法等場景下(這很訊飛),模型的可解釋性是至關(guān)重要的。
用大白話講,就是要說清楚模型內(nèi)部到底發(fā)生了什么,才產(chǎn)生出這樣的結(jié)果,否則計算機通過模型給出的判定很難讓人信服。
然而,現(xiàn)在很多千億模型內(nèi)部還處于“黑盒”狀態(tài),有些原理不僅是現(xiàn)在看不透,而且由于其龐大的體量和錯綜復(fù)雜的結(jié)構(gòu),以后也很難解釋清楚。
大模型處理多模態(tài)數(shù)據(jù)的前景
除了大模型的工業(yè)應(yīng)用外,大模型處理多模態(tài)數(shù)據(jù)的前景也是個有意思的議題。
大家應(yīng)該知道(至少能意會到),人腦可以輕松處理多模態(tài)的數(shù)據(jù),從中學習和解耦各種復(fù)雜信息,并且讓各種模態(tài)的數(shù)據(jù)高度協(xié)同作用。
說人話,比如當倆人交談時,除了說出來的言語,還有語氣、語速、神態(tài)、肢體語言等也在傳遞著不同維度信息,就像有人說“好好好”可能是在真心夸贊,也可能是——
讀取并處理各種信息,對咱們聰明的大腦來說一般沒啥問題,但是對于計算機,是否也能輕松解決?
哈工大車萬翔教授表示,這應(yīng)該沒有些人想象的那么困難。
前面他用“同質(zhì)化”一詞形容了當今各個大模型的發(fā)展趨勢,再說一次,這里的“同質(zhì)化”不是貶義詞——
現(xiàn)在,文本、語音、圖像都可以用Transformer這套東西來表示;反之,用Transformer能更容易地整合不同模態(tài)信息。所以,像“語音+文本+圖像”這樣的多模態(tài)預(yù)訓練模型其實已經(jīng)數(shù)不勝數(shù)了。
此外,例如DeepMind的Gato,足足在604個不同的任務(wù)上進行了訓練,訓練數(shù)據(jù)還包括游戲里的建模動畫、模擬的機器人運用場景等。最終,這個“全才”AI不僅可以看圖寫話、和人類聊天,還可以把雅達利游戲玩得飛起,并且能操控機械臂。
清華劉知遠教授補充道,他認為多模態(tài)模型的“模態(tài)”可以更加多樣化,例如用戶行為就是一種值得大模型學習的數(shù)據(jù)。
他提到OpenAI今年發(fā)布的網(wǎng)頁版GPT(WebGPT),可以把用戶通過搜索引擎來回答問題的行為序列作為Transformer的輸入,并對其訓練,然后模型就學到了一個新技能——根據(jù)問題去網(wǎng)上搜索答案。
企業(yè)界這邊,科大訊飛的劉聰指出,在應(yīng)用場景中有剛需的多模態(tài)模型,公司會優(yōu)先投入研發(fā)。
劉聰以語音交互問題舉例:雖然在常規(guī)場景下,語音交互的技術(shù)已經(jīng)相當成熟了;但是在車載、雞尾酒會等嘈雜環(huán)境中,怎么判斷某人正在對A還是B,在對人還是對機器說話?
在這種復(fù)雜的交互場景下,語音和視覺信息等結(jié)合,可以顯著提升模型的準確性。
在大伙兒對多模態(tài)大模型積極表態(tài)之時,劉康研究員則提出了在科研過程中遇到的一個問題:
用Transformer這個萬金油來建立各個模態(tài)之間的關(guān)聯(lián),看似是個近乎完美的方案,但實際極大的依賴于背后數(shù)據(jù)之間的關(guān)系。
舉個簡單的例子,數(shù)據(jù)之間是對應(yīng)關(guān)系還是互補關(guān)系?比如,給出一段新聞數(shù)據(jù),里面的圖片可能是上下文講述的內(nèi)容,也可能是對文字的補充(就像上面那個表情包)。
所以,劉康研究員認為,除了模態(tài)種類還需多樣化外,不同模態(tài)之間的邏輯關(guān)系也是未來值得研究的方向之一。他建議,把采集的數(shù)據(jù)映射到背后的知識庫上,通過知識來處理各種模態(tài)的關(guān)系。
大模型的可解釋性
前文提到,模型的可解釋性在一些特定場景下非常重要,而且打破砂鍋問到底是一眾科研人的求知態(tài)度。
所以盡管前路渺茫,許多人仍在虔誠地探索著,希望有朝一日能解釋清楚超大模型運行過程中的各種原理。
不過,“深度學習大模型天然就不具有可解釋性。”哈工大車萬翔教授分享了他之前看到的這種觀點。他提到,機器并不像人的思維那樣運行。
想追求可解釋性,在淺層模型上更容易找到。當然,淺層模型的精度一般比深度學習模型差遠了。
車教授認為,高精度和可解釋性本身就是矛盾的。所以根據(jù)具體場景和需要選擇不同模型就好了。
比如,讓機器給學生作文打分,總得說清楚為什么得出這個分數(shù)吧。也就是要講明白為模型設(shè)置了多少feature,如:典故、排比、修辭方式、邏輯性等。這里淺層模型就更適用。
劉康研究員也認為,要去搞清楚深度學習模型黑盒部分的原理,宛如走進一條死胡同。
現(xiàn)在的研究者主要采用兩種手段試圖解釋深度學習模型黑盒內(nèi)發(fā)生了什么:
一種是觀察分析輸入哪些內(nèi)容或獲得更多權(quán)重;另一種是用可解釋的淺層模型無限逼近黑盒模型,然后用淺層模型的結(jié)果來近似解釋黑盒模型。
然而這兩種方法本本質(zhì)上也只是模擬,還是沒解釋黑盒模型的機制到底是怎么樣的。此外還有個重大問題:即使做了解釋,也幾乎是不可驗證的,這樣就沒法判斷解釋是否真的靠譜。
也有人對此觀點持不同態(tài)度——清華劉知遠教授就認為,深度學習模型還是具有可解釋性的,只不過別之前的淺層模型復(fù)雜多了,需要用到更復(fù)雜的模型和機制。這些東西還需探索,但非完全不可逾越的。
從產(chǎn)業(yè)角看來看大模型的可解釋性問題,京東吳友政和科大訊飛劉聰都表示:
要結(jié)合各行業(yè)場景的需求來分層看待可解釋性,部分簡單場景其實不太需要深度可解釋性,而教育、醫(yī)療等用戶關(guān)切過程的重大社會場景則會對可解釋性提出更高的要求 。
對于那些對可解釋性有特別需求之處,先弄清楚到底需要對哪些點進行“解釋”,除了用大模型之外,還可以結(jié)合其他知識運用類的技術(shù)。
劉聰還補充道,人機協(xié)同也是很重要的一種方式。當機器不能獨立Perfect時,那就先與人合作唄,用戶的行為或許也能為模型可解釋性提供一定幫助。
審核編輯 :李倩
-
深度學習
+關(guān)注
關(guān)注
73文章
5560瀏覽量
122752 -
自然語言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14140 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22598
原文標題:NLP,能輔助法官判案嗎?
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
焊接技術(shù)在汽車電子制造領(lǐng)域的應(yīng)用

電子技術(shù)在汽車領(lǐng)域的應(yīng)用與發(fā)展
多線示波器的原理和應(yīng)用領(lǐng)域
直播報名丨AIGC技術(shù)在工業(yè)視覺領(lǐng)域的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論